基于近场音频信号传递函数数据来生成个性化自由场音频信号传递函数的方法和系统与流程
背景技术:
1、每个人对声音信号的声学感知可能由于其生物学听觉器官的不同而不同:在收听者周围传输的声音信号到达收听者的鼓膜之前,它被收听者的身体或身体的一部分(例如,收听者的肩部、骨骼或耳廓)反射、部分地吸收和传输。这些影响导致声音信号的改变。换句话讲,收听者接收到的不是最初传输的声音信号,而是修改的声音信号。
2、人脑能够从这种修改导出声音信号最初传输的位置。因此,考虑了不同的因素,包括:(i)耳间振幅差,即,在一只耳朵中与另一只耳朵相比接收到的声音信号的振幅差;(ii)耳间时间差,即,在一只耳朵中与另一只耳朵相比接收到的声音信号的时间差;(iii)接收到的信号的频率或脉冲响应,其中响应是收听者(特别是收听者的耳朵)和位置(特别是从其接收声音信号的方向)的特性。考虑到上述因素,可通过通常称为头部相关传递函数(hrtf)的函数来描述传输的声音信号与在收听者的耳朵中接收到的声音信号之间的关系。
3、这种现象可用于通过声源来模拟看起来是从相对于收听者或收听者耳朵的特定方向接收的声音信号,所述声源位于相对于收听者或收听者耳朵的不同于所述特定方向的方向上。换句话讲,可确定描述当由收听者(即在收听者的耳朵内)接收时从特定方向传输的声音信号的修改的hrtf。所述传递函数可用于生成用于改变从与特定方向不同的方向传输的后续声音信号的特性使得接收到的后续声音信号被收听者感知为是从特定方向接收的滤波器。换句话讲:可合成位于特定位置处和/或特定方向上的另外声源。因此,在通过固定位置的扬声器(例如,耳机)传输声音信号之前将适当生成的滤波器应用于声音信号可使人脑将声音信号感知为具有特定的特别是可选择的空间位置。
4、为了确定相对于收听者的每个可能方向(更准确地说,相对于收听者的每个耳朵)的相应hrtf可能是非常耗费成本和时间的。因此,确定作为收听者或收听者耳朵以及声音信号来自的方向的特性的频率或脉冲响应特别具有挑战性。此外,当在实验室条件下(例如,在消声室中)执行时,在合理的时间和成本范围内可生成用于特定收听者的仅有限数量的传递函数。
5、本发明解决了以时间和成本有效的方式生成与用户耳朵相关联的个性化声音信号传递函数(例如,hrtf的频率或脉冲响应)的问题,声音信号传递函数中的每一个与相对于用户耳朵的相应声音信号方向相关联。
技术实现思路
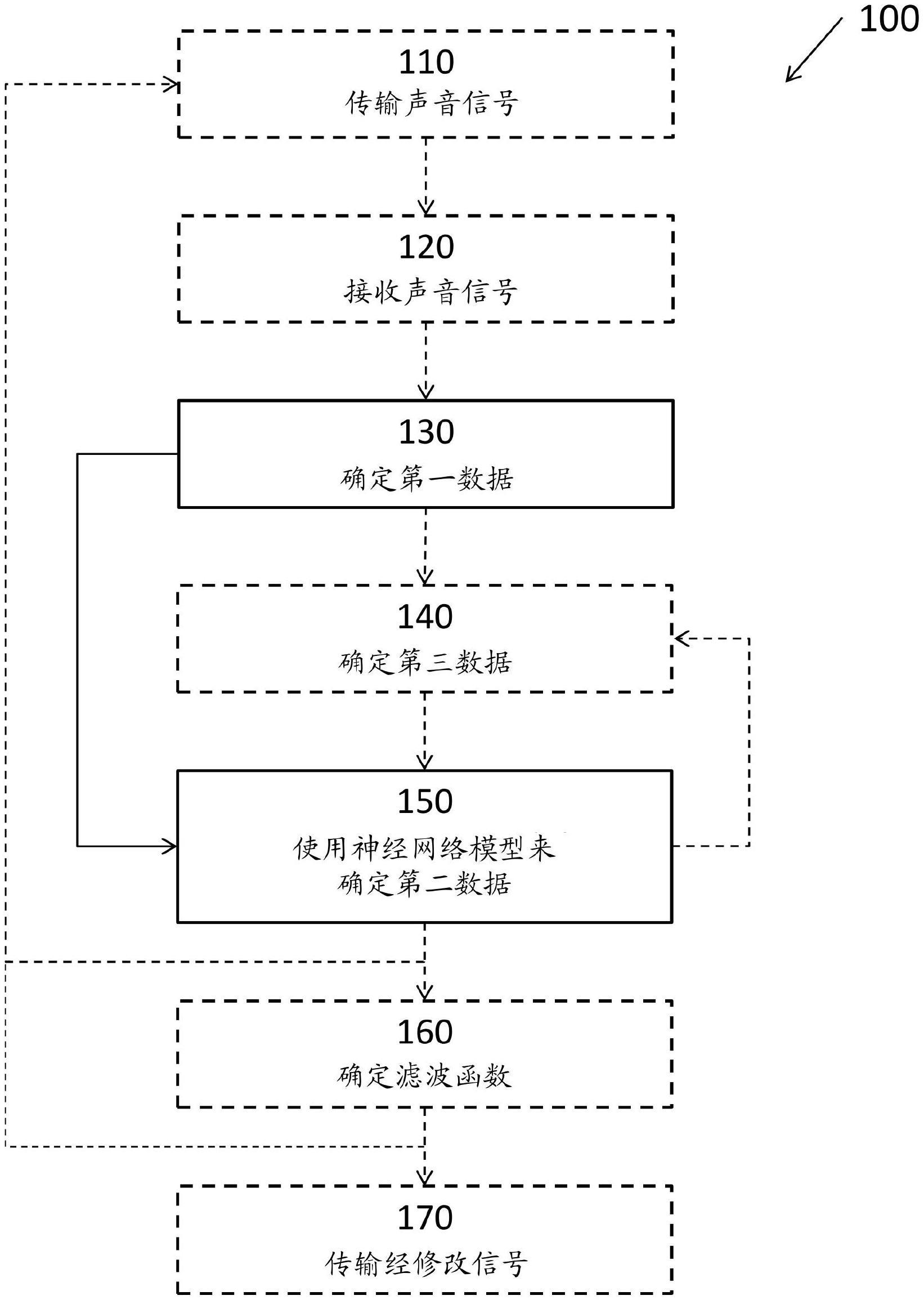
1、根据许多实施方案中的一个,提供了一种用于生成个性化声音信号传递函数的计算机实现的方法,所述方法包括:通过声音接收装置在用户的耳朵处或所述用户的所述耳朵中接收声音信号;基于所接收的声音信号来确定第一数据,其中第一数据表示与用户的耳朵相关联的第一声音信号传递函数;基于第一数据来确定第二数据,其中第二数据表示与用户的耳朵相关联的第二声音信号传递函数。
2、第一声音信号传递函数和第二声音信号传递函数可以是两者分别与用户的耳朵相关联的第一hrtf和第二hrtf的频率或脉冲响应。如此,仅需要例如在实验室环境中测量第一声音信号传递函数。可基于所测量的第一声音信号传递函数来确定第二声音信号传递函数或多个另外的第二声音信号传递函数。换句话讲,第一数据可以是第一输入数据,第二数据可以是生成数据或推断数据。
3、第二声音信号传递函数可适用于修改声音信号或后续声音信号。例如,使用第一hrtf或第二hrtf,声音信号或后续声音信号可被修改,即被定制,用于个性化空间音频处理。此外,可使用第一hrtf和/或第二hrtf的仅一部分(例如,特定方向(即角度或角度的组合)的频率响应)来创建定制均衡或呈现个性化音频响应以获得增强的声音质量。
4、替代地或另外,第一hrtf和/或第二hrtf可用作信息来消除来自hrtf(特别是第一hrtf)的设备响应的歧义,以增强信号处理(诸如anc(主动噪声消除)、直通或低音-管理)以便使所述信号处理更有针对性和/或更有效。
5、根据一个实施方案,第一声音信号传递函数表示近场声音信号传递函数,和/或其中所述方法还包括在相对于用户的耳朵的近场内从声音传输装置、特别是从由用户佩戴的耳机接收声音信号。
6、声音接收装置可以是麦克风。麦克风可被配置为(特别是足够小以)位于用户的耳朵的耳道中。换句话讲,麦克风可在声学上阻塞耳道。麦克风和耳机可彼此通信地耦接或者各自与计算设备或服务器通信地耦接。
7、如此,麦克风和耳机可由用户他/她自己使用,而不需要用户处于实验室环境(诸如消声室)中。将麦克风放置在耳道中之后,用户可戴上耳机,使得麦克风可接收由耳机或耳机的扩音器传输的任何声音信号或参考声音信号。可针对用户的双耳重复这些步骤。对于每只耳朵,可从由麦克风接收的声音信号提取相应近场声音信号传递函数。
8、根据一个实施方案,第二声音信号传递函数表示远场或自由场声音信号传递函数。
9、根据一个实施方案,第二声音信号传递函数与声音信号方向相关联;所述方法还包括:确定第三数据,其中第三数据指示声音信号方向,并且其中确定第二数据进一步基于第三数据。换句话讲,第三数据可以是第二输入数据。
10、声音信号方向可由要传输的声音信号(例如,音乐文件)的元数据来指示。通过确定第二数据进一步基于第三数据,可修改要传输的声音信号,以唤起用户对音频信号是从相对于用户耳朵的自由场内的特定方向接收的印象。如此,当只有位于相对于用户的耳朵的有限数量的位置中的有限数量的声音信号源(例如,由用户佩戴的一对耳机)可用时,可通过模拟或合成位于相对于用户的耳朵的不同位置处的一个或多个声音信号源进一步改进用户的声音或音乐感知。因此,可仅使用有限数量的声源(例如,耳机中的两个声源)来实现“环绕声音感知”。
11、根据一个实施方案,所述方法还包括:在接收声音信号之前,通过声音传输装置传输声音信号;和/或基于第二数据来确定用于修改声音信号和/或后续声音信号的滤波函数;和/或通过声音传输装置传输所修改的声音信号和/或所修改的后续声音信号。
12、滤波函数可以是滤波器,诸如有限脉冲响应(fir)滤波器。滤波函数可修改频域和/或时域中的声音信号。分别使用时域到频域变换或频域到时域变换,可将时域中的声音信号变换为频域中的声音信号(例如,声音信号的振幅和/或相谱),反之亦然。时域到频域变换可以是傅里叶变换或小波变换。频域到时域变换可以是逆傅立叶变换或逆小波变换。滤波函数可修改声音信号或声音信号的一部分的振幅谱和/或相位谱和/或其频域到时域变换和/或传输声音信号或声音信号的一部分的时间延迟。
13、根据一个实施方案,使用基于人工智能或基于机器学习的回归算法(优选地神经网络模型)来确定第二数据,特别地其中第一数据和/或第三数据被用作神经网络模型的输入。术语“基于人工智能的回归算法”或“基于机器学习的回归算法”和术语“神经网络模型”在本文中在适当情况下可互换地使用。
14、使用神经网络模型,个性化声音信号传递函数(例如,与特定用户的特定耳朵相关联的特定方向的自由场hrtf的频率响应)可基于与此特定耳朵相关联的近场hrtf数据的频率响应来精确地生成(而不是从多个声音信号传递函数选择),其中所述数据可由用户他/她自己在家里收集。
15、根据一个实施方案,所述方法还包括在训练过程中用于启动和/或训练回归算法的计算机实现的方法。如果尚未以其他方式获得,则执行训练过程可产生可用于确定第二数据的训练神经网络模型。
16、根据本发明的另一方面,提供了一种用于启动和/或训练神经网络模型的计算机实现的方法,所述方法包括:确定训练数据集,其中所述训练数据集包括多个第一训练数据和多个第二训练数据;以及基于所述训练数据集来启动和/或训练所述神经网络模型,以基于与用户的耳朵相关联的输入第一声音信号传递函数来输出与所述用户的耳朵相关联的第二声音信号传递函数;其中所述多个第一训练数据中的每一个表示与训练对象的或训练用户的耳朵或者相应训练用户的耳朵相关联的相应第一训练声音信号传递函数;其中所述多个第二训练数据中的每一个表示与所述训练用户的耳朵或所述相应训练用户的耳朵相关联的相应第二训练声音信号传递函数。
17、所述训练对象可以是训练用户、训练模型、训练假人等。术语培训对象和训练用户在本文中可互换地使用。所述训练数据集可在实验室环境(诸如消声室)中收集或确定。所述多个第一和第二训练数据中的每一者可与特定训练用户的特定耳朵相关联。在训练过程期间,神经网络模型可将第一训练数据的属性分配给第二训练数据的属性,使得训练的神经网络模型可被配置为从第一训练数据导出第二训练数据或第二训练数据的近似值和/或反之亦然。所收集的训练数据集可包括用于训练神经网络模型的训练子集以及用于测试和评估所训练的神经网络模型的测试子集。
18、例如由训练数据的测试子集包括的尚未在训练过程期间使用的新第一训练数据和第二训练数据可用于评估模型的质量或准确度。新第一训练数据可用作模型的输入,新第二训练数据可用于与模型的输出进行比较以便确定误差,例如,误差值。
19、根据一个实施方案,相应第一训练声音信号传递函数中的每一个表示相应近场声音信号传递函数,特别地其中输入第一声音信号传递函数表示近场声音信号传递函数。
20、第一训练数据可基于由位于训练用户的耳道中或附近的麦克风接收的声音信号来确定,例如,收集或生成。麦克风所接收的声音可通过训练用户的耳朵附近的声音传输装置例如通过由训练用户佩戴的耳机传输。
21、根据一个实施方案,相应第二训练声音信号传递函数中的每一个表示相应远场或自由场声音信号传递函数,特别地其中输出第二声音信号传递函数表示远场或自由场声音信号传递函数。
22、第二训练数据可基于由位于训练用户的耳道中或附近的麦克风接收的声音信号来确定,例如,收集或生成。麦克风所接收的声音可由位于训练用户或训练对象的远场或自由场内的其他声音传输装置传输。例如,每个相应第二训练声音信号由位于相对于训练用户的耳朵的自由场或远场内的相应方向上的多个声音传输装置中的相应一个传输。例如,训练用户被这些声音传输装置包围。声音传输装置可以是消声室中的设置的一部分。换句话讲,由声音传输装置传输的声音信号非反射地接收到训练用户的耳朵。
23、根据一个实施方案,所述相应第二训练声音信号传递函数中的每一个与相对于所述训练用户的耳朵的训练声音信号方向或相对于所述训练用户的耳朵的相应训练声音信号方向相关联;和/或其中所述训练数据集还包括第三训练数据,其中所述第三训练数据指示所述训练声音信号方向或所述相应训练声音信号方向;和/或其中所输出的第二声音信号传递函数与相对于所述用户的耳朵的输入声音信号方向相关联,特别地其中启动和/或所述训练神经网络模型以输出所述第二声音信号传递函数进一步基于所述输入声音信号方向。换句话讲,所述模型被训练来输出与声音信号方向(即,输出声音信号方向)相关联的输出第二声音信号传递函数,所述声音信号方向被用作所述模型的输入。
24、此外,训练声音信号方向可以是第二或输出训练声音信号方向。相应第一训练声音信号传递函数中的每一个可与相对于训练用户的耳朵的第一训练声音信号方向或相对于训练用户的耳朵的相应第一训练声音信号方向相关联,和/或其中第三训练数据指示第一训练声音信号方向和第二训练声音信号方向或相应第一训练声音信号方向和相应第二训练声音信号方向,和/或其中启动和/或训练神经网络模型以输出第二声音信号传递函数进一步基于作为模型的输入的第一声音信号方向和第二声音信号方向。
25、第三训练数据可针对每个第二训练数据指示相对于用户的耳朵从哪个方向接收声音信号。如此,神经网络模型可将所接收的训练声音信号的属性或者训练声音信号的频率或脉冲响应分配给从其接收训练声音信号的方向。
26、因此,训练的神经网络模型可被配置为基于包括表示近场频率响应的数据和表示特定方向的数据的输入数据来输出与特定方向相关联的远场或自由场频率响应。
27、根据一个实施方案,用于启动和/或训练神经网络模型的计算机实现的方法还包括:在相对于训练用户的耳朵的近场内,从第一声音传输装置、特别是从由训练用户佩戴的耳机在训练用户的耳朵中或在训练用户的耳朵处接收多个第一训练声音信号;以及基于所接收的多个第一训练声音信号中的每一个来确定相应第一训练声音信号传递函数;和/或在相对于训练用户的耳朵的远场或自由场内,从第二声音传输装置或相应第二声音传输装置在训练用户的耳朵中或在训练用户的耳朵处接收多个第二训练声音信号;以及基于所接收的多个第二训练声音信号中的每一个来确定相应第二训练声音信号传递函数;特别地其中训练声音信号方向或相应训练声音信号方向表示在训练用户的耳朵处或在训练用户的耳朵中相对于训练用户的耳朵接收相应第二训练声音信号的方向和/或第二声音传输装置或相应第二声音传输装置相对于训练用户的耳朵定位的方向。
28、根据一个实施方案,所述第三训练数据包括指示训练声音信号方向(即,输出训练声音信号方向,即与所述第二训练数据或相应第二训练声音信号传递函数相关联的训练声音信号方向)的矢量数据,并且其中所述第三训练数据包括第二矢量数据,其中所述第二矢量数据取决于所述第一矢量数据,特别是从所述第一矢量数据导出。
29、第三训练数据可包括相应矢量,所述相应矢量包括每个声音信号方向的相应矢量数据。第一矢量和第二矢量可分别表示笛卡尔或球面第一矢量和第二矢量。第二矢量数据可用于扩展第一矢量数据。例如,第一矢量和第二矢量可分别表示各自具有三个矢量项的三维笛卡尔第一矢量和第二矢量。第二矢量数据可用于将第一矢量从三维矢量转移到六维矢量。第一矢量可平行于或反平行于第二矢量。第二矢量的项可表示第一矢量的项的绝对值和/或因式分解值。替代地或另外,第三数据可包括零矢量,特别是与第一矢量具有相同维度的零矢量,而不是第一矢量。
30、通过引入一个或多个第二矢量数据,例如通过引入一个或多个扩展矢量,创建基于方向矢量的数据流并行化。因此,可在神经网络模型架构中使用一个或多个并行层或其部分。具体地,在训练过程中,可通过基于扩展矢量的不同模型输出(即不同的方向数据)的比较来训练模型。因此,可增强模型,例如,可实现模型的更好收敛。
31、根据本发明的另一方面,提供了一种数据处理系统,其包括:用于执行用于生成个性化声音信号传递函数的计算机实现的方法和/或用于启动和/或训练神经网络模型的计算机实现的方法的装置。
32、根据本发明的另一方面,提供了一种计算机可读存储介质,其包括:指令,所述指令在由数据处理系统执行时使数据处理系统执行用于生成个性化声音信号传递函数的计算机实现的方法和/或用于启动和/或训练神经网络模型的计算机实现的方法。
33、通过参考附图阅读以下对非限制性实施方案的描述,可以更好地理解本发明。
- 还没有人留言评论。精彩留言会获得点赞!