一种基于深度强化学习的自动化网络安全检测方法
1.本发明涉及网络空间安全领域,尤其涉及一种基于深度强化学习的自动化网络安全检测方法。
背景技术:
2.当前,越来越多的数据和服务通过电子平台交付,促进了网络基础设施快速发展的同时,增加了网络漏洞的风险,保证现代网络系统和基础设施安全成为安全领域面临的一个至关重要的挑战。网络安全检测(penetration testing, pt)作为一种安全演习,采用进攻姿态对计算机系统进行已授权的模拟攻击,这种攻击性安全评估方法发现漏洞的有用性是无可争议的。sarraute等人将网络安全检测划分为信息收集、攻击和网络安全检测、本地信息收集、权限提升、移动、清理足迹等6个主要步骤,每个步骤的详细内容如图1所示。迄今为止, pt主要由训练有素的人类攻击者进行,其成功关键取决于专家的专业知识。
3.pt是一个耗时耗力且复杂的任务,需要专家对目标系统以及可能对其进行的潜在攻击有相关的了解,需要大量的隐性知识,难以形式化,也容易出现人为错误。在任何领域,自动化都是节省时间和资源的最佳解决方案,自动化pt 过程为有效解决该问题提供了思路。目前,已经开发了许多支持自动化pt的框架和工具,如metasploit、nessus和tenable等。然而,现有工具并不能代替人工进行智能决策,无法实现网络安全检测的智能化和全自动化。因此,自动化网络安全检测仍然是一项富有挑战性的工作。
4.随着人工智能在各个领域的发展,安全专家们开始基于ai实现自动化网络安全检测。因此,从进攻和防守的角度提高对使用人工智能的认识至关重要。强化学习(reinforcement learning,rl)是通过对环境的探索和经验的积累来学习的机器学习类型,rl的智能体可以在没有先验数据集的情况下自行适应实时、连续的环境。rl的能力表明它非常适合用于解决pt问题。
5.2013年,sarraute等人采用了部分可观测马尔可夫决策过程(partiallyobservable markov decision processes,pomdp)来形式化pt问题。同时,建立了一种4al分解算法,将一个大的网络按照网络结构分割成较小的网络,并通过pomdp逐个求解。2018年,ghanem和chen提出了一种使用强化学习的智能网络安全检测方法,将系统建模为pomdp,并使用外部pomdp求解器进行测试。基于pomdp的研究结果证实了强化学习可以提高网络安全检测的准确性和可靠性的假设。然而,这些工作大多仅限于规划阶段,而不是实际环境中的整个实施阶段。此外,2014年,durkota等人提出了一种用于计算具有动作成本和故障概率攻击图的最优攻击策略的算法,将攻击图的最优路径规划问题转化为马尔可夫决策过程(markov decision processes,mdp),生成最佳攻击策略以指导网络安全检测。2019年,周等人将网络安全检测描述为mdp,提出了一种基于网络信息增益的攻击规划(nig-ap)算法。2020年,hu等人基于深度强化学习构建了一个自动化网络安全检测框架,自动化找到给定拓扑结构的最佳攻击路径。2021年,zennaro等人将简单ctf题目形式化为网络安全检测问题,基于无模型的强化学习解决此类问题。基于mdp的强化学习可以在没有先验知识的
情况下探索性的进行网络安全检测,然而由于实际网络安全检测的环境的复杂性,这种尝试仅仅停留在规模较小,主机结构较为简单的场景下。
技术实现要素:
6.为解决上述技术问题,本发明提出了一种基于深度强化学习的自动化网络安全检测方法,用以解决现有技术中自动化网络安全检测方法智能化和自动化程度不高、实用性不强的技术问题。
7.根据本发明的第一方面,提供一种基于深度强化学习的自动化网络安全检测方法,所述方法包括以下步骤:
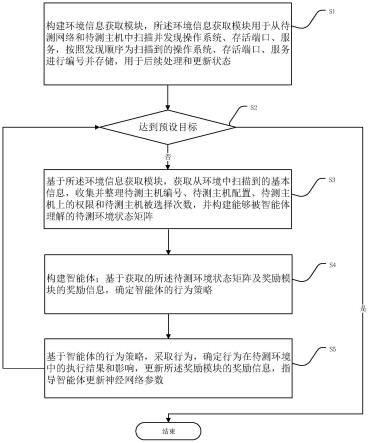
8.步骤s1:构建环境信息获取模块,所述环境信息获取模块用于从待测网络和待测主机中扫描并发现以下基本信息:操作系统、存活端口、服务信息,按照发现顺序为扫描到的操作系统、存活端口、服务信息进行编号并存储,用于后续处理和更新状态;
9.步骤s2:判断是否达到预设目标,若是,方法结束;若否,进入步骤s3;所述预设目标为实现对特定目标的网络安全检测;
10.步骤s3:基于所述环境信息获取模块,获取从环境中扫描到的基本信息,收集并整理待测主机编号、待测主机配置、待测主机上的权限和待测主机被选择次数,并构建能够被智能体理解的待测环境状态矩阵;
11.步骤s4:构建智能体;基于所述待测环境状态矩阵及奖励模块的奖励信息,确定智能体的行为策略;
12.步骤s5:基于智能体的行为策略,采取行为,确定行为在待测环境中的执行结果和影响,更新所述奖励模块的奖励信息,指导智能体更新神经网络参数,进入步骤s2。
13.优选地,所述步骤s2,其中:
14.所述预设目标为实现对特定目标的网络安全检测,包括从某一起始主机出发,对网络环境中某台特定主机的网络安全检测和/或对单个主机的网络安全检测。
15.优选地,所述步骤s3,其中:
16.基于网络安全检测的类型,智能体对待测环境进行扫描:若网络安全检测类型为网络安全检测,则由待测网络的某个待测主机出发,扫描待测网络信息,基于反馈信息确定扫描到的各待测主机的潜在漏洞;基于所述各待测主机的潜在漏洞,确定对各待测主机的探测机制;若网络安全检测类型为单主机网络安全检测,则将所述单主机作为当前待测主机,确定所述当前待测主机的潜在漏洞,为探测机制配置权限,选用与所述当前待测主机的潜在漏洞相对应的行为对所述当前待测主机进行探测。
17.优选地,状态信息结构确定待测环境状态矩阵,作为智能体的输入,包含了智能体对环境的理解;
18.待测环境状态矩阵表示如下:
19.[hi|p0(hi) ... pm(hi)|privilege(hi)|times(hi)]
[0020]
其中,hi表示当前待测主机编号,m为所述待测主机的所有配置信息数, privilege(hi)表示智能体在当前待测主机上的权限,p
num
(hi)表示待测主机hi上拥有的配置信息,times(hi)表示该待测主机hi被选择次数。
[0021]
优选地,所述步骤s5,所述基于智能体的行为策略,更新所述奖励模块的奖励信
息,包括:
[0022]
若智能体成功完成行为,则获得的奖励,所述奖励设计为定值20;
[0023]
若智能体得到特定权限,则获得的奖励,所述奖励设计为定值50;
[0024]
若智能体选择错误行为,则得到惩罚,所述惩罚设计为定值50;所述错误行为包括但不限于无法执行的行为、重复的行为;
[0025]
若智能体行为失败,得到的惩罚,所述惩罚设计为定值20。
[0026]
根据本发明第二方面,提供一种基于深度强化学习的自动化网络安全检测装置,所述装置包括:
[0027]
环境信息模块:配置为构建环境信息获取模块,所述环境信息获取模块用于从待测网络和待测主机中扫描并发现以下基本信息:操作系统、存活端口、服务信息,按照发现顺序为扫描到的操作系统、存活端口、服务信息进行编号并存储,用于后续处理和更新状态;
[0028]
判断模块:配置为判断是否达到预设目标,所述预设目标为实现对特定目标的网络安全检测;
[0029]
待测环境状态矩阵构建模块:配置为基于所述环境信息获取模块,获取从环境中扫描到的基本信息,收集并整理待测主机编号、待测主机配置、待测主机上的权限和待测主机被选择次数,并构建能够被智能体理解的待测环境状态矩阵;
[0030]
智能体构建模块:配置为构建智能体;基于所述待测环境状态矩阵及奖励模块的奖励信息,确定智能体的行为策略;
[0031]
奖惩模块:配置为基于智能体的行为策略,采取行为,确定行为在待测环境中的执行结果和影响,更新所述奖励模块的奖励信息,指导智能体更新神经网络参数,触发判断模块。
[0032]
根据本发明第三方面,提供一种基于深度强化学习的自动化网络安全检测系统,包括:
[0033]
处理器,用于执行多条指令;
[0034]
存储器,用于存储多条指令;
[0035]
其中,所述多条指令,用于由所述存储器存储,并由所述处理器加载并执行如前所述的方法。
[0036]
根据本发明第四方面,提供一种计算机可读存储介质,所述存储介质中存储有多条指令;所述多条指令,用于由处理器加载并执行如前所述的方法。
[0037]
根据本发明的上述方案,该方法构建一个更符合真实网络安全检测过程的自动化模型,解决已有自动化网络安全检测方法中存在的智能化和自动化程度不高、实用性不强的问题。本发明所述方法采用深度强化学习技术,将实际网络安全检测过程抽象并建模为马尔可夫决策过程解决了上述问题,实现如下效果:(1)本发明提出了一种基于深度强化学习构建自动化网络安全检测模型的新思路,形式化真实网络安全检测过程,增强了网络安全检测过程的规范性和可理解性,便于专业和非专业安全人员清晰了解并实现网络安全检测,有效节省人力成本;(2)利用所述方法可以实现网络和主机状态的自动探索网络安全检测,并生成到达目标主机的攻击路径,有助于后期弥补漏洞,增强网络和主机的安全性;(3)利用所述方法学习生成的自动化网络安全检测模型可以适用于相似简单的网络环境中,而
无需重复训练智能体,具有高度的灵活性和迁移性。
[0038]
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
附图说明
[0039]
构成本发明的一部分的附图用来提供对本发明的进一步理解,本发明提供如下附图进行说明。在附图中:
[0040]
图1为现有技术中网络安全检测的主要步骤;
[0041]
图2为本发明一个实施方式的基于深度强化学习的自动化网络安全检测方法流程图;
[0042]
图3为本发明一个实施方式的马尔科夫决策过程示意图;
[0043]
图4为本发明一个实施方式的自动化网络安全检测模型结构示意图;
[0044]
图5为本发明一个实施方式的自动化网络安全检测模型示意图;
[0045]
图6为本发明一个实施方式的智能体神经网络结构示意图;
[0046]
图7为本发明一个实施方式的基于深度强化学习的自动化网络安全检测装置结构框图。
具体实施方式
[0047]
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明具体实施例及相应的附图对本发明技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0048]
首先结合图2说明为本发明一个实施方式的基于深度强化学习的自动化网络安全检测方法流程图。如图2、图4、图5所示,所述方法包括以下步骤:
[0049]
步骤s1:构建环境信息获取模块,所述环境信息获取模块用于从待测网络和待测主机中扫描并发现以下基本信息:操作系统、存活端口、服务信息,按照发现顺序为扫描到的操作系统、存活端口、服务信息进行编号并存储,用于后续处理和更新状态;
[0050]
步骤s2:判断是否达到预设目标,若是,方法结束;若否,进入步骤s3;所述预设目标为实现对特定目标的网络安全检测;
[0051]
步骤s3:基于所述环境信息获取模块,获取从环境中扫描到的基本信息,收集并整理待测主机编号、待测主机配置、待测主机上的权限和待测主机被选择次数,并构建能够被智能体理解的待测环境状态矩阵;
[0052]
步骤s4:构建智能体;基于所述待测环境状态矩阵及奖励模块的奖励信息,确定智能体的行为策略;
[0053]
步骤s5:基于智能体的行为策略,采取行为,确定行为在待测环境中的执行结果和影响,更新所述奖励模块的奖励信息,指导智能体更新神经网络参数,进入步骤s2。
[0054]
本发明基于深度强化学习实现网络安全检测过程的自动化和智能化,首先将真实环境中的网络安全检测过程形式化表征为马尔可夫决策过程,然后基于形式化表征构建强化学习的状态,行为和奖励信息,之后根据状态和行为信息的规模构建深度神经网络拟合
智能体的q值,最后构建完整的模型实现自动化网络安全检测。
[0055]
网络安全检测是一个动态交互的过程,包括信息收集、远程攻击、本地攻击、横向移动等模块,需要将网络安全检测形式化为马尔可夫决策过程,才能基于强化学习的相关技术解决该问题。然而真实网络环境中拓扑结构复杂且包含海量的配置信息,难以形式化表征,因此本发明提取现实网络安全检测场景中常见的信息,分析总结常见人工专家操作,并构建仿真环境模拟动态交互过程。
[0056]
网络安全检测对安全专家的知识和技能的要求很高,是一项复杂度高、成本高且需持续进行的任务,解决该任务的有效方法就是自动化该过程。本发明针对自动化和智能化进行网络安全检测的需求,基于深度强化学习构建更符合真实场景的模型。
[0057]
本发明首先需要对网络安全检测过程进行形式化表征,将其表示为马尔可夫决策过程。马尔可夫决策过程由状态,行为,奖励,概率模型四部分组成,交互过程如图3所示,其中s表示状态,a表示行为,r表示奖励,p表示在当前状态下采取该行为到达下一状态的概率。
[0058]
本发明的思想是将网络安全检测过程进行形式化表征,将其表示为马尔可夫决策过程。
[0059]
所述步骤s2,其中:
[0060]
所述预设目标为实现对特定目标的网络安全检测,包括从某一起始主机出发,对网络环境中某台特定主机的网络安全检测和/或对单个主机的网络安全检测。
[0061]
所述步骤s3,其中:
[0062]
状态信息结构确定待测环境状态矩阵,作为智能体的输入,包含了智能体对环境的理解,信息结构中的状态信息应尽可能充分的考虑环境中的各类信息,包括待网络安全检测的网络拓扑结构,网络中主机包含的配置信息等。
[0063]
基于网络安全检测的类型,智能体对待测环境进行扫描:若网络安全检测类型为网络安全检测,则由待测网络的某个待测主机出发,扫描待测网络信息,基于反馈信息确定扫描到的各待测主机的潜在漏洞;基于所述各待测主机的潜在漏洞,确定对各待测主机的探测机制。例如,采用不同的行为策略、不同的优先级对各待测主机进行探测。若网络安全检测类型为单主机网络安全检测,则将所述单主机作为当前待测主机,确定所述当前待测主机的潜在漏洞,为探测机制配置权限,选用与所述当前待测主机的潜在漏洞相对应的行为对所述当前待测主机进行探测。
[0064]
网络安全检测与单主机网络安全检测,均与马尔科夫决策过程的序贯决策过程一致,本发明将网络安全检测过程形式化为序贯决策过程。
[0065]
所述待测环境状态矩阵,也是待测环境网络连通状态矩阵,为一个n
×
n的矩阵,其中n表示网络中的待测主机数量,单个待测主机配置信息表示为一个大小为m的一维矩阵,其中m为所述待测主机的所有配置信息数,privilege(hi)表示智能体在当前待测主机上的权限。此时状态矩阵表示如下:
[0066][0067]
在这种定义方式下,网络连通信息矩阵大小为n(n+m+1),这种定义方式下,网络规模或配置信息的范围变化时,网络连通信息矩阵的规模就会发生变化,因此更换网络环境时可能需要重新训练模型,迁移性和实用性不够强。
[0068]
对网络规模而言,网络从一台到成千上万台不等,难以划定其范围,范围过大容易造成矩阵稀疏,范围过小则会溢出。因此出于实用性考虑,本发明进一步对网络连通信息矩阵进行了更改,改进后的网络连通信息矩阵表示如下:
[0069]
[hi|p0(hi) ... pm(hi)|privilege(hi)|times(hi)]
[0070]
其中,hi表示当前待测主机编号,p
num
(hi)表示待测主机上拥有的配置信息, times(hi)表示该待测主机被选择次数,0≤num≤m。例如,某待测主机配置信息中选择11个操作系统,12个服务,11个服务版本,51个常见端口,选择的常用配置信息如表1所示:
[0071][0072]
表1主机常见配置信息
[0073]
所述步骤s4,其中:
[0074]
智能体基于输出,确定行为,行为即为智能体的输出,表示智能体针对当前环境做出的决策,对于强化学习的智能体而言,它无法做到自己生成新的行为,只能从行为库中根据学习到的经验选择某个行为,因此,要充分考虑专家的行为信息,构建合适的行为库,行为应至少包括扫描,本地、远程漏洞利用和横向移动等。
[0075]
如图6所示,所述智能体为神经网络模型,所述神经网络模型包括三层全连接层;所述神经网络模型的训练过程为:经过全连接层的输出更新所述神经网络模型的参数,直到精度达到预设阈值。在设计状态信息结构和行为模块时,为提高其在真实场景中的实用性,应充分考虑真实场景中的环境信息和可采用的动作信息,因此不可避免的出现状态空间和行为空间巨大的问题。因此本发明采用深度神经网络进行非线性函数逼近,以拟合动作价值函数。
[0076]
本实施例中,初始时,奖励模块的奖励信息为0。基于所述网络连通信息矩阵以及主机配置矩阵,确定智能体的行为策略,包括:
[0077]
对输入智能体的待测环境状态进行分析,观察当前待测主机包含的配置信息,判断可能存在的本地漏洞,以及与当前待测主机连接的主机信息,判断可能存在的远程漏洞和可连接到其他待测主机的凭证信息。
[0078]
因此,对于智能体可选的行为信息,本发明将网络安全检测行为分为三类,分别为实现主机提权的本地漏洞利用操作,实现攻击其他主机的远程漏洞利用操作,以及连接到其他主机的移动操作。针对常用主机配置信息,按照行为分类,列举部分可选动作如表2所示。
[0079][0080]
表2常见行为信息
[0081]
例如:基于自动化网络安全检测模型中对状态和行为的定义,输入状态矩阵大小为80,输出矩阵大小为20。设计神经网络结构如下图所示,网络结构包括三层全连接层,全连接层的规模分别为256,128,64,经过全连接层输出每个行
[0082]
为对应的值作为o值,根据
[0083]
更新参数,训练智能体。
[0084]
本实施例中,网络环境不同时,状态和可采取的行为也不同,这就导致针对当前网络训练的模型难以适用于其他网络,构建的自动化网络安全检测模型适用性不强,因此,本发明在设计状态和行为时尽可能充分的考虑了基本真实网络安全检测场景中的各类因素,以提高模型的可迁移性和适用性。
[0085]
所述步骤s5,其中:
[0086]
奖励是智能体行为的反馈,影响着智能体决策的正确性和收敛速率,奖励由智能体采取正确行为获得的正反馈和采取错误行为获得的负反馈两部分构成。本发明将奖励分为正向反馈和负向反馈两部分。
[0087]
基于智能体的行为策略,更新所述奖励模块的奖励信息,包括:
[0088]
若智能体成功完成行为,则获得的奖励,所述奖励设计为定值20;
[0089]
若智能体得到特定权限,则获得的奖励,所述奖励设计为定值50。特别的是,为了引导智能体对于待测目标主机的网络安全检测能力,为待测目标主机设计定值为100的较大奖励,以鼓励智能体学习有效的策略;
[0090]
若智能体选择错误行为,则得到惩罚,所述惩罚设计为定值50;所述错误行为包括
但不限于无法执行的行为、重复的行为;
[0091]
若智能体行为失败,得到的惩罚,所述惩罚设计为定值20。
[0092]
图7为本发明一个实施方式的基于深度强化学习的自动化网络安全检测装置的结构示意图,如图7所示,所述装置包括:
[0093]
环境信息模块:配置为构建环境信息获取模块,所述环境信息获取模块用于从待测网络和待测主机中扫描并发现以下基本信息:操作系统、存活端口、服务信息,按照发现顺序为扫描到的操作系统、存活端口、服务信息进行编号并存储,用于后续处理和更新状态;
[0094]
判断模块:配置为判断是否达到预设目标,所述预设目标为实现对特定目标的网络安全检测;
[0095]
待测环境状态矩阵构建模块:配置为基于所述环境信息获取模块,获取从环境中扫描到的基本信息,收集并整理待测主机编号、待测主机配置、待测主机上的权限和待测主机被选择次数,并构建能够被智能体理解的待测环境状态矩阵;
[0096]
智能体构建模块:配置为构建智能体;基于所述待测环境状态矩阵及奖励模块的奖励信息,确定智能体的行为策略;
[0097]
奖惩模块:配置为基于智能体的行为策略,采取行为,确定行为在待测环境中的执行结果和影响,更新所述奖励模块的奖励信息,指导智能体更新神经网络参数,触发判断模块。
[0098]
本发明实施例进一步给出一种基于深度强化学习的自动化网络安全检测系统,包括:
[0099]
处理器,用于执行多条指令;
[0100]
存储器,用于存储多条指令;
[0101]
其中,所述多条指令,用于由所述存储器存储,并由所述处理器加载并执行如前所述的方法。
[0102]
本发明实施例进一步给出一种计算机可读存储介质,所述存储介质中存储有多条指令;所述多条指令,用于由处理器加载并执行如前所述的方法。
[0103]
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
[0104]
在本发明所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如,多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
[0105]
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
[0106]
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以
是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。
[0107]
上述以软件功能单元的形式实现的集成的单元,可以存储在一个计算机可读取存储介质中。上述软件功能单元存储在一个存储介质中,包括若干指令用以使得一台计算机装置(可以是个人计算机,实体机服务器,或者网络云服务器等,需安装windows或者windows server操作系统)执行本发明各个实施例所述方法的部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器 (read-only memory,rom)、随机存取存储器(random access memory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
[0108]
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1