一种基于移动边缘计算的用户调度方法
1.本发明涉及一种基于移动边缘计算的用户调度方法,属于无线通信技术领域。
背景技术:
2.随着5g时代的来临,新型应用和服务不断涌现,如实时在线游戏、虚拟现实等,这些应用和服务都具有计算密集、延时敏感等特点,终端设备本地计算和传统集中式云计算难以满足这一要求;移动边缘计算(mobile edge computer,mec)技术应运而生,通过在网络边缘提供云服务,允许在终端用户附近执行应用,大大降低了服务器到终端的延迟,减轻了网络负载,显著提高了数据处理效率,为新型技术应用提供了更好的平台;但mec服务器的资源有限,大量用户设备任务卸载可能会使有些用户分配的计算资源过少,无法在时延限制内完成任务。
技术实现要素:
3.本发明的目的在于提供一种基于移动边缘计算的用户调度方法,解决现有技术中用户调度代价大、资源有限的问题,完成用户调度,最大化可支持用户数量。
4.为实现以上目的,本发明是采用下述技术方案实现的:
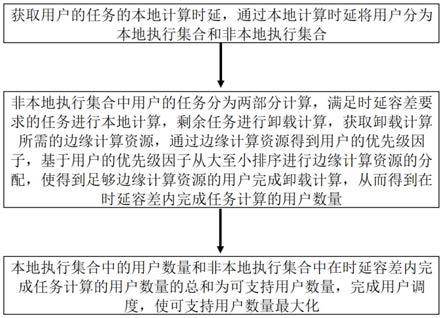
5.本发明提供了一种基于移动边缘计算的用户调度方法,包括:
6.获取用户的任务的本地计算时延,通过本地计算时延将用户分为本地执行集合和非本地执行集合;
7.非本地执行集合中用户的任务分为两部分计算,满足时延容差要求的任务进行本地计算,剩余任务进行卸载计算,获取卸载计算所需的边缘计算资源,通过边缘计算资源得到用户的优先级因子,基于用户的优先级因子从大至小排序进行边缘计算资源的分配,使得到足够边缘计算资源的用户完成卸载计算,从而得到在时延容差内完成任务计算的用户数量;
8.本地执行集合中的用户数量和非本地执行集合中在时延容差内完成任务计算的用户数量的总和为可支持用户数量,完成用户调度,使可支持用户数量最大化。
9.进一步的,获取任务的本地计算时延:
[0010][0011]
其中,vn表示用户n的计算任务数据的大小,cn表示用户n计算1bit数据所需的cpu周期数,qn表示用户n的本地计算资源。
[0012]
进一步的,通过本地计算时延将用户分为本地执行集合和非本地执行集合:
[0013]
若用户的本地计算时延小于等于tn,则该用户属于本地执行集合;
[0014]
若用户的本地计算时延大于tn,则该用户属于非本地执行集合;
[0015]
其中,tn为用户n完成任务计算的最大时延容差。
[0016]
进一步的,获取卸载计算所需的边缘计算资源:
[0017]
非本地执行集合中用户的任务进行卸载计算时,用户向基站发送任务卸载请求,建立蜂窝链路,将任务卸载至能够提供所需服务中具有最佳信道条件的基站,获取用户与基站之间的信道传输速率;
[0018]
通过计算得到非本地执行集合中用户卸载计算的任务量,其中,vk是用户k的总任务量,ck是用户k计算1bit数据所需的cpu周期数,是非本地执行集合中用户k的本地计算资源,tk是用户k完成任务的最大时延容差;
[0019]
根据用户与基站之间的信道传输速率、非本地执行集合中用户卸载计算的任务量获取卸载计算所需的边缘计算资源:
[0020][0021]
其中,rk是用户与基站之间的信道传输速率。
[0022]
进一步的,获取用户与基站之间的信道传输速率:
[0023][0024]
其中,和分别为用户到sbs和mbs的信道传输速率,通过如下公式计算得到:
[0025][0026][0027]
其中,b表示子信道带宽大小,和分别是用户k在信道中向sbs和mbs传输数据的功率,为用户k和sbs之间的信道增益且服从莱斯分布,为用户k和mbs之间的信道增益且服从瑞利分布,no为背景噪声功率。
[0028]
进一步的,所述用户的优先级因子通过如下公式计算得到:
[0029][0030]
其中,为用户k的边缘计算资源,用户优先级和所述优先级因子的值呈正相关。
[0031]
与现有技术相比,本发明所达到的有益效果是:
[0032]
本发明提供的一种基于移动边缘计算的用户调度方法,通过本地计算时延将用户分为本地执行集合和非本地执行集合,非本地执行集合中用户的不满足时延容差要求的任务进行卸载计算,即用户的任务无法及时在本地计算完成时,可将一部分任务卸载至基站端的服务器辅助计算,在这些用户中卸载计算所需的边缘计算资源更少的用户优先级更高,在本方法中获取卸载计算所需的边缘计算资源,通过边缘计算资源得到用户的优先级因子,基于用户的优先级因子大小排序进行边缘计算资源的分配,优先处理卸载计算所需的边缘计算资源更少的用户,使得系统在有限的计算和信道资源情况下能够支持更多的用
户,解决现有技术中用户调度代价大、资源有限的问题,完成用户调度,最大化可支持用户数量。
附图说明
[0033]
图1是本发明实施例提供的一种基于移动边缘计算的用户调度方法的流程图;
[0034]
图2是本发明实施例提供的多用户多服务器通信系统的示意图;
[0035]
图3是本发明实施例提供的可支持用户数量与用户数量的关系仿真图。
具体实施方式
[0036]
下面结合附图对本发明作进一步描述,以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
[0037]
实施例一
[0038]
如图2所示,建立一个多用户多服务器通信系统,包括宏基站(mbs,macro base station)、小基站(sbs,small base station)以及n个用户,每个基站处都有mec服务器,每个用户都能够与一个基站建立一条蜂窝链路,每个用户都有一个任务需要计算,所述任务能够通过本地计算和卸载计算两种方式完成。
[0039]
如图1所示,本发明实施例提供的一种基于移动边缘计算的用户调度方法,包括:
[0040]
获取用户的任务的本地计算时延,通过本地计算时延将用户分为本地执行集合和非本地执行集合。
[0041]
基于如图2所示的多用户多服务器通信系统,计算所有用户的任务的本地计算时延,获取任务的本地计算时延:
[0042][0043]
其中,vn表示用户n的计算任务数据的大小,cn表示用户n计算1bit数据所需的cpu周期数,qn表示用户n的本地计算资源。
[0044]
通过本地计算时延将用户分为本地执行集合l和非本地执行集合k:
[0045]
若用户的本地计算时延小于等于tn,即满足则该用户属于本地执行集合l;
[0046]
若用户的本地计算时延大于tn,即不满足则该用户属于非本地执行集合k;
[0047]
其中,tn为用户n完成任务计算的最大时延容差。
[0048]
考虑到本地执行集合l中用户的任务均为本地计算,全部为系统的可支持用户;因此,提高可支持用户数量需要特别关注非本地执行集合k中的用户。
[0049]
非本地执行集合中用户的任务分为两部分计算,满足时延容差要求的任务进行本地计算,剩余任务进行卸载计算,获取卸载计算所需的边缘计算资源,通过边缘计算资源得到用户的优先级因子,基于用户的优先级因子从大至小排序进行边缘计算资源的分配,使得到足够边缘计算资源的用户完成卸载计算,从而得到在时延容差内完成任务计算的用户数量。
[0050]
由于非本地执行集合k中的用户的任务在本地计算不满足时延容差要求,考虑将其任务分为两部分计算,即本地计算和卸载计算协同完成,为了最大可能利用有限的计算资源,任务应在时延容差内尽可能多的在本地计算,剩余部分任务卸载至基站处的mec服务器进行远程计算。
[0051]
非本地执行集合k的用户向基站发送任务卸载请求,建立蜂窝链路;考虑信道上信道衰落的影响,用户将任务卸载到能够提供所需服务中具有最佳信道条件的基站,获取用户与基站之间的信道传输速率:
[0052][0053]
其中,rk是用户与基站之间的信道传输速率,和分别为用户到sbs和mbs的信道传输速率,通过如下公式计算得到:
[0054][0055][0056]
其中,b表示子信道带宽大小,和分别是用户k在信道中向sbs和mbs传输数据的功率,为用户k和sbs之间的信道增益且服从莱斯分布,为用户k和mbs之间的信道增益且服从瑞利分布,no为背景噪声功率。
[0057]
为了有效地复用频谱,sbs和mbs工作在同一频段,每个信道的带宽相同。
[0058]
通过计算得到非本地执行集合中用户卸载计算的任务量,其中,vk是用户k的总任务量,ck是用户k计算1bit数据所需的cpu周期数,是非本地执行集合中用户k的本地计算资源,tk是用户k完成任务的最大时延容差;
[0059]
根据用户与基站之间的信道传输速率、非本地执行集合中用户卸载计算的任务量获取卸载计算所需的边缘计算资源:
[0060][0061]
通过边缘计算资源得到用户的优先级因子:
[0062][0063]
其中,为用户k的边缘计算资源,pk的值越大,用户优先级越高,用户的优先级因子的定义考虑了用户卸载任务所需边缘计算资源的大小。
[0064]
对用户的优先级因子按照从大到小的顺序排序,然后分配有限的边缘计算资源,得到足够边缘计算资源的用户能够在时延容差内完成任务的卸载计算,从而完成任务的计算,从而得到在时延容差内完成任务计算的用户数量。
[0065]
本地执行集合中的用户数量和非本地执行集合中在时延容差内完成任务计算的
用户数量的总和为可支持用户数量,完成用户调度,使可支持用户数量最大化。
[0066]
获取上述本地执行集合l中用户数量、非本地执行集合k中在时延容差内完成任务计算的用户数量,两者的总和为系统的可支持用户数量,至此完成用户调度,使用上述的一种基于移动边缘计算的用户调度方法能够使可支持用户数量最大化。
[0067]
实施例二
[0068]
如图2所示,建立一个多用户多服务器通信系统,包括宏基站(mbs,macro base station)、小基站(sbs,small base station)以及n个用户,每个基站处都有mec服务器,每个用户都能够与一个基站建立一条蜂窝链路,每个用户都有一个任务需要计算,所述任务能够通过本地计算和卸载计算两种方式完成。
[0069]
如图1所示,本发明实施例提供的一种基于移动边缘计算的用户调度方法,包括:
[0070]
获取用户的任务的本地计算时延,通过本地计算时延将用户分为本地执行集合和非本地执行集合。
[0071]
基于如图2所示的多用户多服务器通信系统,计算所有用户的任务的本地计算时延,获取任务的本地计算时延:
[0072][0073]
其中,vn表示用户n的计算任务数据的大小,cn表示用户n计算1bit数据所需的cpu周期数,qn表示用户n的本地计算资源。
[0074]
通过本地计算时延将用户分为本地执行集合l和非本地执行集合k:
[0075]
若用户的本地计算时延小于等于tn,即满足则该用户属于本地执行集合l;
[0076]
若用户的本地计算时延大于tn,即不满足则该用户属于非本地执行集合k;
[0077]
其中,tn为用户n完成任务计算的最大时延容差。
[0078]
考虑到本地执行集合l中用户的任务均为本地计算,全部为系统的可支持用户;因此,提高可支持用户数量需要特别关注非本地执行集合k中的用户。
[0079]
非本地执行集合中用户的任务分为两部分计算,满足时延容差要求的任务进行本地计算,剩余任务进行卸载计算,获取卸载计算所需的边缘计算资源,通过边缘计算资源得到用户的优先级因子,基于用户的优先级因子从大至小排序进行边缘计算资源的分配,使得到足够边缘计算资源的用户完成卸载计算,从而得到在时延容差内完成任务计算的用户数量。
[0080]
由于非本地执行集合k中的用户的任务在本地计算不满足时延容差要求,考虑将其任务分为两部分计算,即本地计算和卸载计算协同完成,为了最大可能利用有限的计算资源,任务应在时延容差内尽可能多的在本地计算,剩余部分任务卸载至基站处的mec服务器进行远程计算。
[0081]
非本地执行集合k的用户向基站发送任务卸载请求,建立蜂窝链路;考虑信道上信道衰落的影响,用户将任务卸载到能够提供所需服务中具有最佳信道条件的基站,获取用户与基站之间的信道传输速率:
[0082][0083]
其中,rk是用户与基站之间的信道传输速率,和分别为用户到sbs和mbs的信道传输速率,通过如下公式计算得到:
[0084][0085][0086]
其中,b表示子信道带宽大小,和分别是用户k在信道中向sbs和mbs传输数据的功率,为用户k和sbs之间的信道增益且服从莱斯分布,为用户k和mbs之间的信道增益且服从瑞利分布,no为背景噪声功率。
[0087]
为了有效地复用频谱,sbs和mbs工作在同一频段,每个信道的带宽相同。
[0088]
通过计算得到非本地执行集合中用户卸载计算的任务量,其中,vk是用户k的总任务量,ck是用户k计算1bit数据所需的cpu周期数,是非本地执行集合中用户k的本地计算资源,tk是用户k完成任务的最大时延容差;
[0089]
根据用户与基站之间的信道传输速率、非本地执行集合中用户卸载计算的任务量获取卸载计算所需的边缘计算资源:
[0090][0091]
通过边缘计算资源得到用户的优先级因子:
[0092][0093]
其中,为用户k的边缘计算资源,pk的值越大,用户优先级越高,用户的优先级因子的定义考虑了用户卸载任务所需边缘计算资源的大小。
[0094]
对用户的优先级因子按照从大到小的顺序排序,然后分配有限的边缘计算资源,得到足够边缘计算资源的用户能够在时延容差内完成任务的卸载计算,从而完成任务的计算,从而得到在时延容差内完成任务计算的用户数量。
[0095]
本地执行集合中的用户数量和非本地执行集合中在时延容差内完成任务计算的用户数量的总和为可支持用户数量,完成用户调度,使可支持用户数量最大化。
[0096]
获取上述本地执行集合l中用户数量、非本地执行集合k中在时延容差内完成任务计算的用户数量,两者的总和为系统的可支持用户数量,至此完成用户调度,使用上述的一种基于移动边缘计算的用户调度方法能够使可支持用户数量最大化。
[0097]
在本实施例中,信道带宽b取值为0.05mhz,对于计算任务,用户的任务大小vn在0.1mbits到4mbits之间服从均匀分布随机生成,用户的本地计算资源fn的取值在0.5
×
109到2
×
109cpu cycles/s之间服从均匀分布随机生成,计算任务每比特所需cpu周期数cn的取
值在500到1500cpu cycles/bit之间服从均匀分布随机生成,sbs和mbs处的mec服务器的计算资源均为5
×
109cpu cycles/s,所有任务的最大计算时延容差为1.5s,用户发射功率为24dbm,信道噪声功率为10-9
w。
[0098]
图3为本发明实施例提供的调度方法与传统轮循调度下,可支持用户数量与用户数量的关系仿真图,能够明显看出,本发明实施例提供的一种基于移动边缘计算的用户调度方法在系统的可支持用户数量上明显优于传统轮循调度方案。
[0099]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0100]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0101]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0102]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0103]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1