基于异构计算的VR实时自适应传输系统及方法
本发明属于vr自适应传输技术领域,具体涉及基于异构计算的vr实时自适应传输系统及方法。
背景技术:
随着vr的发展,图像数据和计算规模快速膨胀,逐渐衍生出了云vr技术。其将vr与云计算相结合,把复杂的计算处理任务上移至云端,可以有效减轻用户侧的渲染压力。为了实现最小化的响应延迟和带宽需求,云vr采用基于用户视点信息的自适应传输方法,尽可能压缩用户视窗外的冗余图像信息。但是现有的预处理模式自适应传输方案存在两个严重不足。首先是服务的精度较低,由于划分的视频版本的离散且数量有限,服务器只能选择最接近用户视点方向的版本,但始终存在偏差。另一个缺点来自于视频编码,由于视频编码中使用了帧间压缩技术,解码器不能从任意帧开始解码,而必须从被称为随机接入点的参考帧(i帧)开始解码,这就要求服务端传输视频时要保持一个gop(groupofpicture)中的视频版本一致,否则用户端解码将出错。这种要求极大地限制了自适应传输中视频版本切换频率,也导致了用户收到的图像误差增大。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于异构计算的vr实时自适应传输系统和方法,打破了现有方案中多版本视频预生成模式,使得服务端可以依据用户反馈的视点信息实时完成图像变换,有效提升视点刷新频率和视点匹配准确度。同时,利用异构计算进行并行处理加速,使得实时处理变为可能。
本发明的目的可以通过以下技术方案来实现:
现有的多版本预处理方案,通过将投影变换和视频压缩这些复杂耗时的处理过程与服务解耦,希望将实际服务时的处理响应最小化来提升用户接收到的画面质量。但多版本预处理方案主要有两个不足,首先是应用场景受限只能处理vr视频播放这类简单业务。在预处理模式下,要求视频图像可以非实时预先产生,对于vr游戏这类强交互应用则无能为力。将原本的实时视点选择阶段先前调整至投影处理过程中,与投影视点的确定合并为一个模块。这样用户视点的实时响应结果即为投影矩阵旋转的方向,服务端的视点匹配误差不再存在。实时视点的响应与选择在视频压缩之前完成,投影视点可以在每一帧发生切换,大大提高了视点切换的频率。
相比于预处理方案,实时处理模式下完整的投影和视频压缩过程都需要实时地完成。其庞大的计算量和极短的时延要求对于系统的实现提出了很大的挑战。因此,本发明基于异构计算设计了一套高效的vr投影压缩处理方案,包括vr实时自适应传输系统及方法。
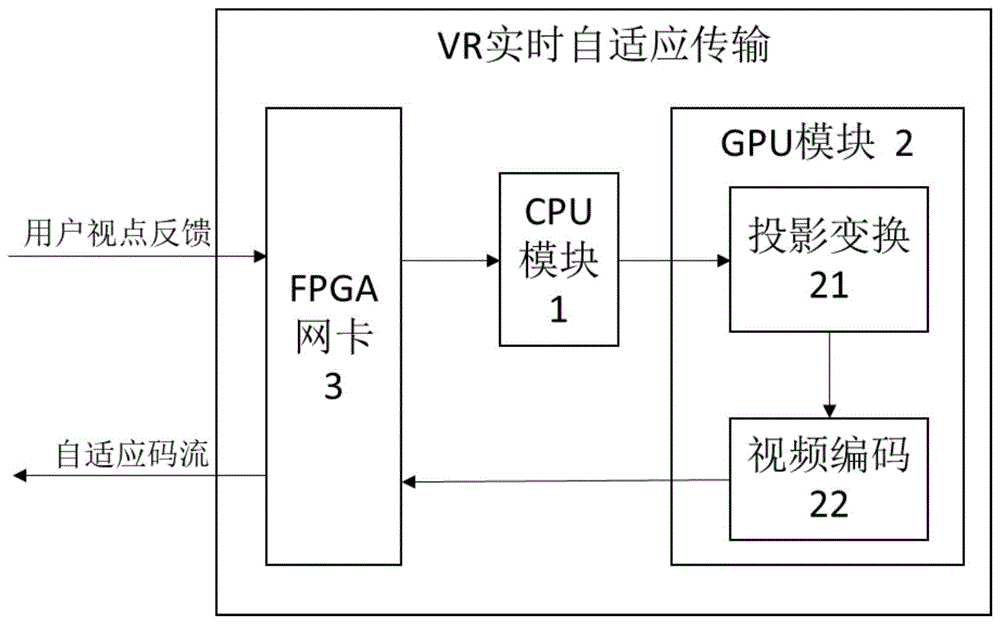
本发明提供的vr实时自适应传输系统,参见图1所示;由cpu模块、gpu模块和fpga网卡相互连接组成,其中,所述cpu模块负责系统的协调与控制;所述gpu模块包含投影变换模块和视频编码模块两部分,分别完成基于用户视点信息的实时投影变换以及自适应码流的视频编码生成,这里,自适应码流由gpu模块根据用户反馈的视点信息实时计算产生,未进行预处理变换;所述fpga网卡负责网络数据包的收发和校验和的计算;所述投影变换模块与cpu模块相连,接收待投影视频帧和实时用户视点,并与视频编码模块相连,将投影后图像进行视频编码;所述视频编码模块在完成编码后输出自适应码流,并直接传输(通过gpudirect)至fpga网卡发送。
本发明中,cpu模块与投影变换模块、cpu模块与fpga网卡、视频编码模块与fpga网卡间均通过pcie总线接口相连。
不同于传统自适应传输方案,本发明中的自适应码流由gpu模块根据用户反馈的视点信息实时计算产生,未进行预处理变换。
本发明中,投影变换模块和视频编码模块均在gpu模块内部完成无需额外的数据传输开销。
视频编码模块使用gpu模块内部集成的视频编码硬件加速器完成。
本发明中,cpu模块与投影变换模块通信的过程使用乒乓缓存进行优化以掩盖传输时间。
本发明中,对于生成好的自适应码流数据视频编码模块直接通过pcie总线的设备直传功能发送至fpga网卡,而不需要cpu模块的额外干涉。
本发明中,cpu模块需要在程序初始化阶段为视频编码模块设置好待传输码流的网络包头,网络包头包含客户端ip地址端口号等信息。码流产生后网络与包头一并送至fpga网卡。
fpga网卡模块在接收到视频编码模块发送的数据包后,为网络包头计算并装填校验和,随后进行网络传输。
基于上述传输系统,本发明的vr实时自适应传输方法,具体步骤如下:
s01,系统经由fpga网卡接收用户实时反馈的视点信息,并通过cpu模块发起gpu处理任务;
s02,gpu模块根据用户视点信息实时进行投影变换处理,产生自适应码流传输至fpga网卡;
s03,fpga网卡为自适应码流计算并装填包头校验和等信息,然后经由网络回传给用户。
步骤s01中,所述cpu模块发起gpu处理任务,包含如下步骤:
s0101,cpu模块接收到用户发出的连接请求后,初始化gpu模块,分配帧乒乓缓存,设置客户端包头;
s0102,cpu模块发起乒乓传输,上传待投影视频帧;
s0103,cpu模块接收到用户实时视点信息后发起下次乒乓传输(异步上传),同时基于已上传帧和用户视点控制gpu启动实时自适应传输处理。
步骤s02中,所述gpu模块根据用户视点信息实时进行投影变换处理,包含如下步骤:
s0201,gpu接收主机传输的实时用户视点信息,并根据这一信息对预先存储在显存中的初始投影矩阵施加旋转变换,通过流处理器并行执行;
s0202,基于变换后的投影矩阵,使用流处理器进行投影变换操作,将最新的erp图像帧变换为金字塔/tsp形式;
s0203,将变换后的图像送入硬件加速器进行视频压缩编码,生成最终的vr自适应码流;
s0204,所生成的vr自适应码流连同预先设置好的网络包头一并发送至fpga网卡,使用pcie总线的设备间直传功能,不需要经过cpu内存。
步骤s03中,所述fpga网卡模块处理部分,包含如下步骤:
s0301,fpga网卡经由pcie总线接收网络数据包;
s0302,校验和计算模块分析完整数据包,分别计算ip和tcp/udp校验和;
s0303,校验和计算模块根据帧结构将计算好的ip和tcp/udp校验和装填到数据包中;
s0304,fpga网卡将完整数据包经由网络协议栈发送。
与现有技术相比,本发明具有以下优点:
(1)本发明调整了基于投影变换的自适应传输处理流程,将投影视点确定和实时视点选择合并为实时处理,不需要预先生成多版本视频;有效克服视点匹配准确度差、切换频率低的问题,大大提升用户的观看体验。
(2)本发明基于异构计算技术设计的系统方案,可以实现极低延时的实时处理,可以满足8k分辨率60fps的vr视频实时自适应传输服务。
附图说明
图1为本实施例的结构示意图。
图2为本实施例cpu与gpu交互示意图。
图3为本实施例软硬件协同网络协议栈示意图。
图4为本实施例cpu模块乒乓传输处理流程图。
图5为本实施例gpu处理流程图。
图6为本实施例校验和模块图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
实施例
为实现基于异构计算的vr实时自适应传输方案,本发明通过以下技术方案来实现,本实施例的结构示意图如图3所示,本发明由相互连接的cpu模块(1)、gpu模块(2)和fpga网卡(3)共同组成的异构计算系统完成vr实时自适应传输,具体设计如下。
(1)cpu模块(1)设计
所述的cpu模块(1)负责完整系统的协调与控制任务,在数据处理和网络传输任务中均起到关键作用。其工作流程为:
(1.1)cpu模块(1)接收到用户发出的连接请求后,初始化gpu模块,分配帧乒乓缓存(图2),设置客户端包头(图3)。
(1.2)cpu模块(1)与gpu模块(2)通信,使用乒乓缓存(23)优化传输,如图4所示,通过乒乓缓存交替上传待投影视频帧,以掩盖传输时间。
(1.2.1)在该模式下,系统服务的响应以及erp帧的上传均由同一个线程完成。
(1.2.2)在对第n帧执行投影变换前,服务线程首先发起第n+1帧的异步非阻塞上传操作,之后不等待传输完毕,立即返回继续第n帧处理。
(1.2.3)当下次服务开始时第n+1帧已经上传完成,原本第n帧缓存已处在空闲状态,此时切换乒乓缓存开始下一轮处理。
(2)gpu模块(2)设计
所述的gpu模块(2)主要包含了投影变换模块(21)和视频编码模块(22)两部分,分别完成基于用户视点信息的实时投影变换以及自适应码流的视频编码生成。所述投影变换模块(21)与cpu模块(1)相连,接收待投影视频帧和实时用户视点,并与视频编码模块(22)相连,将投影后图像进行视频编码,具体的投影编码处理流程如图5所示。
(2.1)初始投影矩阵计算:假设用户视点方向为极坐标(0,0),因此初始重映射矩阵mi为固定值,可以预先计算生成mi。其中的每个元素iij是相应像素的重映射索引。对于金字塔/tsp投影可以根据其2d到3d坐标映射关系计算出相应的初始重映射矩阵mi。
(2.2)投影视点确定:给定一个新的用户视点中心极坐标(
(2.3)投影矩阵旋转:根据用户视点方向调整投影矩阵,对初始重映射矩阵mi中的每个点施加旋转变换r,调整目标图形的视点朝向为(
mp中每个投影点pij可以由mi中对应点iij经过视点方向的旋转变换得到:
(2.4)投影处理:得到了目标图像中每个点在金字塔上对应的三维直角坐标,可以进行投影变换。将其转换为极坐标并用于索引全景图中的像素。设原始erp全景图长为w宽为h,则投影后图形可以如下填充。
(2.5)视频压缩:经过初始矩阵选择和投影变换后产生的图像直接传入nvenc中进行视频压缩编码,在实现高效运算的同时也降低了数据传输的开销。
(2.6)传输:所述视频编码模块(22)在完成编码后输出自适应码流,与初始化包头一并通过gpudirect直接传输至fpga网卡(3)发送传输。
(3)fpga网卡(3)
所述的fpga网卡(3)负责网络数据包的收发和校验和计算模块(31),如图3所示。
(3.1)如图6,所述的校验和模块(31)完成ip和tcp/udp校验和的计算和装填。
(3.1.1)校验和计算模块(311)分析完整数据包,分别计算出ip和tcp/udp校验和。
(3.1.2)完整数据包流过校验和计算模块后暂存到数据包队列(313)中,而计算得到的校验和暂存在校验和队列(312)中。
(3.1.3)校验和装填模块(314)从两个队列中取出校验和和数据包,并根据帧结构将计算好的ip和tcp/udp校验和装填到数据包中。
(3.2)所述的网络数据包收发通过xilinx提供的以太网物理层和mac层ip核完成。
以上所述,仅是本发明的较佳实例,本发明所主张的权利范围并不局限于此。本发明还有其他多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员可根据本发明作出各种相应的改变和变形,但这些改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!