一种基于多智能体强化学习的LEO星间链路的动态规划方法
一种基于多智能体强化学习的leo星间链路的动态规划方法
技术领域
1.本发明涉及卫星通信技术领域,具体涉及一种基于多智能体强化学习的leo星间链路的动态规划方法。
背景技术:
2.近年来,低地球轨道(leo)卫星星座已成为一种新兴且有前途的技术,能够为地面用户提供低延迟、宽带通信和全球覆盖,并有望在6g通信中发挥重要作用。许多头部公司,如spacex、oneweb和亚马逊,都试图部署一个大型的leo卫星星座,以提供稳定的宽带互联网服务。低轨卫星之间可以利用光学或可见光通信系统实现卫星间链路(inter-satellite links,isls)的连接,包括:平面内isls,连接同一轨道平面的相邻卫星;平面间isls,连接不同轨道平面的卫星。由于同一轨道平面内卫星间的距离可以在很长时间内保持恒定,所以平面内isls相当稳定。然而,不同轨道平面之间的星间距离是时变的:卫星在赤道上空时距离最长,在极地边界时距离最短。此外,在不同的高度部署轨道平面时,轨道周期也会不同,导致拓扑结构的非周期性。因此,任何固定的平面间isls连通性方案都不能很好地满足星座拓扑的变化,动态规划平面间isls至关重要。
3.由于低地球轨道星座的环境特性和硬件条件的限制,动态规划低地球轨道星座的平面间isls具有一定的挑战性。首先,由于leo星座的动态运动和高维性,星座中星间链路的规划变得非常复杂。数百颗卫星相对于地面用户以大约7.5km/s的速度移动,每颗卫星都有一组用于建立isls的平面间邻居卫星。这导致了平面间isls的规划是np-hard(所有np问题都能在多项式时间复杂度内归遇到的问题)的,并面临“维数诅咒”的问题;其次,由于有限的视线距离,每个卫星只能观测到部分星座信息,实时采集全球星座信息成本较高,而部分信息容易陷入局部最优;第三,一颗卫星可能有资格与其多个相邻卫星建立平面间isls,同一轨道上的卫星之间存在竞争和合作,与其他卫星竞争一颗卫星是为了提高其平面间isls的质量,而合作则是为了使星座的总吞吐量最大化,对于整个星座来说,在竞争与合作之间实现良好的权衡是至关重要的。
4.现有的研究大多集中在分析星间链路的特征和模型,而没有对卫星间连接进行规划。例如,作者在文献[1]中提出了一个功率预算模型来分析倾斜范围对功率需求的影响,文献[2]在通过研究卫星之间的可见性及其天线转向能力,对星间链路的连接进行了全面的分析。这些工作只是为平面间星间链路提供了一些参考,并没有提供任何具体的星间链路规划方案。基本的星间链路规划算法是启发式的[3]-[5],它们根据leo星座的部分信息,通过贪婪、模拟退火等方法推导出方案,但是,上述文献很容易陷入局部最优;另一种典型的方法由文献[6]提出,该方法用有限状态自动化对星间链路网络进行建模,并用整数线性规划对其进行求解,但是,该算法计算量大,不适合高维度、高动态性的leo星座。
[0005]
因此,设计一种能够使整个星座在竞争与合作之间实现良好的权衡的leo星间链路的规划方法是至关重要。
技术实现要素:
[0006]
为了解决上述问题,本发明提出了一种基于多智能体强化学习的leo星间链路的动态规划方法,联合优化星座总吞吐量和平面间isls切换率,以实现整个星座在竞争与合作之间实现良好的权衡。
[0007]
本发明通过下述技术方案实现:
[0008]
一种基于多智能体强化学习的leo星间链路的动态规划方法,包括:
[0009]
s1、根据欧氏距离、视线距离、通信速率和天线切换成本设计部分可观察马尔科夫决策过程模型,所述部分可观察马尔科夫决策过程模型的元素包括状态空间、动作空间和奖励函数;
[0010]
s2、基于多智能体深度确定性策略梯度将接收到的所述部分可观察马尔科夫决策过程模型的元素对应的数据逐轨道平面地对卫星的智能体进行集中式训练,直到所述智能体收敛,求得可行卫星对组成的最优匹配图集合使卫星网络函数效用最大化;
[0011]
s3、智能体根据同属一个卫星的状态收集器收集到的本地状态数据进行决策,并将决策指令传输给与该智能体同属一个卫星的链路执行器,所述链路执行器根据该智能体的决策指令与相应的卫星建立平面间星间链路。
[0012]
作为优化,所述状态空间为si={di,li,ri},其中,di为智能体i与视距范围内正向相邻轨道平面上的卫星的距离信息集合,li为智能体i在当前的正向星间链路连接的目标卫星,ri为智能体i当前正向星间链路的通信速率,其中,智能体的正向为:智能体所在卫星u靠近平面((p(u)+1)mod m)的一侧为正向,背离平面((p(u)+1)mod m)的一侧为负向,p(u)为卫星u所在的轨道平面,m为轨道平面的数量。
[0013]
作为优化,所述动作空间为ai={vi,k},其中,vi为智能体i视距范围内的正向相邻轨道平面上卫星,k为不执行任何动作;若智能体i选择了动作ai∈vi,即智能体i选择与卫星vi建立星间链路,则智能体i在智能体i的正向与动作ai对应的目标卫星建立平面间的星间链路;若智能体i的动作ai=k,则智能体i将不会建立正侧的星间链路。
[0014]
作为优化,所述奖励函数为
[0015]
其中na=n-nm,为智能体个数,n为卫星的总个数,nm为在第m个轨道平面上的卫星数量,ri为智能体i的贡献:
[0016][0017]
其中,αi为智能体i的决策冲突折扣因子,ai为智能体i的动作,ρ为单位通信速率的利润,λ为智能体i的单位天线转向角转向成本,为智能体i所在的卫星与ai对应的目标卫星之间的天线转向角,r
snr
(i,ai)为智能体i所在的卫星与ai对应的目标卫星之间通信的最大数据速率。
[0018]
作为优化,s2的具体训练方法为:
[0019]
s2.1、初始化一个经验回放池d用以存储状态转移数据;
[0020]
s2.2、从所述经验回放池中随机采样小批量(1024个)的状态转移数据,在每个决策时刻t结束时,更新智能体i的策略网络πi和价值网络直到智能体i的策
略网络πi和价值网络收敛,其中,na表示智能体个数,ai表示智能体i的动作,si表示智能体i的状态,为第na个智能体的动作,为第na个智能体的状态。
[0021]
作为优化,s2.1的具体实施步骤为:
[0022]
s2.1.1、初始化经验回放池;
[0023]
s2.1.2、在每个决策时刻t开始时,智能体i根据当前策略网络πi、当前状态s
i,t
={di,li,ri}和噪声,选择并执行一个动作a
i,t
,a
i,t
~πi(
·
|s
i,t
),同时,所述智能体i与相应的目标卫星建立星间链路;
[0024]
s2.1.3、在智能体i与相应的目标卫星之间建立星间链路之后,所述智能体i将当前状态s
i,t
转移至第二状态s
i,t+1
并获取到奖励数据r
i,t
,r
i,t
为智能体i在决策时刻t获得的奖励数据;
[0025]
s2.1.4、在状态转移完成后,以及奖励数据获取完成后,经验回放池记录状态转移(x
t
,x
t+1
,a
t
,r
t
),其中a
t
为智能体在决策时刻t的动作集合,r
t
为智能体在决策时刻t获得的奖励数据集合,x
t
为智能体在决策时刻t的状态数据集合,x
t+1
为智能体在决策时刻t+1的状态数据集合。
[0026]
作为优化,s2.2的具体实施步骤为:
[0027]
s2.2.1、在决策时刻t结束时,采用策略梯度法对智能体i的策略网络进行更新:目标值为:其中,是拥有延迟参数θ
′i的目标策略网络集合,j代表随机采样的状态转移编号,γ代表折扣率,na=n-nm为智能体的个数,该智能体所在的卫星在轨道平面m上,n为卫星的数量,nm为轨道平面m上拥有的卫星数量,为目标卫星的目标价值网络;分别为卫星1,...,na对应的动作数据;卫星i的奖励函数;
[0028]
s2.2.2、在决策时刻t结束时,通过最小化损失来更新智能体i的价值网络;
[0029]
其中,代表所有策略网络集合;
[0030]
s2.2.3、在决策时刻t结束时,利用策略梯度法更新智能体i的策略网络的权值:
[0031]
s2.2.4、更新目标网络的权值θ
′i:
[0032]
θ
′i←
βθi+(1-β)θ
′i;β为学习率;
[0033]
s2.2.5、重复s2.2.1-s2.2.4,直到智能体i的策略网络πi和价值网络收敛。
[0034]
作为优化,智能体i所在的卫星与ai对应的卫星之间的星座网络函数效用最大化表示为:
[0035]
[0036]
其中,为第n次决策的效用函数,ρ为单位通信速率的利润,λ为单位天线转向角转向成本,为卫星集,u为智能体i所在的卫星,v为ai对应的卫星,r
snr
(u,v)为可行卫星对uv之间的信噪比,nd为决策次数,为第n次决策的匹配图,即可行卫星对组成的星座,表示卫星在正负方向上的相邻顶点数量,为卫星u、v之间的边的天线转向角,e为可行卫星对集合。
[0037]
作为优化,智能体i所在的卫星与ai对应的目标卫星之间的转向角为:
[0038][0039]
其中,为智能体i所在的卫星的平均天线转向角,为ai对应的目标卫星的平均天线转向角,n为决策次数,为第n次决策时星座中所有平面间星间链路组成的匹配图,为n-1次决策时星座中所有平面间星间链路组成的匹配图。
[0040]
作为优化,智能体i所在的卫星和ai对应的目标卫星组成的可行卫星对集合为:
[0041][0042]
其中,l(iai)为智能体i所在的卫星与ai对应的目标卫星之间的视线距离;||iai||表示智能体i所在的卫星与ai对应的目标卫星之间的欧式距离;p(i)为智能体i所在的卫星所在的轨道平面,p(ai)为ai对应的目标卫星所在的轨道平面。
[0043]
本发明与现有技术相比,具有如下的优点和有益效果:
[0044]
1.本发明将卫星网络中的平面间星间链路的通信速率和天线切换成本函数效用化,天线切换成本在建立新的平面间星间链路产生,本发明能够在保证较高的星座总通信速率的前提下,减少天线切换带来的成本。
[0045]
2.本发明建立了一个部分可观察马尔可夫决策过程模型,并利用具有集中式训练和分布式执行范式的算法来训练智能体,同时设计了一个额外的惩罚机制(奖励函数中折扣冲突因子的设计),以引导整个星座在竞争和合作之间的良好权衡。
[0046]
3.本发明为了解决“维数诅咒”问题,加快算法的收敛速度,逐轨道平面地对智能体进行动态规划算法的训练。
附图说明
[0047]
为了更清楚地说明本发明示例性实施方式的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。在附图中:
[0048]
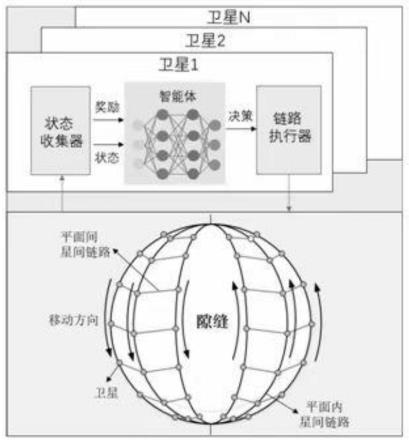
图1为卫星的星间链路拓扑和星间链路决策网络图。
具体实施方式
[0049]
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本
发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
[0050]
实施例
[0051]
在介绍本发明的基于多智能体强化学习的leo星间链路的动态规划方法之前,先介绍如下概念。
[0052]
如图1所示,本发明适用的星座为极轨星座。其中,n个卫星均匀分布在m个平面上。每个轨道平面m∈{1,2,...m}部署在给定的轨道高度hm,轨道倾角∈m,每个轨道平面由均匀分布的nm个卫星组成。此外,将卫星u在直角坐标系中的位置表示为{xu,yu,zu},并将p(u)定义为卫星u所在的轨道平面,p(u)∈{1,2,...,m}。一般地,每个卫星共有四个星间链路。两个平面内的星间链路连接来自同一平面的相邻卫星,而两个平面间星间链路连接来自不同平面的卫星。每个卫星都有一个星间链路的决策网络,在此决策网络中,位于卫星上的智能体通过接收到所有奖励数据和状态数据进行训练,直到此决策网络收敛。位于卫星上的状态收集器通过与环境中的其他卫星相互作用来获取状态数据和奖励数据,智能体根据状态收集器收集到的状态信息进行决策,位于卫星上的链路执行器根据智能体的指令与相应的卫星建立平面间星间链路。
[0053]
一、建立卫星之间的通信模型。
[0054]
假设决策周期td,决策次数nd=t/td,其中t为星座周期。在任意决策时刻,星座可以表示为无向图其中为顶点集,表示卫星,为边集合,表示星间链路。定义顶点v相对于顶点u的相对方向为:
[0055][0056]
并分别将相对于u正、负方向上的相邻顶点数量表示为和将一对源卫星u和目的卫星v称为卫星对uv,并将源卫星定义为标准卫星,目的卫星定义为目标卫星。
[0057]
由于多普勒效应和视线距离的限制,leo星座中某些卫星对之间无法建立平面间星间链路,如果一个卫星对之间可以建立一个平面间星间链路,则定义该卫星对为可行卫星对。下面,筛选出符合条件的卫星对集即可行卫星对集:
[0058]
将卫星对uc之间的欧式距离表示为:
[0059][0060]
xu、yu、zu分别为卫星u在x轴、y轴、z轴上的坐标;xv、yv、zv为卫星v在x轴、y轴、z轴上的坐标。
[0061]
若两个卫星之间的欧式距离大于它们之间的视线距离,则视线将受到地球的阻挡。定义卫星对uv之间的视线距离为l(uv),如果||uv||<l(uv),则该卫星对为可行卫星对。视线距离可以表示为:
[0062][0063]
其中,re表示地球半径,h
p(u)
为卫星u在轨道平面p(u)上的轨道高度,h
p(v)
为卫星v
在轨道平面p(v)上的轨道高度。
[0064]
第一个平面和第m个平面的卫星以相反的方向运动,具有很大的相对速度。在“隙缝”区域(图1中的缝隙)维护星间链路具有很大挑战性,因此不考虑建立隙缝区域星间链路。由于本发明的关注点为平面间星间链路,位于同一平面内的卫星对不是可行卫星对。根据以上分析,可行卫星对集合可以表示为:
[0065][0066]
卫星在自由空间环境中通信,因此,星间通信主要受到自由空间路径损耗(free-space path loss,fspl)和热噪声影响。对于可行卫星对,分析其特征如下:
[0067]
可行卫星对uv之间的自由空间路径损耗为:
[0068][0069]
其中,c为光速,f为载波频率,||uv||为卫星对uv之间的欧式距离。
[0070]
在任意时刻,可行卫星对uv之间的信噪比可以表示为:
[0071][0072]
其中,p
t
为发射功率,g
t
和gr分别为发射端天线增益和接收端天线增益,kb为玻尔兹曼常数,τ为热噪声,单位为开尔文,b为信道带宽,单位为赫兹。
[0073]
假设所有卫星都有足够窄的天线波束,并具有精确的波束对准能力。因此,卫星可以在无干扰的环境下进行通信。在无干扰环境下,卫星u与卫星v通信的最大数据速率为:
[0074]rsnr(u,v)
=blog2(1+snr(u,v))。
[0075]
二、建立切换成本模型
[0076]
卫星u的天线由对准卫星v1到对准卫星v2的天线转向角为:
[0077][0078]
为了度量平面间星间链路切换成本的影响,定义卫星u的平均天线转向角:
[0079][0080]
其中,和是分别是满足条件uv∈e的相对于卫星u正负方向上的卫星集合,和分别是集合和中的卫星数量,e为可行卫星对集合。
[0081]
对于第n次决策,将图中连接可行卫星对的所有边表示为
[0082]
对于图中的边,定义θ
uv
(n)为uv边的天线转向角:
[0083][0084]
为卫星u平均天线转向角,为卫星v平均天线转向角。
[0085]
为了在保证星座高吞吐量的前提下,最小化平面间星间链路的切换成本,本发明研究了在周期t内星座总通信速率和平面间星间链路的切换成本的联合优化问题。
[0086]
在每个决策时刻,都可以把建立平面间星间链路看作是一个匹配问题。对于第n次决策的匹配图将效用函数定义为可实现的通信利润减去切换成本,可以写成:
[0087][0088]
其中,ρ为单位通信速率的利润,λ为单位天线转向角转向成本。
[0089]
因此,优化问题是求出最优匹配图集合使卫星网络函数效用最大化,即:
[0090][0091]
其中,为第n次决策的效用函数,ρ为单位通信速率的利润,λ为单位天线转向角转向成本,为卫星集,u为智能体i所在的卫星,v为ai对应的卫星,r
snr
(u,v)为可行卫星对uv之间的信噪比,nd为决策次数,为第n次决策的匹配图,即可行卫星对组成的星座,表示卫星在正负方向上的相邻顶点数量,为卫星u、v之间的边的天线转向角,e为可行卫星对集合。
[0092]
接下来,介绍本发明所述的基于多智能体强化学习的leo星间链路的动态规划方法。
[0093]
s1、根据欧氏距离、视线距离、通信速率和天线切换成本设计部分可观察马尔科夫决策过程模型,所述部分可观察马尔科夫决策过程模型的元素包括状态空间、动作空间和奖励函数;
[0094]
为了解决“维数诅咒”问题,并对智能体逐轨道地进行训练,首先从卫星网络中选择智能体,并为它们设计合适的动作。在卫星u运动过程中,将其靠近平面((p(u)+1)mod m)的一侧定义为正向,另一侧定义为负向。每个卫星主动地决策正向星间链路,而负向星间链路被动地接受来自负向卫星的决策。由于“隙缝”的存在,第m个平面上的卫星无需主动决策正向isl。因此,除第m个平面上的卫星外,所有卫星都是独立的智能体。
[0095]
本实施例中,所述状态空间为si={di,li,ri},其中,di为智能体i与视距范围内正向相邻轨道平面上的卫星的距离信息集合,li为智能体i在当前的正向星间链路连接的目标卫星,ri为智能体i当前正向星间链路的通信速率,其中,智能体的正向为:智能体所在卫星u靠近平面((p(u)+1)mod m)的一侧为正向,背离平面((p(u)+1)mod m)的一侧为负向,p(u)为卫星u所在的轨道平面,m为轨道平面的数量。在不同的决策时刻中,由于卫星的运动,每个智能体的状态空间是时变的。
[0096]
本实施例中,所述动作空间为ai={vi,k},其中,vi为智能体i视距范围内的正向相邻轨道平面上卫星,k为不执行任何动作;若智能体i选择了动作ai∈vi,即智能体i选择与卫星vi建立星间链路,则智能体i在智能体i的正向与动作ai对应的目标卫星建立平面间的星间链路;若智能体i的动作ai=k,则智能体i将不会建立正侧的星间链路。
[0097]
本实施例中,所述奖励函数为
[0098]
其中na=n-nm,为智能体个数,n为卫星的总个数,nm为在第m个轨道平面上的卫星数量,ri为智能体i的贡献:
[0099][0100]
其中,αi为智能体i的决策冲突折扣因子,ai为智能体i的动作,ρ为单位通信速率的利润,λ为智能体i的单位天线转向角转向成本,为智能体i所在的卫星与ai对应的目标卫星之间的天线转向角,r
snr
(i,ai)为智能体i所在的卫星与ai对应的目标卫星之间通信的最大数据速率。由于每个智能体都是根据自己的部分观测信息独立做出决策,所以同一轨道平面上的智能体可能选择了相同的目标卫星,造成了冲突。因此,设计了一个训练器,根据所有智能体的部分观测信息和动作,重新评估每个智能体的贡献。即与其他智能体无冲突的智能体的决策冲突折扣因子αi=1,而与其他智能体有冲突的智能体的决策冲突折扣因子设计如下:根据目标卫星的不同,将所有的智能体添加到不同的列表中,对于每个智能体i,如果其与目标卫星建立的平面间星间链路的通信速率大于列表中其他智能体与该目标卫星建立的平面间星间链路的通信速率,则αi=0.8,否则αi=0.1。
[0101]
s2、基于多智能体深度确定性策略梯度将接收到的所述部分可观察马尔科夫决策过程模型的元素对应的数据逐轨道平面地对卫星的智能体进行集中式训练,直到所述智能体收敛,求得可行卫星对组成的最优匹配图集合使卫星网络函数效用最大化。
[0102]
本发明提出的星间链路动态规划方法是基于多智能体深度确定性策略梯度(maddpg)的。maddpg采用集中式训练,分布式执行的范式。因此,训练收敛后,每个智能体可以根据自己的部分观测独立做出决策。
[0103]
每个智能体i都有自己的策略网络πi,策略网络πi的权值为θi,该策略网络πi能够通过gumbel-softmax分布产生可微分样本。每个智能体i有一个价值网络其中除此之外,每个智能体i有一个相应的目标策略网络π
′i和目标价值网络
[0104]
本实施例中,s2的具体训练方法为:
[0105]
s2.1、初始化一个经验回放池d用以存储状态转移数据;
[0106]
s2.2、从所述经验回放池中随机采样小批量(1024个)的状态转移数据,在每个决策时刻t结束时,更新智能体i的策略网络πi和价值网络直到智能体i的策略网络πi和价值网络收敛,其中,na表示智能体个数,ai表示智能体i的动作,si表示智能体i的状态,为第na个智能体的动作,为第na个智能体的状态。
[0107]
本实施例中,s2.1的具体实施步骤为:
[0108]
s2.1.1、初始化经验回放池;
[0109]
s2.1.2、在每个决策时刻t开始时,智能体i基于当前策略网络πi、智能体i的当前状态s
i,t
={di,li,ri}和噪声,智能体i选择并执行一个动作a
i,t
,a
i,t
~πi(
·
|s
i,t
),同时,所述智能体i与相应的目标卫星建立星间链路;
[0110]
s2.1.3、在智能体i与相应的目标卫星之间建立星间链路之后,所述智能体i将当前状态s
i,t
转移至第二状态s
i,t+1
并获取到奖励数据r
i,t
,r
i,t
为智能体i在决策时刻t获得的奖励数据;
[0111]
s2.1.4、在状态转移完成后,以及奖励数据获取完成后,即在获取到所有信息后,经验回放池将会记录状态转移(x
t
,x
t+1
,a
t
,r
t
),其中a
t
为智能体在决策时刻t的动作集合,r
t
为智能体在决策时刻t获得的奖励数据集合,x
t
为智能体在决策时刻t的状态数据集合,x
t+1
为智能体在决策时刻t+1的状态数据集合。
[0112]
本实施例中,s2.2的具体实施步骤为:
[0113]
s2.2.1、在决策时刻t结束时,采用策略梯度法对智能体i的策略网络进行更新,其中目标值为中目标值为其中,是拥有延迟参数θ
′i的目标策略网络集合,j代表随机采样的状态转移编号,γ代表折扣率,na=n-nm为智能体的个数,该智能体所在的卫星在轨道平面m上,n为卫星的数量,nm为轨道平面m上拥有的卫星数量,为目标卫星的目标价值网络;为目标卫星对应的动作数据;为目标卫星的奖励函数;
[0114]
s2.2.2、在决策时刻t结束时,通过最小化损失来更新智能体i的价值网络;
[0115]
其中,代表所有策略网络集合。
[0116]
s2.2.3、在决策时刻t结束时,利用策略梯度法更新智能体i的策略网络的权值:
[0117]
s2.2.4、更新目标网络的权值θ
′i:
[0118]
θ
′i←
βθi+(1-β)θ
′i;β为学习率;
[0119]
s2.2.5、重复s2.2.1-s2.2.4,直到智能体i的策略网络πi和价值网络收敛,得到智能体i所在的卫星与其他卫星之间的最优匹配链路,若干最优匹配链路组成了最优匹配图,即最优匹配星座网络,每个决策时刻的最优匹配图组合起来形成最优匹配图集合判断智能体是否收敛的具体方式为:奖励函数停止更新增长,维持在一个恒定的范围。
[0120]
本实施例中,智能体i所在的卫星与ai对应的卫星之间通信的最大数据速率r
snr
(i,ai)为:
[0121][0122]
其中,b为信道带宽,单位为赫兹,snr(i,ai)为智能体i所在的卫星与ai对应的目标卫星之间的信噪比。
[0123]
本实施例中,智能体i所在的卫星与ai对应的目标卫星之间的转向角为:
[0124]
[0125]
其中,为智能体i所在的卫星的平均天线转向角,为ai对应的目标卫星的平均天线转向角,n为决策次数,为第n次决策时星座中所有平面间星间链路组成的匹配图,为n-1次决策时星座中所有平面间星间链路组成的匹配图。
[0126]
本实施例中,智能体i所在的卫星和ai对应的目标卫星组成的可行卫星对集合为:
[0127][0128]
其中,l(iai)为智能体i所在的卫星与ai对应的目标卫星之间的视线距离;||iai||表示智能体i所在的卫星与ai对应的目标卫星之间的欧式距离;p(i)为智能体i所在的卫星所在的轨道平面,p(ai)为ai对应的目标卫星所在的轨道平面。
[0129]
s3、智能体根据与智能体根据同属一个卫星的状态收集器收集到的本地状态数据进行决策,并将决策指令传输给与该智能体同属一个卫星的链路执行器,所述链路执行器根据该智能体的决策指令与相应的卫星建立平面间星间链路。
[0130]
本发明提出的一种基于多智能体强化学习的leo星间链路的动态规划方法,该方法联合优化了leo星座的总吞吐量和平面间星间链路的切换成本,研究了以最大期望折扣回报为目标的优化问题。基于目标网络和经验回放池,基于多智能体深度强化学习的星间链路规划算法能够有效地学习最优策略,每个卫星可以分布式地决策平面间链路。实验结果表明,与基线算法相比,本发明提出的方法具有更好的性能。大量的实验结果表明,本发明提出的算法可以显著降低isls切换率,提高星座总吞吐量和卫星平均isl数量。
[0131]
文献[1]为o.popescu,“power budgets for cubesat radios to support ground communications and inter-satellite links,”ieee access,vol.5,pp.12 618
–
12 625,2017.
[0132]
文献[2]为y.lee and j.p.choi,“connectivity analysis of mega constellation satellite networks with optical inter-satellite links,”ieee transactions on aerospace and electronic systems,pp.1
–
1,2021.
[0133]
文献[3]为i.leyva-mayorga,b.soret,and p.popovski,“inter-plane inter-satellite connectivity in dense leo constellations,”ieee transactions on wireless communications,vol.20,no.6,pp.3430
–
3443,2021.
[0134]
文献[4]为w.chengzhuo,l.suyang,g.xiye,and y.jun,“dynamic optimization of laser inter-satellite link network topology based on genetic algorithm,”in 2019 14th ieee international conference on electronic measurement&instruments(icemi).ieee,2019,pp.1331
–
1342.
[0135]
文献[5]为s.liu,j.yang,x.guo,and l.sun,“inter-satellite link assignment for the laser/radio hybrid network in navigation satellite systems,”gps solutions,vol.24,no.2,pp.1
–
14,2020.
[0136]
文献[6]为z.yan,g.gu,k.zhao,q.wang,g.li,x.nie,h.yang,and s.du,“integer linear programming based topology design for gnsss with intersatellite links,”ieee wireless communications letters,vol.10,no.2,pp.286
–
290,2020.
[0137]
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明
的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1