一种无人机自组织网络信道接入方法与流程
1.本发明涉及信道接入技术领域,特别是涉及一种无人机自组织网络信道接入方法。
背景技术:
2.无人机自组织网络因为其具有广阔的应用前景而受到越来越多的研究关注,其中mac协议控制着全网节点在接入无线信道时所遵循的规则,决定了如何最大限度使用有限的信道带宽,因此信道技术的好与坏直接决定了无线信道的利用率和整体的网络性能。目前无人机自组网主要依靠传统ad hoc网络中的竞争类协议进行信道接入的管控,但无人机自组网具有节点高速移动、拓扑动态变化的特点,现有协议无法满足性能要求,因而研究无人机自组网中的mac技术具有很重要的意义。
3.网络动态性对于竞争类协议的影响在于信道的竞争环境会发生变化,例如活跃节点数、其他节点接入策略等的变化,这就要求各节点具有一定的反馈和调节能力,能以动态策略调整的方式进行信道接入。现有的基于csma机制的竞争类协支持节点快速入网/退网,但接入碰撞概率随着节点数的增加而增加,缺乏自适应性。
4.本发明在深度强化学习技术的基础上,将每个无人机节点作为决策体,提出一种分布式的自适应mac算法,使节点与环境交互学习直到获得自适应性较强的接入策略,提高信道利用率和公平性,降低传输时延,具有可观的应用前景。
技术实现要素:
5.有鉴于此,本发明的目的在于提供一种无人机自组织网络信道接入方法,用以在p-坚持csma协议的基础上,让信道接入概率p随着环境的改变而自适应调整,以提高信道利用率和公平性,降低传输时延。
6.为了实现上述目的,本发明采用如下技术方案:
7.一种无人机自组织网络信道接入方法,所述接入方法应用于基于无人机自组织网络的通信场景,将无人机自组织网络中的每个节点作为决策体,再基于深度强化学习算法,使得决策体与环境进行交互学习,得到具有自适应性的接入策略,所述接入方法具体包括如下步骤:
8.步骤s1、在某一时隙,当所述无人机自组织网络中一个或者多个节点在执行数据传输任务时,首先对信道进行载波侦听,判断是否有空闲信道,若所有道均为占用状态,则选择推迟接入,在下一个时隙再进行决策;
9.若存在至少一条空闲信道,则根据闲时接入概率,选择其中一条空闲信道进行接入,占用若干个时隙对接收节点进行数据包发送,或者,选择推迟接入,继续进行载波侦听;
10.步骤s2、定义节点在进行不同决策时,获得的信道反馈以及反馈对应的奖励值,包括:若节点选择推迟接入,则信道反馈为信道的忙闲状态,奖励值为0;若节点选择接入一条空闲信道且信道反馈为接入成功,则奖励值为1;若节点选择接入一条空闲信道且信道反馈
为节点碰撞,接入失败,则奖励值为c,其中,-1《c《0;
11.步骤s3、选择某一节点与其他其他节点进行交互学习,并且比较该节点与周围邻近无人机节点的决策,根据决策的相似程度修改步骤s2中的奖励值,其中,相似程度越高,其接入成功的奖励值就越大,其余奖励值保持不变;
12.步骤s4、构建深度q网络以及训练用经验重放池,以该经验重放池作为输入对所述深度q网络进行训练,通过梯度下降法更新网络中的参数,在进行多次迭代之后固定网络参数,得到信道分配模型,其中,经验重放池包括步骤s3中选择的节点,其当前与过去若干时步内的决策和反馈;
13.步骤s5、针对步骤s3中选择的节点,将其历史经验作为当前状态输入至步骤s4中得到的信道分配模型中,通过该模型计算出节点下一步进行不同决策对应的不同概率,即所述闲时接入概率;
14.步骤s6、针对该通信场景中所有具有数据传输任务的节点,重复步骤s1-步骤s5,根据闲时接入概率做下一个决策,直至各节点获得具有自适应性的接入策略。
15.进一步的,所述基于无人机自组织网络的通信场景,在该场景中,包括n个节点,m个信道,每个信道具有相同的带宽和接入条件,每条信道划分为多个时隙,其中,节点和信道的集合分别记为:和
16.进一步的,所述步骤s3具体包括:
17.步骤s301、设定节点在接入信道进行发送时,将当前决策对应的闲时接入概率附在数据包上发出;
18.步骤s302、每个节点记录收到的来自周围节点的闲时接入概率p,其中,p
min
为接收到的最小值,p
max
为接收到的最大值;
19.步骤s303、将区间[p
min
,p
max
]均匀分为8个小区间,按p所在区间的数量将8个小区间降序排序为{[it0,it1],[it1,it2],
······
,[it7,it8]},即在区间[it0,it1]中p值出现最频繁,8个区间对应的奖励值为
[0020]
步骤s304、当节点当前决策是接入信道且接入成功,则根据决策的闲时接入概率p所在区间将本次决策的奖励值从1改为r
ace
。
[0021]
进一步的,在所述步骤s4中,采用两个结构相同但参数不同的深度q网络进行训练,分别命名为主网络和目标网络,网络参数分别初始化为θ和θ-,每隔f个时步将主网络的参数赋值给目标网络,以降低数据之间的相关性,其中,所述的深度q网络,其采用了循环神经网络rnn结构,包括一个输入层,两个隐藏层和一个输出层,其中两个隐藏层分别为长短期记忆层lstm和一个前向传播层fnn。
[0022]
进一步的,在所述步骤s4中,在训练之前,需要建立初始集合{s
t
,a
t
,r
t+1
,s
t+1
},其中,s
t
为时步t的状态,a
t
为时步t采取的决策,r
t+1
为时步t采取决策后获得的奖励,s
t+1
为时步t的下一个时步的状态;节点在时步t可能采取的动作a
t
∈{0,1,2,...,m},a
t
为0时,节点选择推迟接入,a
t
为m,且m不为0时,节点选择信道m进行接入;状态s
t+1
=[c
t-ω+2
,...,c
t
,c
t+1
],其中c
t+1
=[a
t
,z
t
]
t
,z
t
为节点在时步t采取决策后获得的反馈,表达式为:
分别代表了载波侦听的结果和接入信道的结果,ω为状态历史长度。
[0023]
进一步的,所述状态历史长度,其值满足:16≤ω≤32。
[0024]
进一步的,在所述步骤s4中,在进行训练时,以s
t
作为网络输入,其网络输出为:
[0025][0026]
公式(1)中,a表示在动作集合中所有可能的动作,θ是神经网络中边的权重,q即为在t时刻状态下所有可能决策所对应的得分;
[0027]
对经过公式(1)得到的q用ε-greedy和softmax算法处理,整合成闲时接入概率,其表达式为:
[0028]
σn(t)={p
n,0
(t),p
n,1
(t),...,p
n,m
(t)}
ꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0029]
公式(2)中,当m不为0时,p
n,m
(t)表示为节点n在时步t选择接入信道m的概率,m为0时,p
n,0
(t)表示节点推迟接入的概率。
[0030]
进一步的,在所述步骤s4中,在进行训练时,需考虑时步的非均匀分布特性,来计算损失函数,通过梯度下降法更新神经网络参数,其具体包括:
[0031]
每个决策都对应一个时间步骤,载波侦听决策需要1个时隙,信道接入决策则需要若干个时隙,则在τ时步现实奖励值计算表达式为:
[0032][0033]
在公式(3)中,γ为时间折扣因子,0<γ<1,d(a
τ
)为节点在时步τ所做决策需要持续的时间;
[0034]
损失函数的计算表达式为:
[0035][0036]
在公式(4)中,ne为训练神经网络时从经验池e取出的样本数量,e
τ
为离散的样本;
[0037]
对损失函数l(θ)运用梯度下降法,更新神经网络参数,计算方法如下:
[0038][0039]
在公式(5)中,为q(s
τ
,a
τ
;θ)的梯度函数。
[0040]
本发明的有益效果是:
[0041]
与现有技术相比,本发明在深度强化学习技术的基础上,将每个无人机节点作为决策体,提出一种分布式的自适应信道接入算法,使节点与环境交互学习直到获得自适应
性较强的接入策略,提高信道利用率和公平性,降低传输时延,具有可观的应用前景。
附图说明
[0042]
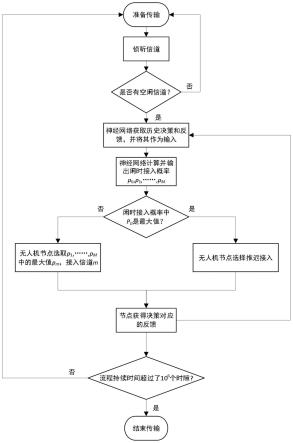
图1为实施例1中提供的一种无人机自组织网络信道接入方法的流程示意图;
[0043]
图2为实施例1中提供的无人机自组网的网络模型图;
[0044]
图3为实施例1中提供的无人机节点与环境的进行交互学习的示意图。
具体实施方式
[0045]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0046]
实施例1
[0047]
参加图1-图3,本实施例提供一种无人机自组织网络信道接入方法,该方法在深度强化学习技术的基础上,将每个无人机节点作为决策体,使节点与环境交互学习直到获得自适应性较强的信道接入策略。该方法包括如下过程:
[0048]
步骤1、无人机节点有数据传输需求时,首先会对信道进行载波侦听,若所有信道均为占用状态,则节点只能选择推迟接入,在下一个时隙再进行决策;
[0049]
若侦听到存在空闲信道,节点根据闲时接入概率,可以选择接入一条空闲信道,占用之后若干个时隙对特定节点进行数据包发送,或选择推迟接入,继续进行载波侦听;
[0050]
步骤2、无人机节点的不同决策得到信道的不同反馈和奖励值,具体包括:
[0051]
若无人机节点选择推迟接入,则信道反馈为信道的忙闲状态,奖励值为0;
[0052]
若节点选择接入一条空闲信道且信道反馈为接入成功,则奖励值为1;
[0053]
若节点选择接入一条空闲信道且信道反馈为节点碰撞,接入失败,则奖励值为c(-1《c《0);
[0054]
步骤3、节点与周围其他节点进行交互学习,比较当前决策无人机节点与周围邻近无人机节点的决策,根据决策的相似程度修改步骤2中的奖励值,相似程度越高接入成功的奖励值就越大,其余奖励值保持不变;
[0055]
步骤4、将当前与过去若干时步内的决策和反馈成对存储到深度强化学习算法的经验重放池,每次训练神经网络时从经验池中抽取一簇数据,通过梯度下降法更新网络中边的权重;将节点的历史决策和反馈作为当前状态输入神经网络,神经网络会相应地计算出节点下一步进行不同决策对应的不同概率,即闲时接入概率;
[0056]
步骤5、无人机节点重复以上步骤,根据闲时接入概率做下一个决策,直至各节点获得自适应性较强的接入方法。
[0057]
具体的说,在本实施例中,无人机自组网的网络模型如图2所示,假设网络中共有n个节点,节点按所在位置划分为多个集群,不同集群的无人机节点共享有限的带宽资源,这一资源可根据频谱划分出m个信道,每个信道具有相同的带宽和接入条件。节点和信道的集合分别记为:和
[0058]
根据基于随机竞争的csma机制要求,每条信道又可划分为多个时隙,每个无人机
节点在有数据发送需求时会在某个时隙选择一个可用信道进行接入,当两个或更多邻近节点在同一时隙选择接入同一信道时,会发生碰撞干扰,导致接入无效。
[0059]
具体的说,在本实施例中,由于节点的发送范围有限,两个距离较远的节点同时接入同一条信道不会造成干扰,因此无线信道具有一定的复用性。在图2中,簇1和簇2中的无人机节点距离较近,因此无人机no.1~5构成一个干扰域,同理无人机no.4~6构成另一个干扰域。同一干扰域中的节点不能在同一时隙接入同一信道,而不同干扰域中的节点不受限制。
[0060]
具体的说,在本实施例中,在每个时隙开始时,无人机节点需要进行决策,其具体包括:
[0061]
若节点没有数据传输需求,则节点只能选择推迟接入信道,继续保持载波侦听;若节点有数据传输需求,则节点会首先参考上一时隙的决策与反馈,若上一时隙节点进行侦听且发现空闲信道,则节点在空闲的信道中选择一条进行接入,占用之后若干个时隙对特定节点进行数据包发送,否则节点只能选择推迟接入信道并继续保持载波侦听。
[0062]
具体的说,在本实施例中,节点具体选择接入哪条信道根据闲时接入概率来判断。节点在时步t所能采取的决策可表示为a
t
∈{0,1,2,...,m},其中a
t
为0代表节点选择推迟接入,a
t
为m(m≠0)代表节点选择信道m进行接入,m是空闲信道中的一条。
[0063]
具体的说,在本实施例中,无人机节点每做完一次决策就会获得相应的来自信道的反馈,节点根据不同反馈获取相应的奖励,其具体包括:
[0064]
若无人机节点选择推迟接入,则信道反馈为信道的忙闲状态,节点获得的奖励值为0;若节点选择接入一条空闲信道且信道反馈为发送成功,则节点获得的奖励值为1;
[0065]
若节点选择接入一条空闲信道但同一干扰域有其他节点选择了同时接入,信道反馈为接入失败,则节点获得的奖励值为c(-1《c《0)。
[0066]
节点在时步t采取决策后获得的反馈为z
t
,表示为:
[0067][0068]
具体的说,在本实施例中,对深度强化学习过程建立初始集合{s
t
,a
t
,r
t+1
,s
t+1
},其中s
t
为时步t的状态,a
t
为时步t采取的决策,r
t+1
为时步t采取决策后获得的奖励,s
t+1
为时步t的下一个时步的状态,即为节点能够观察到的信道现状和获取的历史经验,可表示为s
t+1
=[c
t-ω+2
,...,c
t
,c
t+1
],其中c
t+1
=[a
t
,z
t
]
t
,ω为状态历史长度也即经验窗口的长度,ω越大则节点做决策时所能获得的参考更多,做出合理决策的可能性越大,但同时状态空间的增长会导致算法收敛性变差。
[0069]
更具体的说,在本实施例中,ω选择折中的数值,其具体为16≤ω≤32。
[0070]
具体的说,在本实施例中,节点与环境的交互学习过程如图3所示,在t-4时,节点选择信道2进行接入且发送成功;由于节点在上一时隙处于发送状态,没有进行载波侦听,所以在t-3时,节点只能选择侦听,结果为有空闲信道;因为上一时隙侦听结果为空闲,在t-2时刻节点可以选择接入,但节点根据闲时接入概率选择了推迟接入,侦听结果为信道全部繁忙;在t-1时刻完成侦听后,t时刻节点选择了信道1进行接入并成功完成了发送。
[0071]
具体的说,在本实施例中,节点除了与环境进行交互学习,还可以通过与周围节点
进行交互学习来提高算法性能。与周围其他节点进行交互学习的方法为:
[0072]
步骤301、节点在接入信道进行发送时,会将当前决策对应的闲时接入概率附在数据包上发出;
[0073]
步骤302、每个节点记录收到的来自周围节点的闲时接入概率p,p
min
为接收到的最小值,p
max
为接收到的最大值;
[0074]
步骤303、将区间[p
min
,p
max
]均匀分为8个小区间,按p所在区间的数量将8个小区间降序排序为{[it0,it1],[it1,it2],
······
,[it7,it8]},即在区间[it0,it1]中p值出现最频繁,8个区间对应的奖励值为
[0075]
步骤304、当节点当前决策是接入信道且接入成功,则根据决策的闲时接入概率p所在区间将本次决策的奖励值从1改为r
ace
。
[0076]
具体的说,在本实施例中,在深度强化学习过程中,将当前与过去若干时步内的决策和反馈成对存储到深度强化学习算法的经验重放池,每次训练神经网络时从经验池中抽取一簇数据。
[0077]
具体的说,在本实施例中,上述的神经网络即深度q网络,其采用了循环神经网络rnn结构,包括一个输入层,两个隐藏层和一个输出层,其中两个隐藏层分别为长短期记忆层lstm和一个前向传播层fnn。深度强化学习算法将过去的ω个时步都作为现状态的一部分作为参考,神经网络的输入为s
t
,输出为:
[0078][0079]
在公式(2)中,a表示在动作集合中所有可能的动作,θ是神经网络中边的权重,q即为在t时刻状态下所有可能决策所对应的得分,得分越高意味着决策适合当前环境的可能性越大;
[0080]
对输出q用ε-greedy和softmax算法处理,整合成闲时接入概率,表达式为:
[0081]
σn(t)={p
n,0
(t),p
n,1
(t),...,p
n,m
(t)}
ꢀꢀꢀꢀꢀꢀꢀ
(3)
[0082]
在公式(3)中,m不为0时,p
n,m
(t)即为节点n在时步t选择接入信道m的概率;m为0时,p
n,0
(t)为节点推迟接入的概率。
[0083]
具体的说,在本实施例中,算法采用两个结构相同但参数不同的神经网络,分别命名为主网络和目标网络,网络参数分别初始化为θ和θ-,每隔f个时步将主网络的参数赋值给目标网络,以降低数据之间的相关性。
[0084]
具体的说,在本实施例中,将非均匀时步特性考虑在内时,神经网络的训练和更新过程如下:
[0085]
节点的每个决策都对应一个时间步骤,而每个时步对应的时长不一定相同。节点做推迟接入和载波侦听决策需要1个时隙,做信道接入决策则需要若干个时隙来发送数据包。在深度强化学习中,当前决策的价值由折扣累加的未来有可能演进到的状态的价值来衡量,未来状态的价值对于现状态价值的影响会随着时步推移而逐渐变小,因此对于那些持续时间较长的时步,折扣累加的过程要做修改。
[0086]
当不考虑时步的非均匀特性时,在时步τ现实奖励值计算表达式为:
[0087][0088]
而在本实施例中,现实奖励值计算表达式更新为:
[0089][0090]
在公式(5)中,γ为时间折扣因子,0<γ<1,d(a
τ
)为节点在时步τ所做决策需要持续的时间。更新内容为对奖励做了一个折扣平均处理,把奖励值平摊到每个时隙上,然后对后续状态的最大价值也做了折扣处理,因为下一个时步τ+1已经是d(a
τ
)个时隙之后了。
[0091]
误差函数的计算表达式为:
[0092][0093]
在公式(6)中,ne为训练神经网络时从经验池e取出的样本数量,e
τ
为离散的样本。
[0094]
对误差函数l(θ)运用梯度下降法,更新神经网络参数,计算方法如下:
[0095][0096]
在下一个时隙,神经网络又会获得新的状态,训练并更新参数,输出闲时接入概率,无人机节点根据闲时接入概率选择下一个决策,将决策和反馈输入神经网络,不断重复,直至获得性能较好的自适应接入策略。
[0097]
综上所述,本发明在深度强化学习技术的基础上,将每个无人机节点作为决策体,提出一种分布式的自适应信道接入算法,使节点与环境交互学习直到获得自适应性较强的接入策略,提高信道利用率和公平性,降低传输时延,具有可观的应用前景。
[0098]
本发明未详述之处,均为本领域技术人员的公知技术。
[0099]
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1