用于光突发交换网络中的入侵检测方法
1.本发明属于光通信技术领域,具体涉及一种用于光突发交换网络中的入侵检测方法。
背景技术:
2.光突发交换(optical burst switching,obs)是一种将光电路与光分组交换技术相结合的新型技术。光突发交换技术实现了数据分组与控制分组在全光互联网中时间与信道的独立传送,提高了资源的利用率与分配灵活性,是未来全光互联网中重点发展技术之一。
3.边缘节点、核心节点以及wdm链路构成了obs网络。突发包是obs网络的基本交换单元,包括突发数据包(burst data packet,bdp)及与突发数据包对应的突发控制分组(burst control packet,bcp)。obs传输技术在光学域中对控制头信息进行复杂的电子处理,并将数据保存在里面。obs传输技术将边缘节点(入口节点)的客户端传输的数据组合成数据突发。然后一个包含了 db包信息(突发长度、到达时间、偏移时间等)的bhp通过专用的带外波分复用信道向前传输。bhp在db之前的时间称为偏置时间,用于预留所需的资源。bhp进入中间节点的时候会进行光
‑
电
‑
光转换,并通过电子处理来分配进去光领域的数据突发资源。入口边缘节点以突发的形式发送数据,最终在目标边缘节点上被分解。
4.在数据传输过程中,bcp和bdp采用了分离物理传输信道的方法,bcp 占用控制信道,bdp占用数据信道。这种方法在很大程度上可以简化数据处理过程,但却导致网络容易受到攻击。攻击者通过恶意节点向网络发送大量的 bhps时,目标节点开始为每个恶意bhp保留新的wdm信道。合法的db到达且没有空闲的wdm信道可用时,到达的db将会被核心交换机丢弃,在极端情况下,此攻击行为还会导致网络产生严重的拒绝服务。
5.但是,目前尚没有一种稳定可靠且高效的针对光突发交换网络的入侵检测方法。
技术实现要素:
6.本发明的目的在于在于提供一种针对泛洪攻击能够进行高准确率识别,而且可靠性高、稳定性好且性能优异的用于光突发交换网络中的入侵检测方法。
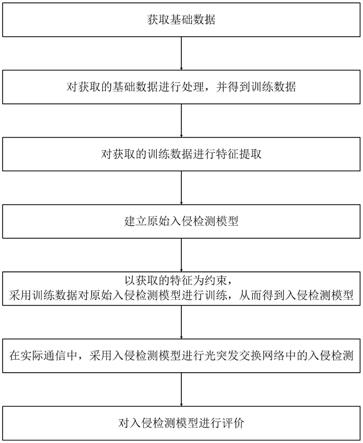
7.本发明提供的这种用于光突发交换网络中的入侵检测方法,包括如下步骤:
8.s1.获取基础数据;
9.s2.对步骤s1获取的基础数据进行处理,并得到训练数据;
10.s3.对步骤s2获取的训练数据进行特征提取;
11.s4.建立原始入侵检测模型;
12.s5.以步骤s3获取的特征为约束,采用步骤s2得到的训练数据对步骤s4 建立的原始入侵检测模型进行训练,从而得到入侵检测模型;
13.s6.在实际通信中,采用步骤s5得到的入侵检测模型进行光突发交换网络中的入侵检测。
14.所述的用于光突发交换网络中的入侵检测方法,还包括如下步骤:
15.s7.计算分类精度ca、分类率rmc、灵敏度sns、假阴性率frn、假阳性率fpr、特异性spc、预测准确率prc、阴性预测值npv和f1评分对入侵检测模型进行评价。
16.所述的计算分类精度ca、分类率rmc、灵敏度sns、假阴性率frn、假阳性率fpr、特异性spc、预测准确率prc、阴性预测值npv和f1评分,具体为采用如下算式进行计算:
[0017][0018][0019][0020][0021][0022][0023][0024][0025][0026]
式中tp为正确识别的个数;tn为正确拒绝的个数;fn为错误拒绝的个数;fp 为错误识别的个数;precision为准确率得值;recall为召回率。
[0027]
步骤s1所述的获取基础数据,具体为采用uci机器学习库中的关于光突发交换网络中的bhp泛洪攻击数据集。
[0028]
步骤s2所述的对步骤s1获取的基础数据进行处理,并得到训练数据,具体为采用如下步骤得到训练数据:
[0029]
a.数据清洗:删除缺失值,同时删除数据包大小字节d11;
[0030]
b.数据转换:转换四个分类{nb no block、block、no block、nb wait}和节点在黄台{表现、不表现、潜在不表现}到one
‑
hot编码中;n位状态寄存器对应n个状态,每个状态由对应的独立的寄存器位控制,并且任何时候仅有一个编码有效;
[0031]
c.数据归一化:将数据采用最小最大归一化方式进行标准化处理。
[0032]
步骤s3所述的对步骤s2获取的训练数据进行特征提取,具体为采用如下步骤进行特征提取:
[0033]
采用皮尔逊相关系数衡量两个变量之间的相关程度:皮尔逊相关系数越接近1或者
‑
1,则表明两个变量之间的关联度越强;采用如下算式计算皮尔逊相关系数:
[0034][0035]
式中ρ
xy
为变量x和变量y的皮尔逊相关系数;cov(x,y)为两个变量之间的协方差;e()为数学期望;x、y为变量;μα、μy为样本平均数;δxδy为两个变量之间的标准差;
[0036]
然后,根据计算得到的皮尔逊相关系数值,选取训练数据的特征。
[0037]
步骤s4所述的建立原始入侵检测模型,具体为采用如下步骤建立模型:
[0038]
采用resnet模型作为检测模型;
[0039]
模型包括输入层、第一卷积层、池化层、残缺块、第二卷积层、第三卷积层、全连接层、dropout层和adam优化器;
[0040]
输入层:用于将数据输入到模型中;输入层采用一维卷积,数据维度为1060,卷积核的维度为3,卷积核的数量为64,步长为1;卷积方式为same;对特征进行无监督的学习,学习方式为对每层输入与输出间的残差信息进行学习;
[0041]
第一卷积层:通过不同卷积核对上层特征图进行不同特征提取,利用激励函数构建输出特征图;每一层输出都是对多输入特征的卷积操作,数学公式表达为其中h
i
为网络第i层特征向量图,且当i=1时h
i
为输入层;w
i
为第i层卷积核权值向量;b
i
为偏移量;f()为激励函数;为卷积运算符,用于完成卷积核与第i
‑
1层特征图的卷积运算;激励函数为relu函数:
[0042]
池化层:采用最大池化法提高特征,同时降低网络过拟合; h
i
=f(β
i
down(h
i
‑1)+b
i
),其中h
i
为池化层输出;β
i
为网络乘性偏置矩阵; down()为池化函数;
[0043]
残差块:池化层后连接残差块;
[0044]
第二卷积层和第三卷积层:用于对每层输入与输出间的残差信息进行学习;卷积大小为3,卷积方式为same的一维卷积;
[0045]
全连接层:用于对所有具有目标类型区分性的局部信息的低维特征进行整合;采用softmax分类器o=f(b
i
+ω0h
i
),ω0为权值矩阵;神经元个数为128;
[0046]
dropout层:全连接层将数据输入dropout层;
[0047]
adam优化器:用于采用学习率逐步降低的方法对卷积神经网络进行训练;设置网络的权重为截断正态分布,均值为0且方差为1;初始化偏置值为0.1; dropout值设置为0.5;学习率初始值赋值为10
‑3;网络迭代次数设置为2000。
[0048]
本发明提供的这种用于光突发交换网络中的入侵检测方法,将残差网络应用于光突发交换网络的入侵检测,实现了针对泛洪攻击的检测,而且准确率高,可靠性高、稳定性好且性能优异。
附图说明
[0049]
图1为本发明方法的方法流程示意图。
[0050]
图2为本发明方法的入侵检测模型的结构示意图。
[0051]
图3为本发明方法的pcc计算结果的可视化热力图。
[0052]
图4为本发明方法与dcnn在训练准确率和验证准确率的对比结果示意图。
[0053]
图5为本发明方法与dcnn在训练损失值和验证损失值的对比结果示意图。
具体实施方式
[0054]
如图1所示为本发明方法的方法流程示意图:本发明提供的这种用于光突发交换网络中的入侵检测方法,包括如下步骤:
[0055]
s1.获取基础数据;具体为采用uci机器学习库中的关于光突发交换网络中的bhp泛洪攻击数据集,该数据集有1075个样本数据,每个样本数据包含 22个属性;
[0056]
s2.对步骤s1获取的基础数据进行处理,并得到训练数据;具体为采用如下步骤得到训练数据:
[0057]
a.数据清洗:删除缺失值,同时删除数据包大小字节d11;
[0058]
b.数据转换:转换四个分类{nb no block、block、no block、nb wait}和节点在黄台{表现、不表现、潜在不表现}到one
‑
hot编码中,这使得分类器在处理属性数据时更加高效,并且在一定功能上来说也扩展了函数的属性特征;n 位状态寄存器对应n个状态,每个状态由对应的独立的寄存器位控制,并且任何时候仅有一个编码有效,例如,nb no block类的单热编码为{1,0,0,0}, block类的单热编码为{0,1,0,0};
[0059]
c.数据归一化:将数据采用最小最大归一化方式进行标准化处理;从而消除数据特征之间的维度影响,消除不同数量级样本不同属性的影响,还可以加快梯度下降最优解的搜索速度,提高分类精度;
[0060]
s3.对步骤s2获取的训练数据进行特征提取;具体为采用如下步骤进行特征提取:
[0061]
特征选取是从给定的属性集中选择相关属性子集的过程;在现实任务中经常会遇到维度灾难问题,这是属性太多造成的;如果能从中选取重要的特征,后续的学习过程只需要对一部分特征建立模型,去掉无关的特征往往会降低学习任务的难度;采用皮尔逊相关系数衡量两个变量之间的相关程度:皮尔逊相关系数越接近1或者
‑
1,则表明两个变量之间的关联度越强,同时如果两个属性有完全正的线性相关性,删除一个不会造成信息丢失;采用如下算式计算皮尔逊相关系数:
[0062][0063]
式中ρ
xy
为变量x和变量y的皮尔逊相关系数;式中ρ
xy
为变量x和变量y的皮尔逊相关系数;cov(x,y)为两个变量之间的协方差;e()为数学期望;x、y为变量;μα、μy为样本平均数;δxδy为两个变量之间的标准差;
[0064]
对pcc的计算结果进行可视化,生成了图3中的热力图,图3(a)表示数据集特征选择前相关系数的热图,图3(b)表示数据集特征选择后相关系数的热图,其中的数字表示pcc相关系数的计算结果;
[0065]
然后,根据计算得到的皮尔逊相关系数值,选取训练数据的特征;
[0066]
s4.建立原始入侵检测模型(如图2所示);具体为采用如下步骤建立模型:
[0067]
采用resnet模型作为检测模型;
[0068]
模型包括输入层、第一卷积层、池化层、残缺块、第二卷积层、第三卷积层、全连接层、dropout层和adam优化器;
[0069]
输入层:用于将数据输入到模型中;输入层采用一维卷积,数据维度为1060,卷积核的维度为3,卷积核的数量为64,步长为1;卷积方式为same;对特征进行无监督的学习,学习方式为对每层输入与输出间的残差信息进行学习;
[0070]
第一卷积层:通过不同卷积核对上层特征图进行不同特征提取,利用激励函数构建输出特征图;每一层输出都是对多输入特征的卷积操作,数学公式表达为其中h
i
为网络第i层特征向量图,且当i=1时h
i
为输入层;w
i
为第i层卷积核权值向量;b
i
为偏移量;f()为激励函数;为卷积运算符,用于完成卷积核与第i
‑
1层特征图的卷积运算;激励函数为relu函数:从而避免梯度爆炸和梯度消失、加快收敛速度;同时,relu 会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生;
[0071]
池化层:采用最大池化法提高特征,同时降低网络过拟合; h
i
=f(β
i
down(h
i
‑1)+b
i
),其中h
i
为池化层输出;β
i
为网络乘性偏置矩阵; down()为池化函数;
[0072]
残差块:池化层后连接残差块;
[0073]
第二卷积层和第三卷积层:用于对每层输入与输出间的残差信息进行学习;卷积大小为3,卷积方式为same的一维卷积;
[0074]
图2中的bn即为batch normalization数据归一化加速训练过程,此方法经多个交替相连的卷积层和池化层完成特征提取后,为方便分类器准确分类,通过增加全连接层这一方法,来对所有具有目标类型区分性的局部信息的低维特征进行整合,输入目标分类层进行故障分类;
[0075]
全连接层:用于对所有具有目标类型区分性的局部信息的低维特征进行整合;采用softmax分类器o=f(b
i
+ω0h
i
),ω0为权值矩阵;神经元个数为128;
[0076]
dropout层:全连接层将数据输入dropout层;
[0077]
adam优化器:用于采用学习率逐步降低的方法对卷积神经网络进行训练;设置网络的权重为截断正态分布,均值为0且方差为1;初始化偏置值为0.1; dropout值设置为0.5;学习率初始值赋值为10
‑3;网络迭代次数设置为2000;
[0078]
随着迭代次数增加,学习率由大逐步减小,不仅避免了因学习步长过大从而越过最优过早网络退化的现象,而且避免了学习步长过小导致网络收敛速度慢的问题;
[0079]
s5.以步骤s3获取的特征为约束,采用步骤s2得到的训练数据对步骤s4 建立的原始入侵检测模型进行训练,从而得到入侵检测模型;
[0080]
s6.在实际通信中,采用步骤s5得到的入侵检测模型进行光突发交换网络中的入侵检测;
[0081]
s7.计算分类精度ca、分类率rmc、灵敏度sns、假阴性率frn、假阳性率fpr、特异性spc、预测准确率prc、阴性预测值npv和f1评分对入侵检测模型进行评价;具体为采用如下算式进行计算:
[0082][0083][0084][0085][0086][0087][0088][0089][0090][0091]
式中tp为正确识别的个数;tn为正确拒绝的个数;fn为错误拒绝的个数;fp 为错误识别的个数;precision为准确率得值;recall为召回率。
[0092]
以下,将本发明方法与现有技术进行对比:
[0093]
将本发明方法与常用的knn算法、nb算法、svm算法以及dcnn对obs 网络中的bhp泛洪攻击的检测效率进行比较。将五个算法经过属性的训练,通过仿真实验所得的数据进行测试。
[0094]
表1展示了knn和nb算法的混淆矩阵,表2展示了svm和dcnn的混淆矩阵,表3展示了resnet的混淆矩阵。
[0095]
表1 knn算法与nb算法的混淆矩阵示意表
[0096][0097]
表2 svm算法和dcnn算法的混淆矩阵示意表
[0098][0099]
表3本发明方法的混淆矩阵示意表
[0100][0101]
计算得到性能评价指标以及分类结果。此处使用混淆矩阵与9个性能评价指标;表4显示了不同模型的分类性能度量,resnet最大分类精度为100%, knn、nb、svm、dcnn的分类精度分别为96%、87%、89%和99%。knn、nb、svm的精度为92%、75%、78%,它们都存在过拟合现象,resnet预测准确率为100%,相比knn、nb、svm、dcnn提升了3%、25%、22%、1%。resnet 的敏感性100%,特异性100%,精密度100%,阴性预测值100%,f1评分100%。 resnet的其他机器学习性能指标也较好,误分类率最低为0,其中knn、nb、 dcnn的误分类率分别为4%、13%、11%和1%。resnet的假阳性率、假阴性率最低均为0。
[0102]
表4 5种分类模型的性能指标示意表
[0103] carmcsnsfnrfprspcprcnpvf1knn0.960.040.920.080.030.970.920.970.92nb0.870.130.750.250.080.920.750.920.75svm0.890.110.780.220.070.930.780.930.78dcnn0.990.010.990.010.010.990.990.990.99resnet1.001.0001.01.01.01.0
[0104]
图4和图5展示了本发明提出的resnet模型和dcnn的训练准确率和验证准确率训练损失值和验证损失值。本发明提出的resnet模型当迭代次数达到750 时,损失函数开始趋于稳定,dcnn模型准确率呈现不同程度的下降,说明随着网络层数的增加,出现了退化问题。当迭代次数超过1500时,由于残差块的学习,将输入直接传到输出,保护了信息的完整性,解决了退化问题,使准确率不断提高直至稳定。本发明提出的resnet模型和dcnn模型的的准确率刚开始就达到了非常高的数值,但本发明提出的resnet模型比dcnn准确率一直更高,且训练和验证数据都更早的达到了稳定的高准确率,大大地缩短了训练时间,且训练和验证数据准确率达到了100%的精度水平。同时,随着迭代次数的增加,dcnn模型损耗水平逐渐降低,本发明提出的resnet模型的损失值短暂升高,随后跳跃性的下降,并趋于稳定。相比dcnn模型来说,本发明提出的 resnet模型损失值更快的下降到稳定水平,相比其他模型提高了检测准确率,降低了误报率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1