一种最小化网络时延的边缘节点负载均衡方法
本发明属于5g网络计算卸载技术领域,尤其涉及一种最小化网络时延的边缘节点负载均衡方法。
背景技术:
边缘计算是5g网络的核心技术之一。终端设备向边缘节点卸载计算任务已经成为新的计算范式。然而,一方面相比于传统的中心云,边缘节点的计算资源是有限的;另一方面在不同区域的边缘节点服务于不同的群体,其承载的计算负载量是悬殊的。如何平衡边缘节点的负载,降低计算时延,提高整个边缘网络的服务效益是一个非常重要的研究问题。
技术实现要素:
针对上述问题,本发明提供了一种最小化网络时延的边缘节点负载均衡方法,结合边缘计算和软件定义网络(sdn)的优势,设计了边缘网络中边缘节点协作卸载计算模型,通过调度边缘网络中过载节点的计算任务,即分割过载节点的计算任务,并通过一跳或者多跳的方式卸载到其它相对欠载的边缘节点,以平衡网络中边缘节点的负载。
为了实现上述目的,本发明提供如下的技术方案:
一种最小化网络时延的边缘节点负载均衡方法,所述方法包括如下步骤:
步骤1:用
步骤2:统计每个边缘节点的负载情况,假设与节点j关联且向该节点卸载任务的终端设备的集合为ij={1,2,......,i};每个设备产生的任务大小为si,处理每一位数据所需要的cpu周期数为ci,则边缘节点接收到的数据量的大小为
步骤3:分割源节点的计算任务,假设节点j上的计算任务被分成了若干个部分,每部分的计算任务分别卸载给其它边缘节点k,k∈{1,2,…,j},视为目标节点,其数据量
步骤4:确认目标节点的负载,
步骤5:确定卸载路径,定义二进制变量
步骤6:计算卸载路径传输时延,rmn表示该链路(m,n)的传输速率,卸载路径的传输时延为通路上每条链路的传输时延之和,即所有xmn(αjk)=1的链路的传输时延之和,故节点j向节点k卸载任务的传输时延为
步骤7:计算目标节点计算时延,每个目标节点的计算资源除用于自身计算任务外,还分配给别的节点用于计算卸载,定义目标节点k分配给源节点j的计算资源为fjk,则节点j向节点k卸载所花的计算时延为
步骤8:每部分计算任务产生的时延包括传输时延以及目的节点的处理时延。所以处理
步骤9:结合步骤3、5、6、7、8,建立如下关于过载节点的卸载的数学模型:
p1:
xmn(αjk)∈{0,1}②
问题p1描述的是源节点j通过多路卸载以及本地计算的方式完成
步骤10:结合步骤4,确定
步骤11:根据步骤9和步骤10重塑问题
p2:
s.t.①~③,⑤
步骤12:设计量子粒子群算法适应度函数,根据步骤10中的目标问题和约束定义适应度函数f=f′+pen,其中
步骤13:定义粒子群的大小为n,第n个粒子的位置向量为λn={λj1,λjk,...,λjk,...,λj|j|},λjk的具体表达为:λjk=(αj1,x);
步骤14:首次迭代,第n个粒子的局部最佳位置为pn(1)=λn(1),从pn(1)(n=1,2,......,n)中找到最佳的粒子位置作为g(1);
步骤15:第m+1次迭代,更新粒子的位置:
步骤16:更新粒子的局部最佳位置和和全局最佳位置
步骤17:循环迭代,直到达到设定的迭代次数,输出全局最佳粒子的位置g即全局最佳解;
步骤18:sdn控制器将求得的g,即将包含任务分割比例、路径、目标节点的卸载决策信息发送给源节点,节点接收到相应信息的时候执行相应的卸载操作;
步骤19:sdn控制器继续收集基础设施层的状态信息,当发现有过载节点的重复步骤2到步骤18。
本发明的有益效果为:利用sdn控制器根据监控边缘网络的状态,调度过载节点向欠载节点卸载,优化卸载决策,降低过载节点的负载,最终降低边缘网络的处理时延。
附图说明:
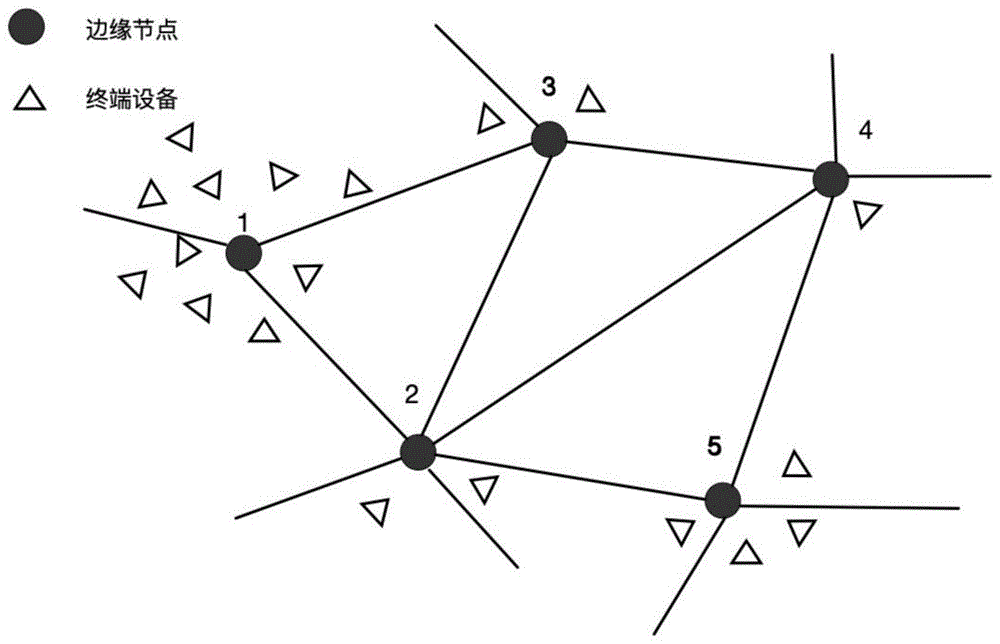
图1是边缘网络结构模型示意图。
具体实施方式
下面结合附图对本发明作进一步说明。
参照图1,一种最小化网络时延的边缘节点负载均衡方法,包括如下步骤:
步骤1:如图1所示的边缘网络结构模型图,任意一个边缘节点都可以直接关联到其邻近的节点,只要该节点在其辐射半径范围内,例如节点1可以直接向节点2或者节点3卸载数据,但是要关联到远端的节点,只能通过中继节点转发,例如节点1向节点4卸载数据只能通过节点3转发或者由节点2转发给节点5,再由节点5传输给节点4,用
步骤2:统计边缘网络中每个边缘节点的负载情况,每个节点关联着若干个设备,假设与节点j关联且向该节点卸载任务的终端设备的集合为ij={1,2,......,i}。每个设备产生的任务的大小为si,处理每一位数据所需要的cpu周期数为ci,则边缘节点接收到的数据量的大小为
步骤3:分割源节点的计算任务,假设节点j上的计算任务被分成了若干个部分,每部分的计算任务分别卸载给其它边缘节点k,k∈{1,2,…,j},视为目标节点,其数据量
步骤4:确认目标节点的负载,
步骤5:确定卸载路径,定义二进制变量
例如节点1通过节点2转发向节点5卸载数据,则x12(α15)=1,x25(α15)=1。节点1作为源节点,对于数据
步骤6:计算卸载路径传输时延,rmn表示该链路(m,n)的传输速率。传输时延为通路上每个链路的传输时延之和,换句话说,就是所有xmn(αjk)=1的链路的传输时延之和,故节点j向节点k卸载任务的传输时延为
步骤7:计算卸载路径计算时延,每个目标节点的计算资源除用于自身计算任务外,还分配给别的节点用于计算卸载,定义目标节点k分配给源节点j的计算资源为fjk,则节点j向节点k卸载所花的计算时延为
步骤8:每部分计算任务产生的时延包括传输时延以及目的节点的处理时延,所以处理
步骤9:结合步骤3、5、6、7、8,建立如下关于过载节点的卸载的数学模型:
p1:
xmn(αjk)∈{0,1}②
问题p1描述的是源节点j通过多路卸载以及本地计算的方式完成
步骤10:结合步骤4,确定
步骤11:根据步骤9和步骤10重塑问题
p2:
s.t.①~③,⑤
步骤12:设计量子粒子群算法适应度函数,根据步骤10中的目标问题和约束定义适应度函数f=f′+pen,其中
步骤13:定义粒子群的大小为n,第n个粒子的位置向量为λn={λj1,λjk,...,λjk,...,λj|j|},λjk的具体表达为:λjk=(αj1,x);
步骤14:首次迭代,第n个粒子的局部最佳位置为pn(1)=λn(1),从pn(1)(n=1,2,......,n)中找到最佳的粒子位置作为g(1);
步骤15:第m+1次迭代,更新粒子的位置:
步骤16:更新粒子的局部最佳位置和和全局最佳位置
步骤17:循环迭代,直到达到设定的迭代次数,输出全局最佳粒子的位置g即全局最佳解;
步骤18:sdn控制器将求得的g,即将包含任务分割比例、路径、目标节点的卸载决策信息发送给源节点,节点接受到相应信息的时候执行相应的卸载操作;
步骤19:sdn控制器继续收集基础设施层的状态信息,当发现有过载节点的重复步骤2到步骤18。
本说明书的实施例所述的内容仅仅是对发明构思的实现形式的列举,仅作说明用途。本发明的保护范围不应当被视为仅限于本实施例所陈述的具体形式,本发明的保护范围也及于本领域的普通技术人员根据本发明构思所能想到的等同技术手段。
- 还没有人留言评论。精彩留言会获得点赞!