一种基于逐次概率判别算法的工业控制网络蜜罐识别方法与流程
1.本发明属于网络安全技术领域,涉及一种基于逐次概率判别算法的工业控制蜜罐识别方法。
背景技术:
2.随着中国工业制造2025和国外工业4.0的提出,plc等工业设备联网势在必行,世界范围内的工业网络的安全问题日益明显。作为应对工业网络安全的常见手段之一的工业控制网络蜜罐越来越多地出现在各种工业控制网络和工业互联网上用来诱骗攻击者,以此捕获攻击者,分析攻击者行为。
3.工控蜜罐常被部署在工业控制网络中,诱骗攻击者进行非法访问,进而全面捕获、监测和追踪攻击者的行为,使防御方从单纯的被动防御转变为更有效的主动防御。现有的工控蜜罐常常使用开源的工控蜜罐进行部署,例如:conpot,gaspot以及scada honeynet等。上述开源蜜罐实现了常用的工控协议,如:modbus,atg以及s7等工控协议,可以模拟某一类型的控制设备的网络通信行为,对攻击者的请求做出有效恢复。工控蜜罐的部署可以独立于工业生产,过程流程等场景,在不影响正常生产的情况下保护工控网络。
4.对工控蜜罐的有效识别,对于攻击者和安全人员有着巨大的作用。攻击者可以通过蜜罐识别避免陷入网络蜜罐陷阱,对目标网络进行有效的测绘和渗透;对于安全人员可以根据工控蜜罐的识别改进工控蜜罐的交互性,提高对攻击者的欺骗能力。
技术实现要素:
5.本发明提出一种基于逐次概率判别算法的工业控制网络蜜罐识别方法,可以识别不同场景和网络环境中的常见开源以及自研工控蜜罐。
6.本发明的技术方案如下:
7.一种基于逐次概率判别算法的工业控制网络蜜罐识别方法,包含如下步骤:收集蜜罐与真实设备数据、提取工业控制网络蜜罐特征、训练逐次概率识别模型以及应用该逐次概率识别模型进行工业控制网络蜜罐的识别。
8.一、收集蜜罐与真实设备数据、提取工业控制网络蜜罐特征
9.(一)独有特征
10.conpot与s7协议分析
11.conpot对s7协议的实现源码,提取特征如下:
12.1.s7协议实现默认配置信息列表,列表主要含有系统名称(systemname)、s7设备型号(s7_id)、s7设备模块名称(s7_module_type)、s7设备名称(facilityname)、模块名称(module_name)和版权(copyright)五项特征。其中基本默认配置:facilityname初始值设置为“mouser factory”、systemname初始值设置为“technodrome”、s7_id初始值设置为“88111222”、copyright初始值设置为“original siemens equipment”、s7_module_type初始值设置为“im151
‑
8pn/dp cpu”、将module name的初始值为“siemens,simatic,s7
‑
200”;
13.2.s7协议连接时长,conpot的设计者为了避免攻击者长时间保持与conpot蜜罐连接,占用带宽,在源代码中设置了与conpot的s7蜜罐设备连接最长时间为5秒。
14.3.s7协议回复时长,经过大量实验,发现真实设备的请求回复时长是conpot蜜罐回复时长的7倍左右,可以理解为真实设备的计算能力普遍弱于部署蜜罐的计算机设备。但该特征受网络环境(路由器跳数)的影响较大。
15.gaspot与atg协议
16.分析gaspot对atg协议的实现源码,提取特征如下:
17.1.atg协议实现默认配置信息列表,列表主要含有产品名称1(product1)、产品名称2(product2)、产品名称3(product3)、产品名称4(product4)以及地理位置(station)。其中product1初始值设置为super,product2初始值设置为unlead,product3的初始值设置为diesel,product4的初始值设置为premium。地理位置信息为众多真实油气设备地理位置列表。
18.2.atg协议请求回复默认配置,atg协议主要应用于油气设备控制。通过大量试验发现,真实设备的容量(volumetc)字段在一段时间内(一般为12小时)的变化量的绝对值基本等于缺量(ullage)字段的变化量的绝对值。而gaspot对上述两个字段的数值采用随机化的方式进行生成。
19.conpot与modbus协议
20.1.modbus协议读写寄存器功能实现,conpot未实现对寄存器的读写功能。通过大量实现发现,conpot在针对功能码0x10和0x03的回复都有错误:illegal data address(非法数据地址);
21.2.modbus协议回复错误功能码功能实现,当连续对conpot蜜罐设备发送错误功能码时,conpot蜜罐只接受数据而不会回复。而真实设备会正确回复错诶功能码。
22.(二)共有特征
23.由于蜜罐设备都是对真实工控设备的虚拟,必然会存在共同的虚拟缺陷,发现该类缺陷对识别蜜罐将会起到极大作用。
24.1.端口特征,通过大量实验,发现真实设备通常只会开放个位数的端口,而蜜罐设备会开放数十个端口。
25.2.系统特征,通过大量实验发现蜜罐往往存在于云端主机或虚拟机上,其操作系统通常是linux操作系统。
26.3.部署特征,通过大量实验发现如果目标设备的whois信息是云服务商或是网络供应商,则有很大可能该设备是蜜罐设备。
27.二、应用该逐次概率识别模型进行工业控制网络蜜罐的识别
28.(一)生成训练模型数据集
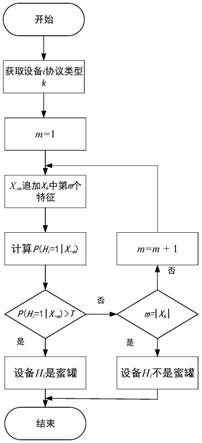
29.考虑到协议特征方面的不同,本发明将数据集依据协议划分为3个子数据集,分别是全球ipv4的modbus协议数据集,s7协议数据以及atg数据集。其中蜜罐标签根据如下3条依据确定:1.该设备网络供应商为云服务供应商;2.该设备由企业网络供应商托管且具有windows操作系统;3.该设备的网络供应商为大学。
30.其中modbus协议数据集的特征选择:modbus读写寄存器功能状态,modbus错误功能码回复时间,端口数量,路由器跳数。具体描述如表1所示。各个特征按照编号的先后顺序
标记为{x1,x2,x3,x4},对这些特征进行处理,对于x1读写寄存器功能,只有两种结果能或者是不能,所以x1∈{0,1}。由于modbus错误功能码回复时间跨度较大,对x2进行归一化处理。对x3取原本的数值进行编码,由于数据集中路由器跳数最小值为19,最大值为30,所以对x4进行等宽化处理,从15开始,以5为间隔,按照原本数值对应分别编码为0到2。
31.其中s7协议数据集特征选择:设备名称字段,设备标识符字段,设备模块序列号字段,5s后断开连接状态,报文回复时间,端口数量以及路由器跳数。具体描述如表2所示。各个特征按照编号的先后顺序标记为{x1,x2,x3,x4,x5,x6,x7},对这些特征进行处理,对x1,x2,x3按照字典编码,取每个特征数量最多的值放入字典中,将其他较少的数值统一标号,即x
i
∈{0,1,2,...,n},i∈{1,2,3}。特征取值最多的4个数值为空值、technodrome、saap7
‑
server和simatic 300(1),分别在数据集中以0到3对相应的数值编码,其他少量存在的数值以4编码。特征取值最多的3个数值为空值、mouser factory和doe water service,分别在数据集中以0到2对相应的数值编码,其他少量存在的数值以3编码。特征取值最多的3个数值为空值、88111222和s c
‑
c2ur28922012,分别在数据集中以0到2对相应的数值编码,其他少量存在的数值以3编码。对特征按照经过5s后主动断开连接编码为1,积极主动继续建立连接编码为0。对特征报文回复时间进行等宽化处理,对标签为蜜罐的特征的取值进行平均取值发现平均值为0.3左右,对标签为非蜜罐的特征的取值进行平均取值发现平均值为0.6左右,所以取0.2为单位,从0开始取7个分段,等宽化处理特征的数据。对特征开放端口数量不处理,按照原本的数值进行编码。路由器跳数使用等宽化进行编码,由于数据集中最小的跳数为14,最大的跳数为30,选择从10开始,5为间隔,共取4段,按照原本数值对应分别编码为0到3。
32.其中atg协议数据集特征选择:atg协议的产品名称1,atg协议的产品名称2,atg协议的产品名称3,atg协议的产品名称4,atg协议应用层时序特征,端口数量,路由器跳数。具体描述如表3所示。各个特征按照编号的先后顺序标记为{x1,x2,x3,x4,x5,x6,x7},对这些特征进行处理,对x1,x2,x3,x4按照01编码,将特征x1中特征值为super的编码为1,其他编码为0,特征x2中特征值为unlead的编码为1,其他编码为0,特征x3中特征值为diesel的编码为1,其他编码为0,特征x4中特征值为premium的编码为1,其他编码为0。对特征x5按照符合atg协议应用层时序特征标记为1,不符合标记为0。对特征x6开放端口数量不处理,按照原本的数值进行编码。路由器跳数x7使用等宽化进行编码,由于数据集中最小的跳数为16,最大的跳数为30,选择从15开始,5为间隔,共取3段,按照原本数值对应分别编码为0到2。
33.将每个协议的数据集划分成两个互斥的集合,训练集和测试集,按照7:3的比例划分。将蜜罐样本在训练集和测试集的数量控制在7:3,将非蜜罐样本在训练集和测试集的数量也控制在7:3。s7comm协议数据集中共有928条数据,modbus协议数据集中共有100条数据,atg协议数据集中共有391条数据。
34.(二)逐次概率判别算法
35.对于设备i,设其是蜜罐的概率是h
i
,首先使用第一个特征x1计算在特征x1的条件下,h
i
=1的条件概率p(h
i
=1|x1),如果该条件概率大于设定的阈值t,则认为该设备是蜜罐;如果该条件概率小于设定的阈值t,则继续计算添加了第二个特征x2下的条件概率p(h
i
=1|x1,x2),再次判断该条件概率是否大于设定的阈值t,依次类推依次特征x3,x4,...,x
n
。最终如果使用了所有的特征后条件概率均小于设定的阈值t,则认为该设备是真实设备。
36.设x
k
表示协议k所有特征集合,x
k
={x1,x2,...,x
n
},x
‑
i
表示第i次计算条件概率所使用特征集合,x
‑
i
={x1,x2,...,x
i
}。
37.对于运行协议k的设备,逐次概率判别算法可以描述如下:
38.1.第一次依据协议k的特征x1计算h
i
=1的条件概率,
[0039][0040][0041][0042]
其中表示h
i
=1且x
i
=j(x
i
取对应特征的第j个值,下文中含义相同)的在数据集中的样本数量,n表示数据及总体样本数量。如果p(h
i
=1|x1=j)大于设定的阈值t,则认为该设备h
i
是蜜罐设备。其中x
‑
i
=x
‑1={x1}。如果小于阈值t则添加第二特征继续计算h
i
=1的条件概率p(h
i
=1|x1=j,x2=k)。
[0043]
2.依据特征x1和x2计算h
i
=1的条件概率,
[0044][0045][0046][0047]
其中表示h
i
=1且x
i
=j,x2=k的在数据集中的样本数量,n表示数据及总体样本数量。其中x
‑
i
=x
‑2={x1,x2}。如果p(h
i
=1|x1=j,x2=k)大于设定的阈值t,则认为该设备h
i
是蜜罐设备。
[0048]
3.依次类推,第m次计算h
i
=1的条件概率,
[0049][0050][0051][0052]
其中表示h
i
=1且x1=j,...,x
m
=z的在数据集中的样本数量,n表示数据及总体样本数量。其中x
‑
i
=x
‑
m
={x1,...,x
m
}。
[0053]
如果小于阈值t则逐次添加其余特征继续计算h
i
=1的条件概率p(h
i
=1|x1=j,x2=k,...)。直到该条件概率大于设定阈值t或用完所有特征,x
‑
n
=x。如果使用完所有特征得到的条件概率仍然小于阈值t,则认为给设备是真实设备。
[0054]
本发明可以有效减少与目标设备的交互次数,减小目标设备的交互压力,提高识
别准确率与识别效率。本发明通过大量实验,验证了该方法在交互次数,识别效率与识别准确率上有较好的效果。
附图说明
[0055]
图1是本发明中工业控制网络蜜罐识别流程示意图。
[0056]
图2是本发明中逐次概率判别算法的流程图。
具体实施方式
[0057]
以下结合附图和具体实施方案对本发明作进一步的详细说明。
[0058]
下面是本发明中逐次概率判别算法伪代码。
[0059]
输入:特征集合x,数据集d,未知设备i
[0060]
输出:未知设备i的蜜罐标签
[0061]
过程:
[0062][0063]
表1 modbus协议数据集的特征
[0064]
编号名称描述1readwriteholdingregistersmodbus读写寄存器功能2errorresponsetimemodbus错误功能码回复时间3portsnum端口数量4routerhops路由器跳数
[0065]
表2 s7协议数据集的特征
[0066]
编号名称描述1nameoftheplcs7comm协议nameoftheplc字段2plantidentifications7comm协议plantidentification字段3serialnumberofmodules7comm协议serialnumberofmodule字段4time5laters7comm协议5s后是否选择断开连接5responsetimes7comm协议报文回复时间6portsnum端口数量7routerhops路由器跳数
[0067]
表3 atg协议数据集的特征
[0068]
编号名称描述1atgproduct1atg协议的产品1名称2atgproduct2atg协议的产品2名称3atgproduct3atg协议的产品3名称4atgproduct4atg协议的产品4名称5atgtimeapplicationatg协议应用层时序特征6portsnum端口数量7routerhops路由器跳数
[0069]
表4实施案例一中各算法效果对比表
[0070][0071][0072]
实施例1:真实设备与工控蜜罐识别
[0073]
本发明使用上述中所描述的三种协议数据集对本发明所提逐次概率判别算法与常见的机器学习算法进行识别效果对比。表4展示了对三种协议使用逐次概率模型与支持向量机、朴素贝叶斯和决策树的识别效果。y代表通过逐次概率判别算法判断后与标签符合的数据数量,n代表通过逐次概率判别算法判断后与标签不符合的数据数量,包括判断为蜜罐但实际不是蜜罐和未判断出是蜜罐但是标签为蜜罐的数量和。u代表通过逐次概率判别算法判断后没有判断为蜜罐,即不确定是否为蜜罐的数量。可以看到,逐次概率判别算法在使用较少特征的条件下,仍然可以取得较好的识别效果,优于支持向量机模型和朴素贝叶斯,与决策树算法相当。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1