一种基于大数据的舆情聆听系统的制作方法
本发明涉及互联网信息处理技术领域,具体为一种基于大数据的舆情聆听系统。
背景技术:
从传统的社会学理论上讲,舆情本身是民意理论中的一个概念,它是民意的一种综合反映。从现代舆情理论的严格意义上讲,舆情本身并不是对民意规律的简单概括,而是对“民意及其作用于执政者及其政治取向规律”的一种描述。在实际工作中,舆情信息员对舆情概念的理解,必须把握四层义:1.舆情是民意集合的反映。换句话说,民意是形成舆情的始源,没有民意,就没有舆情;2.舆情所要反映的民意,是那些对执政者决策行为能够产生影响的“民意”,而非民意的全部;3.舆情因变事项是舆情产生的基础,研究、分析舆情,首先要深入研究、分析舆情因变事项的发生、发展和变化的规律;4.舆情空间对舆情传播及其对执政者决策行为的影响有重要作用。
但是,现有舆情聆听系统对于数据采集方面不够全面,监测结果易受恶意用户灌水评论产生偏差,掩盖民众自然形成的正常舆情,导致网络舆情监控失去可靠性;因此,不满足现有的需求,对此我们提出了一种基于大数据的舆情聆听系统。
技术实现要素:
本发明的目的在于提供一种基于大数据的舆情聆听系统,以解决上述背景技术中提出的现有舆情聆听系统对于数据采集方面不够全面,监测结果易受恶意用户灌水评论产生偏差,掩盖民众自然形成的正常舆情,导致网络舆情监控失去可靠性的问题。
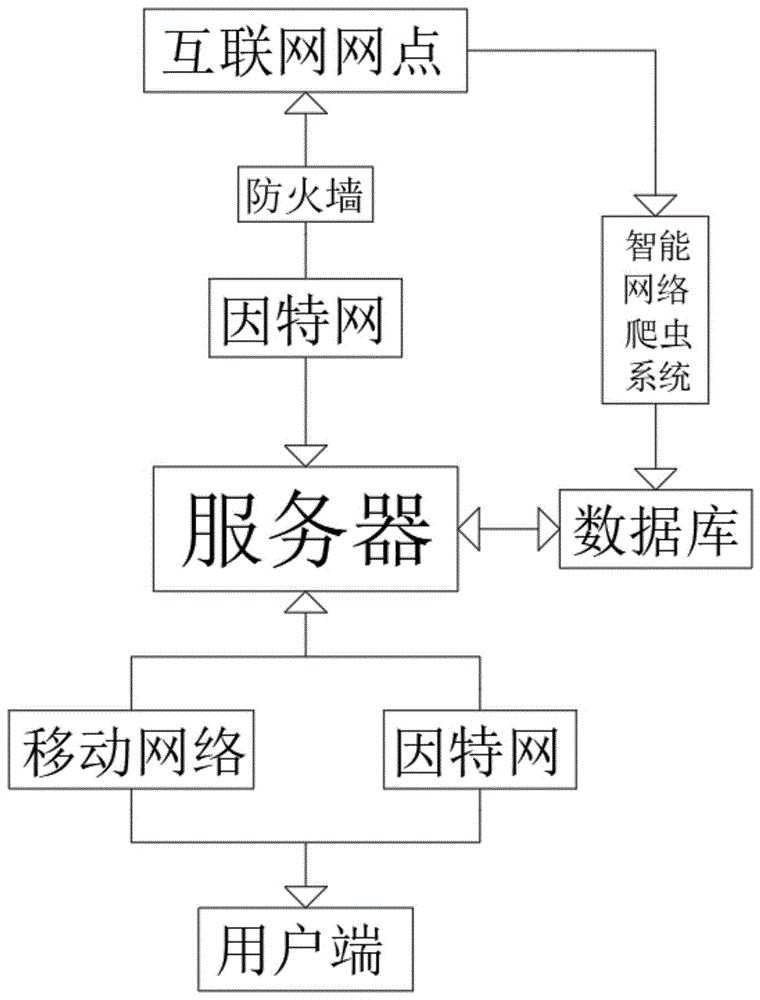
为实现上述目的,本发明提供如下技术方案:一种基于大数据的舆情聆听系统,包括服务器、数据库、智能网络爬虫系统、互联网网点和用户端,所述服务器的输入端通过因特网或无线网络与用户端双向连接,所述服务器的输出端通过因特网与互联网网点双向连接,所述服务器与互联网网点的连接处设置有防火墙,所述互联网网点的输出端通过智能网络爬虫系统与数据库的输入端连接,所述数据库与服务器双向连接,所述智能网络爬虫系统的内部设置有采集模块和分析聆听模块。
优选的,所述互联网网点包括微博、博客、社区论坛网址、信息资讯网址、政府机构网址、新闻资讯网址、媒体网站、视频网站、搜索引擎以及社交网站。
优选的,所述微博包括新浪微博、腾讯微博、网易微博、搜狐微博等,博客包括新浪博客、腾讯博客、网易博客、博客网等,社区论坛网址包括天涯论坛、新浪论坛、网易论坛、搜狐社区等,信息资讯网址包括行业资讯网、地方信息网等,政府机构网址包括中国政府网、首都之窗等,新闻资讯网址包括网易、人民网、新浪网等,媒体网站包括人民日报,中国日报等,视频网站包括youtube、优酷、腾讯视频、爱奇艺等,搜索引擎包括谷歌、百度、搜狗等,社交网站包括facebook、豆瓣、qq、微信等。
优选的,所述采集模块包括智能提取、关键词检索、全文索引、智能去重和分类存储。
优选的,所述智能提取包括标题、文章或评论、作者、日期、来源提取。
优选的,所述智能去重包括url去重、标题去重和正文去重。
优选的,所述分析聆听模块包括ip地址查重、智能初步分析和人工二次分析。
优选的,所述智能初步分析的信息包括网址,点击数,回复数,转发数等。
与现有技术相比,本发明的有益效果是:
1、本发明通过对智能网络爬虫系统获取的舆情信息进行ip地址查重处理,将相同ip地址发送出的舆情信息进行整合,再对其所在的网址,点击数,回复数,转发数等进行初步分析,依次为基础,经由舆情分析人员进行数据信息的二次加工处理,从而得出较为准确、合理的分析信息,若相同ip地址存在若干条相似舆情信息,即判断为恶意灌水,工作人员将其上传至数据库后,可由服务器向防火墙发送信息,对该ip进行封禁,阻止其继续访问网站,而民众自然形成的正常舆情,则在存储至数据库后,由服务器上传至网站等信息载体,将分析内容进行展示,方便查看,避免了现有舆情聆听系统对于数据采集方面不够全面,监测结果易受恶意用户灌水评论产生偏差,导致网络舆情监控失去可靠性的问题发生。
2、本发明通过在该系统内设置互联网网点作为信息采集源,互联网网点包括微博、博客、社区论坛网址、信息资讯网址、政府机构网址、新闻资讯网址、媒体网站、视频网站、搜索引擎以及社交网站,涉猎范围广,可从各个方面进行舆情信息的采集,数据较为全面。
3、通过采用智能提取,采集模块在提取舆情数据时,仅截取ip地址、标题、文章或评论、作者、日期和来源信息,过滤掉广告等无用的垃圾信息,有效减少了数据库负担。
4、通过采用智能去重,智能去重包括url去重、标题去重和正文去重,通过三种方式,有效去除重复或相似内容,进一步减小数据库负担,且方便后续的查询以及检索。
5、通过采用智能初步分析,智能初步分析信息包括网址,点击数,回复数,转发数等,经由以上数据,可判断该舆论的重要度,并且仅将重要度较高的舆情转移至人工二次分析阶段,降低工作人员的工作负担,提高了舆情分析效率
6、通过采用人工二次分析,在系统初步分析的基础上,经由舆情分析人员进行数据信息的二次加工处理,从而得出更加准确、合理的分析信息,进一步降低用户恶意灌水评论,掩盖民众自然形成的正常舆情的情况发生。
附图说明
图1为本发明的整体结构示意图;
图2为本发明的智能网络爬虫系统结构示意图;
图3为本发明的互联网网点结构示意图;
图4为本发明的采集模块结构示意图;
图5为本发明的分析聆听模块结构示意图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
请参阅图1-5,本发明提供的一种实施例:一种基于大数据的舆情聆听系统,包括服务器、数据库、智能网络爬虫系统、互联网网点和用户端,服务器的输入端通过因特网或无线网络与用户端双向连接,服务器的输出端通过因特网与互联网网点双向连接,服务器与互联网网点的连接处设置有防火墙,互联网网点的输出端通过智能网络爬虫系统与数据库的输入端连接,数据库与服务器双向连接,智能网络爬虫系统的内部设置有采集模块和分析聆听模块。
进一步,互联网网点包括微博、博客、社区论坛网址、信息资讯网址、政府机构网址、新闻资讯网址、媒体网站、视频网站、搜索引擎以及社交网站,设置多网点共同采集舆论数据,可从多方面多信息进行采集,数据较为全面。
进一步,微博包括新浪微博、腾讯微博、网易微博、搜狐微博等,博客包括新浪博客、腾讯博客、网易博客、博客网等,社区论坛网址包括天涯论坛、新浪论坛、网易论坛、搜狐社区等,信息资讯网址包括行业资讯网、地方信息网等,政府机构网址包括中国政府网、首都之窗等,新闻资讯网址包括网易、人民网、新浪网等,媒体网站包括人民日报,中国日报等,视频网站包括youtube、优酷、腾讯视频、爱奇艺等,搜索引擎包括谷歌、百度、搜狗等,社交网站包括facebook、豆瓣、qq、微信等,信息源充足,确保舆论获取全面。
进一步,采集模块包括智能提取、关键词检索、全文索引、智能去重和分类存储,智能提取能够提取文章或评论中的重要信息,以及该条信息发送人的ip地址,经由关键词检索查找出文章或评论中出现频率较高的关键词,由全文索引查找每个词条的出现频率,以此为基准建立一个以词库为目录的索引,智能去除重复以及相似的内容,并通过关键词以及词库的匹配进行分类存储。
进一步,智能提取包括信息源的ip地址,标题、文章或评论、作者、日期、来源提取,仅对关键内容进行提取,过滤掉广告等无用的垃圾信息,有效减少数据库负担。
进一步,智能去重包括url去重、标题去重和正文去重,通过三种方式,有效去除重复或相似内容,进一步减小数据库负担,且方便查询以及检索。
进一步,分析聆听模块包括ip地址查重、智能初步分析和人工二次分析,系统对舆情发送人的ip地址进行整理,将相同ip地址发送出的舆情信息进行整合,再对其所在的网址,点击数,回复数,转发数等进行初步分析,在此基础上,经由舆情分析人员进行数据信息的二次加工处理,从而得出较为准确、合理的分析信息,若相同ip地址存在若干条相似舆情信息,即判断为恶意灌水信息,可通过后上传至数据库后,由服务器向防火墙发送信息,对该ip进行封禁,阻止其继续访问网站,而民众自然形成的正常舆情,则在存储至数据库后,由服务器上传至网站等信息载体,将分析内容进行展示,方便查看。
进一步,智能初步分析的信息包括网址,点击数,回复数,转发数等,经由以上数据,可判断该舆论的重要度,仅将重要度较高的舆情转移至人工二次分析阶段,降低工作人员的工作负担,提高了舆情分析效率。
工作原理:使用时,用户通过因特网或无线网络登录服务器,依靠网络进入互联网网点,在网站上发表自己的舆论信息,而该系统基于智能网络爬虫系统运行,首先由系统内的采集模块对互联网网点进行舆情信息的采集,互联网网点包括微博、博客、社区论坛网址、信息资讯网址、政府机构网址、新闻资讯网址、媒体网站、视频网站、搜索引擎以及社交网站,其中,微博为新浪微博、腾讯微博、网易微博、搜狐微博等,博客为新浪博客、腾讯博客、网易博客、博客网等,社区论坛网址为天涯论坛、新浪论坛、网易论坛、搜狐社区等,信息资讯网址为行业资讯网、地方信息网等,政府机构网址为中国政府网、首都之窗等,新闻资讯网址为网易、人民网、新浪网等,媒体网站为人民日报,中国日报等,视频网站为youtube、优酷、腾讯视频、爱奇艺等,搜索引擎为谷歌、百度、搜狗等,社交网站为facebook、豆瓣、qq、微信等,设置多网点共同采集舆论数据,涉猎范围广,数据更为全面,信息的采集过程为智能提取,仅提取信息源的ip地址、标题、文章或评论、作者、日期以及来源,过滤掉广告等无用的垃圾信息,有效减少数据库负担,再经由关键词检索查找出文章或评论中出现频率较高的关键词,由全文索引查找每个词条的出现频率,以此为基准建立一个以词库为目录的索引,依靠url去重、标题去重和正文去重三种方式智能去除重复以及相似的内容,并通过关键词以及词库的匹配进行分类存储,存储后的信息首先由分析聆听模块进行ip地址查重,将相同ip地址发送出的舆情信息进行整合,再对其所在的网址,点击数,回复数,转发数等进行初步分析,在此基础上,经由舆情分析人员进行数据信息的二次加工处理,从而得出较为准确、合理的分析信息,若相同ip地址存在若干条相似舆情信息,即判断为恶意灌水信息,可通过后上传至数据库后,由服务器向防火墙发送信息,对该ip进行封禁,阻止其继续访问网站,而民众自然形成的正常舆情,则在存储至数据库后,由服务器上传至网站等信息载体,将分析内容进行展示,方便查看。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
- 还没有人留言评论。精彩留言会获得点赞!