一种基于核密度估计的失陷账号检测方法及系统与流程
1.本发明涉及数据识别、数据表示及数据处理技术领域,特别是涉及一种基于核密度估计的失陷账号检测方法及系统。
背景技术:
2.随着网络技术的日益发展,网络数据的数据安全、信息安全等问题越来越突出。目前种类繁多的外部网络攻击已有成熟的解决方案,但是,由于组织内部引起的违规泄露事件,如账号的异常登录引起的敏感数据外泄行为,传统的基于网关的安全架构无法有效解决组织内部引起的违规泄露事件,无法在事件发生之前或之后的较短时间内即时响应,造成信息泄露等安全性事件的发生。
技术实现要素:
3.为了解决上述问题,本发明提出了一种基于核密度估计的失陷账号检测方法及系统,基于网络中的实际实体及行为数据,构建账号正常在线时间历史基线与常用登录设备基线,以此发现偏离历史基线的行为,定位失陷账号风险,准确发现网络的数据失泄密行为,提高异常行为检测的准确性,保证数据安全。
4.为了实现上述目的,本发明采用如下技术方案:第一方面,本发明提供一种基于核密度估计的失陷账号检测方法,包括:通过核密度估计算法对账号在不同时间点的在线数据进行概率估计,以此建立账号在线时间历史基线;通过核密度估计算法对账号在不同设备的登录数据进行概率估计,以此建立账号登录设备历史基线;根据账号在线时间历史基线和账号登录设备历史基线,对待测账号实际的登录时间和登录设备进行偏离诊断;若偏离诊断结果异常,则定位为失陷账号,若偏离诊断结果正常,则定位为正常账号。
5.作为可选择的实施方式,建立账号在线时间历史基线的过程包括:获取账号在不同时间点的在线数据,所述在线数据包括登录时间,聚合统计账号登录时间的次数分布序列,根据次数分布序列采用核密度估计算法得到不同时间点账号登录的概率密度。
6.作为可选择的实施方式,建立账号在线时间历史基线的过程包括:以小时为粒度聚合账号的在线数据,得到账号登录时间的次数分布序列;选定带宽及核函数,构建核密度估计函数,以根据次数分布序列得到不同时间点账号登录的概率密度。
7.作为可选择的实施方式,建立账号在线时间历史基线的过程包括:对概率密度小于时间阈值的时间点定义为非正常登录时间。
8.作为可选择的实施方式,建立账号登录设备历史基线的过程包括:获取账号在不同设备的登录数据,所述登录数据包括账号在不同设备上的登录次数,根据登录次数采用
核密度估计算法得到账号在不同设备上登录的概率密度。
9.作为可选择的实施方式,建立账号登录设备历史基线的过程包括:聚合账号登录设备的ip,得到账号登录设备及登录次数的序列;选定带宽以及核函数,构建核密度估计函数公式,根据得到的序列采用核密度估计函数得到账号在不同设备上登录的概率密度。
10.作为可选择的实施方式,建立账号登录设备历史基线的过程包括:对概率密度小于设备阈值的登录设备定义为非常用登录设备。
11.作为可选择的实施方式,对待测账号实际的登录时间和登录设备进行偏离诊断的过程包括:若待测账号实际的登录时间偏离账号在线时间历史基线,则偏离诊断结果异常,定位为失陷账号行为。
12.作为可选择的实施方式,对待测账号实际的登录时间和登录设备进行偏离诊断的过程包括:若待测账号实际的登录设备偏离账号登录设备历史基线,则偏离诊断结果异常,定位为失陷账号行为。
13.第二方面,本发明提供一种基于核密度估计的失陷账号检测系统,包括:第一基线构建模块,被配置为通过核密度估计算法对账号在不同时间点的在线数据进行概率估计,以此建立账号在线时间历史基线;第二基线构建模块,被配置为通过核密度估计算法对账号在不同设备的登录数据进行概率估计,以此建立账号登录设备历史基线;检测模块,被配置为根据账号在线时间历史基线和账号登录设备历史基线,对待测账号实际的登录时间和登录设备进行偏离诊断;定位模块,被配置为若偏离诊断结果异常,则定位为失陷账号;若偏离诊断结果正常,则定位为正常账号。
14.与现有技术相比,本发明的有益效果为:本发明提出一种基于核密度估计的失陷账号检测方法及系统,基于网络中的实际实体及行为数据,构建账号正常在线时间历史基线与常用登录设备基线,以此发现偏离历史基线的行为,定位失陷账号风险,准确检测失陷账号,准确发现网络中的数据失泄密行为,提高异常行为检测的准确性,保证数据安全。
15.本发明提出一种基于核密度估计的失陷账号检测方法及系统,通过核密度估计算法对账号正常登录时间及常用登录设备建立历史基线,真实还原账号登录时间及空间情况,有利于账号失陷的检测。
16.本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
17.构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
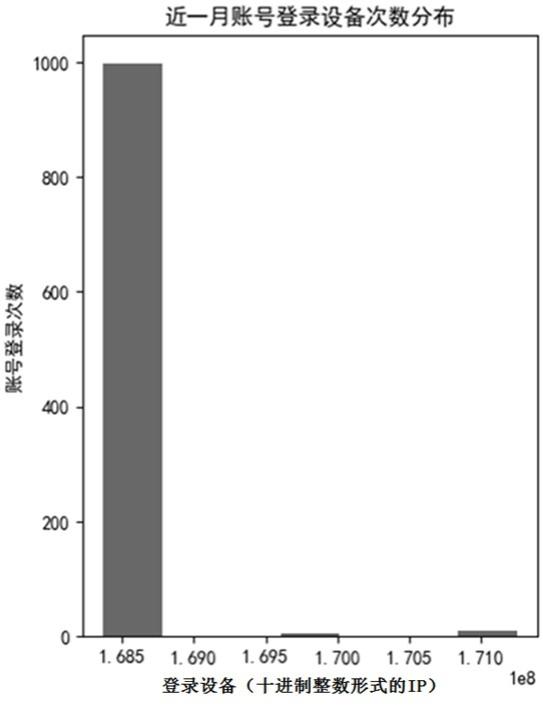
18.图1为本发明实施例1提供的基于核密度估计的失陷账号检测方法示意图;图2(a)-2(b)为本发明实施例1提供的近一月账号登录设备次数分布和近一月账号登录设备概率趋势示意图;图3(a)-3(b)为本发明实施例1提供的近一月账号24时登录次数分布和近一月账
号24时登录概率趋势示意图。
具体实施方式
19.下面结合附图与实施例对本发明做进一步说明。
20.应该指出,以下详细说明都是示例性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。
21.需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本发明的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
22.在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
23.实施例1如图1所示,本实施例提供一种基于核密度估计的失陷账号检测方法,包括:s1:通过核密度估计算法对账号在不同时间点的在线数据进行概率估计,以此建立账号在线时间历史基线;s2:通过核密度估计算法对账号在不同设备的登录数据进行概率估计,以此建立账号登录设备历史基线;s3:根据账号在线时间历史基线和账号登录设备历史基线,对待测账号实际的登录时间和登录设备进行偏离诊断;s4:若偏离诊断结果异常,则定位为失陷账号,若偏离诊断结果正常,则定位为正常账号。
24.在本实施例中,以内网安全为例,将内网网络环境中多元异构的数据仿真抽象为实体及实体的行为数据,实体即为人员、设备、数据等有形的实体,行为数据即为实体在网络中的行为动作日志;通过用户网络行为与主机行为等信息整合,完成用户与实体的关联,完整还原用户行为,实现网络账号与实体的关联,仿真网络真实用户行为。
25.本实施例从实体数据与实体行为数据中,获取用户账号信息以及账号登录行为信息,如表1所示:表1账号信息以及账号登录行为信息账号登录时间登录ip109612021-11-0108:0010.11.110.72109612021-11-0109:3010.11.110.71在步骤s1中,账号正常在线时间的概率估计;通过核密度估计算法对用户账号在不同时间点的在线数据进行概率估计,即得到在不同时间点可能发生账号在线的概率,以此建立账号在线时间历史基线。
26.在本实施例中,用户账号在不同时间点的在线数据包括账号在每个时间点的访问行为、登录时间。
27.作为可选择的一种实施方式,本实施例选择24小时内不同时间点的账户在线数据。
28.在本实施例中,获取账号不同时间点的在线数据后,聚合统计账号登录时间的次数分布,利用核密度估计算法计算不同时间点账号登录概率密度;同时将低于既定阈值的时间段定义为非正常登录时间。
29.在步骤s2中,账号常用登录设备的概率估计;通过核密度估计算法对用户账号在不同设备的登录数据进行概率估计,即得到用户账号在不同设备可能发生账号登录的概率,以此建立账号登录设备历史基线。
30.在本实施例中,获取用户在一段时间内账号在不同设备的登录数据,得到账号在不同设备登录次数的序列分布,以此建立账号登录设备历史基线。
31.在本实施例中,获取账号在不同设备的登录数据后,计算账号在不同设备上的登录次数,利用核密度估计算法计算不同设备账号登录的概率密度;同时将低于既定阈值的设备定义为非常用登录设备。
32.由给定样本集求解随机变量的分布密度函数问题是概率统计学的基本问题,解决这一问题的方法主要有参数估计以及非参数估计。在参数估计中,需要假定数据分布符合某种特定的分布。经验和理论说明参数模型的这种基本假定与实际物理模型之间往往存在较大差距。
33.核密度估计算法是概率分布函数密度中非参数估计的典型方法,核密度估计算法并不加入任何先验知识,无需对数据样本的分布情况建模,而是根据已知数据样本本身的特点、性质来拟合分布,非常适合于对未知样本的概率估计。
34.核密度估计算法的原理是根据待估计点与每个样本点的距离得到密度值,距离越近,得到的密度值就越大,相反,距离越远,得到的密度值就越小,最后将所有密度值加权平均就得到该估计点在样本分布中的概率密度值。
35.假设有数据样本集{x|x1,x2,
…
,xn}的共n个样本,样本的概率密度函数为f(xi),其核密度函数估计公式为:其中,为核函数,包括高斯函数、余弦函数等,通常具有对称性,并且满足;参数h为核函数带宽,用于平衡核密度估计的偏差以及方差;xi、xj为第i个样本和第j个样本。
36.那么,在建立账号在线时间历史基线的过程中,以小时为粒度聚合一段时间内的账号在线数据,获得一组小时时间点以及登录次数的序列;根据登录时间点和登录次数,选定带宽以及核函数,采用核密度估计函数公式,对用户正常在线时间进行概率估计;同时对于估计概率不小于既定阈值的时间点定义为账号正常在线时间。
37.在建立账号登录设备历史基线的过程中,聚合一段时间内账号登录设备的ip,获
得一组账号登录设备以及登录次数的序列;根据登录设备ip、登录次数,选定带宽以及核函数,采用核密度估计函数公式,对用户常用登录设备进行概率估计;同时对于估计概率不小于既定阈值的登录设备定义为账号登录常用设备。
38.在步骤s3-s4中,对待测账号实际的登录时间和登录设备进行偏离诊断,根据账号登录的时间和设备是否偏离基线来检测定位账号失陷行为;建立账号在线时间历史基线以及账号登录设备历史基线后,获取待测账号实际的登录时间和登录设备,判断账号实际登录时间及登录设备是否偏离账号在线时间历史基线以及账号登录设备历史基线,若账号实际登录时间偏离账号在线时间历史基线和/或账号实际登录设备偏离账号登录设备历史基线,即待测账号在非正常登录时间或在非常用登录设备上登录时,偏离诊断结果异常,则定位为账号失陷行为,否则偏离诊断结果正常,定位为正常账号。
39.本实施例的实验数据为时间跨度共66天的oa系统登录日志,数据量为451134条数据,共3256个用户。
40.以用户id为12936的数据为例,在近一个月登录设备如表2所示;其中,登陆ip为点分十进制的表示形式,将登陆ip转换为十进制整数值形式的数字编号,设ip地址为 a.b.c.d,则转换公式为:a*2563+b*2562+c*256+d;如ip地址为10.11.120.6时,则10+2563+11*2562+120*256+6=168523782。
41.表2 登录设备用户id登录ipip转换为数字编号登录次数1293610.11.120.61685237822051293610.9.32.751683702511971293610.11.120.16168523792991293610.53.1.25417124607861293610.30.106.2516976540131293610.11.120.516852378121293610.9.26.381683686781登录时间如表3;表3登录时间用户id登录时间(小时)登录次数1293687112936930129361024129361139129361217129361337129361426129361530129361631129361753
12936184412936193512936201812936211612936222612936232312936021293633如图2(a)-2(b)所示为近一月账号登录设备次数分布和近一月账号登录设备概率趋势示意图,当动态阈值设置为0.02时,可发现用户的常用登录设备为:10.11.120.6,10.9.32.75,10.11.120.16。
42.如图3(a)-3(b)所示为近一月账号24时登录次数分布和近一月账号24时登录概率趋势示意图,当动态阈值设置为0.02时,发现用户正常工作时间大概为8时-23时,0-5时为非正常工作时间。
43.检索用户12936在非正常工作时间使用非常用设备登录的痕迹,如发现用户12936在2021-11-25晚1点登录的记录,疑似账号失陷。
44.实施例2本实施例提供一种基于核密度估计的失陷账号检测系统,包括:第一基线构建模块,被配置为通过核密度估计算法对账号在不同时间点的在线数据进行概率估计,以此建立账号在线时间历史基线;第二基线构建模块,被配置为通过核密度估计算法对账号在不同设备的登录数据进行概率估计,以此建立账号登录设备历史基线;检测模块,被配置为根据账号在线时间历史基线和账号登录设备历史基线,对待测账号实际的登录时间和登录设备进行偏离诊断;定位模块,被配置为若偏离诊断结果异常,则定位为失陷账号;若偏离诊断结果正常,则定位为正常账号。
45.此处需要说明的是,上述模块对应于实施例1中所述的步骤,上述模块与对应的步骤所实现的示例和应用场景相同,但不限于上述实施例1所公开的内容。需要说明的是,上述模块作为系统的一部分可以在诸如一组计算机可执行指令的计算机系统中执行。
46.上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1