一种高精度的室内定位追踪方法
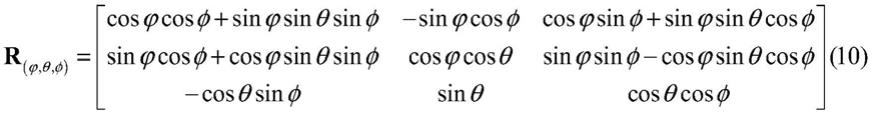
1.本发明涉及室内目标物定位追踪领域,尤其涉及一种高精度的室内定位追踪方法。
背景技术:
2.随着近几年无线定位技术的快速发展,复杂室内环境中的高精度定位受到越来越多的关注。复杂的室内环境中,存在大量的物体遮挡和频繁的人员走动,产生的非视距(non
‑
line
‑
of
‑
sight,nlos)环境使得传统的定位方法受到限制,导致测距误差增大,进而导致定精度降低。研究人员提出利用uwb(超宽带,ultra
‑
wideband)技术和imu(惯导,inertial measurement unit)技术对室内移动目标物进行定位与追踪。一方面,uwb无线信号带宽大,具有很强的穿透性,可以穿透墙壁和隔断,在室内定位领域具有较广泛的应用;另一方面,imu对移动目标物的运动轨迹具有较好的追踪。二者的联合定位,优势互补,将极大地提高室内移动目标物的定位估计精度。
3.近年来,研究人员利用多种方法对uwb和imu的联合定位展开研究。在工业物联网环境中,人们利用卡尔曼滤波和扩展卡尔曼滤波的方法,设计了一种传感器追踪方法,该方法验证了联合定位方法在物联网领域中得以实现。此外,人们根据仿生学原理,将uwb和imu与生物力学模型相结合,提出运动捕捉算法来跟踪移动目标物的位置和姿态。并且,研究人员采用紧耦合的传感器融合方法,结合uwb和imu的测量信息,验证联合估计系统的有效性和可靠性。
4.尽管uwb和imu混合定位系统得到了初步的研究,但是,在复杂的室内环境中,传统的方法受到的折射、反射等干扰较大。因此,稳定可靠的室内混合定位方法亟需探索研究。
技术实现要素:
5.发明目的:为解决背景技术中存在的技术问题,本发明提出一种高精度的室内定位追踪方法,提出一种新颖的联合定位追踪系统(huid系统),该系统利用深度置信网络(deep belief networks,dbn)将uwb和imu的估计信息相结合,充分利用环境中的信道状态信息,估计移动目标物的位置坐标,实现高精度的定位与追踪技术。
6.本发明方法具体包括:
7.步骤1,利用三边定位法,设计超宽带uwb定位系统,估计目标物的位置坐标
8.步骤2,利用惯导imu设备,设计惯导imu定位方法,估计目标物的位置坐标
9.步骤3,基于和利用深度置信网络dbn设计huid联合定位系统。
10.步骤1包括:
11.步骤1.1:基于超宽带uwb设备,利用三边定位法完成对目标物的位置估计:
12.考虑一个典型的室内定位场景,该场景中包含了多个基站和一个标签。设第i个基站的坐标为p
i
=[p
x,i
,p
y,i
]
t
,p
x,i
和p
y,i
分别表示第i个基站的横坐标和纵坐标,
表示基站数目的集合,n
b
为基站的总数目,未知位置的标签坐标为u
n
=[u
x,n
,u
y,n
]
t
,n表示测量过程中的第n个测量点,表示测量点的集合,n为测量点的总数目。
[0013]
设定标签在第n个测量点与第i个基站的估计距离为利用三边定位法,则估计的目标物的位置坐标为:
[0014][0015]
最后,利用最小二乘法可获得上述问题的解。然而,在室内环境中,uwb的测距信息容易受到nlos环境的影响,进而导致定位误差增大。因此,需要对nlos进行识别,然后针对识别结果,对测距误差进行修正。
[0016]
步骤1.2:利用随机森林分类器完成对非视距nlos环境的分类识别:
[0017]
基于归一化接收信号的方差、平均时延扩展、均方根时延扩展和峭度参数,利用随机森林分类器对nlos环境进行识别。定义训练集其中φ
i,n
和z
i,n
∈{
‑
1,1}分别表示目标物在第n个测量点接收到第i个基站的信号特征和标签,z
i,n
=1表示视距los环境,z
i,n
=
‑
1表示非视距nlos环境;
[0018]
将随机森林分类器中决策树的节点分裂前的基尼系数定义为:
[0019][0020]
其中,pr(z
i,n
=
‑
1)表示训练集中非视距nlos出现的概率。基于特征ξ∈φ
i,n
,设定将数据集分裂为和两个子集,每个子集分别含有l1和l2组数据,则节点分裂后的基尼系数为:
[0021][0022]
则基尼系数增益gig表示为:
[0023][0024]
根据基尼系数增益,得到每个节点的分裂准则,基于分裂准则构建决策树模型,进而构建随机森林,对视距los和非视距nlos环境进行识别;
[0025]
基于上述准则,随机森林的构建步骤如下:
[0026]
步骤一:从数据集中随机有放回地选择部分数据,组成采样集;
[0027]
步骤二:从特征中随机无放回地选择部分特征用于训练决策树,组成训练子集
[0028]
步骤三:根据分裂准则,训练每一棵决策树,多个决策树组成随机森林模型。
[0029]
其中,单个决策树的训练过程如下:
[0030]
步骤一:对于给定的训练子集计算其基尼系数;
[0031]
步骤二:遍历所有特征对应的基尼系数增益,选择最大的增益及其对应的特征;
[0032]
步骤三:分裂决策树中的每一个节点,直到终止条件满足,生成决策树。
[0033]
最后,基于构建的随机森林模型,对los和nlos环境进行识别。
[0034]
步骤1.3:利用随机森林回归器完成对超宽带uwb测距误差修正:
[0035]
基于上述分类结果,利用随机森林回归器对uwb测距误差进行修正。定义回归训练集ε
i,n
表示在第n个测量点与第i个基站的测距误差,即:
[0036][0037]
其中,d
i,n
表示在第n个测量点与第i个基站的真实距离。
[0038]
基于特征ζ∈φ
i,n
,将分裂为和两个子集,其节点分裂准则用均方误差代替,即:
[0039][0040]
其中,c1和c2分别表示和的方差,表示分裂后的子集与第i个基站测距误差,表示分裂后的子集与第i个基站测距误差;在每个节点分裂到不再分裂时,设定分裂成了g个子集,则经过随机森林回归器的回归误差为:
[0041][0042]
其中,含有s组数据,表示第u个决策树中第g个子集,u表示决策树的数量。因此,修正的超宽带uwb测距值表示为:
[0043][0044]
根据修正的测距值,公式(1)中估计的欧氏距离重新定义为在视距los环境中,在非视距nlos环境中,超宽带uwb定位系统的目标物的位置坐标为:
[0045][0046]
步骤2包括:
[0047]
imu设备通过加速度计和陀螺仪的信息估计目标物的姿态,进而确定位置和运动轨迹。定义绕设备坐标系z轴、x轴、y轴的旋转角度为θ、φ,则旋转矩阵可表示为:
[0048][0049]
则参考坐标系(即地球坐标系)和设备坐标系之间的转换关系为:
[0050][0051]
为简化旋转矩阵的求解过程,引入四元数法求解。定义归一化的四元数q为:
[0052]
q=[q0,q1,q2,q3]
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0053]
其中,q0,q1,q2,q3表示四元数中的四个归一化分量。则第n
‑
1点的四元数q
n
‑1更新为第n个点的四元数q
n
的更新方程为:
[0054][0055]
其中,ω
n
‑1表示第n
‑
1点的更新矩阵,即:
[0056][0057]
δt表示采样间隔,分别表示在设备坐标系下第n
‑
1个点的绕x轴、y轴、z轴的旋转角度。
[0058]
因此,旋转矩阵可重新定义为:
[0059][0060]
在第n点获得惯导imu定位方法估计的目标物位置坐标表达式为:
[0061][0062]
其中,
[0063][0064][0065]
和分别定义为第n
‑
1个点的速度和加速度的值,为单位向量,g=9.81m/s2表示重力加速度。
[0066]
huid定位系统:
[0067]
步骤3包括:将uwb和imu的估计值结合,所述huid联合定位系统估计的位置坐标表示为:
[0068][0069]
其中,和分别表示超宽带uwb的系数和惯导imu的系数,并将α
n
和β
n
作为指纹信息用于深度置信网络dbn训练。
[0070]
步骤3中,采用如下方法进行深度置信网络dbn训练:
[0071]
在训练阶段,根据目标物的真实位置u
n
和估计位置得到:
[0072][0073]
然后,构建dbn框架,dbn包含三个受限玻尔兹曼机(restricted boltzmann machines,rbms)和一个反馈神经网络,其构建过程包含三个阶段:预训练、重构和反向传输。每一个rbm都是基于能量函数的无向图模型,其中包含一层可见神经元和一层隐藏神经元,并且,上一层rbm的输出值作为下一层rbm的输入。
[0074]
定义和分别为第k个受限玻尔兹曼机rbm的可见层神经元和隐藏层神经元,分别表示可见层神经元中第i个元素和隐藏层神经元中第i个元素,i=1,
…
,m
k
,j=1,
…
,n
k
,m
k
和n
k
分别表示可见层神经元和隐藏层神经元的数量,下标k∈{1,2,3},为减少训练数据的维度,设定n1>n2>n3。定义和表示第k个受限玻尔兹曼机rbm的可见层v
(k)
的偏差和隐藏层h
(k)
的偏差,分别表示对应的可见层神经元的偏差和隐藏层神经元的偏差,定义w
(k)
表示v
(k)
和h
(k)
之间的连接权值,即:
[0075][0076]
其中,表示连接可见层和隐藏层对应元素和的权值;
[0077]
预训练阶段:
[0078]
第k个受限玻尔兹曼机rbm的能量e(v
(k)
,h
(k)
)表示为:
[0079]
e(v
(k)
,h
(k)
)=
‑
(a
(k)
)
t
v
(k)
‑
(h
(k)
)
t
w
(k)
v
(k)
‑
(b
(k)
)
t
h
(k)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(22)
[0080]
联合概率分布pr(v
(k)
,h
(k)
)为:
[0081][0082]
其中,中间参数因此,得到v
(k)
的概率分布pr(v
(k)
)为:
[0083][0084]
最小化第k个受限玻尔兹曼机rbm的对数损失函数以获得最优的参数w
(k)
,a
(k)
和b
(k)
,等价表示为
[0085][0086]
针对上述优化问题的解,使用传统的梯度下降法中求偏导过程复杂,因此引入对比散度cd
‑
1算法求解该问题,即:
[0087][0088][0089][0090]
其中,表示可见层的重构向量。
[0091]
在(26)中,表示在给定v
(k)
时,被激活的概率,其表达式为:
[0092][0093]
其中,sigmoid(
·
)表示受限玻尔兹曼机rbm的激活函数,表示w
(k)
中第i列元素;利用吉布斯采样法,即给定阈值表示均匀分布:
[0094][0095]
则可得到隐藏层h
(k)
。然后,得到条件概率分布函数
[0096][0097]
同理,利用吉布斯采样法得到重构向量进而得到:
[0098][0099]
其中,表示w
(k)
中第i行元素。最后,参数w
(k)
,a
(k)
和b
(k)
的更新方程表示为
[0100][0101]
[0102][0103]
其中,γ表示学习速率。
[0104]
重构阶段:
[0105]
基于在预训练阶段中更新的w
(k)
,b
(k)
和h
(k)
,得到条件概率分布函数为:
[0106][0107]
其中,k=3,2,1,表示重构的隐藏层,且因此,利用吉布斯采样,得到重构向量反向传输阶段:
[0108]
在反向传输阶段,基于重构数据和原始输入数据的均方误差,利用反馈神经网络更新权重和偏差。定义参数则第k层的均方误差j
(k)
(θ)为:
[0109][0110]
其中,ξ
(k
‑
1)
表示第k
‑
1层元素的数量,k=3,2,1,
[0111]
然后,利用梯度下降法更新参数θ,即:
[0112][0113][0114]
其中,υ表示学习速率。
[0115]
整个dbn训练过程如下所示:
[0116]
步骤一:计算n个测量点的归一化接收信号幅度
[0117]
步骤二:估计每个测量点的和
[0118]
步骤三:利用(20)计算α
n
和β
n
;
[0119]
步骤四:预训练阶段,利用(31)更新第k个rbm的参数w
(k)
,a
(k)
和b
(k)
;
[0120]
步骤五:重构阶段,利用(32)计算重构向量
[0121]
步骤六:反向传输阶段,利用(34)更新w
(k)
和b
(k)
;
[0122]
步骤七:输出数据
[0123]
基于构建的深度置信网络dbn,利用径向基函数r
n
估计移动目标物的坐标,即:
[0124]
[0125]
其中,表示目标物在第n个点的受限玻尔兹曼机rbm第三层输出数据,表示的方差,λ表示方差系数。因此,估计的参数和表示为:
[0126][0127][0128]
最终,将上述估计参数代入(19)中估计移动目标物的位置
[0129]
有益效果:本技术实施例提供了一种高精度室内定位追踪方法,包括:步骤一,利用uwb实现目标物的定位,其中,uwb的测距误差由随机森林分类器和回归器进行修正,进而提高了定位精度。步骤二,利用imu实现对目标物的姿态估计,基于四元数法完成轨迹追踪。步骤三,建立混合定位系统模型,利用dbn连接uwb和imu的位置估计信息。该混合系统充分利用uwb和imu的互补优势,一方面,利用uwb缓解imu的漂移误差,另一方面,利用imu进一步提高uwb的定位精度。所设计混合定位系统,有效地提高的室内移动目标物的定位和追踪精度。
附图说明
[0130]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
[0131]
图1为系统模型图;
[0132]
图2为随机森林分类器的结构模型图;
[0133]
图3a为dbn模型图前传阶段示意图;
[0134]
图3b为dbn模型图反馈阶段示意图;
[0135]
图4为测量场景图;
[0136]
图5为随机森林分类器的分类效果随决策树的深度和数目的变化示意图;
[0137]
图6为随机森林回归器在los和nlos环境中,对测距误差修正效果的误差累积分布图;
[0138]
图7为测距误差修正前后,定位误差的对比图;
[0139]
图8为huid联合定位系统中,定位均方误差随着径向基函数参数λ的变化曲线;
[0140]
图9为实测系统中移动目标物的轨迹追踪示意图;
[0141]
图10为所提联合定位系统与单个定位方法之间的定位误差均值和方差的对比图;
[0142]
图11为所提联合系统与传统定位系统的定位误差累积分布图对比。
具体实施方式
[0143]
本发明提供了一种高精度的室内定位追踪方法,本发明方法具体包括:
[0144]
步骤1,利用三边定位法,设计超宽带uwb定位系统,估计目标物的位置坐标
[0145]
步骤2,利用惯导imu设备,设计惯导imu定位方法,估计目标物的位置坐标
[0146]
步骤3,基于和利用深度置信网络dbn设计huid联合定位系统。
[0147]
步骤1包括:
[0148]
步骤1.1:基于超宽带uwb设备,利用三边定位法完成对目标物的位置估计:
[0149]
考虑一个典型的室内定位场景,该场景中包含了多个基站和一个标签。设第i个基站的坐标为p
i
=[p
x,i
,p
y,i
]
t
,p
x,i
和p
y,i
分别表示第i个基站的横坐标和纵坐标,表示基站数目的集合,n
b
为基站的总数目,未知位置的标签坐标为u
n
=[u
x,n
,u
y,n
]
t
,n表示测量过程中的第n个测量点,表示测量点的集合,n为测量点的总数目。
[0150]
设定标签在第n个测量点与第i个基站的估计距离为利用三边定位法,则估计的目标物的位置坐标为:
[0151][0152]
最后,利用最小二乘法可获得上述问题的解。然而,在室内环境中,uwb的测距信息容易受到nlos环境的影响,进而导致定位误差增大。因此,需要对nlos进行识别,然后针对识别结果,对测距误差进行修正。
[0153]
步骤1.2:利用随机森林分类器完成对非视距nlos环境的分类识别:
[0154]
基于归一化接收信号的方差、平均时延扩展、均方根时延扩展和峭度参数,利用随机森林分类器对nlos环境进行识别。定义训练集其中φ
i,n
和z
i,n
∈{
‑
1,1}分别表示目标物在第n个测量点接收到第i个基站的信号特征和标签,z
i,n
=1表示视距los环境,z
i,n
=
‑
1表示非视距nlos环境;
[0155]
将随机森林分类器中决策树的节点分裂前的基尼系数定义为:
[0156][0157]
其中,pr(z
i,n
=
‑
1)表示训练集中非视距nlos出现的概率。基于特征ξ∈φ
i,n
,设定将数据集分裂为和两个子集,每个子集分别含有l1和l2组数据,则节点分裂后的基尼系数为:
[0158][0159]
则基尼系数增益gig表示为:
[0160][0161]
根据基尼系数增益,得到每个节点的分裂准则,基于分裂准则构建决策树模型,进而构建随机森林,对视距los和非视距nlos环境进行识别;
[0162]
基于上述准则,随机森林的构建步骤如下:
[0163]
步骤一:从数据集中随机有放回地选择部分数据,组成采样集;
[0164]
步骤二:从特征中随机无放回地选择部分特征用于训练决策树,组成训练子集
[0165]
步骤三:根据分裂准则,训练每一棵决策树,多个决策树组成随机森林模型。
[0166]
其中,单个决策树的训练过程如下:
[0167]
步骤一:对于给定的训练子集计算其基尼系数;
[0168]
步骤二:遍历所有特征对应的基尼系数增益,选择最大的增益及其对应的特征;
[0169]
步骤三:分裂决策树中的每一个节点,直到终止条件满足,生成决策树。
[0170]
最后,基于构建的随机森林模型,对los和nlos环境进行识别。
[0171]
步骤1.3:利用随机森林回归器完成对超宽带uwb测距误差修正:
[0172]
基于上述分类结果,利用随机森林回归器对uwb测距误差进行修正。定义回归训练集ε
i,n
表示在第n个测量点与第i个基站的测距误差,即:
[0173][0174]
其中,d
i,n
表示在第n个测量点与第i个基站的真实距离。
[0175]
基于特征ζ∈φ
in
,将分裂为和两个子集,其节点分裂准则用均方误差代替,即:
[0176][0177]
其中,c1和c2分别表示和的方差,表示分裂后的子集与第i个基站测距误差,表示分裂后的子集与第i个基站测距误差;在每个节点分裂到不再分裂时,设定分裂成了g个子集,则经过随机森林回归器的回归误差为:
[0178][0179]
其中,含有s组数据,表示第u个决策树中第g个子集,u表示决策树的数量。因此,修正的超宽带uwb测距值表示为:
[0180][0181]
根据修正的测距值,公式(1)中估计的欧氏距离重新定义为在视距los环境中,在非视距nlos环境中,超宽带uwb定位系统的目标物的位置坐标为:
[0182][0183]
步骤2包括:
[0184]
imu设备通过加速度计和陀螺仪的信息估计目标物的姿态,进而确定位置和运动
轨迹。定义绕设备坐标系z轴、x轴、y轴的旋转角度为θ、φ,则旋转矩阵可表示为:
[0185][0186]
则参考坐标系(即地球坐标系)和设备坐标系之间的转换关系为:
[0187][0188]
为简化旋转矩阵的求解过程,引入四元数法求解。定义归一化的四元数q为:
[0189]
q=[q0,q1,q2,q3]
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0190]
其中,q0,q1,q2,q3表示四元数中的四个归一化分量。则第n
‑
1点的四元数q
n
‑1更新为第n个点的四元数q
n
的更新方程为:
[0191][0192]
其中,ω
n
‑1表示第n
‑
1点的更新矩阵,即:
[0193][0194]
δt表示采样间隔,分别表示在设备坐标系下第n
‑
1个点的绕x轴、y轴、z轴的旋转角度。
[0195]
因此,旋转矩阵可重新定义为:
[0196][0197]
在第n点获得惯导imu定位方法估计的目标物位置坐标表达式为:
[0198][0199]
其中,
[0200][0201][0202]
和分别定义为第n
‑
1个点的速度和加速度的值,为单位向量,g=9.81m/s2表示重力加速度。
[0203]
huid定位系统:
[0204]
步骤3包括:将uwb和imu的估计值结合,所述huid联合定位系统估计的位置坐标
表示为:
[0205][0206]
其中,和分别表示超宽带uwb的系数和惯导imu的系数,并将α
n
和β
n
作为指纹信息用于深度置信网络dbn训练。
[0207]
步骤3中,采用如下方法进行深度置信网络dbn训练:
[0208]
在训练阶段,根据目标物的真实位置u
n
和估计位置得到:
[0209][0210]
然后,构建dbn框架,dbn包含三个受限玻尔兹曼机(restricted boltzmann machines,rbms)和一个反馈神经网络,其构建过程包含三个阶段:预训练、重构和反向传输。每一个rbm都是基于能量函数的无向图模型,其中包含一层可见神经元和一层隐藏神经元,并且,上一层rbm的输出值作为下一层rbm的输入。
[0211]
定义和分别为第k个受限玻尔兹曼机rbm的可见层神经元和隐藏层神经元,分别表示可见层神经元中第i个元素和隐藏层神经元中第i个元素,i=1,
…
,m
k
,j=1,
…
,n
k
,m
k
和n
k
分别表示可见层神经元和隐藏层神经元的数量,下标k∈{1,2,3},为减少训练数据的维度,设定n1>n2>n3。定义和表示第k个受限玻尔兹曼机rbm的可见层v
(k)
的偏差和隐藏层h
(k)
的偏差,分别表示对应的可见层神经元的偏差和隐藏层神经元的偏差,定义w
(k)
表示v
(k)
和h
(k)
之间的连接权值,即:
[0212][0213]
其中,表示连接可见层和隐藏层对应元素和的权值;
[0214]
预训练阶段:
[0215]
第k个受限玻尔兹曼机rbm的能量表示为:
[0216]
e(v
(k)
,h
(k)
)=
‑
(a
(k)
)
t
v
(k)
‑
(h
(k)
)
t
w
(k)
v
(k)
‑
(b
(k)
)
t
h
(k)
ꢀꢀꢀꢀ
(22)
[0217]
联合概率分布pr(v
(k)
,h
(k)
)为:
[0218][0219]
其中,中间参数因此,得到v
(k)
的概率分布pr(v
(k)
)
为:
[0220][0221]
最小化第k个受限玻尔兹曼机rbm的对数损失函数以获得最优的参数w
(k)
,a
(k)
和b
(k)
,等价表示为
[0222][0223]
针对上述优化问题的解,使用传统的梯度下降法中求偏导过程复杂,因此引入对比散度cd
‑
1算法求解该问题,即:
[0224][0225][0226][0227]
其中,表示可见层的重构向量。
[0228]
在(26)中,表示在给定v
(k)
时,被激活的概率,其表达式为:
[0229][0230]
其中,sigmoid(
·
)表示受限玻尔兹曼机rbm的激活函数,表示w
(k)
中第i列元素;利用吉布斯采样法,即给定阈值表示均匀分布:
[0231][0232]
则可得到隐藏层h
(k)
。然后,得到条件概率分布函数
[0233][0234]
同理,利用吉布斯采样法得到重构向量进而得到:
[0235][0236]
其中,表示w
(k)
中第i行元素。最后,参数w
(k)
,a
(k)
和b
(k)
的更新方程表示为
[0237][0238][0239][0240]
其中,γ表示学习速率。
[0241]
重构阶段:
[0242]
基于在预训练阶段中更新的w
(k)
,b
(k)
和h
(k)
,得到条件概率分布函数为:
[0243][0244]
其中,k=3,2,1,表示重构的隐藏层,且因此,利用吉布斯采样,得到重构向量反向传输阶段:
[0245]
在反向传输阶段,基于重构数据和原始输入数据的均方误差,利用反馈神经网络更新权重和偏差。定义参数则第k层的均方误差j
(k)
(θ)为:
[0246][0247]
其中,ξ
(k
‑
1)
表示第k
‑
1层元素的数量,k=3,2,1,
[0248]
然后,利用梯度下降法更新参数θ,即:
[0249][0250][0251]
其中,υ表示学习速率。
[0252]
整个dbn训练过程如下所示:
[0253]
步骤一:计算n个测量点的归一化接收信号幅度
[0254]
步骤二:估计每个测量点的和
[0255]
步骤三:利用(20)计算α
n
和β
n
;
[0256]
步骤四:预训练阶段,利用(31)更新第k个rbm的参数w
(k)
,a
(k)
和b
(k)
;
[0257]
步骤五:重构阶段,利用(32)计算重构向量
[0258]
步骤六:反向传输阶段,利用(34)更新w
(k)
和b
(k)
;
[0259]
步骤七:输出数据
[0260]
基于构建的深度置信网络dbn,利用径向基函数r
n
估计移动目标物的坐标,即:
[0261][0262]
其中,表示目标物在第n个点的受限玻尔兹曼机rbm第三层输出数据,表示的方差,λ表示方差系数。因此,估计的参数和表示为:
[0263][0264][0265]
最终,将上述估计参数代入(19)中估计移动目标物的位置
[0266]
图1是本技术实施例部分提供的一种uwb和imu联合定位系统模型示意图,其内容包含两个部分:多基站的uwb定位和imu定位。
[0267]
如图2所示,随机森林分类器的输入为即为归一化接收信号的特征参数。分类器由多个决策树组成,分别训练每个决策树,最后通过投票的方式输出结果,从而组成随机森林模型。
[0268]
如图3所示,dbn模型由前传(图3a)和反馈(图3b)两个阶段,每个阶段由三个rbm组成,通过训练获得最优的参数w
(k)
,a
(k)
和b
(k)
,k∈{1,2,3}。
[0269]
图4是本技术实施例部分提供的联合定位系统实测场景图,该测试系统由多个基站、uwb设备和imu设备组成。将实测场景网格化,在每一个网格点进行测量,测试所提定位系统的定位效果。
[0270]
如图5所示,利用十阶交叉验证的方法,探究随机森林分类效果随决策树的深度d
t
和数目n
dt
变化情况。由结果可知,当n
dt
≥7,d
t
=6时,准确度可以收敛到稳定点0.98。
[0271]
如图6所示,在los环境下,90%的测距误差在0.25m内,经过随机森林回归器修正的误差累积分布图和未修正的累积分布图接近,因此得到结论,在los环境下不需要对测距误差进行修正。在nlos环境下,原始测距误差在1.5m内,经过修正之后,误差控制在0.5m内,结果表明,随机森林回归器有效地减小了测距误差。
[0272]
如图7所示,在nlos环境下,相较于测距误差未修正的情况,测距误差修正后的定位误差大大降低。
[0273]
如图8所示,huid联合定位系统在利用径向基函数定位时,受到参数λ的影响,如公式(35)所示。图中给出了定位误差随着λ的变化情况,结果表明,当λ=29.2时,定位误差达到最小。
[0274]
图9刻画了在los和nlos环境中,huid定位系统、uwb定位系统和imu定位系统的位置追踪路线。通过与真实路径对比,可以观察到在los区域的线性区域,三种定位系统的跟踪路径与真实路径没有明显偏差。然而,在nlos区域,基于uwb定位系统的估计路径明显偏
离真实路径,原因是在nlos效用的影响下,尽管uwb测距误差已被随机森林回归器部分修正,但是依然存在定位误差。对于imu定位系统,在拐角区域的误差显著增加,原因在于imu的测量结果对方向的变化敏感,由于累计误差的增加,跟踪路径逐渐偏离真实路径。对于huid定位系统,其跟踪路径更接近于真实路径,而且在nlos区域更明显。其结果验证了所提huid定位系统的性能明显优于uwb和imu定位系统。
[0275]
图10和图11分别刻画了huid的定位性能,图10给出了定位误差的均值和方差的分布情况,图11给出了定位误差的误差累积分布图,并与传统的扩展卡尔曼滤波ekf算法对比,两个图的结果都验证了所提huid联合定位系统的有效性和可靠性。本发明提供了一种高精度的室内定位追踪方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1