一种基于SHVC质量可伸缩帧间视频编码方法
一种基于shvc质量可伸缩帧间视频编码方法
技术领域
1.本发明属于shvc视频编码领域,具体涉及一种基于shvc质量可伸缩帧间视频编码方法。
背景技术:
2.近年来,随着高清、超高清视频应用逐渐走进人们的视野,视频压缩技术受到巨大的挑战。此外,各式各样视频应用也随着网络和存储技术的发展不断涌现,视频应用的多样化和高清化趋势对视频压缩性能提出更高的要求,为此视频编码联合组在2013年发布了新一代视频编码标准h.265/hevc。从根本上来说,h.265/hevc实现了压缩效率比h.264高50%的目标,但是它的框架依旧采用混合编码框架,包括变换、量化、熵编码、帧内预测以及帧间预测等模块,只是几乎在每个模块都引入了新的编码技术。h.265利用递归式的四叉树编码方式大大增强了编码效率,同时也增加了编码复杂度,因此在解决视频清晰度和实时性的同时,不是很好的解决终端设备的多样性和异构性,因此在2014年推出shvc可伸缩视频编码的标准。
3.如图1所示,shvc是hevc的可伸缩扩展,它主要支持时间、空间、质量等三种可伸缩性。与单一的视频编码码流不同的是,可伸缩编码码流分为基本层(bl,一个)和增强层(el,大于等于1)。这样,便将同一视频不同的特征(比如分辨率)合并在同一比特流中,可根据网络特征随时对码流进行调整。基本层码流包含了视频通信的绝大部分信息,它必须被接收,视频通信才能正常进行。
4.现有的一些算法中可以在一定程度上提高编码速度,但质量可伸缩视频编码仍存在一些问题需要去解决:
5.(1)现在的很多研究在进行预测编码单元的模式的时候都会利用相邻的编码单元的模式进行预测,但是并没有考虑到当前编码单元模式和相邻编码单元模式的可能性程度以及层间的相关性。
6.(2)在进行预测深度的时候,通常使用的是自身纹理特征,或者利用相邻编码单元的深度来预测当前编码单元的深度,但是并没用考虑到当前编码单元采用某个深度的可能性概率。
技术实现要素:
7.为解决以上现有技术存在的问题,本发明提出了一种基于shvc质量可伸缩帧间视频编码方法,该方法包括:
8.s1:获取当前编码单元的深度,并获取当前编码单元的相邻编码单元和父编码单元的的模式信息;
9.s2:根据当前编码单元的相邻编码单元和父编码单元的模式信息采用贝叶斯公式计算当前编码单元采用各个模式的概率;编码单元采用的模式包括ilr模式和inter模式;
10.s3:根据不同模式的概率确定当前编码单元的编码模式;
11.s4:利用率失真值判断当前编码单元是否提前终止划分,若提前终止划分,则得到划分结果,若不提前终止划分,则进入下一个深度,并返回步骤s2;利用率失真值判断当前编码单元是否提前终止划分的过程包括:采用高斯混合模型拟合编码单元的率失真分布,计算该模型的最大期望聚类,根据最大期望聚类判断当前编码单元是否需要进一步划分。
12.优选的,采用贝叶斯公式计算当前编码单元采用各个模式的概率的公式为:
[0013][0014]
其中,fd(cd)表示当前编码单元采用cd模式的可能性,cd表示当前编码单元的模式,p((nd,nr)|cd)表示给定当前cu使用模式cd的条件概率下相邻cu使用向量(nd,nr)的概率,nd表示相邻cu使用的模式,nr表示当前cu和相邻cu的相关性程度,p(pr|cd)表示当前cu使用模式cd的条件概率下父cu使用使用pr模式的概率,pr表示父cu使用的模式,p(cd)表示当前cu使用模式cd的概率,p(nd,nr)表示相关性程度为nr并且当前编码单元的相邻cu采用nd模式的概率,p(pr)表示父cu采用模式pr的概率。
[0015]
进一步的,当前cu和相邻cu以及父cu的相关性的过程包括:基本层bl中的cu和增强层el中同等位置的cu除量化参数qp不同之外的其他参数相同,则将el中cus的相关性程度设置为与bl中相同位置的cus的相关程度相同;相邻cus在深度上的绝对差异越小,其空间相关性越强,则设nbd为bl中cu bc的相邻cus的模式;相邻cus在模式上的最大绝对差为4,则将预测的模式分为四类,ilr记为模式0,merge记为模式1,2nx2n记为模式2,nx2n或者2nxn记为模式3,其他模式记为模式4;采用关联度向量公式计算相邻cu以及父cu的相关性。
[0016]
进一步的,关联度向量公式为:
[0017]
nri=4-|nd
i-nbdi|
[0018]
其中,ndi和nbdi分别为深度级向量nd和nbd的第i个分量,nri表示第i个相邻编码单元和当前编码单元的模式关联度。
[0019]
优选的,判断当前编码单元是否提前终止划分包括确定当前编码单元提前终止划分的条件,该条件包括ilr模式提前终止条件和inter模式提起终止条件;当满足提前终止条件时,则输出划分结果,若不满足条件时则继续划分。
[0020]
进一步的,ilr模式提前终止条件的确定过程包括:
[0021]
步骤1:获取当前编码单元中增强层和基本层的量化系数ze和zb;根据量化系数ze和zb确定系统的最小系数值k2;
[0022]
步骤2:根据当前编码单元中增强层的量化系数ze和最小系数值k2可得:
[0023]
re≤q
estep
rb/q
bstep
+k2q
estep
[0024][0025]
其中,re为el层dct变化的系数,q
estep
为el层量化步长,rb表示,q
bstep
表示,r表示dct变换系数,d
iμ
表示整数dct变换矩阵在(i,μ)处的值,x
μv
表示残差矩阵在(μ,v)处的值;
[0026]
步骤3:获取dct整数变换矩阵a,根据dct整数变换矩阵a得到d
iμ
的最大值为1,则有:
[0027][0028]
步骤4:根据re和|r|的表达式得到:
[0029][0030]
其中,x
μve
和x
μvb
分别是el和bl中的残差系数,为4x4残块的绝对差之和,则16x16残块的绝对差之和为:
[0031][0032]
步骤5:将sad替换成rd,得到ilr模式提前终止的表达式为:
[0033][0034]
其中,ilr
cost
表示当前编码单元增强层率失真值,rdb表示当前编码单元基本层的率失真值;
[0035]
步骤6:根据ilr模式提前终止的表达式判断当前编码单元是否进行ilr层间早期终止,并得到当前编码单元为ilr模式中不同模式的最佳k2。
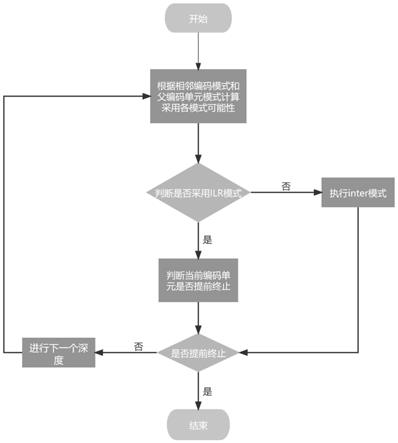
[0036]
进一步的,inter模式提起终止条件的确定过程包括:
[0037]
步骤1:获取当前编码单元中增强层以及相邻cu和基本层以及相邻cu的量化系数z1、z2和z3、z4;根据当前编码单元中增强层的量化系数确定inter模式下的最小系数值k3;
[0038]
步骤2:根据确定的最小系数值k3得到:
[0039]
|r
1-r2|≤q
estep
|r
3-r4|/q
bstep
+k3q
estep
[0040]
其中,r1、r2、r3、r4分别为z1、z2、z3、z4的dct变换系数;
[0041]
步骤3:根据|r|的表达式和步骤2中的表达式可得:
[0042][0043]
其中,x
μve
和x
μvb
分别是el和bl中的残差系数,为4x4残块的绝对差之和,则16x16残块的绝对差之和为:
[0044]
sad
1-sad2≤q
estep
(sad
3-sad4)/q
bstep
+16k3q
estep
[0045]
其中,sad1表示16x16宏块的增强层当前编码单元绝对差值之和,sad2表示16x16宏块的增强层相邻编码单元绝对差值之和,sad3表示16x16宏块的基本层当前编码单元绝对差值之和,sad4表示16x16宏块的基本层相邻编码单元绝对差值之和;
[0046]
步骤5:将sad换成率失真值,得到inter模式提起终止条件表达式:
[0047]
rd
1-rd2≤q
estep
(rd
3-rd4)/q
bstep
+16k3q
estep
[0048]
其中,rd1表示增强层当前编码单元的率失真值,rd2表示增强层相邻编码单元的率失真值,rd3表示基本层当前编码单元的率失真值,rd4表示基本层相邻编码单元的率失真值;
[0049]
步骤6:根据inter模式提前终止的表达式判断当前编码单元是否进行ilr层间早期终止,并得到当前编码单元为ilr模式中不同模式的最佳k3;
[0050]
2nx2n模式,nx2n或者2nxn模式同理,找出每个部分k3的最佳值。
[0051]
优选的,判断当前编码单元是否需要进一步划分的过程包括:
[0052]
步骤1:设置初始编码单元终止划分和进一步划分的率失真期望向量和协方差矩阵分别为μ1,∑1和μ2,∑2;获取当前编码单元对应的高斯混合模型;
[0053]
步骤2:计算高斯混合模型的似然函数;
[0054]
步骤3:对似然函数进行求导;
[0055]
步骤4:在对求导后的似然函数分别对πk,μk,∑k求导,并对令各个求导后的函数等于0,得到μk和∑k的表达式;μk和∑k的表达式为:
[0056][0057][0058][0059][0060]
其中,μk表示率失真期望向量(其中k=1表示终止划分的率失真期望向量,k=2时表示进一步划分的率失真期望向量),nk表示第k类的样本总量(k=1表示终止划分的样本总量,k=2表示进一步划分样本的总量),γ(i,k)表示对于每个数据来说,它是由第k个部分生成的概率,∑k表示协方差矩阵(k=1表示终止划分的协方差矩阵,k=2表示进一步划分的协方差矩阵),xi表示率失真值,n表示要测试的全部编码单元的总量;
[0061]
步骤5:根据μk和∑k的表达式得到
[0062]
步骤6:根据设置的初始编码单元终止划分和进一步划分的率失真期望向量和协方差矩阵对公式μk、πk以及γ(i,k)进行迭代处理,直到该似然函数收敛为止;
[0063]
步骤7:当似然函数收敛时获取当前编码单元终止划分和进一步划分的可能性;当终止划分的可能性大于设置的划分阈值时,结束整个过程,当终止划分的可能性小于设置的最小阈值时,则继续划分,直到编码单元编完为止。
[0064]
进一步的,设置初始编码单元终止划分和进一步划分的率失真期望向量和协方差
矩阵的公式为:
[0065][0066]
其中,pix(i)为第i个终止划分编码单元的像素值,m为终止划分的编码单元的个数,average为期望也就是平均值,varience为方差。
[0067]
进一步的,似然函数的表达式为:
[0068][0069]
其中,n表示需要测试的样本总量,p(xi|π,μ,∑)表示高斯混合模型的表示形式,xi表示率失真值(终止划分的可能性或者进一步划分的率失真值),π表示可能性(终止划分的可能性或者进一步划分的可能性),μ表示率失真期望向量,∑表示协方差矩阵,n(xi|μ1,∑1)表示终止细分或进一步细分的似然函数。
[0070]
本发明的有益效果:
[0071]
本发明通过将当前编码单元的相邻编码单元和父编码单元进行关联,并采贝叶斯公式计算当前编码单元采用各种模式的可能性概率,预测了当前编码单元可能采用的编码模式;在当前编码模式下通过计算当前编码单元是否提前终止划分的条件来判断该单元是否终止划分,提高了划分的时间和效率。
附图说明
[0072]
图1为现有的shvc标准编码框架;
[0073]
图2为本发明的基于shvc质量可伸缩帧间视频编码方法的流程图;
[0074]
图3为本发明的增强层和基本层编码单元示意图;
[0075]
图4为本发明的当前编码单元和父编码单元示意图;
[0076]
图5为本发明的终止细分和进一步细分的率失真分布图。
具体实施方式
[0077]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0078]
一种基于shvc质量可伸缩帧间视频编码方法,如图2所示,该方法包括:
[0079]
s1:获取当前编码单元的深度,并获取当前编码单元的相邻编码单元和父编码单元的的模式信息;
[0080]
s2:根据当前编码单元的相邻编码单元和父编码单元的模式信息采用贝叶斯公式计算当前编码单元采用各个模式的概率;编码单元采用的模式包括ilr模式和inter模式;
[0081]
s3:根据不同模式的概率确定当前编码单元的编码模式;
[0082]
s4:判断当前编码单元是否提前终止划分,若提前终止划分,则得到划分结果,若
不提前终止划分,则进入下一个深度,并返回步骤s2。
[0083]
shvc质量可伸缩帧间编码算法研究是利用层间相关性以及空间相关性来进行预测的,其主体流程包括以下几个步骤:
[0084]
步骤1:因为当前编码单元和相邻编码单元存在很强的相关性,这就使得他们的模式具有高度的相关性,并且如果当前编码单元对应的父编码单元采用一种模式,那么当前编码单元采用同一种模式的可能性很大,同时考虑到相关性程度的问题,因为虽然当前编码单元和其父编码单元以及相邻编码单元有很强的的相关性,但还是有可能不会参考这两个标准的,如果再加上相关性程度,那么对于预测模式会更加准确。
[0085]
首先帧间编码分为ilr模式和inter模式,本技术中研究占据比例比较多的为ilr模式,在inter模式中包括merge模式,2nx2n,nx2n,2nxn模式,利用相邻编吗单元以及父编码单元的模式根据贝叶斯公式得出当前编码单元采用以上几种模式的可能性。如图3和图4所示,增强层(el)、基本层(bl)以及当前编码单元和其父编码单元。其中c为当前编码单元(cu),l,ul,u,ur分别为el层相邻cu,bc为当前cu统一位置的bl层的cu,bl,bul,bu,bur分别为bc位置的相邻cu。u0表示当前深度的cu,u1、u2、u3表示当前深度cu的相邻cu,而u0、u1、u2、u3四个cu一起组成了当前深度的父cu(也就是上一个深度的cu)。
[0086]
获取到上述所说的cu的模式信息,之后利用贝叶斯公式计算当前编码cu采取各模式的可能性。采用贝叶斯公式计算当前编码单元采用各个模式的概率的公式为:
[0087][0088]
其中,fd(cd)表示当前编码单元采用cd模式的可能性,cd表示当前编码单元的模式,cd可能的值为0(ilr模式),1(merge模式),2(2nx2n模式),3(2nxn或者nx2n模式);p((nd,nr)|cd)表示给定当前cu使用模式cd的条件概率下相邻cu使用向量(nd,nr)的概率,nd表示相邻cu使用的模式,nr表示当前cu和相邻cu的相关性程度,p(pr|cd)表示当前cu使用模式cd的条件概率下父cu使用使用pr模式的概率,pr表示父cu使用的模式,p(cd)表示当前cu使用模式cd的概率,p(nd,nr)表示相关性程度为nr并且当前编码单元的相邻cu采用nd模式的概率,p(pr)表示父cu采用模式pr的概率。
[0089]
由于除qp外,bl中的cu和el中同等位置的cu都是相同的,所以可以将el中cus的相关性程度设置为与bl中同处的cus的相关程度相同。显然,相邻cus在深度上的绝对差异越小,其空间相关性越强;反之亦然。也就是说,相邻cus在bl深度的绝对差异与相关程度成反比。设nbd为bl中cu bc的相邻cus的模式。由于相邻cus在模式上的最大绝对差为4,将要预测的模式分为四类,ilr记为模式0,merge记为模式1,2nx2n记为模式2,nx2n或者2nxn记为模式3,其他模式记为模式4,因此关联度向量的第i(0≤i≤3)分量nri可表示如下:
[0090]
nri=4-|nd
i-nbdi|
ꢀꢀ
(2)
[0091]
其中ndi和nbdi分别为深度级向量nd和nbd的第i个分量(0≤i≤3),nri表示第i个相邻编码单元和当前编码单元的模式关联度。
[0092]
由于当前cu有4个相邻的cu,所以每个向量有4个分量,每个分量取5个值,分别为
0、1、2、3、4。如果直接使用式(1)进行计算,过程会非常复杂。为了克服这个问题,可以使用朴素贝叶斯分类器,它可以做一个条件独立的假设。换句话说,我们假设每个cu的关联深度和程度是相互独立的。也就是说,一个向量的不同分量是独立的。根据这个独立性假设,式(1)可计算为:
[0093][0094]
将编码单元c、fc、l、u、ul、ur中的p(nd,nr)设置为其平均值,使得不同模式的概率分布与它们的位置无关;即不同的分量应该有相同的模式概率分布。根据上述实验条件,得到向量(nd,nr)和(nd,nr|cd)中第i(0≤i≤3)分量的模式概率分布,分别表示为p(ndi,nri)和p((ndi,nri)|cd),对cu来说,每个深度不同,所得到的模式概率也是不同的,所以将以上概率分不同深度分别列于下表中。
[0095]
表1深度为0时p(ndi,nri)表示的概率分布
[0096][0097]
表2深度为1时p(nd
i,
nri)表示的概率分布
[0098][0099]
表3深度为2时p(ndi,nri)表示的概率分布
[0100][0101][0102]
表4深度为3时p(nd
i,
nri)表示的概率分布
[0103][0104]
表5深度为0时p((ndi,nri)|cd)表示的概率分布
[0105][0106]
表6深度为1时p(pr|cd)表示的概率分布
[0107][0108][0109]
表7深度为2时p(pr|cd)表示的概率分布
[0110]
[0111]
表8深度为3时p(pr|cd)表示的概率分布
[0112][0113]
在相同条件下,得到每个深度中p(cd)的概率分布如下表所示:
[0114]
表9各深度为p(cd)表示的概率分布
[0115]
cd01234depth02.715%52.764%5.514%28.283%10.724%depth10.627%66.320%5.029%13.703%14.321%depth20.704%81.697%4.123%6.503%6.973%depth31.295%93.414%2.662%2.571%0.059%
[0116]
表10深度1,2,3为p(pr)表示的概率分布
[0117]
pr01234depth11.583%59.482%5.467%21.156%12.311%depth20.652%74.031%4.668%10.128%10.520%depth31.293%1.293%3.376%4.418%3.371%
[0118]
使用模式为cd的当前cu的条件概率fd(cd)可根据公式(3)得到。由于计算可能会涉及到一些舍入误差,因此五个模式概率不一定总是等于1,各个模式的概率的公式可改写为:
[0119][0120]
其中,fd(0)表示当前编码单元模式为0的概率,fd(1)表示当前编码单元采用模式为1的概率,fd(2)表示当前编码单元采用模式为2的概率,fd(3)表示当前编码单元采用模式为3的概率,fd(4)表示当前编码单元采用模式为4的概率。
[0121]
步骤2:结合步骤1得到当前cu采用ilr模式的可能性,因为采用ilr模式的可能性是0-100%,将这个范围分为五部分,分别是0-20%,20%-40%,40%-60%,60%-80%,80%-100%。
[0122]
根据量化后的dct系数的层间相关性,提出了层间早期终止,停止对其他模式的检查。因为在增强层(el)和基本层(bl)相同位置的编码单元,除了qp(量化参数)不同之外,其他都是相同的,所以如果两层之间相同位置编码单元的量化系数之差很小,那么两层之间相同位置的编码单元采用相同的模式。根据以上分析得出:
[0123]ze-zb≤k2ꢀꢀ
(5)
[0124]
其中ze和zb分别为增强层和基本层的量化系数,k2为实验得到的最小系数值。根据
100%时的最佳k2值。
[0141]
步骤3:如果满足步骤2中的条件则进行层间早期终止,如果不终止,则进行检查inter模式。同理首先通过步骤1先得到得到各inter模式的可能性,然后进行merge模式,然后进行2nx2n模式,接着是nx2n或者2nxn这些模式的检查,如果不是以上模式,则定义当前编码单元的模式为其他模式。
[0142]
根据量化dct系数中的空间相关性,提出空间早期终止,来停止对当前编码单元的其他模式的检查。如果一个编码单元和他相邻的编码单元在基本层中是相同的,那么在增强层中相同位置的两个模式也可能是一样的。但是基本层和增强层的qp不同,同时增强层中两个编码单元的模式并不总是相同的。如果在基本层中当前编码单元和其中的相邻编码单元这两个编码单元采用相同的模式,并且他们的量化系数大于增强层中相同位置的两个编码单元的量化系数差,说明qp对模式选择的影响可以忽略,因此增强层中的两个编码单元也该采用相同的模式,因此提出空间早期终止,如下所示:
[0143]
|z
1-z2|-|z
3-z4|≤k3ꢀꢀ
(12)
[0144]
式中z1、z2为增强层中相邻的两个编码单元的量化系数,z3、z4为基本层中相邻的两个编码单元的量化系数,k3为小的系数值,是通过实验得到的。推导式(12)为以下式子:
[0145]
|z
1-z2|-|z
3-z4|≤k3ꢀꢀ
(13)
[0146]
其中r1、r2、r3、r4分别为z1、z2、z3、z4的dct变换系数,由式(13)推导出下式为:
[0147]
|r
1-r2|≤q
estep
|r
3-r4|/q
bstep
+k3q
estep
ꢀꢀ
(14)
[0148]
结合(8)式和(14)式推导出式子如下:
[0149][0150]
那么对于16x16残块的sad为:
[0151]
sad
1-sad2≤q
estep
(sad
3-sad4)/q
bstep
+16k3q
estep
ꢀꢀꢀ
(15)
[0152]
其中,sad1表示16x16宏块的增强层当前编码单元绝对差值之和,sad2表示16x16宏块的增强层相邻编码单元绝对差值之和,sad3表示16x16宏块的基本层当前编码单元绝对差值之和,sad4表示16x16宏块的基本层相邻编码单元绝对差值之和。
[0153]
将sad换成率失真值(rd-cost),得到下式:
[0154]
rd
1-rd2≤q
estep
(rd
3-rd4)/q
bstep
+16k3q
estep
ꢀꢀꢀ
(16)
[0155]
其中,rd1表示增强层当前编码单元的率失真值,rd2表示增强层相邻编码单元的率失真值,rd3表示基本层当前编码单元的率失真值,rd4表示基本层相邻编码单元的率失真值。
[0156]
在预测当前编码单元是否为merge模式时,首先将当前编码单元采用merge模式的可能性分为0-20%、20%-40%、40%-60%、60%-80%、80%-100%五个部分,然后根据上式求出每个部分的阈值k3的最佳值;2nx2n模式,nx2n或者2nxn模式同理,找出每个部分k3的最佳值。以此找到当前编码单元的最佳模式,之后进行步骤4。
[0157]
步骤4:当前编码单元每次都要进行从深度0到深度3的编码,每一层都要进行大量的编码,基于此,本文提出基于率失真值的深度提前终止算法。一般来说,率失真较大的编码单元,需要进一步细分的可能性比较大;反之,率失真较小的编码单元,终止细分的可能
性比较大,如图5所示:横坐标是率失真值,纵坐标为对应的概率密度值。左边的高斯分布代表终止划分的编码单元的率失真值,右边代表需要进一步划分的率失真值。因此可以利用率失真值预测当前编码单元是否需要进一步划分,较多的文献,对于终止划分和进一步划分这两种编码深度,他们的率失真值都服从高斯分布,但是期望和方差不同,因此,首先采用高斯混合模型(gmm)来拟合编码单元的率失真分布,然后采用该模型的最大期望聚类(em)来判断当前编码单元是否需要进一步划分,具体如下:
[0158]
设编码单元终止划分和进一步划分的率失真期望向量和协方差矩阵分别为μ1,∑1和μ2,∑2。对于率失真值x,其对应的高斯混合模型如下:
[0159]
p(xi|π,μ,∑)=π1n(xi|μ1,∑1)+π2n(xi|μ2,∑2)
ꢀꢀ
(17)
[0160]
π1和π2分别为停止细分和进一步细分的可能性,为了求出上式中的六个未知参数,使用最大期望聚类(em)进行求解,该高斯混合模型的似然函数如下:
[0161][0162]
其中,n表示需要测试的样本总量,p(xi|π,μ,∑)表示高斯混合模型的表示形式,xi表示率失真值(终止划分的可能性或者进一步划分的率失真值),π表示可能性(终止划分的可能性或者进一步划分的可能性),μ表示率失真期望向量,∑表示协方差矩阵,n(xi|μ1,∑1)表示终止细分或进一步细分的似然函数。
[0163]
对似然函数进行求导得:
[0164][0165]
再分别对πk,μk,∑k求导得:
[0166][0167]
k=1或者2(k这里代表的是将样本分为几个类别),通过(20)可以得到:
[0168][0169]
其中则可以得到:
[0170][0171]
γ(i,k)表示对于每个数据xi来说,它是由第k个部分生成的概率,其值为:
[0172][0173]
重复迭代(21),(22),(23),直到该似然函数的值收敛为止。
[0174]
在整个迭代过程中,对初始值进行赋值如下:
[0175]
对于μ1,∑1我们根据终止划分的编码单元进行求解期望和方差,根据以下公式进行求解:
[0176][0177]
其中pix(i)为第i个终止划分编码单元的像素值,m为终止划分的编码单元的个数,average为期望也就是平均值,varience为方差,同理也可以使用同样的方式求出μ2,∑2。为了确定当前编码单元是否终止细分,需要确定γ(0,k),是否收敛,设γ(0,k)是第i次迭代表示为γi(i,k),如果γ
i-1
(i,k)和γi(i,k)绝对差很小,可终止迭代,选择0.01为阈值,既满足:
[0178]
|γ
i-1
(i,k)-γi(i,k)|≤0.01
ꢀꢀ
(25)
[0179]
如果满足式(25),则可以终止重复迭代。通过以上过程,得到当前cu终止划分和进一步划分的可能性。当终止划分的可能性大于0.9时,结束整个过程,当终止划分的可能性小于0.05时,表示要继续划分,进行下一个深度返回步骤1,直到编码单元编完为止。
[0180]
以上所举实施例,对本发明的目的、技术方案和优点进行了进一步的详细说明,所应理解的是,以上所举实施例仅为本发明的优选实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内对本发明所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1