一种基于Wifi信号RSSI特征的室内定位方法、系统
本发明属于室内定位
技术领域:
,涉及一种基于wifi信号rssi特征的室内定位方法、系统、计算设备及存储介质。
背景技术:
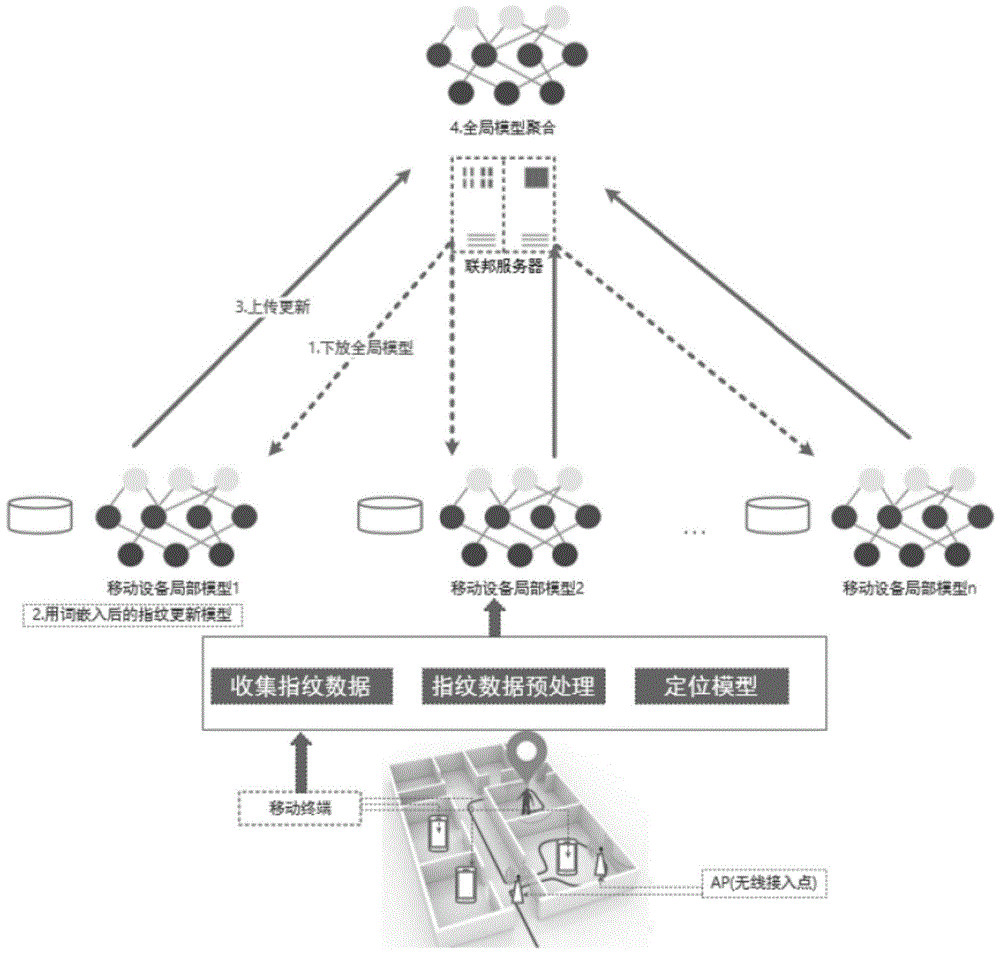
:室内定位技术是指在室内环境下通过终端设备的无线信号从而确定终端室内的位置的技术,随着这些年物联网的发展逐渐成为lbs(locationbasedservices,基于位置的服务)的基础,不同于室外定位已经很成熟的gps方案,室内场景下例如商场、机场、超市、图书馆存在大量遮挡物和承重墙,gps的误差较大不足以满足商用需求。室内定位技术可采用无线信号包括wifi、蓝牙、rfid等,但由于后两者需要大量的设备部署,而wifi信号有着天然存在于室内环境中并抗干扰能力强等特点,并且成本和性能比较低。传统的基于wifi信号rssi(信号接收强度)更多的通过一些数学方法,通过测量接入点ap(accesspoint)之间距离再通过数学几何方法确定设备位置例如三角定位法,这类方法适应性较差,还随着场景的变化导致效果严重下降,并且还需要一些辅助传感器的介入。随着机器学习和深度学习这两年的快速发展,神经网络也被引入基于信号强度传播的定位模型中来提高定位精度,但其中多数以有监督学习为主,这带来的问题就是需要大量的成本进行wifi数据的标注,相较于构建指纹库的方法也牺牲了一定的精度,而少数无监督的方法效果都无法达到商用的要求。同时无论哪种定位模型都要求设备上传并集中存储wifi指纹信号,与之同时上传的包括一些设备的基础信息,可能造成用户的隐私安全问题。技术实现要素:为解决现有技术中存在的问题,本发明的目的在于提供一种基于wifi信号rssi特征的室内定位方法、系统、计算设备及存储介质,本发明能够减少标注的成本、并且能够保证用户隐私。本发明所采用的技术方案如下:一种基于wifi信号rssi特征的室内定位方法,包括如下过程:接收室内环境中无线接入点的wifi信号;对接收的wifi信号的wifi指纹文本化,得到文本,根据所述文本得到包含距离特征的词向量空间,将词向量空间嵌入到wifi指纹并对该wifi指纹进行特征提取,得到融了和词向量特征的wifi指纹特征空间;对wifi指纹特征空间进行聚类,根据所述wifi指纹特征空间对应的wifi指纹所在的簇确定该条wifi指纹所在楼层的层数;根据wifi指纹特征空间对应的wifi指纹特征与gps之间的映射关系得到在平面中的位置。优选的,楼层定位时,聚类得到的一簇与一楼层的wifi指纹对应,把聚类结果与wifi信号的标签集对应,应用匈牙利算法进行二分图的匹配,得到评估最终楼层分类结果。优选的,根据wifi指纹特征空间对应的wifi指纹特征与gps之间的映射关系得到在平面中的位置时,利用wifi指纹特征与gps之间的映射关系,得到wifi指纹所在点的经纬度,根据经纬度确定wifi指纹所在点在平面中的位置。优选的,wifi指纹特征与gps之间的映射关系为加入正则化项的半监督回归函数。优选的,根据所述文本得到包含距离特征的词向量空间时,将无线接入点的空间距离与文本中词向量与词向量之间的距离特征对应。优选的,每个无线接入点的mac地址建立有索引,将wifi指纹文本化,得到文本的过程包括如下步骤:s1,将每个wifi信号的信号接收强度归一化并加入sigmoid函数,引入非线性因子作为词频tf;s2,将每个无线接入点mac地址的索引作为词,把该mac地址对应的经过s1处理的信号接收强度作为词频tf,将词频tf值作为索引在文档中的重复出现次数,得到处理后文本text的格式如下:其中,词频e为自然指数,rssi为信号接收强度,word为文本中的词,n为一条文本中词的个数,i为文本中词的序号。优选的,表示无线接入点的词向量通过如下方式获得:采用word2vec模型训练wifi指纹构成的wifi指纹库,并采用cbow模型最终得到表示每个无线接入点的词向量。本发明还提供了一种基于wifi信号rssi特征的室内定位系统,包括接收模块:用于接收室内环境中无线接入点的wifi信号;数据预处理模块:用于对接收的wifi信号的wifi指纹文本化,得到文本,根据所述文本得到包含距离特征的词向量空间,将词向量空间嵌入到wifi指纹,并对wifi指纹进行特征提取,得到融了和词向量特征的wifi指纹特征空间;计算模块:用于对wifi指纹特征空间进行聚类,根据该wifi指纹特征空间对应的指纹所在的簇确定该条wifi指纹所在楼层的层数;根据wifi指纹特征空间对应的wifi指纹特征与gps之间的映射关系得到在平面中的位置。本发明还提供了一种基于wifi信号rssi特征的室内定位设备,包括:存储器,用于存储计算机程序;处理器,用于执行所述计算机程序时实现本发明如上所述基于wifi信号rssi特征的室内定位方法的步骤。本发明还提供了一种计算机存储介质,所述计算机存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现本发明如上所述基于wifi信号rssi特征的室内定位方法的步骤。本发明具有如下有益效果:本发明基于wifi信号rssi特征的室内定位方法将wifi指纹文本化、并结合文本聚类技术来实现无监督的室内定位,本发明的定位方法在保证了定位效果的同时大大减少了标注的成本并增加了场景变换的适应性,通过将无线接入点的词向量空间嵌入到wifi指纹特征空间中来度量wifi指纹在高维流形空间中的距离,在定位过程中,无需集中式的存储和处理wifi指纹,因此隐私性较好,能够保证用户隐私。附图说明图1是本发明定位方法中采用的联邦定位框架图;图2是本发明定位方法中采用的联邦定位选择的控制协议图;图3是本发明实施例中的定位模型图;图4是本发明实施例中的dcnn网络图;图5是本发明实施例中的准确率随着联邦轮数的变化示意图。具体实施方式下面结合附图和实施例对本发明进行详细说明。实施例本实施例基于wifi信号rssi特征的室内定位方法包括如下步骤:s1;本实施例采用的整体的联邦定位框架图如图1所示,由于参与联邦的设备具有异构性和动态性,为此设计一种选择控制协议来增强框架的鲁棒性和收敛速度,首先联邦服务器通过选择协议计算设备评分、选择本轮参与更新的设备协议流程图如图2所示。s101;考虑到设备的算力、电量这些条件的差异,需要选择上述条件良好的设备参与本轮的训练中,将归一化后的算力和电量之和作为设备得分,去除得分较低的设备。s102;在确定好被选择的设备后,将定位模型参数随机变量初始化、并定位模型下放到设备。s2;在终端设备上对收集到的wifi指纹数据进行预处理并训练定位模型,具体定位模型图如图3所示。s201;观察到wifi指纹与词袋模型(bow,bagofwords)下的文本在特征和数据规格上有着很高的相似性,所以本实施例通过将wifi指纹文本化来利用文本聚类领域的方法来实现定位,首先将wifi指纹处理成文本,一条wifi指纹(fp)的数据格式如下式:其中,api为第i个无线接入点,maci为第i个无线接入点mac地址,rssii为第i个无线接入点的信号接收强度,lon为经度,la为纬度,i为无线接入点的序号,n为扫描到的无线接入点的总数。s202;定位模型中的一个重要思路是衡量大量ap(无线接入点)特征空间之间的距离特征,也即是文本中词与词的距离,根据文本得到包含距离特征的词向量空间,将词向量空间嵌入到wifi指纹,并对wifi指纹进行特征提取,得到融了和词向量特征的wifi指纹特征空间,并将融了和词向量特征的wifi指纹特征空间进行聚类,以将wifi指纹划分开来,为此首先需要将wifi指纹文本化,将每个wifi信号的wifi信号rssi(信号接收强度)归一化并加入sigmoid函数,引入非线性因子作为词频tf,所述词频tf的公式如下之后为每个无线接入点ap的mac地址建立索引,该索引对应的tf值为索引在文档中的重复出现次数,如上处理后得到的一条文档text的格式如下:上式中,其中,词频e为自然指数,rssi为信号接收强度,word为文本中的词,n为一条文本中词的个数,i为文本中词的序号。s203;为了衡量词与词之间的特征距离,也即是无线接入点ap与无线接入点ap之间的特征距离,采用谷歌提出的word2vec模型训练wifi指纹构成的wifi指纹库,采用cbow模式(连续词袋模型)最终得到室内场景下每个无线接入点ap的词向量表示。s204;由于是以无监督学习的模式来提取特征,但是在神经网络的训练中需要用标签引导训练过程,这里采用降维并二值化的方式构建伪标签来提取粗粒度的特征来一定程度引导神经网络特征的提取。s205;将203步骤训练得到的ap词向量嵌入到wifi指纹中,并格式化wifi指纹后输入至神经网络中,并采用上一步骤得到伪标签引导训练。神经网络的损失函数采用联合损失函数具体如下loss=sum(log(o·label))+sum(log(1-o·(1-label)))其中o为最终输出层的输出向量,label为le降维并二值化后的伪标签,sum()为累计加和函数。s206;在设备训练完特定的epoch后,上传网络权重和本轮训练时间给联邦服务器。s3;联邦服务器等待所有设备上传参数并进行参数聚合;s301;由于终端设备具有可能在训练任务中由于一些原因退出的动态性,服务器不可能无终止的等待所有设备参数,为此服务器在每轮中设置截止时间deadline,超过这个时间后进行聚合。s302;接受到的设备参数达到阈值或时间超过deadline后使用fedavg算法进行参数聚合,完成聚合后重新下放定位模型参数给设备。s4;重复s2到s3,直到定位模型收敛,并提取到网络输出层前一层的深度指纹特征。s5;使用k-means算法对wifi指纹的特征空间进行聚类,如果是楼层定位则聚类的簇数为楼层的层数,如果是平面定位簇数则为超参数。s501;楼层定位的前提下,聚类得到的一簇与一楼层下的指纹对应,需要把聚类结果与标签集对应起来,应用匈牙利算法进行二分图的匹配来得到评估最终楼层分类结果。s502;平面定位的前提下,聚类的簇数为超参数,会从每一个簇中选取一个聚类簇中心最近的指纹特征作为锚点,通过hessianssr半监督回归得到特征空间和经纬度的函数关系。上述方案中,s203中的word2vec采用联邦的方式进行训练,也即对于每个设备上的为覅指纹库再每训练一个epoch后由中心服务器聚合参数。s204中采用的降维方式为拉普拉斯特征映射(le),考虑到这种方式使用的是拉普拉斯图的顶部特征向量,该特征向量的定义基于文本相似性矩阵定义,可以发现指纹特征空间的流形结构,由于降维后的数据为小数无法作为one-hot标签,为此设计的二值化方式为取出每一列的值计算其平均值,这一列上的数大于平均值置1否则置0。s205中的神经网络用的是优化后的dcnn(dynamiccnn),结构图如图4所示,其主要特点是有宽卷积,可以保留指纹的边缘特征,第二点是k-max池化,相对于cnn中的max池化可以保留特征图上的多个信息,第三个则是折叠操作,通过折叠细粒度的特征向量来降低复杂度。s301中设置合适的deadline能大大加速模型的收敛速度,避免服务器死等,为此设计控制协议来计算合适的deadline时间公式如下:上式是计算第j轮设备i训练时间的预估,其中,ti,j第j轮设备i训练的预估时间,j为当前联邦轮数,m为联邦轮数,ti,end为设备i的训练完成的时间戳,ti,start,j为设备i的训练开始的时间戳,这样的加权计算得到的训练估计时间综合考虑设备cpu在近期和历史的负载情况,在此基础上最终的聚合deadline由下式得到其中,min{ddl}表示对ddl不断进行最小化,st.表示约束条件,n为设备的个数,pthreshold为完成训练设备的最小比例,f(ti)为1时表示设备i在全局训练完成的最后时间期限之前完成了训练,f(ti)为0时表示设备i未在全局训练完成的最后时间期限之前完成训练,ti为设备i的训练完成时间,ddl为全局训练完成的最后时间期限。s302中使用fedavg算法进行聚合,相较于经典联邦学习中梯度聚合的方法收敛速度更快,聚合公式如下:其中,wr+1为代表下一轮联邦的定位模型的参数,wr为代表本轮联邦的定位模型的参数,k为联邦设备的序号,m代表设备个数。s502中之所以选择一个聚类簇中心最近的点作为锚点,根据实验数据通过t-sne可视化后的观察,wifi指纹的分布与室内场景的结构布局相似,而在同一个位置多次重复采集经纬度坐标,其均值接近真实坐标,假设同一位置多次采集的经纬度变量符合同一分布,根据中心极限定理,采集次数足够多时,其加和符合高斯分布,均值为真实值的无偏估计,即是次数非足够多的前提下,选取的锚点也是距离真实位置误差最小的特征点。这里结合收集到深圳某商场的wifi指纹数据集进行说明,这种实地采集的数据集具有更强的代表性。具体实施步骤相较于上述步骤增加了部分优化来更适应实际数据,具体的步骤如下。步骤1)联邦服务器初始化定位模型并根据设备上传得分选择设备进行本轮联邦,并下放定位模型给这些设备。步骤2)在进行定位模型的流程前需要对数据进行清洗,考虑到实际场景下存在大量的中庭ap,这些ap由于不属于任何一层,这些ap方便更多设备接入其信号强度由中继器得以加器,但是其存在是对正常ap特征的剥离启副作用,为此首先去除那些多个楼层都频繁出现的ap。步骤3)设备执行图3中的定位模型进行训练,在将wifi指纹转化为词向量时采用上述策略,训练word2vec可能存在单一设备指纹库集合较小导致得到的ap词向量空间表示不充分,这里通过将一条wifi指纹中的ap词进行打乱并复制随机插入到整个指纹库中来起到扩充word2vec文本库的作用;步骤4)wifi指纹文本化后输入到dcnn中的一条wifi指纹向量维度是r218x48,每训练完一个epoch进行一次参数聚合,并输出倒数第二层的深度特征和倒数第一层的预测值,通过le降维后的二值化标签来拟合参数。步骤5)将深度特征进行聚类并应用匈牙利算法和hessianssr回归来分别进行楼层预测和平面预测,实现室内的定位。室内定位由平面定位楼层定位组成,针对楼层定位效果的评估方法是在经过聚类结果向标签集合的指派后,每一个簇中的所有指纹特征都被标注了一个相同的楼层信息,则楼层定位的准确率表示为所有被分到正确楼层的指纹与指纹数之比公式如下:其中,acc为楼层分类的准确度,f(y,o)为某一个样本是否被分类函数,等于1时表示正确分类,等于0时表示未正确分类,y为楼层的真实值,o为楼层的预设值,n为wifi指纹的总数。平面定位的误差单位为米,具体公式如下,由经纬度衡量其中,lon和la分别为预测的经纬度,lonreal和lareal分别为实地采集并标注的真实经纬度。表1为某商场通过本发明的定位方法进行定位前采集的测试数据的数据字段;表2实地采集的室内商场的7层楼层分类效果的混淆矩阵,行代表指纹所属的真实类别,列代表的预测类别,例如第一行第一列代表属于一层的指纹被预测为一层的比例,图5展示的是增加联邦轮次整体定位准确率的变化。表1表2表3位本发明定位方法和现有定位方法的精度对比和构建代价:表3由表3可以看出,本发明定位方法的构建代价少,仅为训练时间,相对于标签,构建成本较小。系统误差(米)构建代价weixingxue5-8标签、室内分布图hanzou2-4标签acmu1.5-3标签、室内分布图waipo3-6标签、磁力计、室内分布图本发明定位方法8.27训练时间当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1