虚拟会议室的音频处理方法、装置及存储介质与流程
本申请涉及虚拟会议室,具体涉及一种虚拟会议室的音频处理方法、装置及存储介质。
背景技术:
1、虚拟会议室(virtual meeting room,vmr)是一种高效、便捷的网络会议室。用户通过手机、电脑等移动终端产品可快速高效地与其他用户组建虚拟会议,不受时间和空间的局限,感受身临其境的会议沟通效果。目前的虚拟会议室是把发言者的图像放大,而难以区分不同发言者的声音。当虚拟会议室中有多个发言者同时讲话时,用户难以分辨每个发言者的讲话内容。
技术实现思路
1、鉴于此,本申请提供一种虚拟会议室的音频处理方法、装置及存储介质,以提升发言者的声音的可识别性。
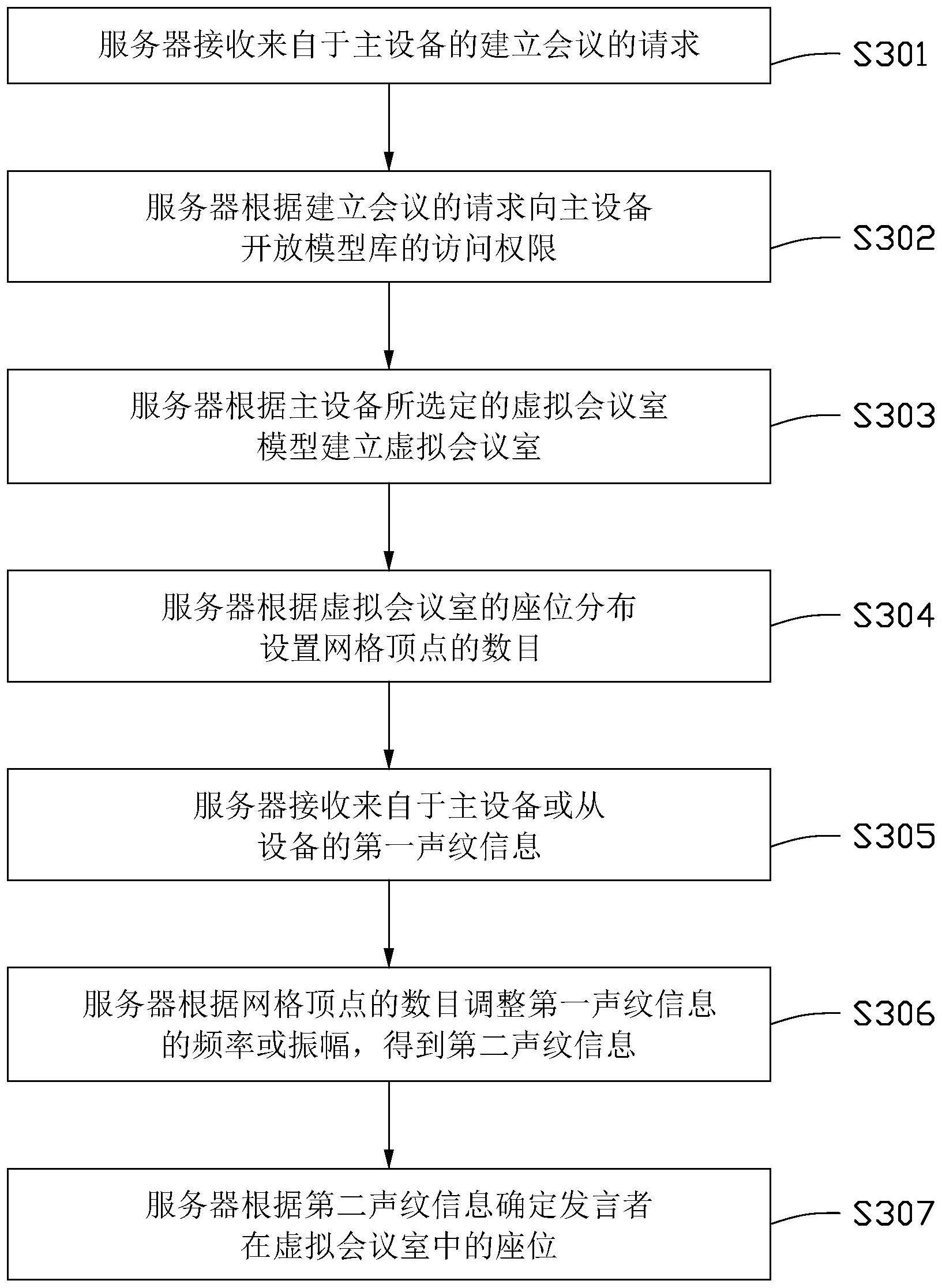
2、本申请第一方面提供一种虚拟会议室的音频处理方法,包括:根据虚拟会议室的座位分布设置网格顶点的数目。获取发言者的第一声纹信息,第一声纹信息包括语音信号的频率、振幅及相位差。根据网格顶点的数目调整第一声纹信息的频率或振幅,得到第二声纹信息。根据第二声纹信息确定发言者在虚拟会议室中的座位。
3、在其中一种实施方式中,根据虚拟会议室的座位分布设置网格顶点的数目,包括:在各个座位所覆盖区域设置不同数目的网格顶点,以建立座位与网格顶点的数目的对应关系。
4、在另一种实施方式中,根据网格顶点的数目调整第一声纹信息的频率或振幅,包括:当第一座位所覆盖区域的网格顶点的数目大于第二座位所覆盖区域的网格顶点的数目时,调高来自于第一座位的第一声纹信息的频率,或调低来自于第二座位的第一声纹信息的频率,使得来自于第一座位的第一声纹信息的频率大于来自于第二座位的第一声纹信息的频率。
5、在另一种实施方式中,根据网格顶点的数目调整第一声纹信息的频率或振幅,包括:当第一座位所覆盖区域的网格顶点的数目大于第二座位所覆盖区域的网格顶点的数目时,调大来自于第一座位的第一声纹信息的振幅,或调小来自于第二座位的第一声纹信息的振幅,使得来自于第一座位的第一声纹信息的振幅大于来自于第二座位的第一声纹信息的振幅。
6、在另一种实施方式中,在根据第二声纹信息确定发言者在虚拟会议室中的座位之后,音频处理方法还包括:获取参会者的眼球运动方向信息。根据眼球运动方向信息确定参会者的专心度,专心度的取值为0或1。根据专心度确定参会者对会议议题是否有兴趣。
7、在另一种实施方式中,根据眼球运动方向信息确定参会者的专心度,包括:当参会者的眼球运动方向朝向发言者时,将专心度标记为1。当参会者的眼球运动方向远离发言者时,将专心度标记为0。
8、在另一种实施方式中,音频处理方法还包括:当存在多个发言者时,统计参会者在每个发言者发言时的专心度的取值。根据专心度的取值确定参会者对会议议题的专心度。
9、在另一种实施方式中,根据专心度确定参会者对会议议题是否有兴趣,包括:当专心度的取值大于或等于预设的兴趣阈值时,确定参会者对会议议题有兴趣。当专心度的取值小于兴趣阈值时,确定参会者对会议议题没有兴趣。
10、本申请第二方面提供一种音频处理装置,包括服务器、主设备及从设备,主设备用以发起虚拟会议,服务器用以根据来自于主设备的指令构建虚拟会议室,从设备用以根据来自于主设备的链接进入虚拟会议室,服务器包括第一处理器和第一存储器,第一处理器运行存储于第一存储器中的计算机程序或代码,实现本申请实施例的音频处理方法。
11、本申请第三方面提供一种存储介质,用于存储计算机程序或代码,当计算机程序或代码被处理器执行时,实现本申请实施例的音频处理方法。
12、本申请实施例将虚拟会议室中的每个座位所覆盖区域的网格顶点的数目与第一声纹信息建立对应关系,根据网格顶点的数目调整来自于不同座位的第一声纹信息的频率或振幅,得到更具辨识性的第二声纹信息,从而建立起每个座位与第二声纹信息的对应关系。如此,可根据第二声纹信息确定发言者在虚拟会议室中的座位。本申请实施例可模拟发言者的声源特性,使发言者的声音具有可识别性,用户可以清楚地分辨出每个发言者的讲话内容。
技术特征:
1.一种虚拟会议室的音频处理方法,其特征在于,所述方法包括:
2.如权利要求1所述的音频处理方法,其特征在于,所述根据所述虚拟会议室的座位分布设置网格顶点的数目,包括:
3.如权利要求1所述的音频处理方法,其特征在于,所述根据所述网格顶点的数目调整所述第一声纹信息的频率或振幅,包括:
4.如权利要求1所述的音频处理方法,其特征在于,所述根据所述网格顶点的数目调整所述第一声纹信息的频率或振幅,包括:
5.如权利要求1所述的音频处理方法,其特征在于,在所述根据所述第二声纹信息确定所述发言者在所述虚拟会议室中的座位之后,所述方法还包括:
6.如权利要求5所述的音频处理方法,其特征在于,所述根据所述眼球运动方向信息确定所述参会者的专心度,包括:
7.如权利要求6所述的音频处理方法,其特征在于,所述方法还包括:
8.如权利要求5所述的音频处理方法,其特征在于,所述根据所述专心度确定所述参会者对会议议题是否有兴趣,包括:
9.一种音频处理装置,包括服务器、主设备及从设备,所述主设备用以发起虚拟会议,所述服务器用以根据来自于所述主设备的指令构建虚拟会议室,所述从设备用以根据来自于所述主设备的链接进入所述虚拟会议室,所述服务器包括第一处理器和第一存储器,其特征在于,所述第一处理器运行存储于所述第一存储器中的计算机程序或代码,实现如权利要求1至8中任一项所述的音频处理方法。
10.一种存储介质,用于存储计算机程序或代码,其特征在于,当所述计算机程序或代码被处理器执行时,实现如权利要求1至8中任一项所述的音频处理方法。
技术总结
本申请公开了一种虚拟会议室的音频处理方法、装置及存储介质,涉及虚拟会议室技术领域。本申请一实施例的音频处理方法包括:根据虚拟会议室的座位分布设置网格顶点的数目。获取发言者的第一声纹信息,第一声纹信息包括语音信号的频率、振幅及相位差。根据网格顶点的数目调整第一声纹信息的频率或振幅,得到第二声纹信息。根据第二声纹信息确定发言者在虚拟会议室中的座位。本申请实施例能够模拟发言者的声源特性,使发言者的声音具有可识别性。
技术研发人员:王呈裕,陈柏诚,李育德
受保护的技术使用者:富联精密电子(天津)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!