基于草图的深度人脸视频编辑方法及系统
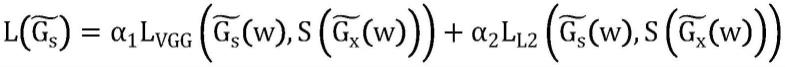
1.本发明涉及计算机图形学和计算机视觉技术领域,尤其涉及对人脸面部视频合成和草图编辑的方法和系统。
背景技术:
2.视频编辑是极具挑战性的科研问题,随着深度学习的发展,视频编辑和修改的工作也越来越多。现有的视频编辑方法,大多修改视频的全局属性,将黑白视频转换成彩色视频,或对视频进行风格化处理,生成艺术化的视频编辑结果。针对人脸视频,现有技术主要完成换脸等编辑任务,同样只修改身份这一全局属性。一些方法可以编辑视频的细节区域,但需要使用ps、pr等专业软件,需要较高的时间和精力成本。草图是一种高效精确的交互工具,具有很高的用户友好性,广泛地被用于图像的生成和编辑问题。但是,现有技术无法将草图编辑从图像扩展至视频,难以处理编辑操作的传播和合成问题。视频编辑有广泛的应用前景,在电影制作、新媒体传播等文化领域有较高价值,然而,现有的技术无法简单快捷地完成视频细节编辑任务。
3.针对视频编辑问题,现有技术能实现对视频自动上色,但其功能较为单一,仅能改变视频的颜色信息。或者对视频进行了风格化,不仅可以改变视频的颜色特征,而且对视频的内容进行艺术变换,生成具备艺术感的视频。但是,上述工作仅能编辑视频的全局特征,无法修改视频的细节。即使工作将视频表示到图集空间,通过ps等软件对图像编辑后,相关细节编辑操作将扩展至视频片段。但是上述方法需要专业的软件进行操作,且视频的编辑和生成都非常耗时。草图是一种更加友好的交互工具,用户的编辑操作更加简单准确。现有技术可以实现草图图像对人脸图像编辑的操作,但是其无法将编辑操作传播至整个视频。
技术实现要素:
4.为了解决上述现有技术的难以对视频内容细节进行编辑,草图编辑无法传播至视频的问题,本发明基于人脸图像生成网络stylegan,将草图编辑抽象表示为隐向量,并设计了创新性的传播和融合机制,编辑人脸视频。本发明提出了一种基于草图的人脸视频编辑方法及系统,可以选定任意的一帧/多帧,使用草图编辑人脸细节并用指定方式传播到整个视频。
5.具体来说本发明提出了一种基于草图的深度人脸视频编辑方法,其中包括:
6.步骤1、对齐并裁剪原视频中人脸,并将人脸编码至隐空间,得到人脸视频中所有帧的隐码;
7.步骤2、添加草图生成分支至stylegan生成网络,反向优化图像隐码,生成编辑向量δ
edit
;
8.步骤3、将编辑向量δ
edit
叠加到所有帧的隐码,完成时序无关编辑的传播;
9.步骤4、使用分段线性函数的权重叠加编辑向量δ
edit
,完成动作或表情的编辑传播;
10.步骤5、根据当前帧与编辑帧的表情参数的相似度,计算权重叠加编辑向量δ
edit
,使编辑与特定表情相对应,完成表情驱动编辑传播;
11.步骤6、使用区域感知融合方法,融合不同帧添加的不同类型的编辑,并将人脸融合至原视频,得到基于草图的人脸视频编辑结果。
12.所述的基于草图的深度人脸视频编辑方法,其中该步骤1包括:检测人脸视频的人脸关键点,并使用时间窗口平滑后,对人脸进行对齐和裁剪,生成视频帧序列f1,f2,
…
,fn,其中,n是该人脸视频的帧数;将帧序列投影至隐空间w
+
,生成隐码序列w1,w2,
…
,wn。
13.所述的基于草图的深度人脸视频编辑方法,其中该步骤2包括:
14.获取stylegan原始生成网络g,并构建用于建模真实人脸图像及草图的联合概率分布的生成网络生成网络包括和两个分支,为g的原始生成网络,用于生成拟真人脸图像,用于生成对应的草图图像;给定图像的隐码w,生成特征图f1,f2,
…
,f
14
,其中,f1用作分支的初始的特征图;分支的特征图经上采样,与特征图fi卷积后的残差图相加,生成隐码w对应的草图图像;
15.使用图像与草图匹配的数据集,训练草图生成网络s,其以人脸图像为输入,生成对应的草图,用于训练训练草图生成分支随机采样隐码w,将其输入生成高真实感人脸图像和对应草图构建损失函数训练草图生成分支
[0016][0017]
l
vgg
是感知损失函数,使用vgg19模型衡量视觉相似度,l
l2
是像素l2损失,α1和α2均为预设权重;
[0018]
在对真实图像和草图的分布建模后,根据输入的人脸图像x,绘制的草图s
edit
和选中区域m
edit
;将人脸图像x投影至w
+
空间,得到隐码w
edit
,生成的草图在编辑区域和输入草图相同,生成的图像在非编辑区域与原始图像相同,其中通过下述损失函数得到w
edit
:
[0019]
l
editing
(w
edit
)=β1l
sketch
+β2l
rgb
,
[0020]
l
sketch
约束编辑区域与草图结果结构相同,l
rgb
约束非编辑区域保持不变,β1与β2为超参数,通过固定生成网络的权重,得到w
edit
;
[0021]
最终的编辑向量δ
edit
=w
edit-w,δ
edit
表示了草图的编辑,并传播到整个人脸视频;对每一帧fi,生成对应的编辑向量:
[0022]
δi=δ
edit
,i=1,2,
…
,n
[0023]
该步骤3包括将每一帧fi对应的δ
edit
传播至整个人脸视频,生成编辑后的帧序列。
[0024]
所述的基于草图的深度人脸视频编辑方法,其中该步骤4包括:
[0025]
在该人脸视频中的特定时间添加眨眼或微笑的动作,在特定的帧f
t
添加编辑向量δ
edit
,输入持续时间h和变化时间l,对于每一帧fi,本发明使用分段线性函数生成光滑的传播编辑向量δi,得到新编辑向量δi:
[0026]
δi=γ
·
δ
edit
,i=1,2,
…
,m
[0027][0028]
t1=t-h/2-l,t2=t-h/2,t3=t+h/2,t4=t+h/2+l,t是编辑帧f
t
对应的时间;
[0029]
这些新的编辑向量δi用于合成拟真人脸图像;
[0030]
该步骤5包括:
[0031]
给定该人脸视频中多个关键帧使用3d重建的方式提取人脸的表情参数及对应的编辑向量m是关键帧的数量,使用下述方式传播表情引导编辑:
[0032][0033]ei
是输入帧fi的表情参数,c是归一化项且编辑向量针对相同的区域;
[0034]
该步骤6包括:
[0035]
给定一系列帧序列f1,f2,
…
,fn,用户选取m个关键帧k1,k2,
…
,km编辑不同的区域,对应m个绘制的标记区域m1,m2,
…
,mm;对每一帧fi,生成m个编辑向量
[0036]
对每一个待预测帧fi生成变形场,对输入标记区域变形生成m个新的标记区域为mj经过动作和表情变形后的区域;将原始帧的特征图的局部区域替换为新的特征图:
[0037][0038]
其中,初始的特征图是g是stylegan的生成网络;
[0039]
下采样使其与和有相同的分辨率;特征图对m个编辑操作,都进行更新,一共更新m次;更新stylegan的中间5个特征图,分辨率从32
×
32到128
×
128,高分辨率则由原本的隐码wi基于stylegan的算法进行调整;将上述的融合操作应用至所有帧fi,i=1,2,..,n,生成编辑融合后的对齐人脸视频;
[0040]
使用人脸分割方法,生成输入帧和编辑帧的人脸标记区域并将其合并,为合并的标记区域生成光滑的边缘,进一步用作融合的权重,融合编辑前后的人脸并将融合后的人脸图像反对齐至原视频,合成该人脸视频编辑结果。
[0041]
本发明还提出了一种基于草图的深度人脸视频编辑系统,其中包括:
[0042]
模块1,用于对齐并裁剪原视频中人脸,并将人脸编码至隐空间,得到人脸视频中所有帧的隐码;
[0043]
模块2,用于添加草图生成分支至stylegan生成网络,反向优化图像隐码,生成编辑向量δ
edit
;
[0044]
模块3,用于将编辑向量δ
edit
叠加到所有帧的隐码,完成时序无关编辑的传播;
[0045]
模块4,用于使用分段线性函数的权重叠加编辑向量δ
edit
,完成动作或表情的编辑传播;
[0046]
模块5,用于根据当前帧与编辑帧的表情参数的相似度,计算权重叠加编辑向量δ
edit
,使编辑与特定表情相对应,完成表情驱动编辑传播;
[0047]
模块6,用于使用区域感知融合方法,融合不同帧添加的不同类型的编辑,并将人脸融合至原视频,得到基于草图的人脸视频编辑结果。
[0048]
所述的基于草图的深度人脸视频编辑系统,其中该模块1用于检测人脸视频的人脸关键点,并使用时间窗口平滑后,对人脸进行对齐和裁剪,生成视频帧序列f1,f2,
…
,fn,其中,n是该人脸视频的帧数;将帧序列投影至隐空间w
+
,生成隐码序列w1,w2,
…
,wn。
[0049]
所述的基于草图的深度人脸视频编辑系统,其中该模块2用于获取stylegan原始生成网络g,并构建用于建模真实人脸图像及草图的联合概率分布的生成网络生成网络包括和两个分支,为g的原始生成网络,用于生成拟真人脸图像,用于生成对应的草图图像;给定图像的隐码w,生成特征图f1,f2,
…
,f
14
,其中,f1用作分支的初始的特征图;分支的特征图经上采样,与特征图fi卷积后的残差图相加,生成隐码w对应的草图图像;
[0050]
使用图像与草图匹配的数据集,训练草图生成网络s,其以人脸图像为输入,生成对应的草图,用于训练训练草图生成分支随机采样隐码w,将其输入生成高真实感人脸图像和对应草图构建损失函数训练草图生成分支
[0051][0052]
l
vgg
是感知损失函数,使用vgg19模型衡量视觉相似度,l
l2
是像素l2损失,α1和α2均为预设权重;
[0053]
在对真实图像和草图的分布建模后,根据输入的人脸图像x,绘制的草图s
edit
和选中区域m
edit
;将人脸图像x投影至w
+
空间,得到隐码w
edit
,生成的草图在编辑区域和输入草图相同,生成的图像在非编辑区域与原始图像相同,其中通过下述损失函数得到w
edit
:
[0054]
l
editing
(w
edit
)=β1l
sketch
+β2l
rgb
,
[0055]
l
sketch
约束编辑区域与草图结果结构相同,l
rgb
约束非编辑区域保持不变,β1与β2为超参数,通过固定生成网络的权重,得到w
edit
;
[0056]
最终的编辑向量δ
edit
=w
edit-w,δ
edit
表示了草图的编辑,并传播到整个人脸视频;
对每一帧fi,生成对应的编辑向量:
[0057]
δi=δ
edit
,i=1,2,
…
,n
[0058]
该模块3包括将每一帧fi对应的δ
edit
传播至整个人脸视频,生成编辑后的帧序列。
[0059]
所述的基于草图的深度人脸视频编辑系统,其中该模块4用于在该人脸视频中的特定时间添加眨眼或微笑的动作,在特定的帧f
t
添加编辑向量δ
edit
,输入持续时间h和变化时间l,对于每一帧fi,本发明使用分段线性函数生成光滑的传播编辑向量δi,得到新编辑向量δi:
[0060]
δi=γ
·
δ
edit
,i=1,2,
…
,m
[0061][0062]
t1=t-h/2-l,t2=t-h/2,t3=t+h/2,t4=t+h/2+l,t是编辑帧f
t
[0063]
对应的时间;
[0064]
这些新的编辑向量δi用于合成拟真人脸图像;
[0065]
该模块5包括:
[0066]
给定该人脸视频中多个关键帧使用3d重建的方式提取人脸的表情参数及对应的编辑向量m是关键帧的数量,使用下述方式传播表情引导编辑:
[0067][0068]ei
是输入帧fi的表情参数,c是归一化项且编辑向量针对相同的区域;
[0069]
该模块6用于给定一系列帧序列f1,f2,
…
,fn,用户选取m个关键帧k1,k2,
…
,km编辑不同的区域,对应m个绘制的标记区域m1,m2,
…
,mm;对每一帧fi,生成m个编辑向量
[0070]
对每一个待预测帧fi生成变形场,对输入标记区域变形生成m个新的标记区域为mj经过动作和表情变形后的区域;将原始帧的特征图的局部区域替换为新的特征图:
[0071][0072]
其中,初始的特征图是g是stylegan的生成网络;
[0073]
下采样使其与和有相同的分辨率;特征图对m个编辑操作,都进行更新,一共更新m次;更新stylegan的中间5个特征图,分辨率从32
×
32到128
×
128,高分辨率则由原本的隐码wi基于stylegan的算法进行调整;将上述的融合操作应用至所有帧fi,i=1,2,..,n,生成编辑融合后的对齐人脸视频;
[0074]
使用人脸分割方法,生成输入帧和编辑帧的人脸标记区域并将其合并,为合并的标记区域生成光滑的边缘,进一步用作融合的权重,融合编辑前后的人脸并将融合后的人脸图像反对齐至原视频,合成该人脸视频编辑结果。
[0075]
本发明还提出了一种存储介质,用于存储执行所述任意一种基于草图的深度人脸视频编辑方法的程序。
[0076]
本发明还提出了一种客户端,用于所述任意一种基于草图的深度人脸视频编辑系统。
[0077]
由以上方案可知,本发明的优点在于:
[0078]
本发明设计的系统能够选定的一个/多个编辑帧,用户绘制草图及相应的编辑区域掩模,指定编辑的传播方式后,实现视频的编辑及传播操作。
附图说明
[0079]
图1为本发明系统流程示意图;
[0080]
图2为草图优化示意图;
[0081]
图3为时序无关编辑与时间窗口编辑结果图;
[0082]
图4为时序无关编辑与表情驱动编辑结果图;
[0083]
图5为不同绘制风格结果图;
[0084]
图6为旋转人脸编辑结果图;
[0085]
图7为优化草图编辑向量后,使用不同方式融合结果图;
[0086]
图8为不同编辑融合结果图;
[0087]
图9为人脸视频编辑中间结果示意图;
[0088]
图10为关键点平滑结果图。
具体实施方式
[0089]
现有技术中缺陷是由草图编辑没有考虑视频上传播问题导致的,原因是视频中的人脸存在表情和动作的变化,输入的草图编辑操作难以直接作用于其他帧,同时,草图既可以改变人脸的身份特征(如五官的形状),也可以改变人脸的表情和动作(如何添加微笑),如何区分他们并合理传播十分困难;视频编辑同时需要保证时序的稳定性,现有的方法没有考虑视频生成的闪烁问题,生成的结果质量较差。
[0090]
发明人经过对图像及视频的草图编辑发现,解决该项缺陷可以通过设计合理的视频编码方式及草图的编辑传播和融合方法来实现。输入人脸视频后,首先经过关键点检测,对人脸区域进行裁剪和对齐。进一步,我们使用图像编码网络,将所有帧的人脸图像编码到stylegan生成网络的隐空间中。针对用户输入的草图编辑,我们设计了一种优化策略,将编辑操作抽象表示为编辑向量。在编辑的传播过程中,编辑操作分为两类,时序无关编辑和时
序相关编辑,时序相关编辑又进一步分为时间窗口编辑和表情驱动编辑,编辑的具体类型由用户指定,并使用不同的方式进行传播。同时,我们设计了一种区域感知的融合策略,融合在不同帧输入的不同编辑操作,生成编辑后的人脸视频。最后,生成的人脸视频反对齐到输入原视频,并融合人脸区域,生成草图视频编辑结果。
[0091]
本发明的核心发明点包括:
[0092]
关键点1,基于stylegan的视频编码模块。输入一段人脸视频后,利用dlib的人脸关键点检测技术,裁剪并对齐人脸图像,使用时间窗口进行平滑。基于e4e人脸到stylegan隐空间编码技术,将输入帧序列编码为隐码序列。根据输入的帧序列及隐码序列,基于pti重建技术,微调stylegan生成网络的权重,使其能完美重建原始视频,完成视频的编码任务,服务于后续的视频编辑;
[0093]
关键点2,草图编辑优化模块。基于预训练好的草图生成网络,扩展原始的stylegan,为其添加草图生成分支。进一步,设计一种优化策略,用户输入绘制的草图及编辑区域掩模,在编辑区域约束与草图相同,而非编辑区域与原始图像相同,迭代优化原本的隐码。优化后的隐码与输入隐码做差,得到编辑向量,抽象表示草图编辑操作。
[0094]
关键点3,时序无关传播技术。部分编辑操作具备时序无关的特征,即编辑应均匀作用于整个视频的帧序列,与表情和动作无关,例如编辑人脸的脸型等。此类编辑,将编辑向量与输入帧的隐码直接相加,完成实现编辑的传播效果。
[0095]
关键点4:时间窗口传播技术。部分编辑操作代表了人脸的具体动作,包括微笑、闭眼等。该类动作被分为三个阶段,开始阶段,持续阶段,结束阶段,开始阶段和结束阶段使用线性变化的权重对编辑向量叠加,持续阶段的使用固定权重叠加,实现动作开始、持续、结束的全过程。
[0096]
关键点5:表情驱动传播技术。部分编辑操作与表情相关,例如微笑的时候伴随闭眼等。针对该类编辑,使用3d重建的方式,提取人脸的表情参数,根据编辑帧与预测帧的表情参数的余弦相似度计算权重,对编辑向量进行叠加。
[0097]
关键点6:区域感知融合模块。在视频编辑过程中,用户往往会选定多帧,同时编辑不同的区域。该模块使用变形操作,根据人脸的动作表情变化,预测变形场,对绘制的掩模进行变形。进一步,根据变形后的掩模区域,替换生成网络的特定位置的特征图.最后,生成的人脸区域会融合并反投影至原始帧,完成不同编辑的融合操作。
[0098]
为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
[0099]
系统流程图如图1所示,该系统包括编辑向量生成,时序无关编辑传播,时间窗口编辑传播,表情驱动编辑传播,区域感知融合等多项技术。
[0100]
草图优化流程图如图2所示,原始的stylegan生成网络被扩展为两个分支,一个分支生成草图图像,另一个分支生成具有高真实感的图像。优化过程包括l_sketch和l_rgb两个损失项,分别约束编辑区域对应草图编辑和其他区域保持不变。
[0101]
如图1所示,一种基于草图交互的高质量人脸视频编辑方法和系统,包括:
[0102]
s1:输入视频后,对齐并裁剪人脸,将人脸编码至隐空间;
[0103]
s2:扩展stylegan生成网络,添加草图生成分支反向优化图像隐码,生成编辑向量δ
edit
;
[0104]
s3:时序无关编辑,将编辑向量δ
edit
直接叠加到所有帧的隐码,完成时序无关编辑的传播;
[0105]
s4:时间窗口编辑,使用分段线性函数的权重叠加编辑向量δ
edit
,完成动作或表情的编辑传播;
[0106]
s5:表情驱动编辑,根据当前帧与编辑帧的表情参数的相似度,计算权重叠加编辑向量δ
edit
,使编辑与特定表情相对应;
[0107]
s6:使用区域感知融合方法,融合不同帧添加的不同类型的编辑,并将人脸融合至原视频;
[0108]
其中,s1的所述方法包括:
[0109]
给定输入视频后,使用dlib检测人脸关键点,并使用时间窗口平滑关键点的坐标,对人脸进行对齐和裁剪,生成视频帧序列f1,f2,
…
,fn,其中,n是帧的数量。本发明使用e4e将帧序列投影至w
+
空间,生成隐码序列w1,w2,
…
,wn。后续生成的编辑向量,将会叠加至隐码序列。其中平滑是对序列上的面部关键点坐标进行平滑,人脸检测方法是单帧检测的,所以帧间会存在一定的抖动。平滑的目的是消除抖动的影响。
[0110]
其中,s2的所述方法如图2所示,包括:
[0111]
s21:给定stylegan原始生成网络g,本发明设计了新的生成网络建模真实人脸图像及草图的联合概率分布。其包括两个分支,生成高真实感的人脸图像,为g的原始生成网络,生成对应的草图图像。给定图像的隐码w,生成特征图f1,f2,
…
,f
14
,其中,f1被用作分支的初始的特征图。分支的中间特征图反复进行上采样,与fi卷积后的残差图相加。对i=2~14都完成上述操作后,最终生成隐码w对应的草图图像。stylegan3原始生成网络有10个像素的扩充,本发明裁剪中间特征图,只使用裁剪后的像素内容。
[0112]
s22:为了训练草图生成分支我们先使用图像与草图匹配的数据集,基于pix2pixhd网络训练一个草图生成网络s。草图生成网络以真实的人脸图像为输入,生成对应的草图,用于训练训练草图生成分支然后,本发明随机采样隐码w,将其输入生成高真实感人脸图像和对应草图之后,本发明使用下述损失函数训练草图生成分支:
[0113][0114]
l
vgg
是感知损失函数,使用vgg19模型衡量视觉相似度,l
l2
是像素l2损失,α1和α2均为预设权重,此时实例中α1=α2=1。
[0115]
s23:在对真实图像和草图的分布建模后,本发明设计一种优化技术,根据用户输入的真实图像x,用户绘制的草图s
edit
和标记区域m
edit
,生成编辑向量δ
edit
。首先,真实图像x被投影至w
+
空间,生成初始的隐码w。然后,本发明优化得到新的隐码w
edit
,生成的草图在编辑区域和输入草图相同,生成的图像在非编辑区域与原始图像相同。为了优化得到w
edit
,本发明使用下述损失函数:
[0116][0117][0118]
其中,l
lpips
是lpips距离,
⊙
为矩阵点乘。l
sketch
约束编辑区域与草图结果结构相同,l
rgb
约束非编辑区域保持不变。最终的优化损失函数为:
[0119]
l
editing
(w
edit
)=β1l
sketch
+β2l
rgb
,
[0120]
β1与β2为超参数。优化过程中,固定网络的权重,唯一优化的参数为w
edit
。
[0121]
s24:最终的编辑向量为:
[0122]
δ
edit
=w
edit-w
[0123]
δ
edit
抽象表示了草图的编辑,并传播到整个视频。
[0124]
其中,s3的所述方法包括:
[0125]
一些编辑操作对整个视频有显著的影响,与表情和动作的相关度较低。这些编辑操作主要改变人脸的基础形状,例如脸型及五官的形状。由于本发明生成的编辑向量δ
edit
本身具备解耦特性和语义特性,将其直接应用至整个视频帧序列。对每一帧fi,生成对应的编辑向量:
[0126]
δi=δ
edit
,i=1,2,
…
,n
[0127]
这些编辑向量将编辑传播至整个视频,生成编辑后的帧序列。
[0128]
其中,s4的所述方法包括:
[0129]
与单帧编辑不同,视频伴随时间具备表情和动作的变化。用户常常编辑时序的人脸动作,例如在特定时间添加眨眼或微笑的动作。在特定的帧f
t
添加编辑向量δ
edit
,用户还需要输入持续时间h和变化时间l。然后,对于每一帧fi,本发明使用分段线性函数生成光滑的传播编辑向量δi:
[0130]
δi=γ
·
δ
edit
,i=1,2,
…
,m
[0131][0132]
t1=t-h/2-l,t2=t-h/2,t3=t+h/2,t4=t+h/2+l,t是编辑帧f
t
对应的时间。这些新的编辑向量δi将会被用于合成高真实感的人脸图像。使用上述编辑方式,本发明不仅可以在特定的时间窗口中生成编辑的效果,也可以形成光滑的过度,即编辑的出现和消失,例如,从自然的表情到微笑的表情,再从微笑的表情到自然的表情。
[0133]
其中,s5的所述方法包括:
[0134]
在一些情景中,用户只想在特定的表情下添加一些编辑,同时,在其他的表情下保持原来的状态或添加新的编辑。这种编辑操作包括表情驱动的皱纹(例如法令纹、抬头纹等),以及一些仅在特定表情下出现的形状编辑(例如微笑的时候变小眼睛)。为了传播这一类表情驱动的编辑,本发明使用3d重建的方式提取人脸的表情参数。更具体的,给定表情编
辑的关键帧m是关键帧的数量,本发明提取了表情参数及对应的编辑向量一些关键帧可以没有任何编辑操作,而作为关键参考帧,表明在某一表情没有任何编辑操作。对于这些帧,编辑向量就是零向量。本发明使用下述方式传播表情引导编辑:
[0135][0136]ei
是输入帧fi的表情参数,c是归一化项本发明中,编辑向量针对相同的区域。
[0137]
其中,s6的所述方法包括:
[0138]
s6.1:本发明支持使用草图编辑任意多帧,并将其编辑效果融合。编辑多帧后,生成多个编辑向量,一个简单的方法是将编辑向量直接相加,然而,如图7所示,该方法会生成瑕疵,本发明设计一种区域感知融合方式。
[0139]
s6.2:给定一系列帧序列f1,f2,
…
,fn,用户选取m个关键帧k1,k2,
…
,km编辑不同的区域,对应m个编辑标记区域m1,m2,
…
,mm。使用前述编辑传播方式,对每一帧fi,生成m个编辑向量代表不同的编辑操作。
[0140]
对于每一个待预测帧fi,本发明使用first-order方法生成变形场,对输入标记区域变形生成m个新的的区域与输入绘制的区域mj标记相似的区域,但考虑了帧fi与编辑关键帧kj间表情和头部的运动。为了融合不同的编辑操作,本发明将原始帧的特征图的局部区域替换为新的特征图:
[0141][0142]
其中,初始的特征图是g是stylegan的生成网络。本发明下采样使其与和有相同的分辨率。对于m次编辑操作,迭代上述上述公式m次,j=1~m,完成多个局部区域的编辑融合。本发明更新生成网络的中间5个特征图,这些特征图主要控制人脸结构信息,分辨率从32
×
32到128
×
128。高分辨率则由原本的隐码wi,使用stylegan网络的算法进行调整。本发明将上述的融合操作应用至所有帧fi,i=1,2,..,n,生成编辑融合后的对齐人脸视频。
[0143]
s6.3:本发明将合成的人脸融合至原始的视频,合成最终编辑视频。首先,使用人脸分割方法,生成输入帧和编辑帧的人脸区域标记图,计算人脸区域的并集。合并的区域进一步膨胀,使边缘光滑过渡。将光滑后的人脸区域标记图转为融合权重,标记区域权重为1,非标记区域权重为0,过渡边缘权重介于0和1之间,基于该权重融合编辑前后的人脸。最后,人脸图像反对齐至原视频,合成最终的编辑视频。
[0144]
如图3所示,展示了本发明的时序无关编辑和时间窗口编辑融合的结果。左侧中的时序无关编辑为编辑人物添加头发和胡子,时间窗口编辑为编辑人物添加挑眉动作。右侧
第一行为原始视频,右侧第二行是编辑后的视频结果,编辑后的视频头发和胡子更多,同时具备挑眉动作。
[0145]
如图4所示,展示了本发明的时序无关编辑和时间窗口编辑融合的结果。左侧中的时序无关编辑变小了人脸的鼻子,表情驱动编辑中,张大嘴时变小眼睛,闭合嘴时保持原本的形状。右侧展示了编辑前后的视频帧,编辑操作都较好地传播至整个视频。
[0146]
如图5所示,展示了使用不同绘制风格的草图编辑人脸的结果。第一列图像展示了绘制的草图和选中区域,第二列图像展示了单帧编辑的结果。右侧第一行展示了原始的视频帧,后续几行展示了编辑传播的结果。针对不同绘制风格的草图,本发明生成了较高质量的结果,具备较好的鲁棒性。
[0147]
如图6所示,展示了对于带有角度变化的人脸编辑的结果。第一行图像是原始的视频帧序列,第二行图像是编辑后的视频帧序列,左侧是用户绘制的草图和选中区域。即使输入的人脸视频带有旋转和角度变化,本发明也生成高质量的编辑结果。
[0148]
如图7所示,展示了两种编辑融合方法的结果。用户添加了两个时序无关编辑,变化脸型和头发,同时添加了时间窗口编辑。第一行展示了编辑的草图的编辑结果,第二行展示了原始视频,第三行展示了多个编辑向量直接相加这一融合方式的结果,第四行展示了区域感知融合方式的结果。区域感知融合方式的结果生成的质量高于编辑向量直接相加,证明了本发明中区域感知融合模块的有效性。
[0149]
如图8所示,展示了不同编辑的融合结果。第一行是原始视频,第二行是时序无关编辑的结果,修改人脸的头发区域,第三行是时间窗口编辑,为人脸添加微笑,最后一行是两种编辑融合的结果。
[0150]
如图9所示,展示了人脸视频编辑的中间结果。第二行展示了真实的视频,第三行展示了对齐的结果。第四行展示了绘制掩模根据表情、动作变形后的结果,第五行展示了对齐人脸的编辑结果。第六行展示了人脸区域分割的结果,最后一行展示了最终的反对齐的人脸编辑结果。
[0151]
如图10所示,展示了关键点平滑的结果。前三行是不使用关键点平滑的结果,裁剪对齐后的人脸有非常大的抖动,后三行是使用关键点平滑的结果,裁剪对齐后的人脸没有抖动问题。
[0152]
以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。
[0153]
本发明还提出了一种基于草图的深度人脸视频编辑系统,其中包括:
[0154]
模块1,用于对齐并裁剪原视频中人脸,并将人脸编码至隐空间,得到人脸视频中所有帧的隐码;
[0155]
模块2,用于添加草图生成分支至stylegan生成网络,反向优化图像隐码,生成编辑向量δ
edit
;
[0156]
模块3,用于将编辑向量δ
edit
叠加到所有帧的隐码,完成时序无关编辑的传播;
[0157]
模块4,用于使用分段线性函数的权重叠加编辑向量δ
edit
,完成动作或表情的编辑传播;
[0158]
模块5,用于根据当前帧与编辑帧的表情参数的相似度,计算权重叠加编辑向量
δ
edit
,使编辑与特定表情相对应,完成表情驱动编辑传播;
[0159]
模块6,用于使用区域感知融合方法,融合不同帧添加的不同类型的编辑,并将人脸融合至原视频,得到基于草图的人脸视频编辑结果。
[0160]
所述的基于草图的深度人脸视频编辑系统,其中该模块1用于检测人脸视频的人脸关键点,并使用时间窗口平滑后,对人脸进行对齐和裁剪,生成视频帧序列f1,f2,
…
,fn,其中,n是该人脸视频的帧数;将帧序列投影至隐空间w
+
,生成隐码序列w1,w2,
…
,wn。
[0161]
所述的基于草图的深度人脸视频编辑系统,其中该模块2用于获取stylegan原始生成网络g,并构建用于建模真实人脸图像及草图的联合概率分布的生成网络生成网络包括和两个分支,为g的原始生成网络,用于生成拟真人脸图像,用于生成对应的草图图像;给定图像的隐码w,生成特征图f1,f2,
…
,f
14
,其中,f1用作分支的初始的特征图;分支的特征图经上采样,与特征图fi卷积后的残差图相加,生成隐码w对应的草图图像;
[0162]
使用图像与草图匹配的数据集,训练草图生成网络s,其以人脸图像为输入,生成对应的草图,用于训练训练草图生成分支随机采样隐码w,将其输入生成高真实感人脸图像和对应草图构建损失函数训练草图生成分支
[0163][0164]
l
vgg
是感知损失函数,使用vgg19模型衡量视觉相似度,l
l2
是像素l2损失,α1和α2均为预设权重;
[0165]
在对真实图像和草图的分布建模后,根据输入的人脸图像x,绘制的草图s
edit
和选中区域m
edit
;将人脸图像x投影至w
+
空间,得到隐码w
edit
,生成的草图在编辑区域和输入草图相同,生成的图像在非编辑区域与原始图像相同,其中通过下述损失函数得到w
edit
:
[0166]
l
editing
(w
edit
)=β1l
sketch
+β2l
rgb
,
[0167]
l
sketch
约束编辑区域与草图结果结构相同,l
rgb
约束非编辑区域保持不变,β1与β2为超参数,通过固定生成网络的权重,得到w
edit
;
[0168]
最终的编辑向量δ
edit
=w
edit-w,δ
edit
表示了草图的编辑,并传播到整个人脸视频;对每一帧fi,生成对应的编辑向量:
[0169]
δi=δ
edit
,i=1,2,
…
,n
[0170]
该模块3包括将每一帧fi对应的δ
edit
传播至整个人脸视频,生成编辑后的帧序列。
[0171]
所述的基于草图的深度人脸视频编辑系统,其中该模块4用于在该人脸视频中的特定时间添加眨眼或微笑的动作,在特定的帧f
t
添加编辑向量δ
edit
,输入持续时间h和变化时间l,对于每一帧fi,本发明使用分段线性函数生成光滑的传播编辑向量δi,得到新编辑向量δi:
[0172]
δi=γ
·
δ
edit
,i=1,2,
…
,m
[0173][0174]
t1=t-h/2-l,t2=t-h/2,t3=t+h/2,t4=t+h/2+l,t是编辑帧f
t
对应的时间;
[0175]
这些新的编辑向量δi用于合成拟真人脸图像;
[0176]
该模块5包括:
[0177]
给定该人脸视频中多个关键帧使用3d重建的方式提取人脸的表情参数及对应的编辑向量m是关键帧的数量,使用下述方式传播表情引导编辑:
[0178][0179]ei
是输入帧fi的表情参数,c是归一化项且编辑向量针对相同的区域;
[0180]
该模块6用于给定一系列帧序列f1,f2,
…
,fn,用户选取m个关键帧k1,k2,
…
,km编辑不同的区域,对应m个绘制的标记区域m1,m2,
…
,mm;对每一帧fi,生成m个编辑向量
[0181]
对每一个待预测帧fi生成变形场,对输入标记区域变形生成m个新的标记区域为mj经过动作和表情变形后的区域;将原始帧的特征图的局部区域替换为新的特征图:
[0182][0183]
其中,初始的特征图是g是stylegan的生成网络;
[0184]
下采样使其与和有相同的分辨率;特征图对m个编辑操作,都进行更新,一共更新m次;更新stylegan的中间5个特征图,分辨率从32
×
32到128
×
128,高分辨率则由原本的隐码wi基于stylegan的算法进行调整;将上述的融合操作应用至所有帧fi,i=1,2,..,n,生成编辑融合后的对齐人脸视频;
[0185]
使用人脸分割方法,生成输入帧和编辑帧的人脸标记区域并将其合并,为合并的标记区域生成光滑的边缘,进一步用作融合的权重,融合编辑前后的人脸并将融合后的人脸图像反对齐至原视频,合成该人脸视频编辑结果。
[0186]
本发明还提出了一种存储介质,用于存储执行所述任意一种基于草图的深度人脸
视频编辑方法的程序。
[0187]
本发明还提出了一种客户端,用于所述任意一种基于草图的深度人脸视频编辑系统。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1