用于面积受限硬件的低深度AESSBox架构的制作方法
用于面积受限硬件的低深度aes sbox架构
技术领域
1.在此呈现的实施例涉及设备、其中的方法、控制器、计算机程序、以及计算机程序产品。具体而言,它们涉及以下技术领域/关键字并与之关联:高级加密标准aes、sbox、硬件实现、关键路径。
背景技术:
2.技术背景/现有技术
3.高级加密标准(aes)是美国国家标准与技术研究院(nist)标准化的加密算法,是当今使用最广泛的加密算法之一。它被用于保护tls协议中的web流量,并且也用于3gpp lte系统中作为三种空中接口加密方法之一。
4.aes的硬件实现也很常见,尤其是在诸如lte网络之类的高速应用中,但是同样在数据通信(datacom)中,对硬件加速加密算法的需求对于直接在网络接口卡(nic)中终接加密网络流量并且从而减轻主cpu的负载的高负载服务器至关重要。
5.aes加密算法在[1]中有详细描述,但将在此对其进行非常简要的介绍。aes是一种采用两个输入变量(明文(p)和密钥(k))的块密码,并产生密文(c)作为输出。p和c的大小决定了密码的块大小,在aes的情况下,这是128位,因此p和c的大小都是128位。密钥k的大小可以是128、192或256位。输入p被分成16个字节,并且排列成4
×
4个字节的矩阵形式,称为状态矩阵。该算法包括对状态矩阵执行的一系列运算,从而将明文越来越多地加扰成最终的密文输出。这些运算在所谓的轮次中被分组在一起。aes中的每一轮执行以下运算:subbytes、shiftrows、mixcolumns、以及addroundkey。取决于k的大小(128、192或256位),该算法执行10、12或14轮这些轮次。对于硬件实现,每轮之间的状态矩阵通常被存储在某种寄存器(触发器或锁存器)中。这意味着对电路进行钟控的最大钟控速度是由信号能够从一个寄存器移动到下一个寄存器的速度来决定的。信号的速度主要取决于信号在被存储在锁存器中之间必须经过的门数。信号经过的门数通常被称为信号的深度,或路径深度。电路的关键路径是电路中的任何组成信号的最长路径(要经过的门最多)。
[0006]
本公开重点将放在aes的所谓的sbox或替换盒(substitution box)上,它是subbytes运算的基本构造块。它也是门数最多、轮函数深度最高的运算。因此,最小化用于实现它的门数以及该电路的深度是一个有趣且有价值的研究目标。最小化门数减少电路的面积和功耗,并且如前所述,最小化关键路径增大算法的可能钟控速率,从而使加密/解密更快。
[0007]
aes sbox的高效硬件设计是一个深入研究的课题。如果期望绝对最大速度,最有可能使用的是简单的表查询实现,这自然导致面积较大。在许多实际情况下,加密子系统的物理面积是有限的,设计人员无法为aes轮次中涉及的sbox实现表查找,尤其是在fpga中实现时。对于这些情况,需要研究如何仅使用逻辑门来实现aes sbox,重点关注面积和最大钟控速度。电路的最大钟控速度由以下项决定:电路的关键路径或深度;从输入信号的变化中获得稳定的输出信号所花费的最坏情况时间。
[0008]
实现aes时的另一方面是需要逆向密码。块密码的许多运算模式仅使用加密功能,因此不需要逆向密码。如果需要正向sbox和逆向sbox两者,组合这两个电路通常是有益的。这是因为aes sbox的主要运算是域元素求逆,这自然是它自己的逆,期望两个电路的许多门可以被共享。
[0009]
图1是sbox电路101的框图,该电路有利地用于aes电路中以将8位输入103映射到8位输出105。
[0010]
在电路级别,sbox 101定义了8个布尔函数,每个函数以8个位作为输入。从数学的角度来看,正向aes sbox被定义为非线性函数i(g)和仿射函数a(g)的组合,使得sbox(g)=a(i(g))。非线性函数i(g)=g
‑1是由不可约多项式x8+x4+x3+x+1定义的有限域gf(2^8)中的元素g的乘法逆。构造gf(2^8)上的逆的电路非常大,因此期望将其最小化。
[0011]
rijmen[2]描述了朝着小面积实现的第一步。该理念是通过对gf((24)2)进行基变换,gf(28)中的逆向计算可以被简化为子域gf(24)中简单得多的逆向计算。
[0012]
2001年,satoh等人发表的[3]使此理念更进一步,并将逆向计算简化到子域gf(22)。这种方法被称为塔域构造。2005年,canright发表的[4]以satoh等人的工作为基础,研究了子域表示的重要性,测试了导致最小面积设计的许多不同的同构。此构造可能是面积受限的组合aes sbox的最常被引用和使用的实现。
[0013]
在一系列论文中,boyar、peralta等人针对子域反相器(inverter)以及最小化逻辑电路面积的新启发法两者提出了一些非常有趣的理念[8、9、10、11]。他们在gf(24)上导出了一个深度为4且门数仅为17的反相器。[10]中的构造是本发明的起点。
[0014]
在boyar之后,其他几篇论文关注低深度实现,例如[5]。2018年,reyhani等人的两篇论文[12、6]介绍了正向sbox和组合sbox两者的最著名实现(到目前为止)。
[0015]
理论上比较结果
[0016]
首先,介绍本文使用的记法。门名称以大写字母gate书写(例如:“与”and、“或”or)。记法mgaten表示类型为gate的m个门,每个门有n个输入(例如:xor4、8xor4、nand3、2and2)。当输入数n缺失时,假设门具有最小输入数,通常只有2(mux为3)。
[0017]
1.标准方法
[0018]
标准方法中考虑的基本基元元素是:{xor,xnor,and,nand,or,nor,mux,nmux,not}。
[0019]
not门(“非”门)的协商。在电路的某些位置,需要使用信号的反相版本。然而,有很多方法来协商使用not门的需要。在此列出了其中的一些。
[0020]
方法1.协商not门的一种方法是更改生成该信号的前一个门以替代地产生反相信号。例如,将“异或”xor切换成“同或”xnor,将“与”and切换成“与非”nand等。
[0021]
方法2.在各种技术中,有些门可以产生正信号和其反相版本。例如,许多实现中的xor门同时产生这两种信号,因此反相值是可用的。
[0022]
方法3.可以在反相信号之后更改后续的门,以使得在给定反相输入的情况下,后续的方案将产生正确的结果。
[0023]
综上所述,认为用标准方法对电路求值时可忽略not门;在标准方法中,它们几乎不能算作全门(full gate)。但是,为了完整性,结果表中包含了not门的数量。不过,其中一些not门可以进一步被协商。
[0024]
在标准方法中,电路面积是通过对基本基元的数量进行计数来计算的,基本基元之间没有任何大小区别。not门被忽略。深度是根据电路路径上基本基元的数量来计数的。因此,电路的总深度是关键路径的延迟。not门被忽略。
[0025]
2.技术方法
[0026]
面积.存在来自不同供应商(英特尔、三星等)的许多asic技术(90nm、45nm、14nm等),这些技术具有不同的特性。为了开发asic,需要获得特定技术的“标准基元库”,该库通常包括比上面列出的标准元素大得多的基元,使得设计有更广泛的构造基元选择。
[0027]
然而,即使考虑标准基元,例如xor,对于不同的技术而言,该基元也具有不同的面积和延迟。这加大了比较由两个团队开发的相同逻辑的两个电路(当这些团队选择应用不同的技术时)的难度。
[0028]
为了公平比较学术界各种解决方案的电路面积,通常使用术语“门等效(ge)”,其中1ge是最小nand门的大小。然后,电路大小(就ge而言)被计算为面积(电路)/面积(nand)
→
t ge。了解每个标准或技术基元的估计ge值使得能够计算就ge而言的电路的估计面积大小。尽管各种技术对于标准基元具有略微不同的ge,但这些ge数字仍然相当接近。对于本公开,已决定使用由三星的std90/mdl90 0.35μm 3.3v cmos技术[7]数据手册中给出的ge值。要使用的基元没有速度x因子。
[0029]
深度.不同的基元(如xor和nand)不仅在ge方面不同,而且在门的最大延迟方面也不同。
[0030]
通常,数据手册包括每个门以及每个输入
‑
输出组合的延迟(例如,以ns为单位)tphl和tplh。切换特性{tphl、tplh}被计算为在输入切换50%电压阈值的时间与输出信号从高到低(tphl)或从低到高(tplh)切换50%的电压的时间之间的差。在此建议通过xor门的延迟对所有被使用的门的延迟进行归一化。即,在关键路径的测量中采用xor门的最坏情况延迟作为1个单位。然后查看每个标准基元,并针对该基元的所有输入
‑
输出路径而选择最大的切换特性{tphl、tplh}。然后,它们被除以xor门的最大延迟,从而获得所使用的每个门的归一化延迟单位。
[0031]
对于多路复用器(mux和nmux),选择位的传播延迟被忽略,因为在大多数情况下,选择位通常是电路的输入。例如,在组合sbox中,选择位控制计算正向sbox还是逆向sbox,该选择已准备好并且不在电路信号传播时切换,因此它是一个稳定信号。
[0032]
上面提出的方法类似于ge的理念,但被用于计算电路的深度,以xor延迟被归一化。选择xor作为延迟计数的基本元素的原因是电路最有可能有很多xor门,因此现在可以比较标准方法与技术方法之间的深度。
[0033]
先前的工作
[0034]
1.正向sbox
[0035]
使用最广泛的设计来自canright在2005年发表的[4]。2005年以后,在正向sbox的速度和面积方面已经进行了多次改进设计的尝试。boyar等人在2012年发表的[10]中构造了先前最小的已知实现,而ueno等人在2015年发表的[5]具有最短关键路径的纪录。最近,reyhani等人提出了更好地平衡面积速度权衡的新构造[12]。先前的结果总结在表1中。
[0036][0037]
表1.正向sbox的先前结果。
[0038]
2.组合sbox
[0039]
使用最广泛的设计来自canright在2005年发表的[4]。该设计的主要缺点是相对较大的关键路径(大深度)。2005年以后,在速度和面积方面也有很多改进设计的尝试,但几乎所有人都只专注于实现正向sbox。这在仅使用算法的加密部分的特定运算模式下具有相关性。2018年,reyhani等人发表的[6]中公开了关于组合sbox的新结果。它提高了速度和深度两者。先前的结果总结在表2中。
[0040]
[0041]
表2.组合sbox的先前结果。
[0042]
现有解决方案的问题
[0043]
在此描述的技术的本质是它能够在关键路径方面做得好得多。因此,使用本文公开的优化的实现能够以高于先前实现的频率被钟控,从而加速加密和解密,或者在asic或fpga中使用比例如表查找更少的基元来实现。随着通信速度的提高和物联网(iot)设备越来越小,对硬件中面积优化后的加密算法的需求越来越大,这将变得越来越重要。
技术实现要素:
[0044]
在硬件中实现加密算法时,决定可能的钟控速度的主要参数是设计的深度(或关键路径)。对于高级加密标准(aes)[1],此路径由sbox子组件主导。因此,目标是为sbox找到给出尽可能低的深度的布尔表达式。对于面积受限的asic,保持sbox的面积小也很重要。
[0045]
根据本发明的一个方面,上述和其他目标通过实现sbox功能的技术(例如,方法、装置、非暂时性计算机可读存储介质、程序装置,例如当被包括在密码电路中时)达成。在一些实施例的一个方面,一种sbox电路包括第一电路部分、第二电路部分、以及第三电路部分。所述第一电路部分包括根据8位输入信号(u)来生成4位第一输出信号(y)的数字电路。所述第二电路部分被配置为与所述第一电路部分并行地操作,并根据所述8位输入信号(u)来生成32位第二输出信号(l),其中,所述32位第二输出信号(l)包括四个8位子结果。所述第三电路部分被配置为通过将所述四个8位子结果中的每一个8位子结果与所述4位第一输出信号(y)的相应的一个位进行标量相乘来产生四个初步的8位结果(k),以及通过将所述四个初步的8位结果(k)相加来产生8位输出信号(r)。此外,所述第一电路部分被配置为通过执行包括第一线性矩阵运算、伽罗瓦域gf乘法、以及gf求逆的计算,根据所述输入信号(u)来生成所述4位第一输出信号(y);以及所述第二电路部分被配置为通过执行包括第二线性矩阵运算的计算,根据所述输入信号(u)来生成所述第二输出信号(l)。
[0046]
在与本发明一致的一些实施例但不一定是全部实施例的一个方面,所述第三电路部分包括根据下式执行计算的数字电路:
[0047]
r=y0·
m0·
u
⊕
...
⊕
y3·
m3·
u,
[0048]
其中:
[0049]
每个m
i
是一个8
×
8矩阵,表示所述8位输入u上的8个线性方程,
[0050]
i=0..3,
[0051]
l=m0·
u||m1·
u||m2·
u||m3·
u,
[0052]
⊕
表示“异或”xor运算,以及
[0053]
||表示并置。
[0054]
在与本发明一致的一些实施例但不一定是全部实施例的另一方面,所述第一电路部分、所述第二电路部分以及所述第三电路部分中的每一个是从选自以下任何一项或多项的数字电路来配置的:
[0055]“异或”xor门;
[0056]“同或”xnor门;
[0057]“与”and门;
[0058]“与非”nand门;
[0059]“或”or门;
[0060]“或非”nor门;
[0061]
多路复用器mux;
[0062]
nmux门;
[0063]“非”not门;
[0064]“与或”反相器aoi;以及
[0065]“或与”反相器oai。
[0066]
在与本发明一致的一些实施例但不一定是全部实施例的另一方面,所述第一电路部分和所述第二电路部分被配置为根据正向sbox运算来生成所述4位第一输出信号(y)和所述32位第二输出信号(l)。
[0067]
在与本发明一致的一些实施例但不一定是全部实施例的另一方面,所述第一电路部分(301,503)和所述第二电路部分(303,505)被配置为根据逆向sbox运算来生成所述4位第一输出信号(y)和所述32位第二输出信号(l)。
[0068]
在与本发明一致的一些实施例但不一定是全部实施例的另一方面,所述第一电路部分和所述第二电路部分被配置为根据正向sbox运算来生成所述4位第一输出信号(y)和所述32位第二输出信号(l);并且所述sbox电路还包括第四电路部分、第五电路部分、以及选择电路。所述第四电路部分包括根据所述8位输入信号(u)来生成替代的4位输出信号(y
alt
)以用于逆向sbox运算的数字电路。所述第五电路部分被配置为与所述第四电路部分并行地操作,并根据所述8位输入信号(u)来生成替代的32位第二输出信号(l
alt
)以用于所述逆向sbox运算,其中,所述替代的32位第二输出信号(l
alt
)包括四个8位子结果。所述选择电路可控制以在正向sbox运算被选择时将所述第一电路部分和所述第二电路部分相接合,以及在逆向sbox运算被选择时将所述第四电路部分和所述第五电路部分相接合。
[0069]
如上所述,与本发明一致的实施例的各方面(例如上面描述的那些方面)可以替代地体现为其他形式,例如但不限于方法、非暂时性计算机可读存储介质、以及程序装置(例如,计算机程序产品)。
附图说明
[0070]
当结合附图阅读以下详细说明时,将理解本发明的目标和优点,其中:
[0071]
图1是将8位输入映射到8位输出的sbox电路的框图;
[0072]
图2是sbox的经典架构的框图;
[0073]
图3a和3b是分别描绘根据本发明的sbox的第一替代实施例和第二替代实施例的框图;
[0074]
图4是传统sbox架构的框图;
[0075]
图5是与本发明一致的sbox架构的框图;
[0076]
图6描绘了示出正向sbox的不同实施例的合成结果的一组图;
[0077]
图7描绘了示出组合sbox的不同实施例的合成结果的一组图;
[0078]
图8是在一个方面中由与本发明一致的实施例执行的动作的流程图;
[0079]
图9示出了均与本发明的各方面一致的计算机程序、计算机可读存储介质、以及计算机程序产品。
具体实施方式
[0080]
描述方法和装置的实施例对于具有在本公开中讨论的特征和可能性的所有技术都是有效的。本文所述的实施例用作非限制性示例。
[0081]
为了便于更好地理解本文所述的技术的各个方面,本“具体实施方式”被分成三个部分。第一部分(“部分a”)侧重于关键方面,并提供了对这些方面的完整描述。第二部分(“部分b”)描述了这些方面,并在这些方面之外还描述了技术的其他方面。第三部分(“部分c”)描述了与a部分和b部分中提出的技术方面一致的附加实施例。
[0082]
部分a
[0083]
经典的sbox架构是使用塔域扩展构建的。为了使用塔域构造来构建gf(2^8),遵循参考文献[4,10]中描述的教导,从基本二进制域gf(2)开始并构建扩展域。让我们从gf(2)上的不可约多项式f(x)=x^2+x+1开始。设w是f(x)的根,使得f(w)=0。正规基(normalbase)是根据w的共轭[w,w^2]构造的。现在,gf(2^2)中的每个元素k都可以表示为k=k0w+k1w^2,其中,k0和k1是gf(2)中的元素;即,1或0。
[0084]
使用相同的技术,可以根据gf(2^2)构建域gf(2^4),以及根据gf(2^4)最终可以构建目标域gf(2^8)。表3总结了所使用的不可约多项式、根、以及正规基。
[0085][0086]
表3.用于构造gf(2^8)的子域的定义。
[0087]
设a=a0y+a1y^16是gf(2^8)中的通用元素,具有位于gf(2^4)中的系数。a的逆可以被写成:
[0088]
a
‑1=(aa
16
)
‑1a
16
[0089]
=((a0y+a1y
16
)(a1y+a0y
16
))
‑1(a1y+a0y
16
)
[0090]
=((a
20
+a
21
)y
17
+a0a1(y2+y
32
))
‑1(a1y+a0y
16
)
[0091]
=((a0+a1)2y
17
+a0a1(y+y
16
)2)
‑1(a1y+a0y
16
)
[0092]
=((a0+a1)2wz+a0a1)
‑1(a1y+a0y
16
).
[0093]
gf(2^8)中的元素求逆可以在gf(2^4)中被完成为:
[0094]
t1=(a0+a1)t2=(wz)t
12
t3=a0a1t4=t2+t3[0095]
t5=t4‑1t6=t5a1t7=t5a0,
[0096]
其中得到的结果为a
‑1=t6y+t7y
16
。在这些方程中使用了几种运算(加法、乘法、缩放、以及平方),但其中只有两个在gf(2)上是非线性的:乘法和求逆。此外,标准乘法运算还包含一些线性运算。如果所有线性运算都与非线性运算分离,并与对aessbox输入(使用aessbox不可约多项式x8+x4+x3+x+1以多项式基表示)进行基转换所需的线性方程捆绑在一起,则最终得到图2所示的sbox201的经典架构(在此表示为“a”)。电路的顶部线性层203执行基转换并生成逆的线性部分。底部线性层205执行aessbox的基反向转换和仿射变换。
[0097]
本发明的重要方面:“架构d”[0098]
该新架构(在此称为“d”,表示深度)是一种其中去除了早期设计中的底部矩阵的
新架构,从而尽可能减小电路的深度。这背后的思路是,底部矩阵仅取决于4位信号y以及8位输入u的一些线性组合的乘法集。结果r可以被实现如下:
[0099]
r=y0·
m0·
u
⊕
...
⊕
y3·
m3·
u,
[0100]
其中,每个m
i
是一个8
×
8矩阵,表示8位输入u上的8个线性方程,它们将与y
i
位进行标量相乘。那些4
×
8线性电路可以被计算为32位信号l,这与用于4位y的电路并行。通过将四个8位子结果相加而获得结果r。因此,在架构d中,在求逆步骤(关键路径:mull和8xor4块,见图5)之后得到深度3,而不是架构a中的深度5
‑
6(见图4)。
[0101]
新架构d需要多一些门,因为组装底部电路需要56个门:32nand2+8xor4。奖励是较低的深度。
[0102]
图3a描绘了架构d的一个示例性实施例的框图,图3b描绘了架构d的替代示例性实施例。两个实施例之间的差别在于,通过使用本文稍后描述的进一步技术,能够将信号q从22位减小到18位。在所有其他方面,这两个实施例是相同的,并且出于这个原因并且为了效率,描述将侧重于图3b所示的实施例,并且将理解,该讨论同样适用于图3a的实施例。
[0103]
如图3b所示,sbox电路300被布置为当被包括在密码电路中时执行sbox计算步骤。示例性sbox电路(300)包括第一电路部分301、第二电路部分303、以及第三电路部分305。第一电路部分301包括根据8
‑
位输入信号(u)来生成4位第一输出信号(y)的数字电路。
[0104]
第二电路部分303被配置为与第一电路部分301并行地操作,以及根据8位输入信号(u)来生成32位第二输出信号(l),其中,32位第二输出信号(l)包括四个8位子结果。
[0105]
第三电路部分305被配置为通过将四个8位子结果(l)中的每一个8位子结果与4位第一输出信号(y)的相应的一个位进行标量相乘来产生四个初步的8位结果(k),以及通过将四个初步的8位结果(k)相加来产生8位输出信号(r)。
[0106]
进一步根据示例性实施例,第一电路部分301被配置为通过将8位输入u提供给第一线性矩阵电路307,根据输入信号(u)来生成4位第一输出信号(y),该第一线性矩阵电路307生成输出q(在图3a的实施例中为22位,在图3b的实施例中为18位)。输出q被提供给乘法/求和电路309,乘法/求和电路309执行伽罗瓦域(gf)乘法309以生成4位信号x,然后该4位信号x被提供给逆伽罗瓦域电路(311),逆伽罗瓦域电路(311)执行gf求逆以生成4位信号y。
[0107]
同样,根据示例性实施例,第二电路部分303被配置为通过执行包括第二线性矩阵运算的计算,根据输入信号u来生成第二输出信号l。
[0108]
为了便于比较传统架构a与新架构d,图4(传统架构a)和图5(新架构d)示出了不同框(block)的更详细描述和实现大小。
[0109]
首先看图4,可以看出传统sbox架构400包括顶层401,顶层401交替地被配置为正向sbox(ftopa)、逆向sbox(itopa)或能够在正向计算与逆向计算之间进行选择的组合sbox(ctopa)。但值得注意的方面是,传统sbox架构400还包括底层403,底层403交替地被配置用于正向运算(fbota)、逆向运算(ibota)或能够在正向运算与逆向运算之间进行选择的组合(cbota)。
[0110]
发明人已经认识到,通过将底层的许多功能方面重新分布到上层中,能够消除传统sbox架构a 400的底层403,并且能够减小深度。结果形成图5所示的架构d500。
[0111]
图5描绘的架构d 500具有与图3所示的架构等效的组织。值得注意的是,它包括顶
层501,顶层501替代地被配置为正向sbox(ftopd)、逆向sbox(itopd)或能够在正向计算与逆向计算之间进行选择的组合sbox(ctopd)。在组合sbox(ctopd)的情况下,正向计算与逆向计算之间的选择取决于接收到的正/逆。
[0112]
一个显著的特征是传统底层(参见例如图4中的底层403)的一些功能方面已被重新分布到新架构500的上层,因此它现在具有与第二电路部分505并行地操作的第一电路部分503。第一电路部分503根据8位输入信号(u)来生成4位第一输出信号(y),第二电路部分505根据8位输入信号(u)来生成32位第二输出信号(l),其中32位第二输出信号(l)包括四个8位子结果。
[0113]
来自第一电路部分503的输出y和来自第二电路部分505的输出l由第三电路部分509一起处理,第三电路部分509被配置为通过将四个8位子结果中的每一个8位子结果与4位第一输出信号(y)的相应的一个位进行标量相乘来产生四个初步的8位结果(k),并通过将四个初步的8位结果(k)相加来产生8位输出信号(r)。
[0114]
新sbox架构500的示例性门配置的细节在下文中呈现。
[0115]
预备知识
[0116]
在下面给出的清单中,描述了两种架构a(小型)和d(快速)中的正向、逆向、以及组合sbox的六个电路的规格。以下清单中使用的符号如下,并具有所指出的含义:
[0117]
·
#comment
–
注释行
[0118]
·
@filename
–
表示应包括来自另一名为“filename”的文件的代码,然后在本节中也给出了它的清单。
[0119]
·
a^b
–
是常见的“异或”xor门;其他门被显式表示并取自集合{xnor,and,nand,or,nor,mux,nmux,not}
[0120]
·
(a op b)
–
在执行顺序(门连接的顺序)很重要的情况下,用括号指定该顺序。
[0121]
到所有sbox的输入是8个信号{u0..u7},输出是8个信号{r0..r7}。输入位和输出位以大端(big endian)位序来表示。对于组合sbox,输入具有额外的信号zf和zi,如果执行正向sbox,则zf=1,否则,如果执行逆向sbox,则zf=0;信号zi是zf的补充信号。我们已经测试了所有提出的电路并验证了它们的正确性。
[0122]
这些电路被划分成子程序,这些子程序分别对应于图5所示的功能/层。讨论从描述公共共享组件开始,然后针对每个解,描述电路的组件(公共的或特定的)。
[0123]
共享组件
[0124]
清单:mulx/inv/s0/s1/8xor4:共享组件。
[0125]
[0126][0127]
清单:muln/mull:共享组件。
[0128][0129]
清单:具有最小延迟的正向sbox(快速)
[0130]
正向sbox(快速)
[0131][0132]
清单:具有面积/深度权衡的正向sbox电路(最佳)
[0133]
正向sbox(最佳)
[0134][0135]
包括以下奖励电路以更新最小sbox的世界纪录。
[0136]
新纪录是108个门,深度为24。
[0137]
清单:具有最小门数的正向sbox电路(奖励)
[0138][0139]
清单:具有最小延迟的逆向sbox(快速)
[0140]
逆向sbox(快速)
[0141][0142]
清单:具有面积/深度权衡的逆向sbox电路(最佳)
[0143]
逆向sbox(最佳)
[0144][0145]
注意:文件
‘
itop.a’中的上述
‘
not(u2)’可以通过设置q11=u2并准确地向下对一些涉及q11的门和变量求“反”来移除。例如,变量y01也应被求“反”,因为:n0=nand(y01,q11),因此,所有涉及y01的门被求“反”,这导致其他q变量被求“反”,等等。
[0146]
清单:具有最少门数的逆向sbox电路(奖励)
[0147]
逆向sbox(奖励)
[0148][0149]
清单:具有最小延迟的组合sbox电路(快速/
‑
s)
[0150]
组合sbox(快速)
[0151]
[0152]
[0153][0154]
清单:具有面积/深度权衡的组合sbox电路(最佳)
[0155]
组合sbox(最佳)
[0156]
[0157][0158]
清单:具有最少门数的组合sbox电路(奖励)
[0159]
组合sbox(奖励)
[0160]
[0161][0162]
本发明的优点
[0163]
具有针对快速sbox的设计对于特定类别的应用非常重要,例如cpu中的aes硬件支持。在这种情况下,sbox设计很可能针对关键路径被非常小心地布局并布线。具有非常短的关键路径会显著加快可能的钟控频率。另外,在更难(与asic相比)达到高钟控频率的fpga中,重要的是在关键路径中具有尽可能少的门。
[0164]“背景技术”一节中的表格已经扩展到现在还包括本文所述的新架构d的结果。注
意与传统sbox电路相比关键路径是如何显著减少的。
[0165]
1.正向sbox
[0166][0167]
新架构d的结果
[0168][0169][0170]
2.组合sbox
[0171][0172]
已经对结果进行了合成,并与其他最近的学术工作进行了比较。
[0173]
技术工艺为globalfoundries 22nm csc20l[glo19],并且已使用拓扑模式下synopsys的design compiler 2017和compile_ultra命令执行了合成。此外,标志compile_timing_high_effort被开启以强制编译器产生尽可能快的电路。在下图中,x轴是时钟周期(以ps为单位),y轴是得到的拓扑估计面积(以μm2为单位)。可用门数不受任何限制,因此编译器可以自由使用非标准门,例如3输入“与
‑
或”门。为了获得以下小节中的图,时钟周期从1200ps时钟周期(~833mhz)开始,然后减少20ps,直到无法满足时序约束为止。要注意的是,编译器的面积估计波动很大,这被认为是编译器必须最小化深度的许多不同策略的结果。一种策略可能对于比如700ps时钟周期是成功的,但另一策略(其导致明显更大的面积)可能对于720ps是成功的。编译器的策略还涉及随机性元素。
[0174]
正向sbox的合成结果如图6所示,组合sbox的合成结果如图7所示。为了进行比较,图6示出了以下架构的合成结果的图:
[0175]
·
ches18_fast 601
[0176]
·
ches18_small 603
[0177]
·“快速”电路605,如本文所述。
[0178]
·“最佳”电路607,如本文所述。
[0179]
·“奖励”电路609,如本文所述。
[0180]
(术语“ches18_fast”和“ches18_small”指示[12]中的结果)。
[0181]
在图6中:
[0182]
‑
描绘此处描述的“快速”电路的曲线605显示为范围从略低于650ps到大约1075ps。
[0183]
‑
描绘“ches18_small”的曲线603范围从大约780ps到大约1075。
[0184]
‑
描绘“ches18_fast”的曲线601范围从大约800直到大约1075。
[0185]
为了进一步比较,图7示出了以下架构的合成结果的图:
[0186]
·
canright 701。
[0187]
·
reyhani 703。
[0188]
·“快速”电路705,如本文所述。
[0189]
·“fast
‑
s”电路707,如本文所述。
[0190]
·“最佳”电路709,如本文所述。
[0191]
·“奖励”电路711,如本文所述。
[0192]
(术语“canright”指示[4]中的结果,术语“reyhani”指示[6]中的结果)。
[0193]
在图7中:
[0194]
‑
描绘“fast
‑
s”的曲线707显示为最接近x轴,范围从大约740到1200。
[0195]
‑
描绘“快速”的曲线705显示为第二接近x轴,范围从大约740到1200。
[0196]
‑
描绘“reyhani”的曲线703的范围从大约900到1200。
[0197]
‑
描绘“canright”的曲线701的范围从大约1000到大约1200。
[0198]
在图6和图7的每一个中,曲线越接近轴线,面积/速度权衡的结果越好。
[0199]
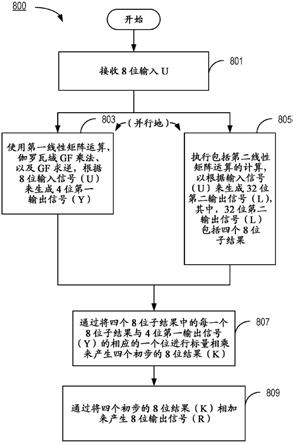
现在参考图8描述本文所述的技术的其他方面,图8在一方面是由与本发明一致的实施例执行的动作的流程图。在另一方面,图8也被视为用于执行sbox功能的装置800的框图,包括用于根据sbox功能将输入映射到输出的各个组件部分(801、803、805、807和809)。
[0200]
动作以接收8位输入u开始(步骤801)。8位输入作为输入被提供给另外两个相互并行地操作的动作。其中第一动作是使用第一线性矩阵运算、伽罗瓦域(gf)乘法、以及gf求逆,根据8位输入信号(u)来生成4位第一输出信号(y)(步骤803)。
[0201]
并行地,执行包括第二线性矩阵运算的计算(步骤805),以根据输入信号(u)来生成32位第二输出信号(l),其中32位第二输出信号(l)包括四个8位子结果。
[0202]
接下来,通过将32位第二输出信号(l)的四个8位子结果中的每一个8位子结果与4位第一输出信号(y)的相应的一个位进行标量相乘来产生四个初步的8位结果(k)(步骤807)。
[0203]
然后,通过将四个初步的8位结果(k)相加来产生8位输出信号(r)。
[0204]
在与本发明一致的实施例的其他方面,如图9所示,本文所述的改进sbox的架构也可以以多种其他形式体现,包括计算机程序901,计算机程序901包括一组程序指令,这些程序指令被配置为使得一个或多个处理器执行一系列动作,例如图3a、3b、5和8中任一个中描绘的动作(例如,当在处理设备上运行时,计算机程序901导致根据本文所述的各种实施例的运算)。通常,程序模块可以包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等。计算机可执行指令、关联的数据结构、以及程序模块表示用于执行本文公开的方法步骤的程序代码的示例。此类可执行指令或关联的数据结构的特定序列表示用于实现此类步骤或过程中描述的功能的相应动作的示例。
[0205]
一些其他实施例采取包括上述计算机程序901的计算机可读存储介质903(或等效的一组介质)的形式。计算机可读介质901可以包括可移动和不可移动存储设备,包括但不限于只读存储器(rom)、随机存取存储器(ram)、压缩盘(cd)、数字多功能盘(dvd)以及类似设备。
[0206]
另外一些实施例可以采取计算机程序产品905的形式,计算机程序产品905被包含在计算机可读介质903中,计算机可读介质903包括由联网环境中的计算机执行的计算机可执行指令,例如程序代码。
[0207]
贯穿本公开,各个图中的框可以指模拟和数字电路的组合和/或一个或多个控制器单元,控制器单元配置有例如存储在存储单元(数据库)中的软件和/或固件,当由一个或多个控制器单元执行时,这些软件和/或固件根据上述方式执行。这些控制器单元,以及模拟和数字电路的任何其他组合中的一个或多个可以被包括在单个专用集成电路(asic)中,或者几个控制器单元和各种数字硬件可以分布在几个单独的组件中,无论是单独封装还是组装到片上系统(soc)中。一个或多个控制器单元可以是中央处理单元(cpu)、图形处理单元(gpu)、可编程逻辑阵列(pal)或任何其他类似类型的电路或逻辑布置中的任何一种或它们的组合。
[0208]
优势
[0209]
本文公开了一种比先前已知的结果更快(具有更短关键深度)的新架构。在这种新架构中,传统解决方案中存在的底部线性矩阵(参见例如图2)已被移除,取而代之的是与求逆电路并行地,在顶部线性矩阵中执行大多数计算(参见例如图3a和3b)。通过这种方式,电路的深度减少了大约25%
‑
30%。由此产生的sbox是已知最快的。
[0210]
缩略词
[0211]
aes:高级加密标准
[0212]
asic:专用集成电路
[0213]
fpga:现场可编程门阵列
[0214]
参考文献
[0215]
[1]nist:高级加密标准(aes)规范。技术报告fips pub 197,美国国家标准与技术研究院(nist)(2001)
[0216]
[2]vincent rijmen。rijndael s
‑
box的有效实现。参见www.esat.kuleuven.ac.be。
[0217]
[3]akashi satoh、sumio morioka、kohji takano和seiji munetoh。具有s
‑
box优化的紧凑型rijndael硬件架构。cryptology
‑
asiacrypt 2001,colin boyd编辑,第7届密码学和信息安全理论与应用国际会议,澳大利亚黄金海岸,2001年12月9至13日,会议记录,计算机科学讲义,第2248卷,第239
‑
254页。springer,2001年。
[0218]
[4]d.canright。用于aes的极紧凑s
‑
box。josyula r.rao和berk sunar编辑,“加密硬件与嵌入系统
‑
ches 2005”,第441
‑
455页,柏林,海德堡,2005年。springer berlin heidelberg。
[0219]
[5]rei ueno、naofumi homma、yukihiro sugawara、yasuyuki nogami和taka
‑
fumi aoki。基于冗余gf算术的高效gf(28)反相电路及其在aes设计中的应用。tim g
ü
neysu和helena handschuh编辑,“加密硬件与嵌入系统
‑
ches 2005”,第17届国际研讨会,法国圣
马洛,2015年9月13至16日,会议记录,计算机科学讲义,第9293卷,第63
‑
80页。springer,2015年。
[0220]
[6]reyhani
‑
masoleh,a.、taha,m.和ashmawy,d.(2018年)。aes组合s
‑
box/逆向s
‑
box的新面积纪录。2018年ieee第25届计算机算术研讨会(arith),第145
‑
152页,2018年。
[0221]
[7]samsung electronics co.,ltd.。纯逻辑/mdl产品数据手册的std90/mdl90 0.35μm 3.3v cmos标准基元库,2000年。
[0222]
[8]joan boyar和ren
éꢀ
peralta。应用于密码学的新型组合逻辑最小化技术。paola festa编辑,实验算法,第178
‑
189页,柏林,海德堡,2010年。springer berlin heidelberg。网址:eprint.iacr.org。
[0223]
[9]joan boyar和ren
éꢀ
peralta。应用于密码学的新型组合逻辑最小化技术。计算机科学讲义,第178
‑
189页。springer,2010年。
[0224]
[10]joan boyar和ren
éꢀ
peralta。用于aes s
‑
box的小深度16电路。dimitris gritzalis、steven furnell和marianthi theoharidou编辑,sec,ifip信息和通信技术进展,第376卷,第287
‑
298页。springer,2012年。网址:link.springer.com。
[0225]
[11]j.boyar和r.peralta。向美国专利商标局提交的专利申请号61089998。用于组合电路优化的新技术和用于aes的s
‑
box的新电路,2009。
[0226]
[12]arash reyhani
‑
masoleh、mostafa taha和doaa ashmawy。粉碎aes s
‑
box的实现记录。加密硬件和嵌入式系统上的iacr交易,2018(2):第298
–
336页,2018年5月。
[0227]
在此公开的实施例可以通过模拟和数字电路的组合、一个或多个控制器单元、以及用于执行本文所述的实施例的功能和动作的计算机程序代码来实现。上述程序代码也可以作为计算机程序产品来提供,例如采取承载计算机程序代码的数据载体的形式,当被加载到移动通信设备中时,计算机程序代码用于执行本文的实施例。一种这样的载体可以是cd rom盘的形式。然而,其他数据载体(例如记忆棒)也是可行的。计算机程序代码还可以作为服务器上的纯程序代码被提供并在生产时和/或在软件更新期间被下载到移动通信设备。
[0228]
当使用“包含”或“包括”一词时,应将其解释为非限制性的,即表示“至少由
……
组成”。
[0229]
上面已经主要参考几个实施例描述了本发明构思。然而,本领域技术人员容易理解,除了以上公开的实施例之外的实施例在本文公开的本发明构思的范围内同样是可能的。
[0230]
本领域技术人员将理解,本文所述的技术的关键方面包括上文关于本公开的部分a中的图3a、3b、5、8和9(“架构d”)以及本公开的部分b的第5节中公开的架构改进而讨论和描绘的技术特征的各种组合和子组合。
[0231]
本领域技术人员将理解,本文所述的技术的其他关键方面包括上文关于如在下面的本公开的部分b的第4节中讨论的用于使用多路复用器解析线性系统的方法而讨论的技术特征的各种组合和子组合。
[0232]
本公开的部分b
[0233]
最小、最佳和最快aes sbox
[0234]
1 简介
[0235]
aes sbox的高效硬件设计是一个深入研究的课题。如果想要绝对最大速度,可能使用简单的表查找实现,这自然导致面积较大。在许多实际情况下,加密子系统的面积是有限的,设计人员无法为aes轮次中涉及的16个sbox实现表查找,尤其是当在fpga中实现时。对于这些情况,需要研究如何仅使用逻辑门来实现aes sbox,重点放在面积和最大钟控速度两者上。电路的最大钟控速度由以下因素决定:电路的关键路径或深度;从输入信号的变化中获得稳定输出信号所花费的最坏情况时间。
[0236]
实现aes时的另一方面是需要逆向密码。块密码的许多运算模式仅使用加密功能,因此不需要逆向密码。如果需要正向sbox和逆向sbox两者,组合这两个电路通常是有益的。这是因为aes sbox的主要运算是域元素求逆,这自然是它自己的逆,期望两个电路的许多门可以被共享。
[0237]
从数学的角度来看,正向aes sbox被定义为非线性函数i(g)和仿射函数a(g)的组合,使得sbox(g)=a(i(g))。非线性函数i(g)=g
‑1是由不可约多项式x8+x4+x3+x+1定义的有限域gf(2^8)中的元素g的乘法逆。我们假设读者熟悉aes sbox,并参考[ost01]以获得更全面的描述。
[0238]
rijmen描述了朝着小面积实现的第一步[rij00],其中使用来自[it88]的结果。该理念是通过对gf((24)2)进行基变换,gf(28)中的逆向计算可以被简化为子域gf(24)中简单得多的逆向计算。2001年,satoh等人发表的[smtm01]使此理念更进一步,并将逆向计算简化到子域gf(22)。2005年,canright发表的[can05]以satoh等人的工作为基础,研究了子域表示的重要性,测试了导致最小面积设计的许多不同的同构。这种构造可能是面积受限的组合aes sbox的最常被引用和使用的实现。
[0239]
在一系列论文中,boyar、peralta等人针对子域反相器以及最小化逻辑电路面积的新启发法两者提出了一些非常有趣的思路[bp10a、bp10b、bp12、bfp18]。他们在gf(24)上导出了一个深度为4且门数仅为17的反相器。[bp12]中的构造是本公开的起点。
[0240]
在boyar之后,其他几篇论文关注低深度实现[jkl10、nnt+10、uhs+15]。2018年,reyhani等人的两篇论文[rmta18a、rmta18b]介绍了正向sbox和组合sbox的最著名实现(到目前为止)。如[rmta18a]中所指出的,在如何呈现和比较组合电路的实现方面,研究者存在分歧。一种方法是简单地对设计中标准门的总数进行计数,并找到通过包含关键路径的电路的路径以确定和比较速度。实际情况要比这复杂得多。在本文中,我们展示了仅使用门数的简单度量,以及基于与“与非”门相比的门所需的典型面积来给出“等效门(gate equivalent,ge)”数。因此,例如,“与非”门具有ge=1,而“异或”门具有ge=2.33。ge的相对数量取决于所使用的特定asic工艺技术,以及所需的来自门的驱动强度。我们使用了从samsung的std90/mdl90 0.35μm 3.3v cmos技术[sam00]获得的ge值。有关我们针对电路比较的选择的全面讨论可在附录a中找到。此外,我们提出对根据“异或”门的延迟来归一化的电路的技术深度进行计数,这使得比较各种学术成果的深度和速度成为可能。
[0241]
在以下公开中,呈现并分析了使线性矩阵的电路实现最小化的各种新技术。此外,还引入了一种在最小化中包含多路复用器的新方法,此方法与组合sbox构造相关。此外,还提供了一种新架构,其中移除了底部线性矩阵(存在于传统电路中)以获得尽可能小的电路深度。这些新技术导致比先前提出的aes sbox更小和更快的aes sbox。
[0242]
2 预备知识
[0243]
当我们现在构造自己的塔域表示时,将遵循[can05]和[bp12]中使用的记法。不可约多项式、根和正规基见表1。
[0244]
表1:用于构造gf(28)的子域的定义。
[0245][0246]
遵循[can05]和[bp12],现在可以导出如下对gf(28)中的通用元素a=a0y+a1y
16
求逆的表达式:
[0247]
a
‑1=(aa
16
)
‑1a
16
[0248]
=((a0y+a1y
16
)(a1y+a0y
16
))
‑1(a1y+a0y
16
)
[0249]
=((a
20
+a
21
)y
17
+a0a1(y2+y
32
))
‑1(a1y+a0y
16
)
[0250]
=((a0+a1)2y
17
+a0a1(y+y
16
)2)
‑1(a1y+a0y
16
)
[0251]
=((a0+a1)2wz+a0a1)
‑1(a1y+a0y
16
)。
[0252]
gf(28)中的元素求逆可以根据下式在gf(24)中完成:
[0253]
t1=(a0+a1)t2=(wz)t
21
t3=a0a1t4=t2+t3[0254]
t5=t4‑1t6=t5a1t7=t5a0[0255]
其中得到的结果为a
‑1=t6y+t7y
16
。在这些方程中,使用了几种运算(加法、乘法、缩放、以及平方),但其中只有两种在gf(2)上是非线性的;乘法和求逆。此外,标准乘法运算还包含一些线性运算。如果将所有线性运算与非线性运算分离,并将它们与对aessbox输入(使用aessbox不可约多项式x8+x4+x3+x+1以多项式基表示)进行基转换所需的线性方程捆绑在一起,则最终得到根据图2的sbox的架构。
[0256]
如果正在处理逆向sbox,则自然需要将逆向仿射变换应用于顶部线性矩阵而不是底部线性矩阵。
[0257]
此架构将是我们的起点,现在提供一组新的或增强的算法以用于最小化两个线性顶部和底部矩阵的面积和深度两者。
[0258]
3用于二元线性方程组的电路
[0259]
在本节中,我们将概括已知的线性电路最小化技术并提出一些改进。我们首先明确声明目标。
[0260]
3.1基本问题陈述
[0261]
给定一个二元矩阵m
m
×
n
和最大允许深度maxd,找到深度d≤maxd的电路,其中“异或”门的数量最少,以使得它计算y=m
·
x。换句话说,给定n位输入x=(x0...x
n
‑1),该电路应计算m个线性组合y=(y0...y
m
‑1)。实现给定线性方程组的任何电路实现都被称为解。
[0262]
上面的问题是np完全问题,我们已经看到了各种启发式方法,这些方法有助于在文献中找到次优解。在我们之前研究过的所有工作中,假设所有输入信号在同一时间到达,并且所有输出信号均“就绪”,延迟最多为maxd。在本文中,我们用如下定义的air和aor来扩展问题。
[0263]
附加输入要求(air)。该问题可以通过对输入信号x的附加要求来扩展,使得每个输入位x
i
以它自己的延迟d
i
(就“异或”门延迟而言)到达。得到的深度d≤maxd则包括输入延
迟。例如,如果某个输入x
i
具有延迟d
i
>maxd,则不存在解。air在导出底部矩阵时很有用,如第2节所述,因为在非线性部分之后,进入底部矩阵的信号将具有不同的延迟。
[0264]
附加输出要求(aor)。该问题可以通过对输出信号的附加要求来扩展。可以要求每个输出信号y
i
在最多为e
i
≤maxd的深度处“就绪”。当某些输出信号继续在关键路径中传播而其他信号可能以更大延迟(但最多仍为maxd)计算时,这很有用。如第2节所述,在推导顶部矩阵时使用aor,因为当我们为组合sbox引入多路复用器时,将要求顶部矩阵的输出信号具有不同的延迟。
[0265]
3.2 无消除启发法(cancellation
‑
free heuristics)
[0266]
无消除启发法是一种产生线性表达式z=a
⊕
b的算法,其中a和b均为输入变量中的布尔线性表达式,并且a和b没有公共项。换句话说,当添加a和b时,不会消除任何项。
[0267]
paar发表的[paa97]提出了一种求解3.1中的基本问题的贪婪法。该解以矩阵m开始并考虑m中的所有列对(i,j)。然后(在列对上)将度量定义为行数,其中m
r,i
=m
r,j
=1,即,输入变量x
i
和x
j
都出现。对于具有最高度量的列对,形成一个新的变量x
n
=x
i
⊕
x
j
并将其添加到矩阵(矩阵现在大小为m
×
(n+1)),并设置位置m
r,i
=m
r,j
=0,且m
r,n+1
=1。
[0268]
另外,canright发表的[can05]使用了这种技术,但他没有使用度量函数,而是对所有可能的列对执行了穷举算法。这是可能的,因为在他的情况下,目标矩阵是大小仅为8
×
8的基本转换矩阵。如我们在第2节中看到的,我们的底部矩阵会大得多,因此需要采取另一种方法。我们还需要考虑air和aor。
[0269]
求解air。在执行该算法时,应跟踪新添加的“异或”门的深度。这是通过具有向量d=(d0...d
n
‑1)来完成的,其中该向量具有所有输入和新添加的信号x
i
的当前深度。当添加新信号x
n
=x
i
⊕
x
j
时,x
n
的延迟微不足道地为d
n
=max(d
i
,d
j
)+1。然后,我们也限制算法,以使得如果d
n
>maxd,则不允许添加x
n
作为新输入信号。air由此被自动求解。
[0270]
求解aor。类似地,当添加新的输入变量x
n
时,需要检查解在理论上是否可能。可以使用函数circuitdepth(详见附录b.1中的算法2)来做到这一点。如果circuitdepth返回比e
i
更大的延迟,则我们知道不存在解,并且应避免该特定的x
n
。
[0271]
概率启发式方法。由于底部矩阵的大小,我们无法对底部矩阵执行完全穷举算法,因此需要限制要保留的对数并进一步求值。我们已发现保留k个最佳候选(基于paar的原始度量),然后随机选择为下一个“异或”门选取哪一个候选是一种良好的策略。在我们的模拟中,这种概率方法为我们提供了比仅考虑最佳度量候选更小的电路。自然地,如果选择太大的k,则执行时间太长,相反,如果选择太小的k,则会减小导出良好电路的机会。在实践中,我们发现k=2...6是一个要保留和尝试的合理候选数量。
[0272]
3.3 可消除启发法
[0273]
无消除方法是次优的,如在boyar和peralta发表的[bp10a]中所示,其中他们还引入一种可消除的新算法。此算法随后由reyhani等人在[rmta18a]中进行了改进。接下来简要描述该启发法的基本思路。
[0274]
3.3.1 基本可消除算法[bp10a]
[0275]
m的每一行是一个包括0和1的n位向量。该向量可以被看作n位整数值。将该整数值定义为目标点。因此,矩阵m可以看作m个目标点的列向量。输入信号{x0,...,x
n
‑1}也可以表示为整数值x
i
=2
i
,其中i=0...n
‑
1。
[0276]
设基本集s={s0,...,s
n
‑1}={1,2,4,...,2
n
}初始表示输入信号。该算法的关键函数是距离函数δ
i
(s,y
i
),此函数返回根据已知点集s来计算目标点y
i
所需的最小“异或”门数。该算法保留向量δ=[δ0,δ1,...,δ
n
‑1],该向量最初被设置为汉明权重减去m的行中的一个行,其是在没有任何共享的情况下所需的“异或”门数。
[0277]
然后,该算法继续组合基集s中的两个基点s
i
和s
j
,并将它们“异或”在一起,从而产生候选点c=s
i
⊕
s
j
。通过在所有不同的对上的穷举搜索来执行s
i
和s
j
的选择,然后针对每个候选点,计算距离向量∑δ
i
的总和,其中i∈[0,n
‑
1]。注意,现在在集合s∪{c}上计算距离函数δ
i
。选取给出最小距离和的对,并且s被更新为s=s∪{c}。如果存在平局,则该算法选取使欧几里得范数最大化的对。如果在此步骤之后仍然存在平局,则[bp10a]的作者研究了不同的策略并得出所有测试的策略都表现相似的结论,因此可以使用简单的随机选择。然后,该算法重复选取两个新的基点并计算距离向量和的步骤,直到距离向量为全零且找到全部目标为止。在原始描述中,还存在“抢占式”选择的概念。抢占式选择是候选点c,使得该点直接满足矩阵m中的目标行。如果找到这样的候选点,则立即将其用作新的点并将其添加到s。
[0278]
reyhani等人发表的[rmta18a]通过在每一轮中直接搜索抢占式候选并在添加“真实”候选并重新计算距离向量之前将它们全部添加到集合s来改进原始算法。他们还改进了平局解决策略,保留所有在欧几里德范数下同样好的候选,并递归地尝试所有候选,保留在下一轮中最好的候选。在我们的实验中,得出了保留两个不同的候选并递归地计算它们会产生良好结果的结论。
[0279]
我们对该算法的改进是更快地计算中等大小的n值的δ值。见附录b.2。
[0280]
3.3.2 当最大深度maxd是必需约束时
[0281]
虽然air问题可以简单地通过将所有已知信号的延迟d的向量以及s相加来求解,但找到具有固定maxd的短电路的问题仍然相当困难。即使将s中每个新添加的信号限制为深度≤maxd,所得到的电路就“异或”门数而言也非常大,实际上比使用无消除启发法所能实现的要大得多。
[0282]
一种思路是,如果相对于最短距离δ
i
=δ(s,y
i
)存在平局,则应采用具有最小延迟的c。但在我们的模拟中,并没有产生比无消除算法更好的结果,即使为这两种算法添加了随机因子也是如此。我们必须得出对可取消启发式算法采用额外的maxd约束仍然是一个悬而未决的问题的结论。
[0283]
3.4 穷举搜索方法
[0284]
在本节中,我们提出了一种算法,用于对最小电路进行有效的穷举搜索。整体复杂度与输入信号的数量呈指数关系,与输出信号的数量呈线性关系。从我们的实验中可以得出该穷举搜索算法很容易应用于大约10位输入的电路的结论。
[0285]
3.4.1 记法和数据表示
[0286]
使用与第3.3.1节中相同的m的行的整数表示和输入信号x
i
,可以重新表述基本问题陈述:给定输入点x
i
的集合,希望在这些输入点上找到“异或”序列,以便获得具有最大延迟maxd的所有m个希望目标点y
i
、矩阵m的行数。输入和输出点可分别具有不同的延迟d
i
和e
i
。
[0287]
对于数据结构,可以将一组2
n
个点存储为普通集合和/或位向量。该集合允许循环遍历这些点,而位掩码表示对于测试集合成员资格是有效的。
[0288]
3.4.2 基本思路
[0289]
穷举搜索算法是一种递归算法,遍历深度,从深度1开始,一直运行到maxd。在每个深度d处,我们尝试从先前的深度构造新点,从而构造具有准确深度d的电路。当找到所有目标点时,检查所需的“异或”门数,跟踪最小的解。将需要以下点集合:
[0290]
known[maxd+1]
–
特定深度d处的已知点集合。
[0291]
ignore[maxd+1]
–
在深度d处将被忽略的点集合。
[0292]
targets
–
目标点集合。
[0293]
candidates
–
要在当前递归步骤被添加到已知集合的候选点集合。
[0294]
已知点的初始集合为x
i
,其中i=0...n
‑
1,目标点集合为y
i
,其中i=0...m
‑
1。通过最初将输入点x
i
放置到深度d
i
处的已知集合来求解air。aor是通过设置具有输出延迟e
i
的点y
i
以忽略大于e
i
的所有深度级上的清单来求解的。
[0295]
现在将解释在递归的每个深度执行的步骤,假设当前处于深度d。
[0296]
步骤1
–
抢占点。检查known[d]集合以查看是否可以组合任何对(xor:ed)以给出尚未找到的目标点。如果找到所有目标,或者如果已到达maxd,我们就从递归的该深度级返回。
[0297]
步骤2
‑
收集候选。形成来自known[0..d
‑
1]集合的所有可能的点对,其中至少一个点来自known[d
‑
1],并对这些点对进行“异或”以导出新点。如果导出的点在集合ignored[d]中,则跳过该点,否则将该点添加到候选集。
[0298]
步骤3
‑
在这一步中,尝试将候选集合中的点添加到已知清单中,并再次递归地调用该算法。首先尝试添加1个点并进行递归调用。如果这不能求解目标点,则尝试添加2个点,依此类推,直到尝试了候选集合中的点的所有组合(或最大数量的组合)。
[0299]
3.4.3 忽略点及其他优化
[0300]
在步骤2中,对照ignored[d]集合(深度d处的忽略点集合)检查候选。忽略集合是根据一组规则来构造的;相交:如果对于所有目标点w
i
都得到(w
i
&p)≠p,则应忽略候选点p。这意味着点p覆盖了太多的输入变量,并且没有被目标集合中的任何点所覆盖;前向传播:可以计算每个级上所有可能的点,从具有n个已知点的顶层d=0开始一直向下到d=maxd。那些永远不会出现在某个级d上的点然后被包括在ignored[d]集合中。如果某个目标点w具有另一期望最大延迟e
i
<maxd,则应忽略后续深度上的该点,即,将w添加到ignored[e
i
+1..maxd];直接输入求和:如果任何输入信号x
i
,x
j
给出点级d上的点p=x
i
⊕
x
j
,则大于d的所有连续级必须使点p在忽略清单中;后向传播:作为最后一次检查,可以逐层向后,从d=maxd开始,在级d=1结束,对于级d上的每个允许(未被忽略)的点,检查在先前的级上是否还有未被忽略的对a,b(a或b中的一个必须在级d
‑
1上),使得它给出p=a
⊕
b。如果不是,则应将点p添加到ignored[d]集合;忽略候选:如果w是小于d的先前级上的候选之一,则动态地将点w添加到ignored[d]集合。
[0301]
3.5 结论
[0302]
从我们的模拟中,可以得出以下关于搜索最小解的结论;顶部矩阵(只有8个输入)可以用第3.4节中的穷举可消除搜索来求解。底部矩阵(有18个输入)对于直接穷举搜索而
言太大,我们应该从第3.2节中的概率无消除启发法开始,然后针对结束部分使用完全穷举搜索,此时剩余行的汉明权重变得足够小以执行穷举搜索。这种方法显示出最好的结果。
[0303]
4 具有多路复用器的线性电路系统
[0304]
假设要为组合sbox找到一个电路,其中顶部和底部线性矩阵需要基于sbox方向而被多路复用。这意味着用于组合线性表达式的电路的大小基本上增加了一倍,加上一组多路复用器。在本节中,将展示如何处理线性表达式的多路复用系统。将展示“mux”门和“异或”门可以以组合方式被求解,以便实现非常紧凑的电路。
[0305]
4.1 浮动多路复用器
[0306]
考虑到对于某些信号y,必须分别为正向sbox和逆向sbox计算两个线性表达式y
f
和y
i
。然后我们应用一个多路复用器,以便只有其中一个信号继续作为y。进一步假设信号y
f
和y
i
共享表达式的某些部分。然后,更好的是将该共享部分向下推送到多路复用器下方,并且由此生成的解能够被简化。
[0307]
例如,设y
f
=x0⊕
x1和y
i
=x0⊕
x2,则通常应使用2个“异或”门和1个多路复用器,这样得到具有3个门的y=mux(select,x0⊕
x1,x0⊕
x2)。但是,可以将公共部分x0推到多路复用器之后,如下所示:
[0308]
y=mux(select,x1,x2)
⊕
x0,
[0309]
然后,得到一个只有2个门的电路。通常,可以选取输入信号上的任何线性组合δ并进行替换:
[0310]
y=mux(select,y
f
,y
i
)
→
mux(select,y
f
⊕
δ,y
i
⊕
δ)
⊕
δ,
[0311]
其中,δ被添加到线性矩阵中作为要计算的附加目标信号。如果该替换导致更短的电路,则保留该替换。我们还应选择使整体深度不增加的δ。因此,各种多路复用器将在电路的深度上“浮动”。δ≠0的信号的最大深度应减小1。
[0312]
4.1.1 要求解的度量和线性表达式
[0313]
我们具有n个输入信号x1...x
n
和m个输出信号y1...y
m
,其中每个y
i
以其最一般的形式表示为三元组(a
i
,b
i
,c
i
),使得:
[0314]
y
i
=a
i
⊕
mux(select,b
i
,c
i
),
[0315]
其中a
i
、b
i
和c
i
是输入信号上的线性表达式。可以针对任何δ
i
将上述表达式修改为(a
i
⊕
δ
i
,b
i
⊕
δ
i
,c
i
⊕
δ
i
),因为y
i
的布尔函数将不改变。
[0316]
设abc表示描述所有行a
i
、b
i
和c
i
的线性矩阵,其中i=0...m,使得
[0317]
abc
×
x
[0318]
给出要使用最少数量的门和给定maxd实现的期望线性系统。通过选择有利的δ
i
值,可以缩减总门数,因为abc的一些目标点可能变得彼此相等,因此abc可以减少至少一行。此外,一些目标可能变为0或只有一位,即,它们等于相应的输入信号。这些目标也从被线性系统中移除,因为它们是不重要的且成本为零的门。在上述化简之后,得到线性表达式组,其中所有行都是不同的,并且汉明权重至少为2。如先前那样,将abc的行解释为整数,并将δ
i
添加(xor:ing)到三行a
i
、b
i
和c
i
将改变这三个目标点,但不改变由此所得到的y
i
。
[0319]
度量.搜索δs的良好组合需要大量计算,并且为每个选择计算最小解很快变得不可行。因此,需要确定一种良好的度量,使我们能够将搜索空间缩减为有希望的δs集合。建议采用基于固定系统的门数下限的度量(当选择δ值时),并将该度量定义为简化后的abc
矩阵的行数,加上完成电路所需的最小数量的额外门,例如多路复用器。
[0320]
在下文中,我们将介绍几种启发式方法,以在最小化度量的同时找到良好的δs集合。
[0321]
4.1.2 寻找δs的迭代算法:度量
→
最小化
[0322]
以下技术仅适用于小的n,但在我们的例子中,它很容易适用于aes sbox的8输入顶部矩阵。
[0323]
算法
‑
a(k)
–
选择k个三元组(a
i
,b
i
,c
i
)并尝试找到最小化度量的匹配δ
i
s。如果某些选择导致较小的度量,则保留该选择并继续用更新后的abc矩阵进行搜索。该算法循环运行,直到度量不再减小。算法
‑
a(1)相当快,算法
‑
a(2)也有可接受的速度。对于较大的k,它变得不可行。算法
‑
a(k)很适合对给定系统进行非常快速/简短的分析,但结果很不稳定,因为对于δ
i
s的随机初始值,得到的度量波动很大。
[0324]
算法
‑
b
‑
与算法
‑
a不同,该算法尝试构造线性表达式组,从一个空的已知集合s开始,然后尝试逐一向s添加新点,直到abc的所有目标都变得被包括在集合s中。在测试新的候选c是否应被添加到s时,循环遍历所有(a
i
,b
i
,c
i
)并针对每一者尝试找到最小化整体度量的δ
i
。这种启发式算法稳定得多并且给出了相当好的结果。
[0325]
但是最小可能的度量并不保证最终的解将具有最少数量的门,并且所需的非目标中间体的数量不明。因此,好的构思是收集许多其度量尽可能最小的有希望的系统,然后尝试在它们之中找到最小的解。我们将在下一节对此进行研究。
[0326]
4.2 用于具有浮动多路复用器的线性系统的新通用启发式技术
[0327]
如果推广浮动多路复用器的思路,让它们在电路中浮动得甚至更高,并且还更广泛地共享它们,则可以获得更好的结果。在本节中,提出了一种针对此类系统寻找近最佳电路的通用启发式算法。
[0328]
4.2.1 问题陈述
[0329]
给定n位输入信号x
n
、二元矩阵和二元向量和向量延迟d
nx
和d
my
。希望找到计算m位输出信号y的最小和最短的解:
[0330]
y
f
=m
f
·
(x
⊕
a
f
)
[0331]
y
i
=m
i
·
(x
⊕
a
i
)
[0332]
y=mux(zf;y
f
⊕
b
f
;y
i
⊕
b
i
),
[0333]
其中,每个输入信号x
i
具有输入到达延迟d
ix
并且每个输出信号y
j
必须具有最多d
jy
的总延迟。a*和b*分别是用于输入信号和输出信号的恒定掩蔽向量(“非”门)。zf是多路复用选择器,当zf=1时,选取第一(y
f
=“正向”)输出,否则选取第二(y
i
=“逆向”)输出。还假设存在也可用作输入控制信号的补码信号zi=zf
⊕
1。
[0334]
4.2.2 预备知识
[0335]
与先前的记法类似,将“点”定义为点值(.p)和延迟(.d)的元组:
[0336]
point:={.p=[f(1bit)|f(n bits)|i(1bit)|i(n bits)],.d=delay}
[0337]
其然后被转换成1位信号电路
[0338]
signal:=mux(zf;f
·
x
⊕
f;i
·
x
⊕
i)
[0339]
并且具有总输出延迟点.d。即,f和i是n位输入x上的线性组合,f和i是在选择器分别为“正向”或“逆向”的情况下应用于结果的取反位。然后n个输入点被表示为:
[0340]
输入点x
k
:={.p=[a
kf
|2
k
|a
ki
|2
k
],.d=d
kx
},其中k=0,...,n
‑
1,
[0341]
而m个目标点为:
[0342]
目标点y
k
:={.p=[b
kf
|y
kf
|b
ki
|y
ki
],.d=≤d
ky
},其中k=0,...,m
‑
1。
[0343]
还应在输入集中包含以下4个不重要的点:
[0344]
信号zf:={.p=[1|0|0|0],.d=0}信号0:={.p=[0|0|0|0],.d=0}
[0345]
信号zi:={.p=[0|0|1|0],.d=0}信号1:={.p=[1|0|1|0],.d=0}
[0346]
给定任意两个(有序)点v和w,最多存在6个可基于以下门来生成的可能的新点:
[0347]
mux(v;w):={.p=[v.f|v.f|w.i|w.i],.d=d
new
}
[0348]
nmux(v;w):={.p=[v.f
⊕
1|v.f|w.i
⊕
1|w.i],.d=d
new
}
[0349]
mux(w;v):={.p=[w.f|w.f|v.i|v.i],.d=d
new
}
[0350]
nmux(w;v):={.p=[w.f
⊕
1|w.f|v.i
⊕
1|v.i],.d=d
new
}
[0351]
xor(v;w):={.p=[w.f
⊕
v.f|w.f
⊕
v.f|w.i
⊕
v.i|w.i
⊕
v.i],.d=d
new
}
[0352]
nxor(v;w):={.p=[w.f
⊕
v.f
⊕
1|w.f
⊕
v.f|w.i
⊕
v.i
⊕
1|w.i
⊕
v.i],.d=d
new
}
[0353]
其中d
new
=max{v.d,w.d}+1。注意,包含4个不重要的点很重要,因为这样能够限制要被考虑的门类型的数量。例如,然后“非”门被实现为xor(v;1),具有zf的“与”门可以被实现为mux(v;0),具有zi的“或”门是mux(v;1)等等。
[0354]
4.2.3算法
[0355]
我们从输入点集合s(大小为n+4)开始,并将所有目标点放入集合t。在每一步,计算通过将上述6个门应用于集合s中的任意两个点而生成的候选点集合c。自然地,c应只包含唯一的点并排除那些已经在s中的点。我们尝试将c中的一个候选点添加到s,并计算从s到t中的每个目标点的距离。此后,比较度量来决定哪个候选点将在该步骤被包括在s中,以及通过计算可能的候选来重新开始。当总距离δ
‑
度量为0时,算法停止。
[0356]
度量包括多个值。距离δ(s,t
i
)是从s中的点获取目标点t
i
所需的最小基本门数(上述6个),以使得延迟最多为d
iy
。第4.2.5子节讨论了如何计算δ(s,t
i
)。所应用的度量及其重要性顺序如下:
[0357][0358][0359]
τ=来自c的最新候选点添加到s的延迟
→
min
[0360][0361]
度量γ是在没有更多共享门的情况下的预计门数;绝对应最小化该度量。如果有多个候选给出相同的值,则研究第二度量δ。
[0362]
δ是距离之和,不包括只需要1个门的距离。给定最小γ的情况下,必须最大化δ。δ越大,缩小γ的机会就越多。由于包含将在下面描述的抢占步骤,因此排除了距离1。如上所述,当逐一将候选接受到s时,度量δ和γ是相似的,但是当在下一小节中引入其中|s|的大
小可能不同的搜索树时,这两个度量将变得不同。
[0363]
τ在上述两个度量针对两个候选显示相同值的情况下选择具有最小深度的候选。如果对目标点没有最大深度约束,则不需要此度量。
[0364]
ν是不包括抢占点的欧几里得范数(类似于δ)。这是最后一个决策度量,因为它不是一个很好的预测器,较差的值可能会给出较好的结果,反之亦然。然而,如果存在具有相等度量δ、γ和τ的两个候选,则可以基于ν对这两个候选进行排序。在出现并列候选的情况下,替代的方法是随机选择其中一个。
[0365]
抢先点.如果某个距离δ(s,t
i
)=1,则立即将该点t
i
接受到s中而无需搜索整个候选c。在算法中包含这一步迫使从度量δ和ν中排除这样的点。
[0366]
在[rmta18a]中,抢占点被包括在度量中,我们认为这是不正确的。例如,当两个距离向量{1,2,...}和{0,2,...}具有相同的预计门时,它们在可能的共享门方面表现出完全相同的情况,并且它们应导致相同的δ,因为距离1将立即被包括在内(抢占点),所以它不会比具有距离0的第二选择有任何优势。因此,距离1不应被计入δ和μ,而是被计入预计门γ中。
[0367]
4.2.4 搜索树
[0368]
除了上述算法之外,我们还提出了搜索树,其中每个节点都是一个具有度量的集合s。这种节点的子代也是节点,其中s'是通过添加其中一个候选点(s
←
c)从s导出的。因此,从根节点到叶的每条路径都表示到根集合s的一系列接受的候选点。如果在某个点,叶具有度量δ=0,则该叶表示可能的解路径。
[0369]
我们保留一些子节点(在实验中,保留至少20
‑
50个最佳子节点),它们的度量是最佳的(它们甚至可能具有不同的预计门γ)。还定义了搜索树的最大深度td(在实验中,尝试了td=1..20)。当在深度td处构造树时,我们检查叶并查看在所有不同分支的所有叶上获得最佳度量的位置。回溯到根,然后选择保留通向最佳叶的顶部分支。移除来自根的其他顶部分支。然后,将根节点推进到选定分支的第一子节点,并尝试从剩余的叶再次延伸树的深度,从而使搜索树保持恒定的深度td。
[0370]
如果在树的每个深度,每个叶都扩展了额外的20
‑
50个子分支,则叶的数量将呈指数增长。但是,可以在将树延伸到下一深度之前对叶应用截断算法。只保留不超过一定数量的有希望的叶,这些叶将延伸到下一深度,而从树中删除其他不太有希望的叶(在我们的实验中,整棵树的截断级别高达400片叶)。这种类型的截断使得可以通过基本在任何深度td处“进一步观察”来选择根节点的最佳顶部分支。值得注意的是,复杂度不取决于深度td,而是取决于截断级别。
[0371]
截断策略.简而言之,我们保留那些具有最佳度量的叶,但尝试在不同分支当中分配近乎相等的叶,以便保留尽可能多的转移解路径(diverted solution paths)。
[0372]
4.2.5 δ(s,t
i
)的计算
[0373]
算法的“核心”和关键部分是计算距离δ(s,t
i
)的算法,前提是给出全新的s。每一步有很多候选要测试,并且有很多分支要跟踪,所以需要使这个核心算法尽可能快。
[0374]
注意,点的长度(.p是整数)是2n+2位,加上延迟值。在对两个点进行布尔运算时,将忽略延迟(.d)值。设分配以下可能的点数:
[0375]
n=2
2n+2
。
[0376]
设v
k
[]是长度为n个单元的向量,每个单元v
k
[p]对应于一个表示为整数索引的(2n+2)位点p,该单元中存储的值将是该点的最小延迟p.d,使得它可以从恰好具有k个门的s中来导出。
[0377]
如果p∈s,设置初始向量v0为否则,v0[p]=∞。此后,通过将允许的6个门应用于来自某个级0≤l<k(v
l
)和级k
‑
l(v
k
‑
l
)的点,从先前导出的向量v0...v
k
推导出向量v
k+1
,从而产生总共l+(k
‑
l)+1=k+1个门。在推导出新的v
k+1
之后,简单地检查它是否包含来自t的目标的新距离值,重复该过程直到找到t中所有t
i
的所有距离δ(s,t
i
)。算法1中给出了该算法的高级描述,在附录b.3中,提供了更详细的描述以及可以运用的多种计算技巧。
[0378][0379]
5 架构改进
[0380]
大多数已知的aes sbox架构看起来非常相似,由顶部和底部线性部分以及中间非线性部分组成,如前面第2节所述。在本节中,我们采用经典设计并提出了一些改进,同时采用专注于低深度解的全新架构。
[0381]
5.1 两种sbox架构
‑
面积和深度
[0382]
参考图2,架构a(面积)是实现基于塔和复合域设计的经典架构。它从到顶部线性矩阵的8位输入信号u开始,该顶部线性矩阵产生22位信号q(参见[bp12])。我们设法将所需q信号的数量简化为18个,并将乘法和线性求和框mul
‑
sum重构为24个门和深度3。(有关方程式,参见附录d.2)。mul
‑
sum框的输出是4位信号x,它是到gf(24)上的逆的输入。来自逆的输出y与在顶部矩阵中导出的q信号非线性混合,并产生18位信号n。最后一步是底部线性矩阵,它取18位n,并且线性地导出输出8
‑
位信号r。顶部和底部矩阵引入了取决于方向的sbox仿射变换。新架构d(深度)(如图3a和3b所示)是一种其中尝试移除底部矩阵并且从而尽可
能缩小电路深度的新架构。背后的思路是底部矩阵只取决于4位信号y以及8位输入u的一些线性组合的乘法集。因此,结果r可以实现如下:
[0383]
r=y0·
m0·
u
⊕
...
⊕
y3·
m3·
u,
[0384]
其中,每个m
i
是8
×
8矩阵,表示8位输入u上的8个线性方程,其将被与y
i
位进行标量相乘。与用于4位y的电路并行地,这些4
×
8线性电路可以被计算为32位信号l。结果r是通过将四个8位子结果相加得到的。因此,在架构d中,在求逆步骤(关键路径:mull和8xor4框)之后得到深度3,而不是架构a中的深度5
‑
6。新架构d需要略多的门,因为组装底部电路需要56个门:32nand2+8xor4。奖励是较低的深度。
[0385]
图4和图5分别给出了两种架构的更详细草图,其中包括设计的组件、延迟、以及门数。
[0386]
5.2 muln的六种不同场景
[0387]
在计算18位n信号的muln框中,需要作为输入的18位q信号和求逆结果y。但还需要y的以下附加线性组合:y
02
=y0⊕
y2、y
13
=y1⊕
y3、y
23
=y2⊕
y3、y
01
=y0⊕
y1、y
00
=y
01
⊕
y
23
—这些对应于[bp12]中的信号m41
‑
m45。因此,y向量实际上扩展到9位,并且n位的延迟变得不同,具体取决于在乘法中使用哪一个y
i
。例如,在最坏情况下,与y1的延迟相比,y
00
的延迟是+2。因此,得到的信号n将具有不同的输出延迟。然而,可以与基信号y0,...,y3并行地计算这5个额外的y。这将使用一些额外的门,但是+2延迟可以缩减到+1或+0。一般来说,可以考虑以下6种场景:
[0388]
·
s0.只计算基信号y0..y3,剩下的{y
01
,y
23
,y
02
,y
13
,y
00
}如上所述通过“异或”来计算。延迟为+2,但具有最少的门数。
[0389]
·
s1.并行地计算{y
01
,y
23
},延迟为+1。
[0390]
·
s2.并行地计算{y
02
,y
13
},延迟为+1。
[0391]
·
s3.并行地计算{y
00
},延迟为+1。
[0392]
·
s4.并行地计算{y
01
,y
23
,y
02
,y
13
},延迟为+1。
[0393]
·
s5.并行地计算{y
01
,y
23
,y
02
,y
13
,y
00
},延迟为+0,因为之后没有要计算的信号。
[0394]
在下一小节中,将展示如何找到上述场景的布尔表达式。
[0395]
5.3 inv.gf(24)上的求逆
[0396]
求逆公式如下:
[0397]
y0=x1x2x3⊕
x0x2⊕
x1x2⊕
x2⊕
x3[0398]
y1=x0x2x3⊕
x0x2⊕
x1x2⊕
x1x3⊕
x3[0399]
y2=x0x1x3⊕
x0x2⊕
x0x3⊕
x0⊕
x1[0400]
y3=x0x1x2⊕
x0x2⊕
x0x3⊕
x1x3⊕
x1[0401]
在[bp12]中,发现了深度为4和17个“异或”的电路,但我们希望通过使用更广泛的标准门来进一步缩小深度。因此,我们使用通用的深度3表达式独立地考虑了每个表达式:
[0402]
y
i
=((x
a op
1 x
b
)op5(x
c op
2 x
d
))op7((x
e op
3 x
f
)op6(x
g op
4 x
h
)),
[0403]
其中x
a
‑
h
是来自{0,1,x0,x1,x2,x3}的项,op1‑7是来自标准门集合{and,or,xor,nand,nor,xnor}的运算符。注意,上面不需要包含所有项,例如,表达式and
(x,x)
就是简单的x。
[0404]
可以按如下方式组织穷举搜索。设具有对象term,它包含长度为16位的真值表tt,
基于4个位x0..x3,以及与该项相关联的布尔函数。从可用项的初始集合t
(0)
={0,1,x0,...,x3}开始,然后迭代地为选定的y
i
构造表达式。假设在某个步骤k具有可用项集合t
(k)
,则可以如下获得下一个项集合和相关联的表达式:
[0405]
t
(k+1)
={t
(k)
,t
(k)
operator t
(k)
},
[0406]
其中考虑唯一的项。在某个步骤k,将得到其tt等于目标tt(y
i
)的一个或多个项。
[0407]
由于实际上可以针对每个y
i
得到多个布尔函数,因此应只选择遵循以下标准的“最佳”函数:没有“非”门(由于更好的共享能力),存在可以在y0..y3的4个表达式之间共享的最大门数,ge方面的面积/深度很小。
[0408]
使用这种技术,我们为求逆找到了深度3、15个门的解。下面给出了方程式,其中还为额外的5个信号{y
01
,y
23
,y
02
,y
13
,y
00
}提供了深度3的解,以便它们在提到的场景s0
‑
s5中也可以共享很多门。
[0409][0410]
在为场景s0
‑
s5实现上述电路并以最佳可能的方式共享门时,获得以下结果:
[0411]
表2:场景s0
‑
s5的inv框。
[0412][0413]
在我们的最佳电路中使用了场景s1,因为它在面积和深度方面显示了最佳结果。对于快速和奖励电路,使用了s0,因为它的面积最小。
[0414]
5.4 用于顶部和底部线性矩阵的alpha
‑
beta方法
[0415]
我们正在使用穷举搜索求解顶部矩阵,以及使用各种启发式技术求解底部矩阵。这些矩阵的外观自然会影响解中的最终门数。在此,我们提出了一种简单的方法来尝试不同的顶部和底部矩阵以获得最佳解。
[0416]
假设sbox是一个黑盒并且它执行函数(不包括常数的最后添加):
[0417]
sbox(x)=x
‑1·
a8×8,
[0418]
其中x
‑1是rijndael域gf(28)中的逆元素,矩阵a8×8是仿射变换。在特征2的任何域中:平方、平方根和乘以常数均为线性函数,因此对于不重要的选择(α,β),设:
[0419][0420][0421]
如果正向sbox和逆向sbox的初始顶部和底部矩阵分别为t
f
、b
f
、t
i
、f
i
,则可以选择任意α=1..255和β=0..7,并按如下方式变换矩阵:
[0422]
t'
f
=t
f
·
e
·
c
α
·
p
β
·
e
[0423]
b'
f
=e
·
a
·
p
β
‑1·
c
α
·
a
‑1·
e
·
b
f
[0424]
t'
i
=t
i
·
e
·
a
·
c
α
·
p
β
·
a
‑1·
e
[0425]
b'
i
=e
·
p
β
‑1·
c
α
·
e
·
b
i
,
[0426]
其中:
[0427]
e
–
是切换位字节序的8
×
8矩阵(在我们的电路中,输入和输出位采用大端序)
[0428]
a
–
是执行sbox的仿射变换的8
×
8矩阵
[0429]
c
α
–
是用选定常数α乘以域元素的8
×
8矩阵
[0430]
p
β
–
是将rijndael域的元素提升到2
β
次幂的8
×
8矩阵
[0431]
t
f
/t
i
–
分别是正向/逆向sbox的顶部线性变换的原始(未经修改)18
×
8矩阵。
[0432]
b
f
/b
i
–
分别是正向/逆向sbox的底部线性变换的原始(未经修改)8
×
18矩阵。
[0433]
(α,β)对存在2040种选择,每种选择都给出新的线性矩阵。很容易测试所有这些选择并找到给出最小sbox电路的最佳组合。对于架构a和d,已将此思路应用于正向sbox和逆向sbox两者。
[0434]
5.4.1 用于组合sbox的alpha
‑
beta方法
[0435]
对于组合sbox,可以独立地将alpha
‑
beta方法应用于正向和逆向部分。这意味着有20402=4,161,600个线性矩阵变体要测试。我们专注于架构d,因为没有底部矩阵,因此可以进行更广泛的搜索。我们搜索了所有这400万个变体,并应用第4.1节中的启发式算法作为快速分析方法来选择大约4000个有希望的例子的集合。然后,应用第4.2节中给出的算法来寻找具有浮动多路复用器的解。在我们的例子中具有n=8位输入,因此每个点都用18位编码,计算距离δ(s,t
i
)的复杂度是n=2
18
个点的二次方。在搜索中使用了最大深度td≤20且截断级别为400个叶的搜索树。
[0436]
5.5 组合sbox中的顶部矩阵的q零点
[0437]
组合sbox需要具有多个用于顶部和底部线性变换两者的多路复用。正向sbox和逆向sbox的顶部线性矩阵分别产生18位信号q
f
和q
i
。这意味着通常应当应用18个多路复用器以基于选定的方向信号zf而在q信号之间切换。但是,存在一组始终为零的q三元组,它们对正向sbox和逆向sbox均有效:
[0438]
0=q0+q11+q12
ꢀꢀ
0=q1+q3+q4
ꢀꢀ
0=q4+q9+q10
ꢀꢀꢀ
0=q6+q7+q10
[0439]
0=q0+q14+q15
ꢀꢀ
0=q2+q8+q9
ꢀꢀ
0=q5+q12+q13
ꢀꢀ
0=q11+q16+q17
[0440]
0=q1+q2+q7
ꢀꢀꢀꢀ
0=q3+q6+q8
ꢀꢀ
0=q5+q15+q17
ꢀꢀ
0=q13+q14+q16
[0441]
清单1:q零点,对正向sbox和逆向sbox均有效。
[0442]
可以使用该知识来仅计算q信号的子集,然后对它们进行多路复用并使用上述零
点计算剩余的q信号。
[0443]
例如,可以针对正向sbox和逆向sbox计算10个位:{q1,q6,q8,q9,q10,q12,q14,q15,q16,q17},然后应用10个多路复用器,之后,推导出剩余的8个信号:q0=q14+q15、q2=q8+q9、q3=q6+q8、q4=q9+q10、q5=q15+q17、q7=q6+q10、q11=q16+q17、q13=q14+q16。
[0444]
因此,能够节省8个多路复用器,以及能够删除组合顶部矩阵的2
×
8个行。但是,应确保在多路复用器之外免除上述8位不会增加顶部线性变换的深度。注意,上面示例中的一些信号q1和q12不参与计算最后8个信号,因此这两个信号被允许具有+1额外深度。即,在应用电路求解器算法之前,应仔细推导出每个输出信号的最大延迟以作为搜索算法的约束。
[0445]
除了(α,β)的上面提到的2040种选择之外,还测试了59535种利用q零点的变体。我们仅将此方法应用于架构a。
[0446]
6 结果与比较
[0447]
在本节中,将提供针对正向aes sbox和组合aes sbox的最佳解。单独的求逆sbox可能没有被广泛使用,这些结果可以在附录c中找到。我们使用附录a中描述的技术比较了我们的面积和深度,并在可能的情况下,重新计算了其他学术成果的相应ge以便于比较。为每个sbox(正向、逆向、以及组合)提供三种不同的解:“快速”、“最佳”和“奖励”。快速解是具有最低关键路径的解,最佳解是面积与速度之间良好平衡的权衡,给出奖励解以在最小门数方面建立新的纪录。可以在附录d中找到所有导出的解的确切电路表达式,该附录还指出了在导出解时使用了哪种算法。
[0448]
6.0.1 合成结果
[0449]
已经对结果进行了合成,并与其他最近的学术工作进行了比较。技术工艺为globalfoundries 22nm csc20l[glo19],并且已使用拓扑模式下synopsys的design compiler 2017和compile_ultra命令执行了合成。此外,开启标志compile_timing_high_effort以强制编译器产生尽可能快的电路。在这些图中,x轴是时钟周期(以ps为单位),y轴是得到的拓扑估计面积(以μm2为单位)。可用门数不受任何限制,因此编译器可以自由使用非标准门,例如3输入“与
‑
或”门。为了获得以下小节中的图,从1200ps时钟周期(~833mhz)开始,然后时钟周期减少20ps,直到无法满足时序约束为止。注意,编译器的面积估计波动很大,我们认为这是编译器必须最小化深度的许多不同策略的结果。一种策略可能对于比如700ps时钟周期是成功的,但不同的策略(其导致明显更大的面积)可能对于720ps是成功的。编译器的策略还涉及随机性元素。
[0450]
表3:正向sbox:结果比较。
[0451][0452]
正向sbox:先前结果
[0453]
[0454][0455]
正向sbox:我们的结果
[0456][0457]
6.1 正向sbox
[0458]
我们在表3中包含了许多有趣的先前结果以用于比较。canright最著名的设计被广泛使用和引用。我们的最佳sbox既快又小。我们还包括boyar等人所做的工作,因为他们的设计是我们研究的起点。
[0459]
reyhani等人在ches'18公布的两个结果是最新的,就ge而言,我们的“最佳”sbox与他们的“轻量”版本具有相似的面积,但速度快约30%。该最佳sbox比他们的“快速”电路更小且更快。此外,我们的“快速”版本比他们的“快速”版本快25%,同时维持了适当的面积增加。ueno完成的目前最快的sbox具有286ge和深度13.772xor,而我们的快速版本只有248ge和深度10.597xor,比已知的最快电路性能高出约23%。
[0460]
我们还包括了boyar在2016年完成的当前世界上最小的电路(就标准门而言),它
有113个门(231.29ge)和深度27个门。我们的“奖励”电路甚至更小,只有108个门和深度24,低至200.10ge。合成结果如图6所示。
[0461]
表4:组合sbox:结果比较。
[0462][0463]
组合sbox:先前结果
[0464][0465]
组合sbox:我们的结果
[0466][0467][0468]
6.2 组合sbox
[0469]
表4示出了我们的结果与先前已知的两个最佳结果的比较。我们的最佳组合sbox具有与[can05]和[rmta18b]相似的大小,但速度快很多,因为电路深度低得多。该最佳电路具有深度16(实际上只有14.413xor)和151个门(296ge),而canright的组合sbox的大小为150(+2)个门(298ge),并具有深度30(25.644xor)。本文中的奖励解的深度略小于最新结果[rmta18b],但大小要小得多(133个标准门对149(+8)个标准门)。最后,所提出的使用架构d的“快速”设计具有目前已知的最佳深度,我们还包括了提供图7中的比较所示的最佳合成结果的设计。
[0470]
7 结论
[0471]
在本附录b中,我们介绍了许多启发式和穷举搜索方法以用于最小化aes sbox的电路实现。我们提出了关于如何在最小化算法中包含组合sbox的多路复用器的新思路,并为正向、逆向和组合aes sbox推导出更小并更快的电路实现。我们还引入了一种新架构,在该架构中移除了底部线性矩阵,以便尽可能快地推导出解。
[0472]
参考文献
[0473]
[art01]artisan components,inc.tsmc 0.18μm工艺1.8伏sage
‑
xtm标准基元库数据手册,2001年。网址:www.utdallas.edu。
[0474]
[bfp18]joan boyar、magnus find和ren
éꢀ
peralta。用于加密应用的小型低深度电路。密码学与通信,2018年11月3日。
[0475]
[bhwz94]michael bussieck、hannes hassler、gerhard j.woeginger和uwe t.zimmermann。最大卷积问题的快速算法。oper.res.lett.,15(3):第133
–
141页,1994年4月。网址:citeseerx.ist.psu.edu。
[0476]
[boy]joan boyar。电路最小化工作。网址:www.cs.yale.edu。
[0477]
[bp10a]joan boyar和ren
éꢀ
peralta。应用于密码学的新型组合逻辑最小化技术。paola festa编辑,实验算法,第178
‑
189页,柏林,海德堡,2010年。springer berlin heidelberg。网址:eprint.iacr.org。
[0478]
[bp10b]joan boyar和ren
éꢀ
peralta。应用于密码学的新型组合逻辑最小化技术。计算机科学讲义,第178
‑
189页。springer,2010年。
[0479]
[bp12]joan boyar和ren
éꢀ
peralta。用于aes s
‑
box的小深度
‑
16电路。dimitris gritzalis、steven furnell和marianthi theoharidou编辑,sec,ifip信息和通信技术进展,第376卷,第287
‑
298页。springer,2012年。网址:link.springer.com。1007/978
‑3‑
642
‑
30436
‑
1_24。
[0480]
[bus01]business machines corporation。asic sa
‑
27e数据手册,第1部分:基础库和i/o数据手册,2001年。网址:people.csail.mit.edu。
[0481]
[can05]d.canright。用于aes的极紧凑s
‑
box。josyula r.rao和berk sunar编辑,加密硬件与嵌入系统
‑
ches 2005,第441
‑
455页,柏林,海德堡,2005年。springer berlin heidelberg。网址:www.iacr.org。
[0482]
[far06]faraday technology co.fsd0a_a 90nm logic sp
‑
rvt(低k)工艺,2006年。网址:www.cl.cam.ac.uk。
[0483]
[glo19]globalfoundries。22nm fdx工艺,2019年。网址:www.globalfoundries.com。
[0484]
[it88]toshiya itoh和shigeo tsujii。使用正规基计算gf(2m)乘法逆的快速算法。inf.comput.,78(3):第171
‑
177页,1988年9月。网址:dx.doi.org。
[0485]
[jkl10]yong
‑
sung jeon、young
‑
jin kim和dong
‑
ho lee。使用资源共享方法的aes算法的紧凑型无内存架构。电路、系统和计算机杂志,19:第1109
‑
1130页,2010年。
[0486]
[mng00]microelectronics group、carl f.nielsen和samuel r.girgis。wpi 0.5mm cmos标准基元库数据手册,2000年。网址:lsm.epfl.ch。
[0487]
[nnt+10]yasuyukinogami、kenta nekado、tetsumi toyota、naoto hongo和
yoshitaka morikawa。用于f((22)2)2中有效求逆的混合基和aes子字节的转换矩阵。第234
‑
247页,2010年8月。
[0488]
[ost01]美国国家标准与技术研究院。高级加密标准。nist fips pub 197,2001年。
[0489]
[paa97]christof paar。reed
‑
solomon编码器的优化算法。1997年4月。
[0490]
[pet]graham petley。互联网资源:vlsi和asic技术标准基元库设计。网址:www.vlsitechnology.org。
[0491]
[rij00]vincent rijmen。rijndael s
‑
box的有效实现。2000年。网址:www.researchgate.net。
[0492]
[rmta18a]arashreyhani
‑
masoleh、mostafa taha和doaa ashmawy。粉碎aes s
‑
box的实现记录。加密硬件和嵌入式系统上的iacr交易,2018(2):第298
–
336页,2018年5月。
[0493]
[rmta18b]arashreyhani
‑
masoleh、mostafa m.i.taha和doaa ashmawy。aes组合s
‑
box/逆向s
‑
box的新面积纪录。2018年ieee第25届计算机算术研讨会(arith),第145
‑
152页,2018年。
[0494]
[sam00]samsung electronics co.,ltd.。纯逻辑/mdl产品数据手册的std90/mdl90 0.35μm 3.3v cmos标准基元库,2000年,网址:www.digchip.com
[0495]
[smtm01]akashi satoh、sumio morioka、kohji takano和seiji munetoh。s
‑
box优化的紧凑型rijndael硬件架构。colin boyd编辑,asiacrypt,计算机科学讲义,第2248卷,第239
‑
254页。springer,2001年,网址:antoanthongtin.vn。
[0496]
[uhs+15]rei ueno、naofumi homma、yukihiro sugawara、yasuyuki nogami和takafumi aoki。基于冗余gf算法的高效gf(28)求逆电路及其在aes设计中的应用。iacr cryptology eprint archive,2015:763,2015年。网址:eprint.iacr.org。
[0497]
本公开的部分b的附录
[0498]
a 面积和速度测量方法
[0499]
首先,我们介绍一些记法。门的名称以大写字母gate书写(例如:and、or)。记法mgaten表示类型为gate的m个门,每个门有n个输入(例如:xor4、8xor4、nand3、2and2)。当输入数n缺失时,假设门具有最小输入数,通常只有2(mux为3)。
[0500]
被构造为门组合的基元可以被描述为gates1
‑
gate2,这意味着首先在第一级gates1上执行一个或多个门,然后结果进入第二级2上的门。示例:nand2
‑
nor2,表示单元有3个输入(a、b、c),对应的布尔函数为nor2(a,nand2(b,c))。
[0501]
提出了两种不同的电路比较方法;标准方法和技术方法。
[0502]
a.1 标准方法
[0503]
基元.标准方法中考虑的基本元素是:{xor、xnor、and、nand、or、nor、mux、nmux、not}。
[0504]“非”not门的协商。在电路的某些位置,需要使用信号的反相版本。这可以通过多种方法实现而无需显式使用not门。这里列出了其中的一些。
[0505]
方法1.实现not门的一种方法是更改生成该信号的前一个门以替代地产生反相信号。例如,将“异或”xor切换成“同或”xnor,将“与”and切换成“与非”nand等。
[0506]
方法2.在多种技术中,有些门可以产生直接信号和反相版本。例如,许多实现中的
xor门同时产生这两种信号,因此反相值是可用的。
[0507]
方法3.可以更改在反相信号之后的门,以使得在给定反相输入的情况下,例如使用德摩根定律,所得到的方案将产生正确的结果。
[0508]
综上所述,认为用标准方法对电路求值时可忽略not门;因为这些门几乎不能算作全门。但是,为了完整起见,结果表中包含了not门的数量。
[0509]
面积.针对面积比较,对基本元素的数量进行计数,这些元素之间没有任何大小区别。not门被忽略。
[0510]
深度.深度是根据电路路径上的基本元素的数量来计数的。因此,电路的总深度是关键路径的延迟。not门被忽略。
[0511]
a.2 技术方法
[0512]
基元.一些论文用一些经常在各种方法中可用的额外的组合基元来补充标准基元。例如,门nand2
‑
nand2、nor2
‑
nor2、2and2
‑
nor2、xor4对改进和加速本文中的sbox电路非常有用。但是,为了与先前的学术成果进行比较,我们将保留标准基元集合,以便进行更公平的比较。在这种方法中,我们在延迟和面积两者中对not门进行计数。
[0513]
面积.存在来自不同供应商(英特尔、三星、globalfoundries等)的许多asic技术(90nm、45nm、14nm等),这些技术具有不同的特性。为了开发asic,需要获得特定技术的“标准基元库”,该库通常包含比上面列出的基本元素更多样化的基元,使得设计人员有更广泛的构造块选择。
[0514]
然而,即使考虑标准基元,例如xor,对于不同的技术而言,该基元也具有不同的面积和延迟。这加大了比较由两个学术团体开发的相同逻辑的两个电路(当这些电路选择应用不同的技术时)的难度。
[0515]
为了公平比较学术界各种解决方案的电路面积,通常使用术语“门等效(ge)”,其中1ge是最小nand门的大小。然后,电路大小(就ge而言)被计算为面积(电路)/面积(nand)
→
t ge。了解每个标准或技术基元的估计ge值使得能够计算就ge而言的电路的估计面积大小。尽管各种技术对于标准基元具有略微不同的ge,但这些ge数字仍然彼此相当接近。
[0516]
我们研究了几种技术,其中有数据手册,并决定使用三星std90/mdl90 0.35μm 3.3v cmos技术[sam00]数据手册中给出的ge值。要使用的基元没有速度x
‑
因子。
[0517]
我们还查阅了其他技术的其他数据手册(例如,ibm的0.18μm[bus01]、wpi 0.5mm[mng00]、faraday的90μm[far06]、tsmc 0.18μm[art01]、web资源[pet]等),以及验证了[sam00]中给出的ge数字非常公平且接近现实。这使得能够对不同电路的有效性进行近似比较,即使它们可能是针对不同的技术而开发的。
[0518]
深度.不同的基元(如xor和nand)不仅在ge方面不同,而且在门的最大延迟方面也不同。
[0519]
通常,数据手册包括每个门以及每个输入
‑
输出组合的延迟(例如,以ns为单位)。
[0520]
我们建议通过xor门的延迟对所有被使用的门的延迟进行归一化。即,我们在关键路径的测量中采用xor门的最坏情况延迟作为1个单位。然后查看每个标准基元,并针对该基元的所有输入
‑
输出路径而选择最大的切换特性,并且它被除以xor门的最大延迟,从而获得所使用的每个门的归一化延迟单位。
[0521]
对于多路复用器(mux和nmux),我们忽略了选择位的传播延迟,因为在大多数情况
下,选择位是电路的输入。例如,在组合sbox中,选择位控制计算正向sbox还是逆向sbox,该选择已准备好作为输入信号并且不在电路信号传播时切换,因此它是一个稳定信号。
[0522]
上面提出的方法类似于ge的理念,但被用于计算电路的深度,以xor延迟被归一化。选择xor作为延迟计数的基本元素的原因是电路经常具有很多xor门,因此现在可以比较标准方法与技术方法之间的深度。例如,在我们的sbox中,关键路径包含14个门,其中大部分是xor,但实际上深度仅相当于12.38个xor延迟,因为关键路径还包含更快的门。
[0523]
a.3 技术基元概要
[0524]
表5总结了三星std90/mdl90 0.35μm门的面积和延迟。
[0525]
表5:基于[sam00]的技术门的面积和延迟。
[0526][0527]
b 算法细节和改进
[0528]
在本节中,我们介绍之前在论文中描述的各种算法的更多细节。
[0529]
b.1 单个输出位的最短电路。
[0530]
该问题是许多算法中反复出现的目标。问题陈述如下。给定k个输入信号x0,...,x
k
‑1以及相应的输入延迟d0,...,d
k
‑1,计算具有最小可能延迟的y=x0⊕
x1⊕
...
⊕
x
k
‑1。
[0531]
[rmta18a]中给出了该问题的解,其中未考虑输入延迟。在算法2中,我们将结果扩展为包括输入延迟并删除了排序步骤。
[0532]
[0533][0534]
b.2 关于3.3.1中δ(s,y
i
)的计算
[0535]
在每一轮中,算法测试来自s的所有已知点对,并针对每个对计算距离。直接的思路是穷举地计算δ,但是当输入大小n不太大时,存在更好的方法。
[0536]
设v是具有2
n
个项的向量,每个项v[t]是当前s到t的最小距离。然后,算法的单轮简化了很多,最短距离为:
[0537]
δ(v,y
i
,c)=min{v[y
i
],v[y
i
⊕
c]+1},
[0538]
其中c是用于添加到s的候选(来自s的其他两个已知点的异或),而y
i
是目标点。假设现在决定添加c到s,则向量v简单地更新为:
[0539]
v'[t]=δ(v,t,c),所有t=0,...,2
n
‑
1。
[0540]
更新v的时间复杂度是o(2
n
),但在特定情况下,它可以比针对一轮中的每个c和y
i
组合而穷举地计算δ快得多,尤其是在使用向量化cpu指令(例如avx2)时。
[0541]
b.3 关于第4.2.5节中δ(s,t
i
)的计算
[0542]
在本节中,我们将更详细地介绍如何计算δ(s,t
i
)。算法3、4和5给出了用于计算δ(s,t
i
)的稍微重新组织的算法集合。
[0543][0544][0545]
算法5 多路复用器mux门的卷积
[0546][0547]
存在两种卷积算法,用于异或门和用于多路复用器门,它们可以被独立地执行。多路复用器卷积可以在线性时间o(n)内完成。我们首先收集所有可能的f值和i值的最小距离(每个值都有个可能的索引),然后可将多路复用器门应用于任何组合,所以卷积是异或卷积更复杂,一般情况下它具有二次复杂度o(n2)。
[0548]
算法改进.假设对于某些s,我们已经计算了所有距离δ
i
=δ(s,t
i
)。对于来自c的每个候选c,我们将其添加到s,使得s'=s∪c,然后需要计算所有距离δ
′
i
=δ(s
′
,t
i
)以便计算度量并决定哪个c是良好的。注意,添加单个候选c意味着对于每个目标t
i
,δ
′
i
≤δ
i
。因此,应修改算法distances(s’,t,maxδ),使得设置maxδ=max{δ
i
}
‑
1,并最终检查如果δ
′
i
==∞,则δ
′
i
=maxδ。这个简单的技巧有助于避免计算最后一个向量v
k
并有效地将计算速度提高多达20倍。
[0549]
候选c的生成涉及测试候选是否已经在c中或s中,因为这些候选需要被忽略。为了加速这部分,可以使用长度为n的临时向量z[n],其中所有基元被初始化为∞,然后针对来自s中的每个点s,设置z[s.p]=s.d。接着,当生成新的候选c时,只需更新表z[c.p]=min{c.d,z[c.p]}。最后,从z中移除s点,并根据z生成c,如下所示:对于所有i=0..n
‑
1,如果z[i]<∞,则添加候选c={.p=i,.d=z[i]}到c。以此方式,用唯一的候选构造c,并且还具有最小深度。
[0550]
架构改进.mux(a,b)和mux(b,a)可以被组合在单个mux卷积函数中。在max{d1,d2}+1中,将+1运算移到卷积函数之外,并替代地在卷积之后执行。完成p
⊕
{.p=[1|0|1|0],.d=0}以便包括具有取反输出的门。这些运算也可以被移到卷积函数之外,并在线性时间内在主函数distances()中执行。这有助于减少函数convolutionxor()的关键循环中的运算次数,基本上这使速度加倍。当a=b时,则在convolutionxor()中,只需要从a开始运行b。当b不等于v0时,convolutionxor只能在b的一半值上进行,因为我们知道所有向量v
k
(其中k>0)就“非”门而言是对称的。当在convolutionxor()中a[a]=∞时,不需要进入b的内循环。对b[b]≠∞执行相同的检查是不合理的,因为它在关键循环中添加了不必要的分支。
[0551]
附加avx.很明显,convolutionmux()可以很容易地被重构为使用avx向量化指令并利用它的128位寄存器和内在特性。但是,将avx附加到convolutionxor()函数有点棘手。首先,假设每个基元a[a]、b[b]都是char类型(字节),则必须开始b被对齐到16个字节,因为avx中的寄存器为128位长。其次,p=a
⊕
b(其中b=0..15 mod 16)的结果将在置换位置p结束,但该置换只发生在低4位。借助_mm_shuffle_epi8(),可以进行目标16字节块的置换,其中置换向量仅取决于a mod 16的值(回想一下b=0 mod 16)。这些置换向量可以被硬编码在常量表中。该convolutionxor中的其他运算很容易实现。还可以附加avx2及其256位长寄存器,从而进一步加速算法。
[0552]
b.3.1 convolutionxor()的更多信息
[0553]
可以注意到,convolutionxor可以借助以下卷积来完成:
[0554][0555]
其中运算和因此,需要在(min,max)
‑
algebra中进行卷积。可以考虑在o(n logn)中应用hadamard变换,但问题是该algebra没有逆元素。
[0556]
在[bhwz94]中,存在一种可以被转换成我们的卷积问题的算法“minconv”,据称它的工作时间“大约平均”为o(n logn)时间。minconv背后的思路是对a和b向量进行排序,然后我们在向量a和b的开头得到最小延迟。因此,可以从最小值开始枚举max{a[a],b[b]}。另外,在对a和b进行排序时应注意索引,以使得能够找到目标点p=a
⊕
b。初次命中的每个点p接收到最小的可能延迟,因此可以在以后被跳过。该算法背后的思路是,覆盖结果的所有n个点的预测命中数将在n logn左右。
[0557]
我们已经对其进行了编程,但它没有展示在我们的输入大小(n=8,n=218)上的加速,而且实际上至少在我们的输入大小上,比我们的avx改进型二次算法执行得慢。此外,上述算法不能被并行化。
[0558]
b.3.2 o(maxdelay2·
n log n)时间内的convolutionxor()
[0559]
通常被存储在v向量中的延迟值很小。可以依据此事实来开发一种比o(n2)更快的算法。
[0560]
该思路很简单。构造两个向量a
x
[]和b
y
[],以使得如果a[p]=x,则a
x
[p]=1,否则a
x
[p]=0,针对b
y
[]采取同样的操作。然后,通过o(n logn)中的经典walsh
‑
hadamard变换来计算两个布尔向量a
x
和b
y
的经典卷积。设c
d
[]为卷积的结果且d=max{x,y}+1。然后,我们知道如果c
d
[p]≠0,则点p可具有深度d。因此,我们只是在c
d
[p]上执行线性循环并检查如果c
d
[p]≠0并且v[p]>d,则v[p]=d。应针对x,y=0..maxd的所有组合重复上述运算,其中
每一步的复杂度为o(n logn)。maxdelay的值也可以在算法开始时被线性地确定。还要注意,a和b的maxdelay可能不同,因此x和y可能具有不同的范围。
[0561]
b.3.3 o(|s|2)时间内的convolutionxor()
[0562]
当从初始v0构造向量v1时,值得采用经典方式并遍历s的点对,而不是在n个点上执行全尺度卷积。然而,新生成的点数增长得非常快,这种方法只能应用于最初的vs(在我们的实验中,仅在v1中看到一些“胜利”,然后对于进一步的v
k
(k>1),已经使用了优化后的卷积算法)。
[0563]
c 逆向sbox
[0564]
据我们所知,单独的逆向sbox的使用不广泛。但我们在表6中提供了与先前已知的解的比较。
[0565]
表6:逆向sbox:结果比较。
[0566][0567]
逆向sbox:先前结果
[0568][0569][0570]
逆向sbox:我们的结果
[0571][0572]
d 电路
[0573]
d.1 预备知识
[0574]
在下面的清单中,我们展示了两种架构a(小型)和d(快速)中的正向、逆向、以及组合sbox的六个电路。使用的符号有:
[0575]
·
##comment
–
注释行
[0576]
·
@filename
–
表示应包括来自另一名为“filename”的文件的代码,然后在本节中也给出了它的清单。
[0577]
·
a^b
–
是常见的“异或”xor门;其他门被显式表示并取自集合{xnor,and,nand,or,nor,mux,nmux,not}
[0578]
·
(a op b)
–
在执行顺序(门连接的顺序)很重要的情况下,用括号指定该顺序。
[0579]
到所有sbox的输入是8个信号{u0..u7},输出是8个信号{r0..r7}。输入位和输出位以大端位序来表示。对于组合sbox,输入具有额外的信号zf和zi,如果执行正向sbox,则zf=1,否则,如果执行逆向sbox,则zf=0;信号zi是zf的补充信号。我们已经测试了所有提出的电路并验证了它们的正确性。
[0580]
根据图5,这些电路被划分成子程序。在第d.2节中,描述了公共共享组件,然后针对每个解,给出电路的组件(公共的或特定的)。
[0581]
d.2 共享组件
[0582]
清单2:mulx/inv/s0/s1/8xor4:共享组件。
[0583][0584]
清单3:muln/mull:共享组件。
[0585][0586]
d.3正向sbox(快速)
[0587]
清单4:具有最小延迟的正向sbox(快速)
[0588][0589]
d.4正向sbox(最佳)
[0590]
清单5:具有面积/深度权衡的正向sbox电路(最佳)
[0591][0592]
d.5 正向sbox(奖励)
[0593]
包括以下奖励电路以更新最小sbox的世界纪录。
[0594]
新纪录是108个门,深度为24。
[0595]
清单6:具有最少门数的正向sbox电路(奖励)
[0596][0597]
d.6逆向sbox(快速)
[0598]
清单7:具有最小延迟的逆向sbox(快速)
[0599][0600]
d.7逆向sbox(最佳)
[0601]
清单8:具有面积/深度权衡的逆向sbox电路(最佳)
[0602][0603]
注意:文件
‘
itop.a’中的上述
‘
not(u2)’可以通过设置q11=u2并准确地向下对一些涉及q11的门和变量求“反”来移除。例如,变量y01也应被求“反”,因为:n0=nand(y01,q11),因此,所有涉及y01s.b.的门被求“反”,这导致其他q变量被求“反”,等等。
[0604]
d.8 逆向sbox(奖励)
[0605]
清单9:具有最少门数的逆向sbox电路(奖励)
[0606][0607]
d.9 组合sbox(快速)
[0608]
清单10:具有最小延迟的组合sbox电路(快速/
‑
s)
[0609]
[0610]
[0611]
[0612][0613]
d.10 组合sbox(最佳)
[0614]
清单11:具有面积/深度权衡的组合sbox电路(最佳)
[0615]
[0616][0617]
d.11 组合sbox(奖励)
[0618]
清单12:具有最少门数的组合sbox电路(奖励)
[0619]
[0620][0621]
本公开的部分c
[0622]
来自部分a和部分b的结果可通过对反相电路的进一步研究来进一步扩展。sbox的最终实施例是具有更短关键路径的电路。
[0623]
gf(24)上的求逆
[0624]
求逆公式如下:
[0625]
y0=x1x2x3
⊕
x0x2
⊕
x1x2
⊕
x2
⊕
x3,
[0626]
y1=x0x2x3
⊕
x0x2
⊕
x1x2
⊕
x1x3
⊕
x3,
[0627]
y2=x0x1x3
⊕
x0x2
⊕
x0x3
⊕
x0
⊕
x1,
[0628]
y3=x0x1x2⊕
x0x2⊕
x0x3⊕
x1x3⊕
x1。
[0629]
在[bp12]中发现了具有深度4和17个xor的电路,但期望通过使用更广泛的标准门来进一步缩小深度。
[0630]
相应地,部分b第4.2节中的算法已被适配为寻找inv框的小型解。该思路很简单;基于4位输入x0,...,x3,每个y
i
是长度为16位的真值表。我们将“点”定义为16位值。所有标准门(and、or、xor、mux、not,包括它们的取反版本)都能够被应用于“已知”点(s)的任何组合,并且可以以与先前类似的方式计算到目标点的距离t。对浮动多路复用器使用这种稍微修改的算法,找到了只有9个门和深度为3的解。结果如方程式2所示,改进电路见附录e。
[0631][0632]
如果期望在inv框中避免多路复用器,则本节中还提供了一组替代方程。每个表达式被独立地考虑,其中使用通用深度3表达式:
[0633]
y
i
=((x
a op
1 x
b
)op5(x
c op
2 x
d
))op7((x
e
op
3 x
f
)op6(x
g op4x
h
)),
[0634]
其中,x
a
‑
h
是来自{0,1,x0,x1,x2,x3}的项,op1‑7是来自标准门集合{and,or,xor,nand,nor,xnor}的运算符。注意,上面不需要包含所有项,例如,表达式and
(x,x)
就是简单的x。
[0635]
可以按如下方式组织穷举搜索。设具有对象term,它包含长度为16位的真值表tt,基于4个位x0..x3,以及与该项相关联的布尔函数。从可用项的初始集合t
(0)
={0,1,x0,...,x3}开始,然后迭代地为选定的y
i
构造表达式。假设在某个步骤k具有可用项集合t
(k)
,则可以如下获得下一个项集合和相关联的表达式:
[0636]
t(k+1)={t(k),t(k)operatort(k)},
[0637]
其中考虑唯一的项。在某个步骤k,将得到其tt等于目标tt(y
i
)的一个或多个项。
[0638]
由于实际上可以针对每个y
i
得到多个布尔函数,因此应只选择遵循以下标准的“最佳”函数:没有“非”门(由于更好的共享能力),存在可以在y0..y3的4个表达式之间共享的最大门数,ge方面的面积/深度很小。
[0639]
使用这种技术,我们为求逆找到了深度3、15个门的解。下面给出了方程式,其中还为额外的5个信号{y
01
,y
23
,y
02
,y
13
,y
00
}提供了深度3的解,以便它们在部分b中提到的场景s0
‑
s5中也可以共享很多门。
[0640][0641]
附录e
[0642]
在本节中,将介绍使用部分c中提供的改进求逆公式的电路。
[0643]
预备知识
[0644]
在下面列出的清单中,描述了新架构d(快速)中的正向、逆向和组合sbox的三个电路的规格。以下清单中使用的符号如下,并具有所指出的含义:
[0645]
·
#comment
–
注释行
[0646]
·
@filename
–
表示应包括来自另一名为“filename”的文件的代码,然后在本节中也给出了它的清单。
[0647]
·
a^b
–
是常见的“异或”xor门;其他门被显式表示并取自集合{xnor,and,nand,or,nor,mux,nmux,not
[0648]
·
(a op b)
–
在执行顺序(门连接的顺序)很重要的情况下,用括号指定该顺序。
[0649]
到所有sbox的输入是8个信号{u0..u7},输出是8个信号{r0..r7}。输入位和输出位以大端位序来表示。对于组合sbox,输入具有额外的信号zf和zi,如果执行正向sbox,则zf=1,否则,如果执行逆向sbox,则zf=0;信号zi是zf的补充信号。已经测试了所有提出的电路并验证了它们的正确性。
[0650]
这些电路被划分成子程序,这些子程序分别对应于图5所示的功能/层。讨论从描述公共共享组件开始,然后针对每个解,描述电路的组件(公共的或特定的)。
[0651]
共享组件
[0652]
共享组件在下面的多个实现中使用,因此这里只描述一次。清单:mulx/8xor4/inv:共享组件
[0653][0654]
清单:muln/mull:共享组件。
[0655]
[0656][0657]
正向sbox(快速)
[0658]
清单:具有最小延迟的正向sbox(快速)
[0659][0660]
组合sbox(快速)
[0661]
清单:具有最小延迟的组合sbox
[0662]
[0663][0664]
逆向sbox(快速)
[0665]
清单:具有最小延迟的逆向sbox电路(快速)
[0666]
[0667]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1