一种基于IHHO-FCM算法的网络流量分类方法
一种基于ihho-fcm算法的网络流量分类方法
技术领域
1.本发明涉及智能无线通信技术领域,具体涉及一种基于ihho-fcm算法的网络流量分类方法。
背景技术:
2.智能无线通信系统近年来发展迅猛,数据流量呈爆炸式增长,不同类型的应用程序不断涌现,产生大量的网络流量。随着生活质量的改善,用户对于不同应用的服务质量和无线资源的需求也会提高,为了使智能无线通信系统能够为各种应用场景提供不同的服务,在实现无线网络资源分配前,必须先将网络流量精确化分类,这是提高用户满意度的一个关键方面。
3.针对网络流量的分类研究,很多学者提出的多种分类模型确实起到了一定的积极作用,如:端口号识别方法、深度包检测方法和机器学习方法等。但这些方法存在一定的弊端,在复杂的环境中,要获取大批量标记好的数据会消耗很大工作量,导致一些常用的有监督学习方法无法满足实际需要,因此模糊c均值聚类算法(fuzzy c-means cluster,fcm)应运而生,但fcm算法自身也存在着局限性,导致聚类结果不准确。
技术实现要素:
4.本发明的目的在于,提供一种基于ihho-fcm算法的网络流量分类方法,其使改进哈里斯鹰优化算法ihho能够在较短时间内收敛到最优解,并将此解作为fcm算法的初始聚类中心,从而有效提高网络流量分类的准确率。
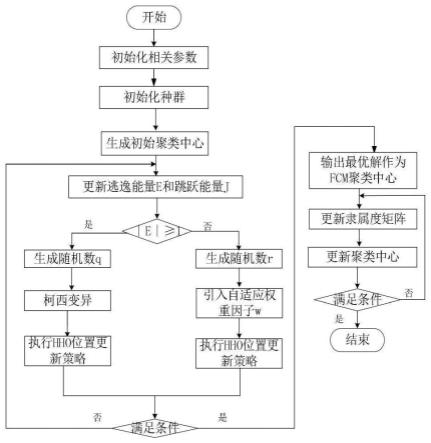
5.为实现上述目的,本技术提出一种基于ihho-fcm算法的网络流量分类方法,包括:
6.步骤1:对网络流量聚类问题的聚类中心进行编码,从网络流量数据集中选取c个样本点作为聚类中心,组成一个个体,重复选取n次,产生n个个体,设置个体初始集合为x={x1,x2,xi...,xn},其中xi为d维的特征向量,最大迭代次数为t;聚类中心集合为v={v1,v2,vk,...,vc},其中vk也是d维向量,则每个个体的位置是一个c*d维的向量xi={v
11
,v
12
,...,v
ij
,...,v
cd
};
7.步骤2:针对网络流量分类问题进行建模,并构建网络流量分类问题的目标函数f(x)来评价分类效果;
8.步骤3:将每个个体映射为一种聚类中心的集合,个体位置即对应聚类中心的选取方式,通过多种策略改进哈里斯鹰优化算法,从而更新个体位置;
9.步骤4:判断当前迭代次数是否达到最大迭代次数,若达到,此时个体的位置就是全局最优位置,即为当前网络流量分类时选取的最优聚类中心方案;
10.步骤5:执行fcm聚类操作,得到最优的隶属度矩阵,然后按照最大隶属度原则对网络流量数据集进行分类操作。
11.进一步的,所述网络流量分类问题的目标函数f(x)为:
[0012][0013][0014]
其中,为隶属度矩阵,xi为是第i个样本;是原fcm算法的目标函数,表示所有样本到各类中心距离的平方误差,用于衡量同种流量类别之间的紧凑性,值越小越紧凑,相似性越大;表示不同流量类别之间的分离程度,值越大,不同类样本距离越远;因此,f(x)值越小代表聚类效果越好。
[0015]
进一步的,通过多种策略改进哈里斯鹰优化算法,从而更新个体位置,具体为:
[0016]
引入tent映射来混沌个体初始集合,所述tent映射策略为:
[0017][0018]
其中,xn是随机产生的初始值,x
n+1
是迭代生成的下一个序列;
[0019]
将个体的逃逸能量e与跳跃强度j相结合,如下所示:
[0020][0021]
e0=2
×r1-1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0022]
j=(1+|e|)r2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0023]
其中,e0是个体的初始能量,r1为[-1,1]的随机数,r2是[0,1]之间的随机数,t为当前迭代次数,t为最大迭代次数。
[0024]
进一步的,个体的逃逸能量|e|≥1时,采用柯西分布函数进行变异,具体为:
[0025][0026][0027]
其中,x(t)和x(t+1)为当前和下次迭代时聚类中心选取的方式,xm(t)为平均位置,x
rand
(t)为随机选出的聚类中心,x
rabbit
(t)为当前最好的聚类中心选取方式,r3,r4,r5,r6,q是[0,1]之间的随机数,ub,lb为上下界,xk(t)为第k种聚类中心的选取方式;
[0028]
此时新的聚类中心选取方式x
_mutation
(t)更新为:
[0029][0030]
其中,x(t+1)为聚类中心原选取方式,x
_mutation
(t)为经过柯西变异后的聚类中心选取方式,r7是[0,1]之间的随机数。
[0031]
进一步的,个体的逃逸能量|e|<1时,引入自适应惯性权重因子w,公式为:
[0032][0033]
此时新的聚类中心选取方式x
new
更新为:
[0034]
x
new
=w
×
x(t)
ꢀꢀꢀꢀꢀ
(11)
[0035]
其中,x(t)为原哈里斯鹰优化算法的个体位置。
[0036]
进一步的,所述最优的隶属度矩阵获取方式为:
[0037][0038]
其中,d
ij
为样本i和聚类中心j之间的距离,m为模糊划分指数;
[0039]
根据下式更新聚类中心:
[0040][0041]
获取误差e,e=v
k+1-vk,若误差e<精度ε,则停止更新,得到最终分类结果,然后按照最大隶属度原则对网络流量数据集进行分类操作。
[0042]
本发明采用的以上技术方案,与现有技术相比,具有的优点是:1、本发明利用tent映射来混沌个体初始集合,可以使个体的搜索空间更均匀,解决了因初始值选择不当而导致搜索时间延长或迭代次数过多的问题,减少出现停滞问题的机会;
[0043]
2、本发明按照生物规律性改进逃逸能量,并与跳跃强度相结合,平衡了本方法的探索和开发;在不同阶段分别引入柯西分布函数和自适应权重因子,使其跳出局部最优的同时,提高收敛速度和搜索效率。
[0044]
3、本发明在适应度函数的设计上,综合考虑了同一类内的紧凑度和不同类间的分离度,使得分类结果更全面、更有说服性。
[0045]
4、本发明提出的一种基于ihho-fcm算法的网络流量分类方法,能够在较短时间内收敛到最优解,将此解作为fcm算法的初始聚类中心,解决fcm固有缺陷,有效提高网络流量的分类的准确性和稳定性。
附图说明
[0046]
图1为基于ihho-fcm算法的网络流量分类方法流程图;
[0047]
图2为实施例中各对比方法的适应度函数收敛曲线图。
具体实施方式
[0048]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本技术,并不用于限定本技术,即所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。
[0049]
因此,以下对在附图中提供的本技术的实施例的详细描述并非旨在限制要求保护的本技术的范围,而是仅仅表示本技术的选定实施例。基于本技术的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本技术保护的范围。
[0050]
为了证明本发明所提方法的有效性,将所提方法与多个已存在的算法进行多方面对比。对比实验采用网络流量分类中最权威的moore数据集来对所提方法进行聚类性能测试。
[0051]
实施例1
[0052]
如图1所示,本技术提供一种基于ihho-fcm算法的网络流量分类方法,具体包括:
[0053]
步骤1:对网络流量聚类问题的聚类中心进行编码,从网络流量数据集中选取c个样本点作为聚类中心,组成一个个体,重复选取n次,产生n
×
c个样本点,组成n个个体,由此个体初始集合为x={x1,x2,xi...,xn},其中xi为d维的特征向量,最大迭代次数为t;聚类中心集合为v={v1,v2,vk,...,vc},其中vk也是d维向量,则每个个体的位置是一个c*d维的向量xi={v
11
,v
12
,...,v
ij
,...,v
cd
};
[0054]
步骤2:针对网络流量分类问题进行建模,考虑到对分类效果的评价要综合类内紧凑度和类间分离度的影响,构建网络流量分类问题的目标函数f(x)来评价分类效果;
[0055]
步骤3:将每个个体映射为一种聚类中心的集合,个体位置即对应聚类中心的选取方式,针对哈里斯鹰优化算法hho随机初始化的缺陷,通过多种策略进行改进,从而更新个体位置;
[0056]
步骤4:判断当前迭代次数是否达到最大迭代次数,若达到,此时个体的位置就是全局最优位置,即为当前网络流量分类时选取的最优聚类中心方案;
[0057]
步骤5:执行fcm聚类操作,得到最优的隶属度矩阵,然后按照最大隶属度原则对网络流量数据集进行分类操作。
[0058]
本发明所用的实验环境为:inter(r)core(tm)i5-7200 cpu@2.50ghz,内存为12gb。实验所用的仿真软件为matlab 2016b,实验结果表明本发明的方法结果优于其他算法的实验结果。
[0059]
方法对比:
[0060]
为了验证所提的ihho-fcm算法对网络流量的分类效果,将ihho-fcm算法与hho-fcm算法、传统fcm算法、pso-fcm算法和gwo-fcm算法在相同的参数条件下对算法的适应度函数收敛曲线进行对比,并将结果记录在图2中。
[0061]
为进一步验证本发明所提算法的聚类性能,将各个算法运行30次的准确率、召回率和f值的平均值结果进行对比,结果分别记录在表1、表2、表3中,其中所有算法中最好的结果加粗显示。
[0062]
表1各算法分类准确率
[0063][0064]
表2各算法分类召回率
[0065][0066][0067]
表3各算法分类f值
[0068][0069]
对比分析:
[0070]
从图2中可以直观地看出,ihho-fcm算法利用了柯西变异和自适应权重因子调整,不但使算法可以很快收敛,而且具有跳出局部最优的能力,能够很快收敛到全局最优解。
[0071]
从表1-3的实验结果可以反映出,基于ihho-fcm算法的网络流量分类方法在moore流量数据集上分类的准确率更高,因此本发明所提方法在网络流量分类的应用场景中整体分类效果更好;同时,ihho-fcm算法的召回率也更高,表明对单个类别应用分类上也表现良好;另外,f值结果表明ihho-fcm算法比其他算法更加真实可靠。
[0072]
综上所述,本发明提出的一种基于ihho-fcm算法的网络流量分类方法,同其他先进方法相比,能够跳出局部最优解,在更短的时间内收敛到全局最优值,并且具有更高的分类准确率和可靠性。
[0073]
前述对本发明的具体示例性实施方案的描述是为了说明和例证的目的。这些描述并非想将本发明限定为所公开的精确形式,并且很显然,根据上述教导,可以进行很多改变和变化。对示例性实施例进行选择和描述的目的在于解释本发明的特定原理及其实际应
用,从而使得本领域的技术人员能够实现并利用本发明的各种不同的示例性实施方案以及各种不同的选择和改变。本发明的范围意在由权利要求书及其等同形式所限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1