基于深度强化学习的多无人机节能巡航通信覆盖方法
1.本发明属于空天地一体化领域,涉及多无人机协调控制和无人机辅助通信技术领域,具体涉及基于深度强化学习的多无人机节能巡航通信覆盖方法。
背景技术:
2.无人机由于其部署迅速、操作方便、成本较低、容量大和覆盖广等特点,被大量用于空天地一体化领域,尤其用于无人机辅助通信等,但由于单无人机所覆盖的区域范围有限,而大量部署无人机则往往造成能源和成本的浪费,为最大程度地为地面节点提供通信条件并节约成本,有必要研究在满足通信情况下的多无人机节能巡航覆盖通信。多无人机节能巡航覆盖通信主要涉及节约无人机能量消耗、巡航覆盖目标区域,多无人机巡航覆盖目标区域所涉及的方面比较多,包括避免多个无人机之间发生碰撞、巡航覆盖完全整个目标区域、公平覆盖目标区域等,从而实现多无人机节能巡航覆盖通信。多无人机巡航覆盖通信的方法有多种,有的将目标区域进行栅格化,再将栅格化后的目标区域划分为多个子任务区域,多个无人机巡航覆盖多个子任务区域的形式实现多无人机巡航覆盖通信;而有的则采用强化学习或深度强化学习算法智能地实现多无人机巡航覆盖通信。
3.目前已有关于基于深度强化学习的多无人机辅助通信的研究,但对于地面用户分布复杂情况下基于深度强化学习的多无人机辅助通信的相关研究还比较缺乏。此外,现有技术中,一些研究分析了满足通信下基于普通单元格划分的多无人机巡航覆盖,但还缺乏满足通信条件下对单元格设置一定奖励值的多无人机巡航覆盖。因此,设计一种基于深度强化学习的多无人机节能巡航通信覆盖方法对灾后辅助救援以及偏远地区的无线通信有重要意义。
技术实现要素:
4.为了解决上述问题,本发明提供一种基于深度强化学习的多无人机节能巡航通信覆盖方法,该方法采用多个无人机以“飞行-通信”和“悬停-通信”两种协议实现用户分布复杂情况下目标区域的巡航覆盖,从而辅助灾区通信;在无人机公平覆盖完全目标区域的同时优化无人机能耗。
5.基于深度强化学习的多无人机节能巡航通信覆盖方法,包括以下步骤:
6.s1、针对灾难发生后用户的分布特点,建立无人机基站与地面用户之间的通信,在满足通信条件下将用户分布不均的目标区域进行栅格化;
7.s2、确定目标区域中的重点单元格与普通单元格,分别设置重点单元格与普通单元格的所对应的权值;
8.s3、设置环境中所需要的相关变量和评估指标,并采用基于深度强化学习的方法对多无人机进行集中式训练、分布式执行;
9.s4、计算在整个系统中目标区域的平均覆盖指数、目标区域的公平覆盖指数以及多无人机巡航覆盖目标区域的能量效率。
10.在一种优选实施方式中,针对灾难发生后地面用户存在分布不均的特点,为保证灾区快速恢复通信,同时节约无人机的能耗,采用多无人机以巡航覆盖的方式辅助灾区通信。而灾难发生后多无人机以巡航覆盖的方式辅助灾区恢复通信是np问题,因此对灾后目标区域进行栅格划分,取每个单元格的中心点作为无人机需要覆盖的任务目标点;无人机需要巡航覆盖所有中心点才可实现对灾后目标区域的全覆盖并实现恢复通信。
11.在一种优选实施方式中,根据灾后用户分布的特点,对于存在避难所等用户聚集地所需要的通信要求较高,而对于用户较少的稀疏区域所需要的通信要求较低。因此将存在避难所的重点单元格表示为u,u∈u,其权重设置为特殊权值wu,而对于用户稀疏区域的普通单元格表示为v,v∈v,权重设置为wv,则目标区域所划分的总单元格数目为k=u+v,且k=u,v;当无人机覆盖到重点单元格时,无人机以悬停-通信协议对重点单元格覆盖一段时间而对于普通单元格,则以飞行-通信协议辅助通信。
12.在一种优选实施方式中,根据灾后目标区域设置环境参数,将目标区域设置为长为l,宽为w的矩形区域;将矩形目标区域划分为10*10的单元格,设置多个无人机以巡航覆盖的方式辅助通信;并且设置平均覆盖指数、公平覆盖指数和无人机能量效率来判断目标区域中的单元格被覆盖的情况。
13.在一种优选实施方式中,采用基于深度强化学习的方法对多个无人机进行集中式训练、分布式执行以实现目标,其中深度强行学习方法主要是基于maddpg算法。每个无人机均由actor-critic框架训练;actor网络获取无人机状态s,进行动作选择(空间探索);critic网络根据动作a和状态s进行评价,采用策略梯度更新actor和critic两个网络的权重。主要使用dnn作为函数逼近器,通过最小化损失函数更新actor网络,则损失函数l的表达式为:
[0014][0015]
其中,表示critic网络参数,j,j
→
∞表示迭代次数,表示由target critic网络生成的目标值,sj表示无人机的状态,表示无人机的行为,则目标值的表达式为:
[0016][0017]
其中,表示无人机获取的奖励值;每个无人机的actor网络的权重参数由策略梯度进行更新,则梯度更新的表达式为:
[0018][0019]
而两个目标网络的权重均由对应的actor和critic网络以θi′←
τθi+(1-τ)θi′
的形式缓慢更新所得。
[0020]
在一种优选实施方式中,目标区域的平均覆盖指数用来衡量一段时间t内,目标区域中的单元格被覆盖的频率,目标区域的覆盖指数c
t
的表达式为:
[0021][0022]
其中,t
t
(u)或t
t
(v)表示在当前t时隙单元格u或v被覆盖的次数;值得注意的是重点单元格的持续覆盖默认为一次覆盖,而平均覆盖率只考虑时间上的覆盖。目标区域的公平覆盖指数用来衡量目标区域中的每个单元格是否被公平的覆盖,避免出现不断重复覆盖一个单元格的情况,目标区域的公平覆盖指数f
t
的表达式为:
[0023][0024]
其中当所有单元格中心点均被覆盖时,f
t
=1,最终该任务的公平覆盖指数f
t
=f
t
|
t=t
。多无人机巡航覆盖目标区域的能量效率用来衡量无人机覆盖通信所耗费的能耗以及衡量无人机是否实现节能通信,能量效率δη
t
的表达式为:
[0025][0026]
其中,δc
t
(u)=c
t
(u)-c
t-1
(u),δc
t
(v)=c
t
(v)-c
t-1
(v);对于任意无人机在时隙t飞行所消耗的能耗为飞行所消耗的能耗为所有无人机完成该任务所消耗的总能耗为为加强无人机的探索策略,给目标区域的单元格中心点设置奖励值g,当无人机覆盖该单元格时,无人机的奖励值加g,而单元格的奖励值则减少g。
[0027]
在一种优选实施方式中,当无人机失去通信连接、飞出目标区域或无人机发生碰撞时会受到惩罚,即无人机的奖励减而当无人机正常巡航到单元格中心点时,无人机的奖励加则无人机的奖励的表达式为:
[0028][0029]
每个无人机的训练目标是使折扣后的未来奖励最大化,则无人机的总奖励值r的表达式为:
[0030][0031]
其中,γ表示损失因子,0≤γ≤1,r表示该段时间t内无人机所获得的总奖励值。
[0032]
有益效果:
[0033]
1.本发明针对地面用户分布复杂的情形,提出以多无人机巡航方式辅助通信的方法,该方法相比于单无人机辅助通信的方法,既延长了网络服务时长,又增加了网络部署的灵活性。
[0034]
2.本发明中多无人机将“飞行-通信”和“悬停-通信”两种协议结合应用,既避免了用户稀疏区域的能量浪费,又保证了用户聚集区域处的服务质量。
[0035]
3.本发明中无人机以深度强化学习的方法巡航用户分布复杂的矩形目标区域,该方式既避免了多个无人机之间发生碰撞,又自适应地探索目标区域,增强了方法的适用性。
[0036]
4.本发明为每个目标单元格设置一定奖励,增加了深度强化学习算法的探索性,提高了无人机巡航覆盖的效率。
[0037]
5.本发明分析了多无人机对地面用户分布复杂情况下的巡航覆盖辅助通信方法,该方法对地面用户的复杂情形提供了一种无人机协同控制以辅助通信覆盖的参考方法。
附图说明
[0038]
下面结合附图和具体实施方式对本发明做进一步详细的说明。
[0039]
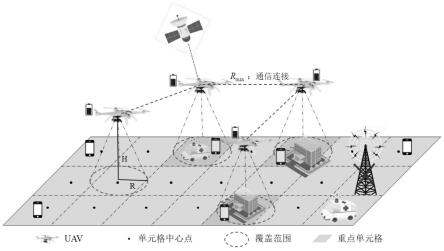
图1为本实施例提供的一种多无人机覆盖通信模型;
[0040]
图2为本实施例提供的目标区域栅格格划分图;
[0041]
图3为本实施例提供的多无人机与环境交互图;
[0042]
图4为本实施例提供的基于深度强化学习的多无人机原理图。
具体实施方式
[0043]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0044]
本实施例基于一种多无人机巡航通信系统实现,如图1所示,该系统所规划的通信巡航区域为一片10*10的单元格区域,每个单元格的尺寸为100*100(m);多架旋翼无人机作为空中基站辅助通信,无人机的飞行高度固定为h,无人机对地面的覆盖半径为r,无人机之间存在通信连接范围为r
max
;该目标区域中存在多个避难所,包含避难所的区域为重点聚集区域,除包含避难所以外的其余区域为用户分布稀疏的普通区域。
[0045]
本实施例提供基于深度强化学习的多无人机节能巡航通信覆盖方法,多无人机以飞行-通信和悬停-通信两种协议为矩形区域中的地面所有用户提供通信条件,矩形区域的长为l、宽为w。该方法包括但不限于如下步骤:
[0046]
s1、建立无人机与地面用户之间的通信,并将目标区域进行栅格划分;
[0047]
假设满足边界用户通信的最小吞吐量为q,当位于无人机覆盖半径r的边界用户的通信数据量大于用户所需的最小吞吐量q时,则认为地面用户能实现正常通信。由于灾难发生后用户分布不均的特点,且灾难发生后多无人机以巡航覆盖的方式辅助灾区恢复通信是np问题;因此在满足通信条件下将用户分布不均的目标区域进行栅格划分,取每个单元格的中心点作为无人机需要覆盖的任务目标点,多个无人机需要巡航覆盖所有任务目标点才可实现对灾后目标区域的全覆盖并实现恢复通信,如图1所示。
[0048]
s2、针对灾难发生后地面用户分布复杂的情形,分别设置重点单元格和普通单元格的权值,如图2所示。
[0049]
灾难发生后用户的分布往往存在特殊性,大部分用户聚集分布在学校、避难所等重点区域,而少部分用户稀疏分布在灾难发生地等普通区域;存在避难所等用户聚集地所需要的通信要求较高,而用户较少的稀疏区域所需要的通信要求较低。为保证灾区快速恢
复通信,同时节约无人机的能耗;因此对存在避难所的重点单元格设置特殊权值wu,如图2所示为阴影颜色较深的单元格,而对于用户稀疏区域的普通单元格则设置权值wv,如图2所示为阴影颜色较浅的单元格;无人机以不同的覆盖方式辅助用户通信以节约无人机能耗。
[0050]
在一种优选实施方式中,当无人机飞行覆盖到重点单元格时,无人机以悬停-通信的协议对重点单元格覆盖一段时间而对于普通单元格,则以飞行-通信协议辅助通信。
[0051]
在一种优选实施方式中,为每个单元格中心点设置一个奖励值g,当无人机巡航到单元格中心点时,则获取该奖励值,而单元格的奖励值则减少g。
[0052]
s3、将多无人机覆盖目标区域任务建模为一个随机博弈,以便采用深度强化学习技术对其求解。如图3所示,该过程可描述为多智能体在环境中学习的过程;多无人机尝试做出动作,环境根据所采取的动作进行状态的改变,并评价该动作是否明智,然后将评价函数q反馈给无人机。该任务采用深度强化学习方法对多个无人机进行集中式训练、分布式执行以实现目标,其中深度强行学习方法主要是基于maddpg算法,如图4所示。每个无人机均由actor-critic框架训练;actor网络获取无人机状态s,进行动作选择(空间探索);critic网络根据动作a和状态s进行评价,采用策略梯度更新actor和critic两个网络的权重。主要使用dnn作为函数逼近器,通过最小化损失函数更新actor网络,则损失函数l的表达式为:
[0053][0054]
其中,表示critic网络参数,j,j
→
∞表示迭代次数,表示由target critic网络生成的目标值,sj表示无人机的状态,表示无人机的行为,则目标值的表达式为:
[0055][0056]
其中,表示无人机获取的奖励值;每个无人机的actor网络的权重参数由策略梯度进行更新,则梯度更新的表达式为:
[0057][0058]
两个目标网络的权重均有对应的actor和critic网络以θi′←
τθi+(1-τ)θi′
的形式缓慢更新所得。
[0059]
具体基于深度强化学习的多无人机节能巡航通信覆盖方法中所提及的算法过程如表1所示:
[0060][0061][0062]
s4、设置平均覆盖指数、公平覆盖指数和无人机能量效率来判断目标区域中多无人机巡航辅助通信的优劣。目标区域的平均覆盖指数用来衡量一段时间t内,目标区域中的单元格被覆盖的频率,则目标区域的平均覆盖指数c
t
的表达式为:
[0063][0064]
其中,其中t
t
(u)或t
t
(v)表示在当前t时隙单元格u或v被覆盖的次数;目标区域的公平覆盖指数用来衡量目标区域中的每个单元格是否被公平的覆盖,避免出现不断重复覆盖一个单元格的情况,则目标区域的公平覆盖指数f
t
的表达式为:
[0065][0066]
其中当所有单元格中心点均被覆盖时,f
t
=1,最终该任务的公平覆盖指数f
t
=f
t
|
t=t
。多无人机巡航覆盖目标区域的能量效率用来衡量无人机覆盖通信所耗费的能耗以及衡量无人机是否实现节能通信,能量效率δη
t
的表达式为:
[0067][0068]
其中,δc
t
(u)=c
t
(u)-c
t-1
(u),δc
t
(v)=c
t
(v)-c
t-1
(v);对于任意无人机在时隙t飞行所消耗的能耗为飞行所消耗的能耗为所有无人机完成该任务所消耗的总能耗为为加强无人机的探索策略,给目标区域的单元格中心点设置奖励值g,当无人机覆盖该单元格时,无人机的奖励值加g,而单元格的奖励值则减g。
[0069]
当无人机飞出目标区域、无人机发生碰撞时会受到惩罚,无人机的奖励减而当无人机正常巡航到单元格中心点时,无人机的奖励加则无人机的奖励的表达式为:
[0070][0071]
每个无人机的训练目标是使折扣后的未来奖励最大化,则无人机的总奖励值r的表达式为:
[0072][0073]
其中,γ表示损失因子,0≤γ≤1,r表示该段时间t内无人机所获得的总奖励值。
[0074]
当介绍本技术的各种实施例时,词语“包括”、“包含”和“具有”都是包括性的并意味着除了列出的元件之外,还可以有其它元件。
[0075]
需要说明的是,本领域普通技术人员可以理解实现上述方法实施例中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法实施例的流程。其中,所述存储介质可为磁碟、光盘、只读存储记忆体(read-0nly memory,rom)或随机存储记忆体(random access memory,ram)等。
[0076]
以上所述仅是本技术的具体实施方式,应当指出,对于本领域的普通技术人员而
言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1