用于客户关系管理的通话准备引擎的制作方法
用于客户关系管理的通话准备引擎
1.相关申请的交叉引用
2.以下美国专利申请的主题与本技术有些相关,特此出于所有目的通过引用将其并入到本技术中,就好像在本文中完全阐述一样:
3.于2017年9月11日递交的、题为“dynamic scripts for tele-agents”的、序列号为15/700,210的美国专利申请;
4.于2017年12月15日递交的、题为“dynamic lead generation”的、序列号为15/844,512的美国专利申请;
5.于2018年10月10日递交的、题为“semantic jargon”的、序列号为16/157,075的美国专利申请;
6.于2018年10月9日递交的、题为“semantic call notes”的、序列号为16/154,718的美国专利申请;
7.于2018年10月31日递交的、题为“semantic inferencing in customer relationship management”的、序列号为16/177,423的美国专利申请;
8.于2018年11月7日递交的、题为“semantic crm mobile communications sessions”的、序列号为16/183,725的美国专利申请;
9.于2018年11月8日递交的、题为“semantic artificial intelligence agent”的、序列号为16/183,736的美国专利申请;
10.于2018年11月21日递交的、题为“semantic crm transcripts from mobile communications sessions”的、序列号为16/198,742的美国专利申请;
11.于2020年8月17日递交的、题为“asynchronous multi-dimensional platform for customer and tele-agent communications”的、序列号为16/947,802的美国专利申请;
12.于2020年1月29日递交的、题为“agnostic augmentation of acustomer relationship management application”的、序列号为16/776,4882的美国专利申请;
13.于2020年4月24日递交的、题为“agnostic customer relationship management with agent hub and browser overlay”的、序列号为16/857,295的美国专利申请;
14.于2020年4月24日递交的、题为“agnostic crm augmentation with a display screen”的、序列号为16/857,321的美国专利申请;
15.于2020年4月24日递交的、题为“agnostic customer relationship management with browser overlay and campaign management portal”的、序列号为16/857,341的美国专利申请;
16.于2020年4月24日递交的、题为“product presentation for customer relationship management”的、序列号为17/248,314的美国专利申请。
背景技术:
17.客户关系管理(“crm”)是一种管理公司与当前和潜在的客户互动的方法。crm通常
对客户与公司的历史实现数据分析,以改善与客户的业务关系,特别是关注客户保留和销售增长。crm系统通常会从一系列通信渠道编译数据,包括电话、电子邮件、实时聊天、短信、营销材料、网站和社交媒体。通过crm方法和用于促进其的系统,企业可以更多地了解他们的目标受众以及如何最好地满足他们的需求。
18.企业crm系统可能非常庞大。这样的系统可以包括数据仓库技术,其用于聚合交易信息,以将信息与关于crm产品和服务的信息合并,并且提供关键表现指标。crm系统有助于管理不稳定的增长和需求,并且实现将销售历史与销售规划相结合的预测模型。crm系统通过多个网络,通过客户点击和销售跟踪客户分析,来跟踪和衡量营销活动。
19.鉴于它们的庞大规模,当今的crm系统往往缺乏充分使用它们可以访问的信息的基础设施。在支持一百个座席的联络中心工作的单个电话坐席(tele-agent)的任务是跨若干个或甚至许多客户端crm系统进行操作,每个客户crm系统有不同的界面。此外,常规的crm系统通常不使用企业可用的信息,进而不将该信息呈现给电话坐席以提高坐席的表现和效率。
附图说明
20.图1阐述了一个网络图,其图示了根据本发明的实施例的用于客户关系管理(“crm”)的通话准备的示例系统。
21.图2阐述了根据本发明的实施例的用于通话准备的示例系统的线绘图。
22.图3阐述了根据本发明的实施例的用于通话准备的系统的系统图。
23.图4阐述了图解的线绘图。
24.图5阐述了根据本发明的实施例的瘦客户端架构中的用于通话准备的示例装置的功能框图。
25.图6阐述了根据本发明的实施例的自动化计算机制的框图,该自动化计算机制包括可用作可用于通话准备的支持语音的设备的声音服务器的计算机的示例。
26.图7阐述了根据本发明的实施例的自动化计算机制的框图,该自动化计算机制包括可用作用于通话准备的三元组服务器的计算机的示例。
27.图8阐述了根据本发明的实施例的厚客户端架构中的用于计算机存储器中的crm的通话准备的示例装置的功能框图。
28.图9阐述了图示根据本发明的实施例的用于客户关系管理(“crm”)的通话准备的示例方法的流程图。
具体实施方式
29.参考附图描述了用于客户关系管理的通话准备的示例方法、系统、装置和产品,附图起始于图1。图1阐述了一个网络图,其图示了根据本发明的实施例的用于客户关系管理(“crm”)的通话准备的示例系统。
30.图1的示例中的客户关系管理(“crm”)的通话准备通过至少一个支持语音的设备(152)、三元组服务器(157)和声音服务器(151)实现。支持语音的设备是被配置为接受和识别来自用户的语音并向用户给出语音提示和语音响应的自动化计算机制。根据本发明的实施例,图1的示例中的支持语音的设备包括台式计算机(107)、智能手表(112)、移动电话
(110)、膝上型计算机(126)和运行通话准备引擎(800)的企业服务器(820)。该示例中的每个支持语音的设备通过网络(100)耦接到三元组服务器(157)和声音服务器(151)以进行数据通信。台式计算机(107)和运行通话准备引擎(802)的企业服务器(820)通过有线连接(120,121)进行连接,而智能手表(112)、移动电话(110)和膝上型计算机(126)分别通过无线连接(114,116,118)进行连接。图1的示例中的连接(有线或有线)中的每个连接都是为了解释而不是为了限制。图1的设备、应用和其他组件可以以本领域技术人员将想到的许多方式耦接以用于数据通信。
31.根据本发明的实施例,图1中所示的整个示例系统通常通过如下操作来进行操作以用于通话准备:调用智能助理(300)以取回潜在客户详细信息(lead details)、客户信息、见解(insight)和其他信息以供在电话座席与客户之间的通话期间使用;管理电话坐席通话准备记录以供在电话坐席与客户之间的通话期间使用;以及显示潜在客户详细信息、客户信息、见解和通话准备记录。
32.如上所述,根据本发明的各种实施例的通话准备是支持语音的。用于识别的语音通常由电话坐席口述,以准备电话坐席与客户之间的通话或该谈话本身的语音。在该示例中,数字化语音的词(509)是来自电话坐席(128)的用于识别的语音或电话坐席(128)与客户之间的谈话。用于识别的语音可以是整个谈话,例如,所有说话的人都在同一房间里,整个谈话由支持语音的设备上的麦克风拾取。通过向支持语音的设备提供来自仅一个人或谈话的一方的人的谈话(例如,仅通过头戴式耳机上的麦克风),可以缩小用于识别的语音的范围。通过仅提供响应于来自例如在支持语音的设备上执行的voicexml对话的提示的语音进行识别,可以进一步缩小用于识别的语音的范围。随着用于识别的语音的范围缩小,整个系统上的数据处理负担总体上减小,尽管至少在一些实施例中,识别整个谈话并跨谈话中的所有词的流进行流式传输仍然是一种选择。
33.通过自然语言处理语音识别(“nlp-sr”)引擎(153)的操作,来自电话坐席或谈话的语音被识别成数字化语音,在此所示的nlp-sr引擎(153)被设置在声音服务器(151)上,但是也可以被安装在支持语音的设备上。nlp-sr引擎还将如此数字化(508)的语音的词(509)解析成描述逻辑的三元组(triple)(752)。
34.三元组是以逻辑形式表达的三部分语句。取决于上下文,使用不同的术语来有效地指代语句在逻辑上相同的三个部分。在一阶逻辑中,这些部分称为常量、一元谓语和二元谓语。在web本体论语言(“owl”)中,这些部分是个体、类和属性。在一些描述逻辑中,这些部分被称为个体、概念和角色。
35.在该示例描述中,三元组的元素被称为主语、谓语和宾语—表达如下:《主语》《谓语》《宾语》。三元组有许多表达模式。三元组的元素可以被表示为统一资源定位符(“url”)、统一资源标识符(“uri”)或国际资源标识符(“iri”)。三元组可以用n-quads、turtle语法、trig、javascript object notation或“json”进行表示,不胜枚举。在此所使用的表达(尖括号中的主语-谓语-宾语)是一种针对人类可读性而不是机器处理进行了优化的抽象语法形式,尽管它的实质内容对于三元组的表达是正确的。使用这种抽象语法,在此是三元组的示例:
36.《bob》《is a》《person》
37.《bob》《is a friend of》《alice》
38.《bob》《is born on》《the 4th of july 1990》
39.《bob》《is interested in》《the mona lisa》
40.《the mona lisa》《was created by》《leonardo da vinci》
41.《the video
‘
la joconde
à
washington’》《is about》《the mona lisa》
42.同一项目可以在多个三元组中被引用。在该实例中,bob是四个三元组的主体,mona lisa是一个三元组的主语和两个三元组的宾语。这种使同一项目成为一个三元组的主语和另一个三元组的宾语的能力使得可以在三元组之间进行连接,并且所连接的三元组形成图形。
43.图1的示例包括语义图数据库(818),其包括企业知识图(816)。语义图是存储器的配置,其使用图结构、节点和边来表示和存储数据。这种配置的关键构思是图(或边或关系),其直接关联数据存储库中的数据项。这样的图数据库与更常规的存储(诸如,逻辑表,其中数据之间的链接仅仅是间接元数据)形成对比,并且使用联接进行查询以在存储库中检索数据从而收集相关数据。语义图通过设计在数据之间建立明确的关系,这在关系系统或逻辑表中可能难以建模。
44.在图1的示例中,语义图数据库(816)包括语义三元组存储库(814)。图1的语义三元组存储库(804)包括供智能助理(300)、crm(806)和通话准备引擎(800)访问的三元组存储库。图1的三元组存储库(814)包含对任何特定知识领域不特殊的词的结构化定义,其中通用语言存储库的每个结构化定义由描述逻辑的三元组实现。三元组存储库(814)还包括在特定知识领域(诸如,产品、行业术语、特定行业、地理区域等)中用于识别的词的结构化定义,其中产品三元组存储库的每个结构化定义都通过描述逻辑的三元组实现。
45.根据本发明的实施例,图1的示例中的语义三元组存储库(814)包括定义在通话准备中使用的各种形式的信息的三元组。这样的三元组可以由通话准备引擎所调用的智能助理查询,以取回见解、被解析成语义三元组的通话准备记录、客户连接、相关用例、聊天、客户的所安装技术、谈话轨迹(talk track)、产品推荐、坐席评分、通话目标、动态脚本、以及本领域技术人员将想到的其它内容。存储在图1的知识图(816)中的信息是为了解释而不是为了限制而呈现的。如本领域技术人员将想到的,根据本发明的实施例,企业知识图可以用于存储在通话准备中有用的其他信息。
46.如上所述,图1的示例包括crm(806)。这样的crm是为电话坐席和企业的其他用户使用而配置的crm系统。通常,存储在crm上且由crm访问的数据是企业本身拥有的且随着时间的推移收集的数据,以供本领域技术人员将想到的组织的各种用户使用。在本发明的其他实施例中,crm可以由通话中心的客户端拥有,并且驻留在crm中的数据由客户端拥有。
47.图1的示例包括通话准备引擎(800)。图1的通话准备引擎是存储在一个或多个非暂态计算机可读介质上的自动化计算机制的模块。图1的通话准备引擎(800)包括通话准备应用(802)和通话准备操纵处应用(call preparation cockpit application)(804)。通话准备应用(802)包括存储在一个或多个非暂态计算机可读介质上的自动化计算机制的一个模块,该模块被配置为调用智能助理(300)以取回潜在客户详细信息、客户信息和见解以供在电话座席与客户之间的通话期间使用,并且管理电话座席通话准备记录以供在电话坐席与客户之间的通话期间使用。
48.通话准备操纵处应用(804)还包括存储在一个或多个非暂态计算机可读介质
(159)上的自动化计算机制的模块,该模块被配置为从通话准备应用(802)接收潜在客户详细信息、见解和通话准备记录,以供在电话坐席与客户之间的通话期间使用,并且通过通话准备操纵处(110)显示潜在客户详细信息(852)、见解(864)和通话准备记录。
49.图1的示例还包括智能助理(300)。图1的智能助理是支持语音的平台,其能够实现见解生成和管理语义图数据库,如下面参考图3更详细讨论的。智能助理(300)、crm(806)和通话准备应用(802)被连接到企业服务器(820)、三元组服务器(157)、声音服务器(151)、潜在客户引擎(lead engine)(134)、社交媒体服务器(130)和行业服务器(130)以进行数据通信。
50.在图1的示例中,智能助理从操作潜在客户引擎(134)的第三方取回潜在客户(lead)。这样的潜在客户可以提供关于客户的信息,通常包括联系信息、关键雇员、站点位置以及本领域技术人员将想到的关于客户的其他信息。如此取回的潜在客户被解析成语义三元组并存储在企业知识图(816)的语义三元组存储库(814)中。
51.图1的智能助理(300)、crm(806)和通话准备应用(802)与一个或多个社交媒体服务器(130)连接以用于数据通信。这样的社交媒体服务器通常由第三方实现,并且经常提供与其用户有关的信息和见解。社交媒体公司的示例包括linkedin、facebook、instagram、以及本领域技术人员将想到的其他公司。在图1的示例中,智能助理(300)可以直接从社交媒体服务器或间接从crm或通话准备引擎接收信息,并且将信息解析成语义三元组以用于存储在企业知识图的语义三元组存储库中。
52.图1的crm(806)和通话准备应用与一个或多个行业服务器连接以用于数据通信。这样的服务器通常由第三方操作并提供与特定行业、各个行业中的公司、以及本领域技术人员将想到的其他内容有关的当前和历史信息。在图1的示例中,智能助理(300)可以直接从行业服务器或间接从crm或通话准备引擎接收信息,并且将信息解析为语义三元组以用于存储在企业知识图的语义三元组存储库中。
53.在图1的示例中使用潜在客户服务器(824)、社交媒体服务器(826)和行业服务器(828)是为了便于解释而不是为了限制。事实上,根据本发明的实施例的通话准备可以利用本领域技术人员将想到的许多第三方系统或内部系统。
54.图1的示例包括通话准备操纵处(110),以供电话坐席在准备与客户的通话以及在电话坐席(128)与客户(129)之间的谈话期间使用。通话准备操纵处(110)是支持语音的用户界面,通话准备引擎(800)在该用户界面上通过其提供实时通话准备信息,以便通过仪表板(110)向电话坐席(128)进行显示,以供电话坐席在准备与客户的通话时以及在电话坐席(128)与客户之间的对话期间使用。
55.通话准备信息可以有许多不同的形式,并且来自企业的内部专有数据存储库、以及由crm取回的信息和来自第三方提供商的通话准备应用。
56.在图1的示例中,根据本发明的实施例的在通话准备中有用的许多组件被保存在计算机存储器(159)中。在图1的示例中,计算机存储器(159)包括高速缓存、随机存取存储器(“ram”)、磁盘存储装置、以及大多数形式的计算机存储器等。如此配置的计算机存储器(159)通常驻留在支持语音的设备上,或者如在此所示的,驻留在一个或多个三元组服务器(157)、声音服务器或企业服务器(820)上。
57.为了进一步解释,图2阐述了根据本发明的实施例的用于通话准备的示例系统的
线绘图。图2的示例包括语义图数据库(818),其包括企业知识图(816)。语义图数据库(818)和企业知识图(816)维护专有和非专有信息的数据存储库,专有和非专有信息关于客户信息、可以在电话坐席(128)与客户之间讨论的产品、针对客户推荐的产品、针对用户的在通话期间的电话坐席说明、以及本领域技术人员将想到的其他内容等。这样的信息可以提供给通话准备应用,通话准备应用又向通话准备操纵处应用(804)证明信息,并且通话准备操纵处应用(804)在通话准备操纵处(110)上进行显示,使得该信息可供电话坐席(128)在电话坐席与客户之间的对话之前和期间实时可用。
58.图2的示例还包括crm(806),crm(806)具有专有和非专有信息的数据存储库,专有和非专有信息关于客户信息、可以在电话坐席(128)与客户之间讨论的产品、针对客户推荐的产品、针对用户逇在通话期间的电话坐席说明、以及本领域技术人员将想到的其他内容等。这样的信息可以提供给通话准备应用,通话准备应用又向通话准备操纵处应用(804)证明信息,并且通话准备操纵处应用(804)在通话准备操纵处(110)上进行显示,使得该信息可供电话坐席(128)在电话坐席与客户之间的谈话之前和期间实时可用。
59.图2的示例包括智能助理(300),这是基于人工智能的技术的目标集合,包括自然和语义语言处理,将非结构化通信处理成结构化信息,从而取决于结构化信息和crm数据而生成通话准备引擎可用的见解,最终推动电话座席的质量和效率的提高。智能助理(300)管理语义图数据库的企业知识图(816),语义图数据库以针对见解生成而优化的三元组的形式存储结构化数据。
60.图2的示例包括通话准备引擎(800),通话准备引擎(800)包括通话准备应用(802)和通话准备操纵处应用(804)。图2的通话准备引擎(900)是存储在一个或多个非暂态计算机可读介质上的自动化计算机制的模块。通话准备应用(802)通常通过以下操作来进行操作:调用智能助理(300)以取回潜在客户详细信息、客户信息、见解和其他信息,以供在电话座席与客户之间的通话期间使用;管理电话坐席通话准备记录,以供在电话坐席与客户之间的通话期间使用。
61.图2的通话准备操纵处应用(804)包括存储在一个或多个非暂态计算机可读介质(159)上的自动化计算机制的模块,并且通常通过以下操作来进行操作:接收并显示本文中所讨论的潜在客户详细信息、客户信息、见解、通话准备记录和其他信息。
62.在图2的示例中,通过通话准备操纵处(110)显示的实时客户和产品信息被提供给电话坐席,以供电话坐席在准备与客户的通话时以及在与客户的谈话期间实时使用。在图2的示例中,支持语音的仪表板包括用于显示电话坐席的通话准备记录(850)的小部件。电话坐席可以在与客户的谈话之前、期间或之后准备或补充这种通话记录。
63.本公开中的小部件被实现为执行一个或多个特定任务的软件应用或组件,并且该软件应用或组件的执行由通话准备引擎管理(通常通过通话准备应用或通话准备操纵处)。图2的小部件被描述为由通话准备操纵处(110)管理,但是这是为了便于解释而不是为了限制。本公开中所描述的小部件中的每个小部件具有如图2中所示的随附gui元件。示例小部件及其相关联的gui元件用于说明而非限制。事实上,如本领域技术人员将想到的,根据本发明的实施例的通话准备引擎可以管理不具有gui元件或具有多于一个gui元件的小部件。
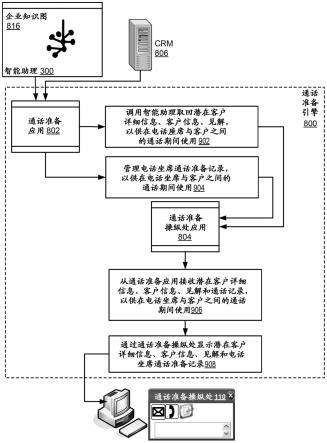
64.在图2的示例中,支持语音的通话准备操纵处(110)包括用于显示潜在客户详细信息(852)的小部件,潜在客户详细信息(852)包括描述客户和客户业务的信息,通常包括客
户的姓名和联系信息、客户所支持的行业、客户开展业务的地点、以及可能包括在有关客户的事实(860)的列表中的其他有用信息。图2的操纵处(110)还显示了连接图像(862),其向电话坐席(128)提供客户与在crm(806)内追踪的其他客户或人或组织之间的任何已知连接。
65.在图2的示例中,支持语音的通话准备操纵处(110)包括用于显示日历(882)的小部件以及用于crm见解(864)显示与crm(806)已知或派生的客户有关的见解的小部件。在图2的示例中,支持语音的仪表板(110)包括用于显示当前安装在客户站点和位置中的技术(858)的小部件,这在与客户讨论与该所安装技术兼容的产品时是有用的。
66.在图2的示例中,支持语音的通话准备操纵处(110)包括用于显示描述产品的用例(880)的小部件,其可能对电话坐席在与客户的谈话期间有用。通常这样的用例由通话中心的客户端提供以更好地向客户告知客户端销售的产品。类似地,这样的客户端可以提供可能在与客户沟通时有用的其他附属品(collateral),并且这样的附属品可以以本领域技术人员将想到的许多形式出现。
67.在图2的示例中,支持语音的操纵处(110)包括用于显示针对客户的产品推荐(852)和显示竞争产品(868)的小部件,竞争产品(868)可能由电话坐席的竞争对手销售,与客户已经在使用的当前安装的技术兼容。这些产品推荐对电话坐席(128)在准备与客户谈话时或在与客户对话期间可能是有用的。这样的产品推荐可以由语义图数据库(816)、crm(806)、通话准备引擎(800)提供、或者来自从本领域技术人员将想到的其他来源。
68.在图2的示例中,支持语音的通话准备操纵处(110)包括用于显示行业见解的小部件。行业见解可以包括客户行业的当前趋势、用于行业的新可用产品、有关行业的当前新闻、以及如本领域技术人员将想到的其他内容等。这样的见解可以由语义图数据库(816)、crm(806)、通话准备引擎(800)存储和管理,或者由第三方提供,例如运营行业服务器、社交媒体服务器、潜在客户服务器和本领域技术人员将想到的许多其他服务器的第三方。
69.在图2的示例中,支持语音的通话准备操纵处(110)包括用于显示谈话轨迹的小部件。谈话轨迹包括用于与客户进行电话通话的特定活动介绍、以及可选的电话坐席的附加谈话要点。在某些情况下,电话坐席可能想要定制谈话轨迹以包括优选的方言、风格和其他属性。在图2的示例中,谈话轨迹可以由电话坐席通过语音或通过使用键盘来编辑。
70.在图2的示例中,支持语音的通话准备操纵处(110)包括用于显示主题专家建议(874)的小部件。主题专家建议(874)可以由语义图数据库(816)、crm(806)、通话准备引擎(800)实时提供或管理,或者从本领域技术人员将想到的其它来源接收。主题专家建议可以由内部主题专家或由第三方主题专家或以本领域技术人员将想到的其他方式提供。
71.在图2的示例中,支持语音的通话准备操纵处(110)包括用于坐席评分(876)的小部件。座席分数可以代表在活动的经定义的销售周期中的电话坐席名次、通话中心或企业中的其他座席之中的电话坐席排名、以及本领域技术人员将想到的对电话坐席进行评分的其他方式。这种座席分数可以由语义图数据库(816)、crm(806)、通话准备引擎(800)或本领域技术人员将想到的其他组件开发和维护。
72.在图2的示例中,支持语音的通话准备操纵处(110)包括用于显示电话坐席的通话目标(878)的小部件。这样的通话目标通常由crm(806)或通话准备应用(802)提供,并且通常与针对特定活动定义的销售周期中的电话坐席名次有关。
73.在图2的示例中,支持语音的通话准备操纵处(110)包括用于显示动态脚本(854)的小部件,动态脚本(854)通常作为电话坐席与客户谈话的指导和帮助而实时创建。这种脚本可以由crm(806)、通话准备引擎(800)或其他组件基于当前的销售活动、与客户有关的信息、历史销售趋势、电话坐席的成功故事、以及本领域技术人员将想到的可能的其他因素来创建。
74.在图2的示例中,支持语音的仪表板(110)包括用于显示晴雨表(barometer)(860)的小部件,晴雨表是图形表示或文本显示,向电话坐席提供为特定销售活动提供服务的电话坐席的当前表现的指示。这样的晴雨表可以由语义图数据库(816)、crm(806)、通话准备引擎(800)或其他组件基于许多因素(诸如,销售活动的目标、电话坐席的表现、或者为销售活动服务的其他电话坐席以及本领域技术人员将想到的许多其他因素)进行创建。
75.在图2的示例中所呈现的组件和小部件用于说明而非限制。组件和小部件、以及它们执行的功能和它们提供的信息可以在本发明的各种实施例之间显著变化,如本领域技术人员将想到的。根据本发明的各种实施例,所有这样的组件和小部件无论其形式如何都可以用于crm的通话准备。
76.为了进一步说明,图3阐述了系统图,其图示了根据本发明的实施例的用于通话准备的系统。图3的系统包括通话准备引擎(800)、计算机(102)、crm(806)、语音引擎(153)、智能助理(300)和语义图数据库(818),它们联网以用于数据通信。通话准备引擎(800)是自动化计算机制的模块,被配置为:调用智能助理(300)以取回潜在客户详细信息、客户信息和见解,以供在电话座席与客户之间的通话期间使用;管理电话座席通话准备记录,以供在电话座席与客户之间的通话期间使用;以及通过通话准备操纵处显示潜在客户详细信息、客户信息、见解和电话座席通话准备记录。
77.图3的智能助理(300)是基于人工智能的技术的目标集合,包括自然和语义语言处理,将非结构化通信处理成结构化信息,并且取决于结构化信息和crm数据生成通话准备引擎可用的见解,最终推动电话座席的质量和效率的提高。
78.图3的crm(806)是提供旨在改善客户关系和最终改善客户满意度和企业盈利能力的联系管理、销售管理、坐席生产力管理和其他服务的自动化计算机制。图3的示例crm跨整个客户生命周期、单个销售周期、活动、推动营销、销售和客户服务等管理客户关系。
79.图3的语义图数据库(818)是一种图数据库,其能够集成来自许多来源的异构数据并在异构数据集之间建立链接。它专注于实体之间的关系,并且能够从现有信息推断出新知识。图3的语义图数据库用于推断或理解信息的含义。图3的语义技术可以自动链接新信息,而无需手动用户干预或显式预构建数据库。这种自动链接在融合来自公司内部和外部数据库(诸如,公司电子邮件、文档、电子表格、客户支持日志、关系数据库、政府/公共/行业存储库、新闻提要、客户数据、社交网络等)的数据时非常强大。在传统的关系数据库中,这种链接涉及复杂的编码、数据仓库和繁重的预处理、以及要询问的查询类型的准确先验知识。
80.图3的语义图数据库(818)包括数据库管理系统“dbms”(316)和数据存储装置(320)。图3的dbms包括企业知识图(816)和查询引擎(314)。图3的企业知识图是存储在数据存储装置(320)中的数据的结构化表示。图3的查询引擎接收结构化查询并取回所存储的信息作为响应。
81.图3的系统包括语音引擎(153)。示例语音引擎包括用于语音识别的nlp引擎和asr引擎、以及用于生成语音的文本转语音(“tts”)。示例语音引擎(153)包括语法(104)、词典(106)和语言特定的声学模型(108),如下面更详细讨论的。
82.图3的智能助理(300)包括三元组解析器和序列化器(serializer)(306)。图3的三元组解析器将某种格式的文件作为输入,诸如标准rdf/xml格式,它与更广泛的xml标准兼容。三元组解析器将这样的文件作为输入,并且将其转换为在该文件中表示的三元组的内部表示。此时,三元组被存储在三元组存储库中,可用于该存储库的所有操作。可以使用三元组序列化器(306)将解析并存储在三元组存储库中的三元组序列化回来。
83.图3的三元组解析器取决于分类学(304)和本体论(308)来创建三元组。分类学(304)包括具有经定义的语义的词或词组,它们将被存储为三元组。为了将语音解析成语义三元组,三元组解析器接收由语音引擎从语音转换的文本,并且标识对应于分类学的文本部分,并且使用分类学的经定义的元素来形成三元组。
84.图3的三元组解析器还取决于本体论(308)创建三元组。本体论是提供可共享且可重用知识表示的正式规范。本体论规范包括域中的概念和属性的描述、概念之间的关系、对可以如何使用关系的约束、以及其他概念和属性。
85.图3的智能助理(300)包括见解生成器(310)。图3的见解生成器(310)查询语义图数据库(818)的查询引擎(314),并且取决于查询结果来标识见解。这样的见解可以从满足检索结果的某些标准的预定义的见解选择,或者可以从查询结果本身形成。在与客户谈话期间,这样的见解可能对电话坐席有用。在电话准备中有用的见解的示例包括:有关行业的信息、客户职位、与预算、权限、需求和时间(“bant”)相关的见解、成本和定价信息、竞争产品、通话中的正面或负面情绪、聊天、电子邮件或其他通信、关键个人的标识、达到的目标、联系上的联系人、行业术语、电话坐席的下一最佳操作、产品推荐、自定义指标、以及本领域技术人员将想到的许多其他内容。根据本发明的实施例的见解生成器使用查询语言来生成查询。查询语言可以被实现为rdf查询语言,诸如sparql。
86.图3的智能助理(300)包括第三方数据取回模块(312)。图3的第三方数据取回模块(312)是自动化计算机制的模块,其被配置为从第三方资源(例如,行业服务器、社交媒体服务器、客户端、客户、以及本领域技术人员将想到的其他资源)取回信息。
87.为了进一步解释三元组和图之间的关系,图4阐述了图(600)的线绘图。图4的示例图以图形式实现了上述关于bob和mona lisa的示例三元组。在图4的示例中,图边(604,608,612,616,620,624)分别表示节点之间的关系,即表示谓语《是(is a)》、《是其朋友(is a friend of)》、《出生于(is born on)》、《感兴趣(is interested in)》、《由其创作(was created by)》和《关(is about)》。节点本身表示三元组的主语和宾语,《bob》、《person》、《alice》、《1990年7月4日(the 4th of july 1990)》、《the mona lisa》、《leonardo da vinci》和《视频“la joconde
à
washington”(the video
‘
la joconde
à
washington’)》。
88.在知识表示的系统中,知识以三元组的图表示,包括例如在prolog数据库、lisp数据结构或在rdfs中面向rdf的本体、owl和其他本体语言中实现的知识表示。通过被配置为在例如prolog或sparql中执行语义查询的检索引擎对这样的图进行检索和推理。prolog是一种通用逻辑编程语言。sparql是“sparql协议和rdf查询语言”的递归首字母缩写词。prolog支持对所连接的三元组的查询,这些三元组被表示为prolog数据库中的语句和规
则。sparql支持对以rdfs或owl或其他面向rdf的本体表示的本体的查询。关于prolog、sparql、rdf等,这些是说明本发明的示例实施例的技术示例。因此,这不是本发明的限制。根据本发明的实施例的有用的知识表示可以采取本领域技术人员现在或将来可能想到的许多形式,并且所有这些现在和将继续在本发明的范围内。
89.描述逻辑是形式知识表示语言家族的成员。一些描述逻辑比命题逻辑更具表现力,但是比一阶逻辑更不具表现力。与一阶逻辑相比,描述逻辑的推理问题通常是可判定的。因此,可以针对描述逻辑中的检索和推理问题实现有效的判定过程。存在一般的、空间的、时间的、时空的和模糊的描述逻辑,每种描述逻辑通过支持不同的数学构造器集来实现表达性和推理复杂性之间的不同平衡。
90.检索查询是沿着语义的尺度设置的。例如,传统的web检索被设置在该尺寸的零点上,没有语义,也没有结构。针对关键字“derivative”的传统web检索会返回讨论衍生作品的文学概念以及微积分过程的html文档。针对关键字“differential”的传统web检索会返回描述汽车零件和微积分函数的html页面。
91.其他查询沿尺度的中点设置,具有一些语义、一些结构,但是不完全完整。这实际上是web检索的当前趋势。这样的系统可以被称为可执行的而不是可判定的。从某些角度来看,可判定性不是主要问题。例如,在许多web应用中,数据集非常庞大,它们根本不需要100%正确的模型来分析可能已被某些本身不完善的启发式程序抓取、获取并转换为结构的数据。人们使用谷歌是因为它在很多时候都能找到好的答案,即使它总是找不到完美的答案。在这种粗糙的检索环境中,可证明的正确性不是关键目标。
92.在结果的正确性是关键并且可判定性进入的情况下,设置了其他类型的查询。作为数据中心中的电话坐席通过电话与汽车客户说话以讨论前差速器的用户担心不需要对微积分结果进行分类以找到正确的术语。这样的用户需要对汽车术语的正确定义,并且用户需要谈话式实时查询结果,例如几秒内。
93.在形式逻辑中,如果存在如下这样方法,则系统是可判定的,所述方法使得对于可以就系统而言表示的每个断言,该方法能够判定该断言是否在系统内有效。实际上,针对可判定描述逻辑的查询不会无限循环、崩溃、无法返回答案或返回错误答案。可判定描述逻辑支持清晰、明确和机器可处理的数据模型或本体。不可判定系统不行。可判定描述逻辑支持计算机系统可以确定逻辑中所定义的类的等效性的算法。不可判定系统不行。可判定描述逻辑可以用c、c++、sql、lisp、rdf/rdfs/owl等实现。在rdf空间中,owl的细分在可判定性上有所不同。full owl不支持可判定性。owl dl可以。
94.为了进一步说明,图5阐述了根据本发明的实施例的瘦客户端架构中的用于通话准备的示例装置的功能框图。瘦客户端架构是一种客户端-服务器架构,其中语音处理和三元组处理中的至少一些、可能大部分、可能全部从客户端卸载到服务器。瘦客户端的薄度各不相同。图5的示例中的支持语音的设备是一个瘦客户端,其中大部分语音处理被卸载到声音服务器(151)。支持语音的设备(152)接受语音输入(315,176),但是随后通过voip连接(216)将语音输入传送到执行所有语音处理的声音服务器(151)。该实例中的支持语音的设备确实实现了针对三元组处理(323,325)和查询执行(298)的一些能力,但是在瘦客户端中这些都不是绝对必要的。存储容量减小的设备(例如,智能手表或移动电话)可以在没有语义查询引擎(298)和三元组存储库(323,325)的情况下实现,只需将查询传递到自身携带所
有三元组存储装置和所有查询处理的三元组服务器(157)。
95.在图5的特定示例中,支持语音的设备占据瘦客户端架构的中间地带。它支持很少的语音处理,但是它确实支持一些三元组处理。本示例中的支持语音的设备仅针对ram(168)中的三元组存储库执行三元组处理和查询执行,将大规模存储装置留给三元组服务器(157)。语义查询引擎根据需要加载三元组存储库以响应查询。因此,存在查询未命中。当语义查询引擎无法利用ram中的三元组存储库来满足查询时,它不会断定失败。相反,它将查询传递给三元组服务器,并且,如果三元组服务器可以通过使用服务器上的三元组来满足查询,它将查询结果和满足查询的三元组两者传回支持语音的设备,然后将这些三元组存储在支持语音的设备上的ram中,以便将来用于类似的查询。随着时间的推移,这样的架构建立在支持语音的设备查询存储库上,其中包含常常有用的三元组,并且减少了通过网络到三元组服务器的昂贵查询之旅的需要—同时在客户端侧使用相对较薄的计算资源层运行。这是完全没有三元组存储装置的极瘦客户端和下面关于图8描述的厚客户端之间的折衷方案。
96.图5的示例装置包括支持语音的设备(152)和声音服务器(151),它们通过voip连接(216)连接以通过数据通信网络(100)进行数据通信。支持语音的应用(195)在支持语音的设备(152)上运行。支持语音的应用(195)可以被实现为在支持语音的浏览器上执行的x+v或salt文档的集合或序列、在java虚拟机上执行的java语音应用、或者以本领域技术人员可能想到的其他技术实现的支持语音的应用。图4的示例支持语音的设备还包括声卡(174),它是专门设计用于接收来自麦克风(176)的模拟音频信号并将音频模拟信号转换为数字形式以供编解码器(183)进一步处理的i/o适配器的示例。
97.voip代表“互联网协议语音”,是用于通过基于ip的数据通信网络路由语音的通用术语。语音数据流经通用分组交换数据通信网络,而不是传统的专用电路交换语音传输线。用于通过ip数据通信网络传输语音信号的协议通常称为“ip语音”或“voip”协议。voip业务可以部署在任何ip数据通信网络上,包括与互联网的其余部分缺乏连接的数据通信网络,例如在私有建筑物范围内的广域网数据通信网络或“lan”。
98.许多协议可以用于进行voip,例如,包括通过ietf的会话发起协议(“sip”)以及被称为“h.323”的itu协议进行的某些类型的voip。sip客户端使用tcp和udp端口5060来连接到sip服务器。sip本身用于建立和终止语音传输的通话。具有sip的voip然后使用rtp来传输实际的编码语音。类似地,h.323是国际电信联盟标准分支的总括建议,它定义了在任何分组数据通信网络上提供视听通信会话的协议。
99.支持语音的应用通常是用户级、支持语音的客户端计算机程序,其向用户(128)呈现语音界面,提供音频提示和响应(314),并且接受用于识别的输入语音(315)。图5的示例包括支持语音的通话准备引擎(800),其包括通话准备应用(802)和通话准备操纵处(804)。支持语音的通话准备引擎(800)通过通话准备操纵处(804)提供语音界面,用户可以通过该语音界面提供口头语音以用于通过麦克风(176)进行识别,并且通过声卡(174)的音频放大器(185)和编码器/解码器(编解码器)(183)而具有数字化的语音,并且将数字化语音提供给声音服务器(151)以用于识别。支持语音的通话准备引擎(800)根据voip协议将数字化语音打包在识别请求消息中,并且通过voip连接(216)在网络(100)上将语音传输到声音服务器(151)。
100.声音服务器(151)通过接受对话指令、voicexml片段等、并且返回语音识别结果(包括表示经识别的语音的文本、用作对话中的变量值的文本、以及执行语义解释脚本和语音提示的输出)为支持语音的设备提供语音识别服务。声音服务器(151)包括支持语音的应用(例如,x+v应用、salt应用或java语音应用)中的针对语音提示和对用户输入的语音响应提供文本转语音(“tts”)转换的计算机程序。
101.图5的示例中的支持语音的设备(152)包括语义查询引擎(298),它是从支持语音的应用(195)接受并针对三元组存储库(323,325)执行语义查询(340)的自动化计算机制的模块。支持语音的应用(195)用来自语音(315)、gui、键盘、鼠标(180,181)等的用户输入制定语义查询。语义查询是针对结构化数据设计和实现的查询。语义查询利用逻辑运算符、命名空间、模式匹配、子类化、传递关系、语义规则和上下文全文检索。语义查询适用于命名图、链接数据或三元组。在本发明的实施例中,三元组通常被链接以形成图。这使语义查询能够处理信息项之间的实际关系并从数据网络推断出答案。
102.语义查询的示例制定是以c、c++、java、prolog、lisp等的。例如,w3c的语义web技术堆栈提供sparql以类似于sql的语法制定语义查询。语义查询针对在三元组存储库、图数据库、语义维基(semantic wikis)、自然语言和人工智能系统中结构化的数据使用。如前所述,语义查询适用于结构化数据,并且在本案例的特定示例中,结构化数据是以符合描述逻辑的方式连接的语义三元组中描述和定义的词。在本发明的许多实施例中,针对根据实现可判定性的描述逻辑结构化的数据断言语义查询。
103.在图5的示例装置中,支持语音的设备通过通信适配器(167)、无线连接(118)、数据通信网络(100)和有线连接(121)耦接到三元组服务器(157)以用于数据通信。三元组服务器(157)为三元组存储库(323,325)提供大容量备份。三元组服务器是一种自动化计算机制的配置,它对三元组进行序列化并将经序列化的三元组存储在关系数据库、表、文件等中。三元组服务器根据请求从非易失性存储装置取回这样经序列化的三元组,将经序列化的三元组解析成三元组存储库,并且根据请求将这样三元组存储库提供给支持语音的设备,以供在根据本发明的实施例的在配置计算机存储器时利用三元组的系统中使用。
104.根据本发明的实施例的通话准备(特别是在瘦客户端架构中)可以用一个或多个声音服务器实现。声音服务器是提供语音识别和语音合成的计算机,即自动化计算机制。因此,为了进一步说明,图6阐述了根据本发明的实施例的自动化计算机制的框图,该自动化计算机制包括可用作在通话准备中有用的支持语音的设备的声音服务器(151)的计算机的示例。图6的声音服务器(151)包括至少一个计算机处理器(156)或“cpu”以及随机存取存储器(168)(“ram”),随机存取存储器(168)通过高速存储器总线(166)和总线适配器(158)连接到处理器(156)和声音服务器的其他组件。
105.声音服务器应用(188)存储在ram(168)中,声音服务器应用(188)是能够操作系统中的声音服务器的计算机程序指令的模块,该系统被配置用于根据本发明的一些实施例配置存储器。声音服务器应用(188)通过接受用于语音识别的请求并返回语音识别结果(包括表示经识别的语音的文本、用作对话中的变量值的文本、以及作为用于语义解释的脚本的字符串表示的文本)来为多模式设备提供语音识别服务。声音服务器应用(188)还包括支持语音的应用(例如,支持语音的浏览器、x+v应用、salt应用或java语音应用等)中的针对语音提示和对用户输入的语音响应提供文本转语音(“tts”)转换的计算机程序指令。
106.声音服务器应用(188)可以被实现为以java、c++、python、perl或任何语言实现的web服务器,其通过对来自x+v客户端、salt客户端、java语音客户端或其他支持语音的客户端设备的http请求提供响应来支持支持x+v、salt、voicexml或其他支持语音的语言。作为另一个示例,声音服务器应用(188)可以被实现为java服务器,java服务器在java虚拟机(102)上运行,并且通过对来自运行在支持语音的设备上的java客户端应用的http请求提供响应来支持java语音框架。此外,支持本发明的实施例的声音服务器应用可以以本领域技术人员将想到的其他方式来实现,并且所有这些方式都在本发明的范围内。
107.本示例中的声音服务器(151)包括自然语言处理语音识别(“nlp-sr”)引擎(153)。nlp-sr引擎在本文中有时被简称为“语音引擎”。语音引擎是一个功能模块,通常是一个软件模块,尽管它也可以包括执行识别和生成人类语音的工作的专门硬件。在该示例中,语音引擎(153)是包括自然语言处理(“nlp”)引擎(155)的自然语言处理语音引擎。nlp引擎接受来自自动化语音识别(“asr”)引擎的经识别的语音,将经识别的语音处理成词类(parts of speech)(主语、谓语、宾语等),然后将经识别的、处理后的词类转换成语义三元组以纳入三元组存储库中。
108.语音引擎(153)包括用于语音识别的自动化语音识别(“asr”)引擎以及用于生成语音的文本转语音(“tts”)引擎。语音引擎还包括语法(104)、词典(106)和特定语言的声学模型(108)。语言特定的声学模型(108)是数据结构、表格或数据库,例如,它将语音特征向量(“sfv”)与表示通常存储在词汇文件中的人类语言中的词的发音的音素相关联。词典(106)是文本形式的词与表示每个词的发音的音素的关联;该词典有效地标识能够被asr引擎识别的词。还存储在ram(168)中的是文本转语音(“tts”)引擎(194),它是计算机程序指令的模块,它接受文本作为输入,并且以数字编码语音的形式返回相同的文本,以供在提供语音作为对支持语音的系统的用户的提示和响应时使用。
109.语法(104)将当前可以被识别的词和词序列传达给asr引擎(150)。为了进一步说明,区分语法的目的和词典的目的。该词典将asr引擎可以识别的所有词与音素相关联。语法传达当前有资格用于识别的词。这两个集合在任何特定时间可能都不相同。
110.语法可以用asr引擎支持的多种格式表示,例如,java语音语法格式(“jsgf”)、w3c语音识别语法规范(“srgs”)的格式、来自ietf的rfc2234的增强backus-naur格式(“abnf”)、在w3c的随机语言模型(n-gram)规范中描述的随机语法的形式、以及本领域技术人员将想到的其他语法格式。语法通常作为对话框的元素操作,例如voicexml《menu》或x+v《form》。语法的定义可以在对话中直接表达。或者,语法可以在单独的语法文档中外部实现,并且通过具有uri的对话框引用。在此是以jsfg表示的语法的示例:
[0111][0112]
在该示例中,名为《命令(command)》、《名称(name)》和《何时(when)》的元素是语法规则。规则是规则名称和规则扩展的组合,它建议asr引擎或语音解译器当前可以识别哪些词。在本示例中,扩展包括合取和析取,竖线“|”表示“或”。asr引擎或语音解译器按顺序处理规则,首先是《命令(command)》,然后是《名称(name)》,然后是《何时(when)》。《命令(command)》规则接受“通话(call)”或“通电话(phone)”或“打电话(telephone)”加(也就是说,结合)从《名称(name)》规则和《何时(when)》规则返回的任何内容用于识别。《名称(name)》规则接受“bob”或“martha”或“joe”或“pete”或“chris”或“john”或“harold”,而《何时(when)》规则接受“今天(today)”或“这个下午(this afternoon)”或“明天(tomorrow)”或“下周(next week)”。命令语法作为整体匹配这样的话语,例如:
[0113]
·“下周与bob通话(phone bob next week)”,
[0114]
·“这个下午给martha打电话(telephone martha this afternoon)”,
[0115]
·“明天提醒我与chris通话(remind me to call chris tomorrow)”,以及
[0116]
·“今天提醒我与pete通电话(remind me to phone pete today)”。
[0117]
本示例中的声音服务器应用(188)被配置为从在网络上距离声音服务器远程定位的支持语音的客户端设备接收来自用户的用于识别的数字化语音,并且将语音传递给asr引擎(150)以进行识别。asr引擎(150)是计算机程序指令的模块,在本示例中也存储在ram中。在执行自动化语音识别时,asr引擎以至少一个数字化词的形式接收用于识别的语音,并且使用数字化词的频率分量来导出语音特征向量或sfv。例如,sfv可以由数字化语音的样本的前十二个或十三个傅立叶或频域分量来定义。asr引擎可以使用sfv从特定语言的声学模型(108)推断词的音素。asr引擎然后使用音素在词典(106)中查找词。
[0118]
还存储在ram中的是voicexml解译器(192),它是处理voicexml语法的计算机程序指令的模块。对voicexml解译器(192)的voicexml输入可以源自例如在支持语音的设备上远程运行的voicexml客户端、在支持语音的设备上远程运行的x+v客户端、在支持语音的设备上运行的salt客户端、在多媒体设备上远程运行的java客户端应用等。在该示例中,voicexml解译器(192)解译并执行表示从远程支持语音的设备接收并通过声音服务器应用(188)提供给voicexml解译器(192)的语音对话指令的voicexml片段。
[0119]
瘦客户端架构中的支持语音的应用(图4上的195)可以通过用这样的支持语音的应用跨网络的数据通信向voicexml解译器(149)提供语音对话指令、voicexml片段、
voicexml《form》元素等。语音对话指令包括一个或多个语法、数据输入元素、事件处理程序等,它们建议voicexml解译器如何管理来自用户的语音输入以及要呈现给用户的语音提示和响应。voicexml解译器通过根据voicexml表单解译算法(“fia”)(193)顺序处理对话指令来管理这样的对话。voicexml解译器解译由支持语音的应用提供给voicexml解译器的voicexml对话。
[0120]
如上所述,表单解译算法(“fia”)驱动用户与支持语音的应用之间的交互。fia通常负责选择和播放一个或多个语音提示、收集用户输入、填写一个或多个输入项的响应或抛出某些事件、以及解译与新填写的输入项有关的动作。fia还处理支持语音的应用初始化、语法激活和停用、输入和离开具有匹配话语的表格以及许多其他任务。fia还维护内部提示计数器,该内部提示计数器随着每次尝试引起用户响应而增加。也就是说,每次尝试提示来自用户的匹配语音响应失败时,内部提示计数器都会增加。
[0121]
还存储在ram(168)中的是操作系统(154)。在根据本发明的实施例的声音服务器中有用的操作系统包括unix
tm
、linux
tm
、microsoft nt
tm
、aix
tm
、ibm的i5/os
tm
、以及本领域技术人员将想到的其他内容。图5示例中的操作系统(154)、声音服务器应用(188)、voicexml解译器(192)、asr引擎(150)、jvm(102)和tts引擎(194)被示出在ram(168)中,但是这种软件的许多组件通常也存储在非易失性存储器中,例如,在磁盘驱动器(170)上。
[0122]
图6的声音服务器(151)包括总线适配器(158)、包含用于高速总线的驱动电子器件的计算机硬件组件、前端总线(162)、视频总线(164)和存储器总线(166)、以及用于较慢扩展总线(160)的驱动电子器件。在根据本发明的实施例的声音服务器中有用的总线适配器的示例包括英特尔北桥(northbridge)、英特尔存储器控制器枢纽、英特尔南桥(southbridge)和英特尔i/o控制器枢纽。在根据本发明的实施例的声音服务器中有用的扩展总线的示例包括工业标准架构(“isa”)总线和外围组件互连(“pci”)总线。
[0123]
图6的声音服务器(151)包括磁盘驱动器适配器(172),其通过扩展总线(160)和总线适配器(158)耦接到处理器(156)和声音服务器(151)的其他组件。磁盘驱动器适配器(172)以磁盘驱动器(170)的形式将非易失性数据存储装置连接到声音服务器(151)。在声音服务器中有用的磁盘驱动器适配器包括集成驱动电子(“ide”)适配器、小型计算机系统接口(“scsi”)适配器以及本领域技术人员将想到的其他适配器。此外,非易失性计算机存储器可以针对声音服务器被实现为如本领域技术人员将想到的光盘驱动器、电可擦除可编程只读存储器(所谓的“eeprom”或“闪存”存储器)、ram驱动器等。
[0124]
图6的示例声音服务器包括一个或多个输入/输出(“i/o”)适配器(178)。声音服务器中的i/o适配器通过例如用于控制到显示设备(例如,计算机显示屏)的输出、以及来自用户输入设备(181)(例如,键盘和鼠标)的用户输入的软件驱动程序和计算机硬件来实现面向用户的输入/输出。图5的示例声音服务器包括视频适配器(209),它是专门设计用于将图形输出到显示设备(180)(例如,显示屏或计算机监视器)的i/o适配器的示例。视频适配器(209)通过高速视频总线(164)、总线适配器(158)和前端总线(162)(也是高速总线)连接到处理器(156)。
[0125]
图6的示例声音服务器(151)包括通信适配器(167),其用于与其他计算机(182)进行数据通信和用于与数据通信网络(100)进行数据通信。这样的数据通信可以通过rs-232连接、通过诸如通用串行总线(“usb”)的外部总线、通过诸如ip数据通信网络的数据通信网
络、以及以本领域技术人员将想到的其他方式串行执行。通信适配器实现数据通信的硬件级别,一台计算机通过它直接将数据通信发送到另一台计算机或通过数据通信网络将数据通信发送到另一台计算机。可用于本发明的实施例的通信适配器的示例包括用于有线拨号通信的调制解调器、用于有线数据通信网络通信的以太网(ieee 802.3)适配器、以及用于无线数据通信网络通信的802.11适配器。
[0126]
为了进一步说明,图7阐述了根据本发明的实施例的自动化计算机制的框图,该自动化计算机制包括可用作用于通话准备的三元组服务器(157)的计算机的示例。图7的三元组服务器(157)包括至少一个计算机处理器(156)或“cpu”以及随机存取存储器(168)(“ram”),随机存取存储器(168)通过高速存储器总线(166)和总线适配器(158)连接到处理器(156)和三元组服务器的其他组件。处理器通过视频总线(164)连接到视频适配器(209)和计算机显示器(180)。处理器通过扩展总线(160)连接到通信适配器(167)、i/o适配器(178)和磁盘驱动器适配器(172)。处理器通过数据通信网络(100)和无线连接(118)连接到支持语音的膝上型电脑(126)。操作系统(154)设置在ram中。
[0127]
还设置在ram中的有三元组服务器应用程序(297)、语义查询引擎(298)、语义三元组存储库(814)、三元组解析器/序列化器(294)、三元组转换器(292)和一个或多个三元组文件(290)。三元组服务器应用程序(297)通过网络(100)从诸如膝上型电脑(126)的支持语音的设备接受语义查询,它传递给语义查询引擎(298)以针对三元组存储库(323,325)执行。
[0128]
三元组解析器/序列化器(294)管理三元组在三元组存储库与各种形式的磁盘存储装置之间的传输。三元组解析器/序列化器(294)接受三元组存储库的内容作为输入,并且将它们序列化以作为三元组文件(290)、表格、关系数据库记录、电子表格等的输出,以便长期存储在非易失性存储器(例如,硬盘(170))中。三元组解析器/序列化器(294)接受三元组文件(290)作为输入,并且将解析出的三元组输出到三元组存储库中。在许多实施例中,当三元组解析器/序列化器(294)接受三元组文件(290)作为输入并将解析出的三元组输出到三元组存储库时,三元组解析器/序列化器将所输出的三元组存储在存储器的连续分段中。在c编程语言中,可以通过调用malloc()函数来实现连续存储。连续存储可以受python缓冲区协议的影响。可以以本领域技术人员将想到的其他方式实现连续存储,并且所有这样的方式在本发明的范围内。在许多实施例中,三元组存储库(323,325)都将存储在连续存储器的一个或两个分段中。
[0129]
为了进一步说明,图8阐述了根据本发明的实施例厚客户端架构中的用于计算机存储器中的crm的通话准备的示例装置的功能框图。厚客户端架构是一种客户端-服务器架构,其中管理配置具有描述逻辑的三元组的计算机存储器所需的全部或大部分功能直接在客户端侧支持语音的设备上得到支持,而不是在服务器上得到支持。服务器用于备份和同步,而不是语音识别或语义查询。厚客户端需要资源、处理器能力和存储,可能并不总是在诸如智能手表的小型设备上可用。然而,在具有足够数据处理资源的厚客户端中,所有相关功能、查询、三元组、语音通常都是立即且完全有用的,而不管网络可用性如何。
[0130]
图8的示例中的厚客户端支持语音的设备是自动化计算机机器,其包括处理器(156)、ram(168)、数据总线(162,164,166,160)、视频(180,209)、数据通信(167)、i/o(178)和磁盘存储装置(170)。设置在ram中的有支持语音的通话准备引擎(800)、语义查询引擎
(298)、语义三元组存储库(814)、三元组解析器/序列化器(294)、三元组转换器(292)和一个或多个三元组文件(290)。支持语音的应用(195)从用户输入接受语义查询,它传递给语义查询引擎(298)以针对三元组存储库(814)执行。所有相关的三元组都在本地ram中可用。所有查询成功或失败仅基于本地存储装置。查询不被转发到三元组服务器(157)。当多个客户端侧设备共享三元组存储库的内容时,三元组服务器(157)提供长期备份和同步功能,但是对于任何特定查询,所有响应三元组都可以直接在客户端侧可用。
[0131]
三元组解析器/序列化器(294)管理三元组在三元组存储库和磁盘存储装置(170)之间的传输,并且磁盘存储装置直接在厚客户端(152)上可用,而不是跨网络在服务器上可用。三元组解析器/序列化器(294)接受三元组存储的内容作为输入,并且将它们序列化以作为三元组文件(290)、表格、关系数据库记录、电子表格等的输出,以便长期存储在非易失性存储器(例如,硬盘(170))中。三元组解析器/序列化器(294)接受三元组文件(290)作为输入,并且将解析出的三元组输出到三元组存储库中。在许多实施例中,当三元组解析器/序列化器(294)接受三元组文件(290)作为输入并将解析出的三元组输出到三元组存储库时,三元组解析器/序列化器将所输出的三元组存储在存储器的连续分段中。
[0132]
语音引擎(153)是全方位服务的nlp-sr引擎,包括自然语言处理(155)、语音识别(150)、语法(104)、词典(106)、模型(108)和文本转语音处理(194),所有这些都在上面更详细地描述了。厚客户端支持语音的设备(152)不需要跨网络进行语音相关处理。完全的语音启用直接在支持语音的设备本身上可用。
[0133]
为了进一步说明,图9阐述了示出根据本发明的实施例的用于客户关系管理(“crm”)的通话准备的示例方法的流程图。图9的方法包括:通过通话准备应用(802)调用(302)智能助理以取回潜在客户详细信息、客户信息和见解,以供在电话坐席与客户之间的通话期间使用。调用(302)智能助理可以通过与智能助理建立通信并向智能助理提供标识和接收潜在客户详细信息、客户信息和见解所需的信息来执行。这样的信息可以包括电话坐席的标识、电话坐席支持的活动、客户、客户端以及本领域技术人员将想到的许多其他信息。
[0134]
一旦被调用,智能助理可以取决于自己的动作、应请求、周期性地、或者以本领域技术人员将想到的其他方式来提供附加信息。例如,智能助理可以根据通话准备分类学和通话准备本体论将从电话坐席的语音转换的文本解析为语义三元组,并且将解析出的三元组存储在语义图数据库的企业知识图中。然后,智能助理可以开发实时查询并使用实时查询来查询语义数据库,并且取决于实时查询的结果标识见解和其他有用信息。此外,智能助理可以标识一个或多个第三方资源(例如,行业资源、社交媒体资源等),并且查询所识别的资源以获取与电话坐席与客户之间的通话相关的信息。
[0135]
图9的方法包括:由通话准备应用(802)管理(304)电话坐席通话准备记录,以供在电话坐席与客户之间的通话期间使用。管理(304)电话坐席通话准备记录可以通过取回先前准备的通话记录、从电话坐席接收通话记录、标识标准或预先准备的通话记录模板、或者以本领域技术人员将想到的其他方式来执行。在一些实施例中,通话准备应用被配置为:通过通话准备操纵处应用从电话坐席接收用于识别的语音,并且取决于一个或多个通话准备语法调用自动化语音识别引擎以将用于识别的语音转换为文本,并且将文本存储为通话准备记录以供电话坐席使用。
[0136]
图9的方法包括:通过通话准备操纵处应用(804)从通话准备应用接收(906))潜在客户详细信息、客户信息、见解和通话记录,以供在电话坐席与客户之间的通话期间使用,并且通过通话准备操纵处显示(908)潜在客户详细信息、客户信息、见解和电话坐席通话准备记录。通过通话准备操纵处显示(908)潜在客户详细信息、客户信息、见解和电话坐席通话准备记录可以通过呈现包含潜在客户详细信息、客户信息、见解和通话准备记录的xml或其他标记语言页面来执行。
[0137]
在图9的示例中,通话准备应用(802)可以从一个或多个客户关系管理(“crm”)系统(806)取回客户信息。这样的客户信息可以包括用例、销售历史、客户所使用的已知技术、以及针对电话坐席在即将到来的通话中的其他有用信息。
[0138]
根据前述描述将理解,在不脱离本发明的真实精神的情况下,可以对本发明的各种实施例进行修改和改变。本说明书中的描述仅用于说明的目的,而不应被解释为限制性的。本发明的范围仅由所附权利要求的语言限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1