一种基于半监督学习与特征增广的多小区大规模MIMO通信的功率分配方法
一种基于半监督学习与特征增广的多小区大规模mimo通信的功率分配方法
技术领域
1.本发明涉及一种基于半监督与特征增广的无需信道状态信息反馈的功率分配方法,属于无线通信、深度学习领域。
背景技术:
2.无线通信技术与我们的生活密切相关,由于其便捷的特性,成为当今时代大家所使用的主要通信手段,人们对无线数据传输性能的要求也在逐年持续提高,5g通信相比4g具有更高的能量效率、更大的频谱效率、更低的传输时延以及更广的覆盖范围,为了实现5g的这些优势,许多核心技术被提出并成为通信领域研究的热门研究问题,例如大规模多输入多输出(mimo)技术、非正交多址接入技术、超密集组网技术等。
3.大规模mimo技术是指在基站端配置数量庞大的大规模天线阵列来同时服务于多个用户,它能够深度挖掘空间维度资源,使得网络中的多个用户可以在同一时频资源上利用大规模mimo提供的空间自由度与基站同时进行通信,从而在不需要增加基站密度和带宽的条件下,提高频谱效率,是解决通信数据服务需求的关键技术之一。蜂窝网络由一组基站(bs,basestation)和一组用户设备(ue,user)组成。每个ue连接到一个bs,bs为其提供服务。下行链路(dl,downlink)是指从bs发送到各自ue终端的传输,上行链路(ul,uplink)是从终端发送到各自bs的传输。
4.在大规模mimo网络中,功率分配对于处理用户间的干扰非常重要。基站对该服务小区内的所有用户分配不同的功率,以达到减小干扰增加网络吞吐量的目的,因为每个用户都会受到同小区用户以及周围小区用户的干扰,用户之间相互制约,想要网络总体性能达到最优往往是非凸的问题,并且很难直接求解,传统解决方法大多基于迭代算法逐次逼近最优解,复杂度高,难以实时实施。目前,基于机器学习技术的快速发展,功率分配可以利用训练深度神经网络模型来解决,有方法利用传统迭代算法获得最优标签,使用监督学习将用户的位置与最优功率分配做映射,但它需要超大量的样本,且需要针对多小区场景中的每一个小区训练不同模型。也有学者使用用户的完整信道信息与最优功率分配信息构建数据集,来进行监督学习,而实际中很难得到完整的信道反馈信息。
5.本发明中使用了半监督dnn模型,能够减少训练所需要的带标签样本,且保持逼近传统优化算法的性能,同时模型仅使用了用户位置信息,并对其进行了特征增广,不需要用户的信道反馈信息,经过训练得到的模型处理新的用户功率分配问题时仅需要线性运算,复杂度低且最终的效果可以逼近复杂的传统迭代优化算法。
技术实现要素:
6.发明目的:本发明是为了解决传统方法求解功率分配问题复杂度高而基于深度学习的算法必须要大量特征与大量样本才能逼近传统算法性能的问题,本发明使用了半监督与特征增广方法减少了深度学习所需要的样本数量,提供一种基于半监督学习与特征增广
的多小区大规模mimo通信的功率分配方法。
7.本发明采用的技术方案:
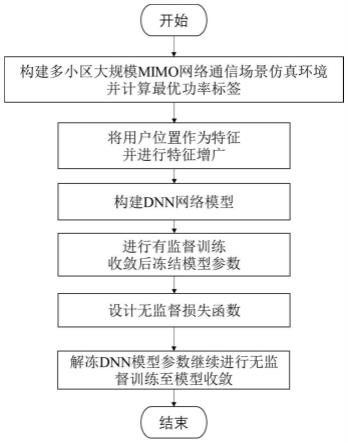
8.一种基于半监督学习与特征增广的多小区大规模mimo通信的功率分配方法,包括如下步骤:
9.(1)构建多小区大规模mimo网络通信场景仿真环境,并计算不同用户分布时所对应的最优功率分配,作为监督学习部分的标签,以用户位置作为特征并进行特征增广。
10.(2)构建分支型dnn模型,进行有监督训练直至收敛,冻结模型参数。
11.(3)设计无监督训练时的损失函数,同时考虑优化目标与功率约束条件两部分。解冻模型参数,继续对模型进行无监督训练至模型收敛。
12.优选地,步骤(1)的具体步骤包括:
13.(1.1)设定要仿真的多小区多用户通信场景的参数信息,对于一个带有l个小区的大规模mimo网络的dl(下行,down link)传输,每个小区包括一个带有m个天线的bs和k个ue,设定基站端最大信号发射功率p
max
、带宽w;建立要仿真区域的二维坐标系,确定每个bs的位置,另外在每个小区随机生成k个ue的位置信息;
14.(1.2)将l*k个用户位置信息按照坐标系的x轴y轴方向分别组合起来,得到初步的位置特征,即(x
11
,x
12
,
…
,x
lk
,y
11
,y
12
,
…
,y
lk
),同时特征维度重复使用并扩增为原来的l倍,以便输入本发明所设计的分支型dnn模型,扩增后的特征长度为2*l*k*l,即(x
11
,x
12
,
…
,x
lk
,y
11
,y
12
,
…
,y
lk
,
……
,x
11
,x
12
,
…
,x
lk
,y
11
,y
12
,
…
,y
lk
);
15.(1.3)信道建模假设为相关瑞利衰落信道,用表示小区l中bsj到uek之间的信道;
[0016][0017]
其中,是基站端的空间相关矩阵;利用导频信号与mmse信道估计,得到预编码向量满足||w
li
||2=1;
[0018]
(1.4)使用传统方法求解时,优化目标定为最大化有效sinr乘积(sinr表示信号干扰噪声比):
[0019][0020][0021]
此优化问题可以转化为一个几何规划问题被有效解决,几何规划问题可以通过变量的变换转化为凸优化问题进行有效求解,使用传统优化方法得到最终的最优输出功率为p
*
=(ρ
11
,
…
,ρ
lk
)。
[0022]
优选地,步骤(2)的具体步骤包括:
[0023]
(2.1)根据得到的用户数据样本特征与标签,设计分支型dnn的网络结构,此dnn一共包含l个分支,网络输入层神经元数量对应输入的增广后的用户位置特征(x
11
,x
12
,
…
,x
lk
,y
11
,y
12
,
…
,y
lk
,
……
,x
11
,x
12
,
…
,x
lk
,y
11
,y
12
,
…
,y
lk
),输出层神经元数量对应每个用户
的功率分配p=(ρ
11
,
…
,ρ
lk
)。
[0024]
(2.2)在进行监督训练时,损失函数设计为dnn预测的最优功率与真实最优功率p
*
之间的均方误差mse,不断重复训练的过程至模型收敛,然后冻结网络参数。
[0025]
优选地,步骤(3)的具体步骤包括:
[0026]
(3.1)损失函数设计为两部分之和,第一部分直接设置为最终的优化目标本身,即用户的频谱效率之和sesum,小区j中uek的dl频谱效率估计为:
[0027][0028]
τd/τc表示相干块中下行数据传输所占的比例。
[0029]
由于网络在训练过程中对损失函数进行梯度下降,所以需要将其变为负值,即-1*sesum。
[0030]
(3.2)损失函数的第二部分为此优化问题的约束,即每个基站给其小区内的用户分配的功率之和不能大于其硬件限制pmax。当功率之和psum大于pmax时,损失会迅速上升,即有较大惩罚,而功率之和psum不超过门限时,功率的大小变化是自由的,应该让功率的变化对损失函数的影响尽量小,让损失函数总体可以朝着主要的优化目标前进,即只让损失函数的第一部分起作用。
[0031]
(3.3)利用sigmoid函数实现此功能,考虑到sigmoid函数在自变量大于-2之后梯度较大,希望损失函数的约束效果为,在psum大于约束值pmax时惩罚能迅速变大,且因为无监督训练是在有监督训练对网络进行了初始化的基础上进行微调,一般不会越过sigmoid梯度较大的范围直至梯度变小处,另外,还设置了权重因子α以实现损失函数中前后两项的平衡。最终的损失函数设计如以下公式所示:
[0032][0033]
(3.4)利用仿真环境生成用户位置数据,无需标签,冻结经过了有监督训练初始化与无监督训练优化后的dnn网络参数,使用训练完毕后的dnn模型即可以处理新的用户数据。
[0034]
有益效果:
[0035]
本发明可以解决多小区大规模mimo用户移动场景下的功率分配,效果可以逼近复杂的传统算法,半监督训练减少了所需样本的数量,特征复用在特征较少的情况下保证了网络的训练效果,且只需要用户的位置信息而不需要信道状态信息反馈。
附图说明
[0036]
图1为本发明实施一种基于半监督与特征增广的无需信道状态信息反馈的功率分配方法流程图;
[0037]
图2为本发明实施例所使用的半监督dnn网络模型结构图;
[0038]
图3为本发明实施例无监督损失函数实现约束功能部分的函数大小与梯度图。
[0039]
图4为本发明实施的一次仿真测试中模型所预测的功率分配决策与最优功率分配对比图;
[0040]
图5为本发明实施在整个测试集上的用户频谱效率性能对比图。
具体实施方式
[0041]
下面结合附图和具体实施方式对本发明的技术方案作进一步的说明。
[0042]
图1展示了本发明实施一种基于半监督与特征增广的无需信道状态信息反馈的功率分配方法流程图,包括:
[0043]
步骤s1:构建多小区大规模mimo网络通信场景仿真环境,并计算不同用户分布时所对应的最优功率分配,作为监督学习部分的标签,以用户位置作为特征并进行特征增广。
[0044]
步骤s11:设定要仿真的多小区多用户场景,对于一个带有4个小区的大规模mimo网络的dl传输,每个小区的面积为250
×
250m,共同形成一个1000
×
1000m的多小区场景,每个小区包含一个基站bs,位于小区中心位置,每个bs的天线数量m=100,用户的上行传输功率p
ul
=100mw,网络中局部散射模型中的角标准差为10度,基站端最大信号发射功率p
max
=500mw,带宽w=20mhz;建立要仿真区域的二维坐标系,在每个小区随机生成k个ue的位置信息;
[0045]
步骤s12:将20个用户位置信息按照坐标系的x轴y轴方向分别组合起来,得到初步的位置特征,即(x
11
,x
12
,
…
,x
lk
,y
11
,y
12
,
…
,y
lk
),因为特征数据量较少,没有信道反馈信息,希望尽量充分利用好用户位置信息,将特征维度重复使用并扩增为原来的4倍,扩增后的特征为(x
11
,x
12
,
…
,x
lk
,y
11
,y
12
,
…
,y
lk
,
……
,x
11
,x
12
,
…
,x
lk
,y
11
,y
12
,
…
,y
lk
),特征长度为160,以便输入本发明所设计的分支型dnn模型。每一个bs进行功率分配决策时,它都需要知道所有用户的位置,因为基站除了服务本小区的用户以外,还要考虑自己发射的信号会对其他小区的用户造成干扰。
[0046]
本发明所设计的分支型网络的每一个分支部分,负责一个基站的功率分配输出,最后组成总体的输出,并用于之后的有监督训练以及无监督训练的损失函数计算。本发明所设计的分支型dnn网络整体上作为一个模型存储并使用。
[0047]
步骤s13:信道建模假设其服从瑞利分布,用表示小区l中bsj到uek之间的信道。
[0048][0049]
其中,是基站端的空间相关矩阵。利用导频信号与mmse信道估计,得到预编码向量满足||w
li
||2=1。
[0050]
步骤s14:有监督训练阶段求解标签时,目标函数选定为最大化有效sinr乘积,sinr表示信号干扰噪声比,即优化目标定为:
[0051]
[0052][0053]
此优化问题可以视为一个几何规划问题被有效解决,几何规划问题可以通过变量的转换化为凸优化问题进行有效求解,使用传统优化方法得到最终的最优输出功率为p
*
=(ρ
11
,
…
,ρ
lk
)。
[0054]
步骤s2:构建分支型dnn模型,进行有监督训练直至收敛,冻结模型参数。
[0055]
步骤s21:根据步骤s1中得到的用户数据样本特征与标签,设计分支型dnn的网络结构图如图2所示,网络输入层神经元数量为160,对应输入的增广后的用户位置特征(x
11
,x
12
,
…
,x
lk
,y
11
,y
12
,
…
,y
lk
,
……
,x
11
,x
12
,
…
,x
lk
,y
11
,y
12
,
…
,y
lk
),输出层神经元为20,对应每个用户的功率分配p=(ρ
11
,
…
,ρ
lk
),此dnn一共包含l=4个分支,每个分支有三层隐藏层,神经元个数分别为512,256,128。
[0056]
步骤s22:在进行监督训练时,一共生成了90000个训练样本,10000个验证样本,以及5000个测试样本。损失函数设计为dnn预测的最优功率与真实最优功率p
*
之间的均方误差mse,批量大小即batchsize为512,不断重复训练的过程,一共迭代60次,然后冻结网络参数。
[0057]
步骤s3:设计无监督训练时的损失函数,同时考虑优化目标与功率约束条件两部分。解冻模型参数,继续对模型进行无监督训练至模型收敛。
[0058]
步骤s31:损失函数设计为两部分之和,第一部分直接设置为最终的优化目标本身,即用户的频谱效率之和sesum,小区j中uek的dl频谱效率估计为:
[0059][0060]
τd/τc表示相干块中下行数据传输所占的比例。
[0061]
由于网络在训练过程中对损失函数进行梯度下降,所以需要将其变为负值,即-1*sesum;
[0062]
步骤s32:损失函数的第二部分为此优化问题的约束,即每个基站给其小区内的用户分配的功率之和不能大于其硬件限制500mw。当功率之和psum大于pmax时,损失会快速变大,即有较大惩罚,而功率之和psum不超过门限时,功率的大小变化是自由的,应该让功率的变化对损失函数的影响尽量小,让损失函数总体可以朝着主要的优化目标前进,即只让损失函数的第一部分起作用。
[0063]
步骤s33:利用sigmoid函数实现此功能,设置了权重因子α,在本研究中设置α=10以实现损失函数中前后两项的平衡。最终的损失函数设计如以下公式所示:
[0064][0065]
sigmoid函数部分与其梯度图如图3所示,从图中可以看出,当功率之和小于500mw
时,sigmoid函数值与梯度值都基本为零,使得其值不影响损失函数中的用户频谱效率之和的部分,当功率之和超过500mw时,sigmoid函数值迅速增大,起到一个较大的惩罚作用,同时因为已经有了有监督训练过程将网络进行了较好的初始化,同时限制了学习率,网络训练过程中很难越过sigmoid函数梯度较大区域到达梯度消失处,即基站的功率分配之和难以大于550mw,这样的设计能够使得sigmoid函数部分起到一个良好的约束效果。
[0066]
步骤s34:利用仿真环境生成用户位置数据,无需标签,得到训练集为90000个样本,验证集为10000个样本,测试集为5000个样本。在训练时batchsize为256,一共迭代了4次,每次迭代更新352步。在训练过程中,观察到用户的频谱效率之和随迭代次数增加而逐步上升,表示无监督训练过程效果较好。
[0067]
步骤s35:冻结经过了有监督训练初始化与无监督训练优化后的dnn网络参数,使用训练完毕后的dnn模型可以处理新的用户数据,图4展示了一次仿真中半监督dnn模型所预测的功率分配决策,只进行了有监督训练的mlp模型的功率分配决策与最优功率分配对比图,本发明的半监督dnn模型预测明显更接近最优决策。图5展示了在5000个样本数量的测试集上,基站使用半监督dnn模型的功率分配决策,与使用mlp模型决策,以及基站使用最优功率分配决策后用户的频谱效率累计分布图(cumulative distribution function,cdf),可以看出半监督dnn模型性能能够逼近最优功率分配决策。
[0068]
本发明的上述算例仅为详细地说明本发明的计算模型和计算流程,而并非是对本发明的实施方式的限定,这里无法对所有的实施方式予以穷举,凡是属于本发明的技术方案所引伸出的显而易见的变化或变动仍处于本发明的保护范围之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1