一种VANET网络自适应路由协议选择方法、计算机程序产品
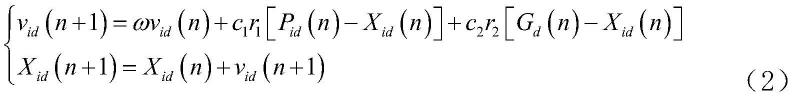
一种vanet网络自适应路由协议选择方法、计算机程序产品
技术领域
1.本发明属于一种路由协议选择方法,具体涉及一种vanet网络自适应路由协议选择方法、计算机程序产品。
背景技术:
2.目前,智能交通和网联车已经成为信息技术和实体经济深度融合的先行者。车辆自组织网络(vehicular ad-hoc network,vanet),是针对交通场景提出的一种自组织网络,主要被用来为车辆及路边单元提供数据通信的相关服务,是智能交通中不可缺少的重要组成部分,同时,也是解决交通安全性差、道路通行率低、驾驶体验度差等问题的有效途径。随着智能交通的发展,对vanet相关技术的要求也愈加严格。如何支持vanet中海量的数据传输,以及如何为车辆间通信提供更可靠的保障已经成为当前vanet面临的最大挑战。
3.在vanet网络的连通性技术中,路由技术是最为关键的一部分。其中,难点在于如何很好地处理vanet网络中一系列对通信质量影响较大的问题,比如链路寿命短、节点移动性高,环境中阻碍多等。目前的路由协议缺少对于网络环境的感知能力,特别是在网络整体的拓扑变化复杂时,无法及时根据网络环境的变化情况对路由信息进行自适应调整。为了应对该特点给vanet网络中路由带来的不良影响,研究人员不断地提出一些自适应方法,期望可以通过给路由协议赋予自适应能力来解决该问题,现有的路由协议自适应技术主要是针对现有路由协议中的参数进行自适应参数调整,首先对传统路由协议的性能进行对比仿真,然后提出一个用于评估动态源路由协议(dynamic source routing,dsr)和目的节点序列距离矢量路由协议(destination sequenced distance-vector,dsdv)性能的效用函数,通过计算路由协议的效用值,结合先验知识构建路由协议策略库,确定不同网络情景区间的最优路由协议。
4.但是,这种针对现有路由协议中的参数进行自适应参数调整的路由协议自适应技术,还存在诸多不足:(1)效用函数固定,且仅能在两种路由协议中进行选择,适用范围有限;(2)路由协议未进行自适应处理,在协议中的参数多采用固定值,无法满足vanet网络场景,实现全局自适应;(3)效用函数对于其他协议的适用性较低,将其中的路由协议替换为其他路由协议,准确率就会大大降低,在实际使用中局限性较大。
技术实现要素:
5.本发明为解决目前针对现有路由协议中的参数进行自适应参数调整的路由协议自适应技术,存在适用范围有限、无法实现全局自适应、对于其他协议的适用性较低的技术问题,提供一种vanet网络自适应路由协议选择方法、计算机程序产品。
6.为达到上述目的,本发明采用以下技术方案予以实现:
7.一种vanet网络自适应路由协议选择方法,其特殊之处在于,包括以下步骤:
8.s1,通过遗传粒子群算法对自适应模糊神经推理系统中的参数进行优化,得到优化后的自适应模糊神经推理系统;
9.s2,对当前vanet网络中的节点移动速度和网络规模进行感知,将感知结果和各待用协议的数据集,输入至优化后的自适应模糊神经推理系统;
10.s3,所述优化后的自适应模糊神经推理系统根据各待用协议的策略库,对相应待用协议在当前网络环境中的多个性能指标进行推理预测,得到与各性能指标相对应推理的性能值;
11.s4,将所述推理的性能值代入相应效用值函数,得到与各性能指标对应的效用值;
12.s5,根据各待用协议的业务需求,确定与业务需求对应的目标函数,结合与各性能指标对应的效用值,得到各待用协议在当前vanet网络环境下针对相应业务需求的目标函数值;
13.s6,选择最大的目标函数值对应的待用协议,作为当前vanet网络的路由协议。
14.进一步地,步骤s1之前还包括步骤s0,自适应参数调整:
15.根据当前网络中邻居节点的变化率r和当前网络的业务负载l,调整路由更新周期t和自适应因素的检测间隔δt。
16.进一步地,为了使现有路由协议性与多变的vanet网络场景更加适配,实现网络性能大的提升,本发明可以先对路由协议中的参数进行调整,具体可采用以下调整方法,步骤s0具体为:
17.s0.1,比较变化率r和当前网络中最大的邻居节点变化率r
max
,若r>r
max
,减小路由更新周期t,执行步骤s0.3;若r<r
max
,增大路由更新周期t,执行步骤s0.2;
18.s0.2,比较路由更新周期t和最大更新周期t
max
,若t>t
max
,使t=t
max
;若t<t
max
,执行步骤s1.3;
19.s0.3,比较业务负载l和目前网络mac层接口队列的最大缓存长度l
max
,若l<l
max
,减小自适应因素的检测间隔δt,若l>l
max
,增大自适应因素的检测间隔δt。
20.进一步地,由于单独使用遗传算法或粒子群算法对自适应模糊神经推理系统进行优化,就无法实现在全局搜索能力以及计算效率上都占有优势。本发明采用了一种遗传粒子群算法对自适应模糊神经推理系统进行优化,步骤s1具体为:
21.s1.1,对自适应模糊神经推理系统的参数进行初始化;
22.s1.2,在空间中,根据自适应模糊神经推理系统的参数范围,随机生成m个粒子,组成粒子集群,粒子集群中每个粒子都具有随机的初始参数;其中,m为大于等于2的整数;
23.s1.3,通过下式计算每个粒子的适应度值:
[0024][0025]
其中,为第i个粒子的适应度值,为第i个粒子第j个预测数值经自适应模糊神经推理系统的输出值,为第i个粒子第j个预测数值对应的实际值,n为预测数值的数目;
[0026]
s1.4,比较和第i个粒子当前的个体最优值p
best-i
,若则用p
best-i
替换否则,保留
[0027]
s1.5,比较所有粒子当前的个体最优值p
best-i
,得到其中的最大值,作为全局最优
解g
best
;
[0028]
s1.6,对各粒子当前的位置和速度进行修正,并对每个粒子的最大移动范围p
max
和最大移动速度v
max
进行限制;
[0029]
s1.7,根据当前各粒子的适应度值对各粒子进行排序;
[0030]
s1.8,对各粒子进行筛选,使粒子集群中前一半粒子进入下一代,并对后一半粒子依次执行遗传算法中的选择、交叉和变异操作,得到优选的粒子;
[0031]
s1.9,将所述优选的粒子与步骤s1.8中进入下一代的粒子进行合并,得到新的粒子集群;
[0032]
s1.10,计算新的粒子集群的个体最优值,并确定新的粒子集群的全局最优解;
[0033]
s1.11,若s1.10得到的全局最优解未达到预设目标,重复执行步骤s1.5至步骤s1.10,直至全局最优解未达到预设目标,或达到最大迭代次数,完成优化,得到优化后的自适应模糊神经推理系统。
[0034]
进一步地,为了保证个体种群多样性并且避免搜索过程过于缓慢,步骤s1.8中,所述遗传算法中的pc和pm分别设置为0.9和0.01。
[0035]
进一步地,步骤s3中,所述多个性能指标包括吞吐量、平均端到端时延和丢包率。
[0036]
进一步地,步骤s4中,所述效用值函数为:
[0037]
对于性能指标中的正指标,效用值函数为:
[0038][0039]
其中,fi为第i项性能指标的实际值对应的效用值,a为效用值函数的第一待定参数,b为效用值函数的第二待定参数,xi为第i项性能指标的实际值,x
i0
为第i项性能指标的平均值,x
iu
为第i项性能指标的最大值;
[0040]
对于性能指标中的逆指标,效用值函数为:
[0041][0042]
其中,x
il
为第i项性能指标的最小值。
[0043]
进一步地,步骤s5中,所述根据各待用协议的业务需求,确定与业务需求对应的目标函数,具体为:
[0044]
s5.a.1,确定目标函数的形式:
[0045]
f=α*throughput+β*averagedelay+γ*packetlossrate,α+β+γ=1
[0046]
其中,f为目标函数值,throughput为吞吐量的效用值,averagedelay为平均端到端时延的效用值,packetlossrate为丢包率的效用值,α为吞吐量的权重,β为平均端到端时延的权重,γ为丢包率的权重;
[0047]
s5.a.2,根据各待用协议的业务需求,确定各业务需求对应目标函数中各性能指标的权重:
[0048]
对于无偏好业务,
[0049]
对于实时性偏好业务和可靠性偏好业务,
[0050]
进一步地,步骤s4中,所述a取值为40,所述b取值为ln2.5。
[0051]
本发明还提供了一种计算机程序产品,包括计算机程序,其特殊之处在于,该程序被处理器执行时实现上述一种vanet网络自适应路由协议选择方法的步骤。
[0052]
与现有技术相比,本发明具有以下有益效果:
[0053]
1.本发明一种vanet网络自适应路由协议选择方法,采用改进后的自适应模糊神经系统,根据不同路由协议在各种网络场景中的表现进行路由协议效用值推理,该系统通过对路由策略知识库进行学习,实现效用值的推理输出。由于vanet网络场景多变,因此,固定的效用函数在场景变化较大时并不适用,而本发明中所使用的自适应模糊神经推理系统,本身就适用于一些无法通过数学进行准确建模的问题,由该系统进行效用值推理不仅准确性更高,而且较以往的效用函数灵活性更好。
[0054]
2.本发明对已有的自适应模糊神经推理系统进行了改进,针对自适应模糊神经推理系统算法结构参数复杂的问题,进一步提出了改进后的gapso-anfis算法。在改进过程中通过粒子群算法对anfis参数进行了寻优,同时,还结合遗传算法中的交叉、变异等操作,进一步避免了粒子群算法早熟的问题,提高了anfis算法的准确性。
[0055]
3.本发明中对现有的路由协议中的固定参数也进行了调整,通过调节参数使现有性能与多变的vanet场景更加适配,从而实现了网络性能的提升。
[0056]
4.本发明还提供了一种能够执行上述方法步骤的计算机程序产品,便于将本发明的方法推广应用,在相应的硬件设备上实现融合。
附图说明
[0057]
图1为本发明一种vanet网络自适应路由协议选择方法实施例中自适应参数调整的流程示意图;
[0058]
图2为本发明实例中自适应参数调整后的aodv与传统aodv的丢包率和时延对比图;其中,(a)为自适应参数调整后的aodv与传统aodv平均端到端时延随速度变化的对比图,(b)为自适应参数调整后的aodv与传统aodv丢包率随速度变化的对比图,(c)为自适应参数调整后的aodv与传统aodv丢包率随节点数目变化的对比图;
[0059]
图3为本发明一种vanet网络自适应路由协议选择方法实施例中自适应最优路由协议选择方案的流程示意图;
[0060]
图4为本发明实施例中吞吐量对应的效用值函数示意图;其中,(a)为采用传统anfis算法得到的预测输出与实际输出的对比图,(b)为采用本发明算法得到的预测输出与实际输出的对比图;
[0061]
图5为本发明实施例中平均端到端时延对应的效用值函数示意图;
[0062]
图6为本发明实施例中丢包率对应的效用值函数示意图。
[0063]
图7为本发明中gapso-anfis算法和传统anfis算法与实际输出的对比图。
具体实施方式
[0064]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
[0065]
本发明提出一种vanet网络自适应路由协议选择方法主要包括两部分,第一部分是关于路由协议自身参数调整方面的自适应,第二部分是使用改进后的自适应模糊神经推理系统进行自适应最优路由协议选择。
[0066]
(1)路由协议中参数的自适应调整
[0067]
典型的vanet路由协议在进行路由协议选择时,没有将节点速度等因素考虑进去,导致路由协议在vanet网络中自适应能力不足。因此,本发明针对典型路由协议中的参数,提出了自适应调节的方法,可以帮助路由协议更快地适应环境的变化,提高网络稳定性。
[0068]
(2)根据网络场景进行自适应最优路由协议的选取
[0069]
不同的vanet路由协议适用于不同的网络环境,因此,需要根据当前的网络状态选取合适的路由协议。如果可以获得任意网络场景中不同路由协议的性能表现,就可以得到任意用户需求下的最优路由协议,因此,本发明首先通过现实场景交通模型得到在不同vanet场景下各路由协议的性能,然后组成策略知识库,通过使用自适应模糊神经推理系统对其进行学习推理,实现在任意vanet场景下都可以准确得到最优路由协议。
[0070]
关于第一部分:现有路由协议的自适应参数调整方案
[0071]
如下以按需距离矢量路由协议(ad hoc on-demand distance vector,aodv)为例,对本发明中的参数调整方案进行说明。
[0072]
针对aodv中路由更新阶段缺乏自适应能力、路由维护阶段链路易断裂的缺点,本发明在aodv的路由更新过程中加入了自适应参数调整机制,提出了一种自适应方法a-aodv(adaptive ad hoc on-demand distance vector,aodv)。在a-aodv中,网络路由的更新周期可以根据节点所处的网络状态决定。实现方式就是通过当前网络的拓扑变化情况以及网络负载情况对其路由更新周期进行调整。
[0073]
具体的,如图1所示,首先,获取当前网络中邻居节点的变化率r和当前网络的业务负载l,然后将r和当前网络中最大的邻居节点变化率r
max
进行对比,若r>r
max
,则说明当前网络拓扑变化剧烈,链路失效频繁,需要更频繁的更新路由,减小路由更新周期t。其次,也需要对当前网络的业务负载l进行判断,如果当前节点的业务负载l小于目前网络mac层接口队列的最大缓存长度l
max
,说明目前网络中整体的负载水平不高,可以将自适应因素的检测间隔δt减小,以便及时了解网络状况。相反,如果l大于l
max
,则说明当前的网络负载略高,因此,对δt进行增大,以避免负载过大导致的链路断裂。如果r小于r
max
,则此时网络状态相对较为稳定,不需要频繁的发送hello消息,因此,可以将t适当增加,节省网络开销。增加后,若t>t
max
,使t=t
max
,若t<t
max
,还需要对当前的网络的业务负载l进行判断,从而调整检测间隔。
[0074]
本发明对aodv和本发明所提出的算法在实际道路场景模型中进行了多次仿真,通过分析不同场景下两种路由协议的性能指标,对aodv和改进后的自适应方法进行了对比,对比结果如图2所示。从图2可以看出,改进后的aodv由于拥有自适应机制以及备用路由,因此,在各种场景下时延和丢包率都相对表现较好。
[0075]
上述是以aodv为例对本发明中的自适应参数调整方案进行说明,对于其他协议,也可采用相同的方法进行自适应参数调整。
[0076]
关于第二部分,自适应最优路由协议选择方案
[0077]
想要根据不同网络环境得到各路由协议的性能,就需要通过改进后的自适应模糊
神经推理系统——gapso-anfis(genetic algorithm and particle swarm optimization-adaptive neural-network-based fuzzy inference system)推理实现。具体的实现流程如图3所示。
[0078]
首先,由网络情景感知模块对当前vanet网络中的节点移动速度和网络规模进行感知,并将感知结果以及相应协议的数据集作为输入传递给gapso-anfis推理系统。然后,由gapso-anfis推理系统根据不同路由协议的策略库对该协议在当前网络环境中的三种性能指标进行推理预测,在得到推理的性能值之后,再将该性能值代入效用值函数中,将得到的值与不同用户需求下的目标函数相结合,就可以得到三种路由协议(本实施例中,以三种路由协议为例,该三种路由协议分别为a-aodv、dsdv和dsr)在当前环境下针对于该用户需求的效用值,然后选择效用值最大的路由协议,就可以实现最优路由协议的选取。上述的三种性能指标为吞吐量、平均端到端时延和丢包率,在本发明的其他实施例中,也可以是其他性能指标,或包含该三种性能指标的更多性能指标。
[0079]
如下是对该方案的具体说明。
[0080]
anfis算法中,通常采用最小二乘法和梯度下降法进行算法参数的寻优,但是这些方法往往速度较慢且易得到局部最优值。本发明使用遗传粒子群算法进行anfis的参数优化,由于粒子群算法对anfis参数优化是本发明中遗传粒子群算法实现的基础,因此,首先对粒子群算法优化anfis寻参的实现思想进行介绍:
[0081]
第1步:对粒子群进行初始化,n代表的是迭代次数,将其设为1,并在所给的参数范围中生成m个粒子,其中每个粒子都会拥有初始的位置值和速度值,分别是和其中,1≤i≤m,1≤d≤d,d在寻优过程中,指的是anfis中前提参数的个数,即当前搜索空间的维数;
[0082]
第2步:每一个所生成的粒子,都是一组anfis的前提参数,根据实际输出和所得到的估计输出,可以通过公式(1)计算出该粒子的适应度值,也就是在该前提参数下anfis的均方根误差值:
[0083][0084]
第3步:对于粒子i,首先需要判断自身适应度值是否小于个体最优值,如果则并使个体最优位置执行第4步,否则,执行第5步;
[0085]
第4步:判断该适应度值是否小于全局最优解gbesti,如果则并使全局最优位置
[0086]
第5步:根据公式(2)更新粒子的速度和位置,并使n=n+1;
[0087][0088]
式(2)中各参数的含义与pso(粒子群)算法中相同,粒子群算法参数含义表1所示。该算法仅依靠粒子群对anfis的前提参数进行寻优,使anfis算法能够更简单快速的实现对自身参数的调整,但是由于在该算法中各个粒子之间互不影响,很容易使当前的求解局限
在某一个位置,产生早熟现象。
[0089]
表1 pso算法参数含义表
[0090][0091]
另外,遗传算法拥有选择、交叉和变异等操作,所以在全局搜索中拥有更明显的优势,遗传算法是通过择优之后再进行交叉变异,整个种群会向全局最优解均匀移动,同时,遗传操作也会保障粒子的多样性。而粒子群则在对以往搜索经验的学习上具有明显优势,因为遗传算法不具有记忆能力,而粒子群算法中的每个粒子都可以通过学习之前的经验,保存所有粒子的最优解,这样可以避免盲目搜索。
[0092]
以上两种算法,如果仅选择其中一种进行参数优化,就无法实现在全局搜索能力以及计算效率上都占有优势。因此,本发明提出一种优势互补后的混合算法,对anfis进行参数寻优,增强了全局寻优能力,提高了系统准确性,混合后的算法与anfis的输出对比如图4所示。由图4中的(b)可以看出,混合算法gapso-anfis给出的预测输出与实际输出几乎重合,而图(a)中传统anfis给出的预测输出则与实际输出差距相对较大,说明本专利中提出的混合算法预测能力较传统的anfis算法具有明显提升。
[0093]
本发明采用如下方法(遗传粒子群算法)对自适应模糊神经推理系统进行优化:在每一次迭代完成并计算出适应度值之后,都会按照粒子的优劣进行排序,将排序属于前半部分的粒子直接用于下一代。然后对剩下的一半粒子进行遗传算法进化,将进化后的粒子与后半部分粒子进行排序,再次选出一部分较优的粒子与前一半粒子结合起来形成新的粒子群,并继续下一步运算,具体地:
[0094]
第1步:对种群的规模即粒子数m、粒子运动最大速度v
max
、最大迭代次数参数t等参数进行初始化;
[0095]
第2步:在空间中,根据anfis的参数范围随机生成m个粒子,其中每个粒子都拥有
随机的初始参数,比如位置和速度其中,1≤i≤m,1≤d≤d,d在本次寻优过程中,指的是anfis中前提参数的个数,即当前搜索空间的维数;
[0096]
第3步:按照该优化问题对应的适应度函数计算每个粒子的适应度值,适应度值由公式(12)可得;
[0097][0098]
中,为第i个粒子的适应度值,yj为第i个粒子第j个预测数值经自适应模糊神经推理系统的输出值,y
dj
为第i个粒子第j个预测数值对应的实际值,n为预测数值的数目;
[0099]
第4步:判断当前适应度值是否小于之前的个体最优值p
best-i
,若小于之前的p
best-i
,则代表该粒子更优,可以使用该粒子对之前的个体最优值进行替换,同时对将该粒子的p
best-i
与其他粒子的p
best-i
进行对比,选出g
best
;
[0100]
第5步:对粒子当前的位置以及速度进行修正,并对每个粒子的最大移动范围p
max
和最大移动速度v
max
进行限制;
[0101]
第6步:计算当前粒子所对应的适应度值,并根据所得到的数值对粒子种群进行排序;
[0102]
第7步:对粒子种群进行筛选,选出较优的前一半粒子进入下一代,然后对后一半粒子执行ga算法(遗传算法)中的选择、交叉、变异等操作,在解决本问题时,为了保证个体种群多样性并且避免搜索过程过于缓慢,将pc和pm分别设为0.9和0.01;
[0103]
第8步:在ga算法操作之后,得到较优的粒子,将其与上一步选出的粒子进行合并,产生新的粒子集群;
[0104]
第9步:重新计算当前粒子群中的p
best-i
和g
best
;
[0105]
第10步:判断当前得到的最优解是否达到目标,或是否达到最大迭代次数,若是则转到第11步,否则对其迭代次数加1并转至第5步;
[0106]
第11步:得到anfis最优参数值,使用测试数据集进行测试。
[0107]
以效用理论为基础,效用函数可以被用来对数据通信业务的相关特性进行解释。数据通信中的场景特性有吞吐量、平均端到端时延以及丢包率,不同的vanet应用类型对于三者有着不同的需求。比如,语音和视频业务允许少量数据内容的丢失,但是对延时要求较高。为了更好的反映用户的业务需求,本发明对各种vanet网络的应用业务采用了多指标综合评价。多指标综合评价指的是对各个评价指标采用相同的量化方法进行量化,从而得到问题的“量化值”,之后再通过选定模型对量化值加权综合,得到总的评价值。在本发明中使用了公式(3)和公式(4)所示的效用值函数,通过非线性计分方法对各指标进行同度量化:
[0108][0109][0110]
其中,公式(3)针对的是非线性记分方法在评价正指标时的效用值函数,公式(4)为用来评价逆指标的效用值函数。公式(3)和公式(4)中,fi为第i项性能指标的实际值对应的效用值,x
i0
为第i项性能指标的平均值,代表了数据平均水平,x
iu
为第i项性能指标的最大值,x
il
为第i项性能指标的最小值,(该处最大值和最小值可统一用“最好值”x
im
代表。对
于正指标x
im
=x
iu
,对于逆指标x
im
=x
il
。其中,a、b均为待定参数,在本实施例中,a取值为40,b取值为ln2.5。由此,xi为第i项性能指标当前的实际值,可得到吞吐量、平均端到端时延和丢包率的具体效用值函数。
[0111]
①
吞吐量
[0112]
由于吞吐量是正指标,因此,需要给出三种路由协议吞吐量的平均值和最大值。例如,当吞吐量指标的最大值为720kb/s,最小值为387kb/s时,可以将该指标的最大值x
iu
和平均值x
i0
分别设为720和554,则该吞吐量指标的效用值函数为公式(5)所示。
[0113][0114]
吞吐量对应的效用值函数可用图5表示。从图5中可以看到,吞吐量的指标值与其同度量化后的效用值成正比。当吞吐量指标值为原始数据中的最大值时,其效用值为100;当吞吐量指标值为原始数据中的最小值时,其效用值降为最低。
[0115]
②
平均端到端时延
[0116]
由于端到端时延是逆指标,因此,需要给出三种路由协议平均端到端时延的平均值和最小值。当平均端到端时延指标的最大值为2.4,最小值为0.15时,可以将该指标的平均值x
i0
和最小值x
il
分别设为1.28和0.15,该平均端到端时延指标的效用值函数见公式(6)。
[0117][0118]
平均端到端时延对应的效用值函数可用图6表示。从图6中可以看到,平均端到端时延的指标值与其同度量化后的效用值成反比。当时延指标值为原始数据中的最小值时,其效用值为100;当时延指标值为原始数据中的最大值时,其效用值降为最低。
[0119]
③
丢包率
[0120]
由于丢包率是逆指标,因此,需要给出三种路由协议丢包率的平均值和最小值。当仿真过程中得到的丢包率指标最大值为7.9,最小值为0.8时,可以将该指标的平均值x
i0
和最小值x
il
分别设为4.35和0.8,该指标的效用值函数见公式(7)。
[0121][0122]
丢包率对应的效用值函数可用图7表示。从图7中可以看到,丢包率的指标值与其同度量化后的效用值成反比。当丢包率指标值为原始数据中的最小值时,其效用值为100;当丢包率指标值为原始数据中的最大值时,其效用值降为最低。
[0123]
最优路由协议选择的工作流程整体为:首先,由策略知识库得到各路由协议的性能指标值;然后利用上述方法得到的效用函数得到各路由协议的效用值;最后,将这些效用值代入目标函数中,就可以计算出个路由协议的目标函数值。在某一网络场景下具有最大目标函数值的路由协议即为该场景下的最优路由协议。
[0124]
完成各指标的同度量化工作后,还需要利用适当的目标函数来拟合各指标的效用函数值。目标函数需要根据用户需求进行选取。在确定目标函数时,常用的合成模型是算术加权平均模型,即根据用户需求分配各指标的权重,然后加权求和,本发明中5目标函数的形式见公式(8)。
[0125]
f=α*throughput+β*averagedelay+γ*packetlossrate,α+β+γ=1(8)
[0126]
其中,throughput、averagedelay和packetlossrate分别是吞吐量、平均端到端时延和丢包率的效用函数值,通过前述的效用值函数计算得到,α,β,γ分别代表的是三种性能指标的权重系数。权重系数的值可以根据用户的应用需求进行定义,但是三种性能指标的效用函数值权重之和必须为1。
[0127]
如下针对三种常见业务进行具体说明,对于其他业务也可采用类似方式确定目标函数。
[0128]
(1)无偏好业务
[0129]
在vanet网络中进行无偏好的应用业务时,目标函数如公式(9):
[0130]
f=1/3*throughput+1/3*averagedelay+1/3*packetlossrate(9)
[0131]
(2)实时性偏好业务
[0132]
在vanet网络中进行偏好于实时性的应用业务时,目标函数如公式(10):
[0133]
f=1/2*averagedelay+1/4*throughput+1/4*packetlossrate(10)
[0134]
(3)可靠性偏好业务
[0135]
在vanet网络中进行可靠性的应用业务时,目标函数如公式(11):
[0136]
f=1/2*packetlossrate+1/4*throughput+1/4*averagedelay(11)
[0137]
通过公式(9)至公式(11),可以得到每一种路由协议在不同网络场景中不同业务需求所对应的效用值,最优路由协议选择,指的就是通过gapso-anfis算法根据当前网络环境和当前应用场景,对于每一种路由协议的吞吐量、平均端到端时延、丢包率等性能指标进行推理,然后将得到的性能指标分别代入其对应的效用函数中,最后针对不同的目标函数选择效用值最大的路由协议。
[0138]
另外,本发明上述的vanet网络自适应路由协议选择方法还可以形成一种计算机程序产品,具体可在计算机可读存储介质或计算机设备上执行,将本发明的方法形成一种能够搭载于设备上执行的硬件产品,便于应用推广。
[0139]
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1