一种基于随机森林的横向蠕虫攻击检测方法与流程
1.本发明涉及蠕虫攻击检测技术领域,具体涉及一种基于随机森林的横向蠕虫攻击检测方法。
背景技术:
2.随着计算机网络技术的飞速发展,internet应用深入,对计算机系统安全和网络安全的威胁日益严重。蠕虫是一种智能化、自动化的入侵技术,不需要计算机使用者干预即可运行的攻击程序或代码,它会扫描和攻击网络上存在系统漏洞的节点主机,通过局域网或互联网从一个节点传播到另外一个节点。
3.蠕虫具有传播速度快、覆盖面广、破坏力强等特点,不仅可以占用受感染主机的大部分系统资源,对目标系统造成破坏,同时,还会抢占网络带宽,造成网络严重堵塞,甚至整个网络瘫痪。因此,如何对网络蠕虫进行实时检测以便及时采取措施对其加以防范和遏止,已经称为网络安全研究领域的一个重要课题。
技术实现要素:
4.针对现有技术中的上述不足,本发明提供的一种基于随机森林的横向蠕虫攻击检测方法解决了如何网络蠕虫进行实时检测的问题。
5.为了达到上述发明目的,本发明采用的技术方案为:一种基于随机森林的横向蠕虫攻击检测方法,包括以下步骤:
6.s1、生成随机森林模型;
7.s2、对随机森林模型进行测试;
8.s3、保存训练好的随机森林模型,实时解析网络流量特征然后加载随机森林模型进行结果预测,如果预测结果属于横向蠕虫攻击则告警,若为正常流量则丢弃该条流量数据。
9.进一步地:所述步骤s1的具体步骤为:
10.s11、下载ms-sql slammer蠕虫攻击网络流量数据作为负样本,工控环境中的正常网络流量数据为正样本;
11.s12、对正样本和负样本提取出网络流量数据中的多维特征;
12.s13、在随机森林中使用50颗树进行模型训练,最终分类结果由随机森林中所有决策树统计得票数最多的类别决定。
13.进一步地:所述步骤s12中的多维特征包括流量五元组:源ip、源端口、目的ip、目的端口、协议类型;与当前连接具有相同源ip的连接数、与当前连接具有相同源ip和相同目的端口的连接数、与当前连接具有相同目的端口的连接数、当前连接的源ip作为目的ip的连接数、与当前连接具有相同源ip和相同目的端口的连接数占比与当前连接具体相同源ip的连接数、当前连接的源ip作为目的ip的连接数占比当前连接的源ip作为源ip的连接数。
14.进一步地:所述多维特征选择10s秒内的流量连接特征进行统计。
15.进一步地:所述步骤s13中分类结果包括横向蠕虫攻击流量数据和正常流量数据。
16.进一步地:所述随机森林模型中使用基尼指数作为切分节点的标准。
17.进一步地:所述切分节点的公式为:
[0018][0019]
ai=i(n
l
)-i(nr)
[0020]
上式中,i(n)为基尼指数,n为未分离节点,n
l
为分离后左节点,nr为分离后右节点,wi为c类样本的类权重,ni为节点内各样本数量,δi为不纯度减少量。
[0021]
进一步地:所述步骤s2中测试的指标包括检测率和误报率,计算公式为:
[0022][0023][0024]
当检测率越高,误报率越低时模型效果越好。
[0025]
本发明的有益效果为:本发明通过采集镜像口网络数据,进行协议深度解析与数据预处理,生成格式化数据并传递到消息队列中,加载预先训练好的随机森林分类模型对流量数据进行实时预测,如果预测结果属于蠕虫攻击则告警。可以实时预测工控网络中的横向蠕虫攻击流量信息,并能够根据告警结果提供对应的解决方案。
附图说明
[0026]
图1为本发明工作原理图。
具体实施方式
[0027]
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
[0028]
如图1所示,一种基于随机森林的横向蠕虫攻击检测方法,包括以下步骤:
[0029]
s1、通过模型训练模块生成随机森林模型;
[0030]
(1)训练数据来源:下载ms-sql slammer蠕虫攻击网络流量数据作为负样本,工控环境中的正常网络流量数据为正样本;
[0031]
(2)特征提取:提取出网络流量数据中的多维特征,包括如下几类特征:
[0032]
1)流量五元组:源ip、源端口、目的ip、目的端口、协议类型;
[0033]
2)与当前连接具有相同源ip的连接数、与当前连接具有相同源ip和相同目的端口的连接数、与当前连接具有相同目的端口的连接数、当前连接的源ip作为目的ip的连接数、与当前连接具有相同源ip和相同目的端口的连接数占比与当前连接具体相同源ip的连接数、当前连接的源ip作为目的ip的连接数占比当前连接的源ip作为源ip的连接数。一般地,所述多维流量特征选择10s秒内的流量连接特征进行统计。
[0034]
(3)模型训练:随机森林中使用50颗树训练,最终分类结果由随机森林中所有决策树统计得票数最多的类别决定(分类结果分为两类:横向蠕虫攻击流量数据和正常流量数据);
[0035]
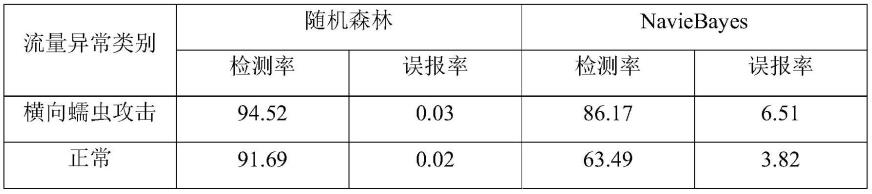
节点切分:随机森林模型中使用基尼指数(gini)作为切分节点的标准,公式为:
[0036][0037]
ai=i(n
l
)-i(nr)
[0038]
上式中,i(n)为基尼指数,n为未分离节点,n
l
为分离后左节点,nr为分离后右节点,wi为c类样本的类权重,ni为节点内各样本数量,δi为不纯度减少量。
[0039]
s2、通过模型验证模块对随机森林模型进行测试;
[0040]
模型验证模块:测试模型时,主要采用以下两个指标来评估:
[0041][0042][0043]
检测率越高误报率越低模型效果越好。
[0044]
s3、通过模型预测模块保存训练好的随机森林模型,实时解析网络流量特征然后加载模型进行结果预测,如果预测结果属于横向蠕虫攻击则告警,若为正常流量则丢弃该条流量数据。
[0045]
本发明通过对捕获的数据包进行实时解析、清洗、特征提取、数据预处理,通过随机森林模型识别横向蠕虫攻击行为,该方法具有如下特点:
[0046]
1)特征提取:该模型能够从流量数据中提取出针对蠕虫攻击的多维度特征;
[0047]
2)特征处理:该模型能够处理高纬度数据,只需要做特征提取不需做特征选择(模型根据特征重要性随机选择),如果有一部分特征遗失仍然可以维持准确度;
[0048]
3)模型训练:该模型训练速度很快,因为随机森林中决策树与决策树之间是相互独立的,容易实现并行化;
[0049]
4)实时告警:可以实时预测流量数据,从网络流量预处理到告警在10s以内完成;
[0050]
5)精确告警:能够精准预测出横向蠕虫攻击类别并给出详细的解决方案。
[0051]
在ms-sql slammer数据集上的试验案例如下:
[0052]
实验数据基于robert beverly提供的ms-sql slammer蠕虫数据集,训练集和测试集比例为7:3
[0053]
训练集:正常数据:707390;蠕虫攻击数据:742448
[0054]
测试集:正常数据:303168;蠕虫攻击数据:318192
[0055]
1)随机森林与naviebayes算法模型对比
[0056][0057]
2)随机森林与svm算法模型对比
[0058][0059]
通过与两种不同算法的对比可以看出随机森林在横向蠕虫攻击的识别中比别的算法检测率高且误报率低,能够作为一种工控网络横向蠕虫识别的方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1