软件定义网络中基于特征遍历选择和模型动态更新分类算法的分布式拒绝服务攻击检测方法
1.本发明属于计算机网络安全技术领域,具体涉及一种软件定义网络中基于特征遍历选择和模型动态更新分类算法的分布式拒绝服务攻击检测方法。
背景技术:
2.随着网络技术的不断发展,在大数据的时代,互联网领域出现了一种新的网络架构——软件定义网络(software defined networks,sdn)。它将控制平面和数据平面解耦,以及通过运行在控制器上的指定应用程序集中网络管理,尽管有许多优点,但sdn网络中心的安全问题仍然是研究界关注的问题之一。分布式拒绝服务攻击(distributed denialof service,ddos)就是sdn网络安全中最大威胁的攻击之一,它是指处于不同位置的多个攻击者同时向一个或多个目标发出攻击,其攻击方式众多、破坏力强,伪造源ip地址迷惑防御系统,导致检测难度增大,随着数据的变化多端,传统攻击检测方法难以检测攻击数据,导致网络系统瘫痪,目前存在的检测方法在sdn网络中不适用于流量较大的网络、检测模型不能很好的适应网络流量的变化,例如基于熵值检测等只适用于较少数据集的情况、非在线检测模型不能及时适应网络的流量变化。
技术实现要素:
3.针对现有技术中存在的缺陷或不足,所以为了适用于当前环境的网络系统,本发明的目的在于,提供一种软件定义网络中基于特征遍历选择和模型动态更新分类算法的分布式拒绝服务攻击检测方法
4.为了实现上述任务,本发明采用如下技术解决方案:
5.一种软件定义网络中基于特征遍历选择和模型动态更新分类算法的分布式拒绝服务攻击检测方法,其特征在于,包括如下步骤:
6.步骤1,获取包含t周期内源ip地址发出数据包的总数量(total bwd packets)、t 周期内目的ip地址接收数据包的总大小(total length of fwd packets)和t周期内源ip 地址发出数据包的总大小(total length of bwd packets)的特征数据集,使用分类算法训练分类模型,构建软件定义网络拓扑架构,并设置动态更新数据集合大小为0;
7.步骤2,使用软件定义网络拓扑结构连接控制器,设置流表项的死亡时间,通过在控制平面获取数据层的交换机中的流表信息进行数据的采集;
8.步骤3,通过步骤2获取到流表信息后利用公式进行计算,计算得到t周期内目的 ip地址发出数据包的总数量、t周期内目的ip地址接收数据包的总大小和t周期内目的 ip地址发出数据包的总大小;
9.步骤4,针对每一个openflow交换机,使用步骤3计算得到的数据集作为输入数据,然后将数据用于knn算法分类模型进行训练后得到原始分类模型,并把输入数据和检测结果作为新的训练数据添加至动态更新数据集合。
10.步骤5,动态更新数据集合数据达到3000条时,并且动态更新分类模型和原始分类模型预测结果不一样的次数小于30次时,将数据用于knn算法分类模型进行训练后得到分类模型;
11.若原始分类模型和动态更新分类模型判断结果一样且为恶意流量,控制器定位攻击目标,删除流表中的攻击流表项并返回给交换机当前的流表信息;
12.若判断结果不一样则判断为正常流量,两个模型预测结果不一样的次数增加1,如果两个模型预测结果不一样的次数超过30次,动态更新数据集合数据清零,防止预测结果和实际结果偏差过大。若动态更新数据集合数据未达到3000条时,判断结果只取决于原始分类模型。
13.根据本发明,在发生ddos攻击时,某些特征的值相对正常通信时的特征值会急剧变大或者变小,选取特征值前30%小的数据和后30%大的数据不仅更有代表性而且可以只使用部分的数据以减少寻找较优特征的速度;依次将特征值从小到大进行排序后选取该特征前30%数据,若该部分数据中恶意流量占比超过60%,说明该部分数据具有代表性,将该特征加入集合1;选取该特征后30%数据,若该部分数据中恶意流量占比超过60%,将该特征加入集合2;
14.对两个集合的特征数据进行遍历、训练和预测,得到较好的预测效果并且特征数量较少的特征为total backward packets、total length of forward packets和total length ofbackward packets。
15.具体地,使用原始数据集合对新数据进行预测之后,将新数据和预测结果加入到动态更新数据集合里面,当动态更新数据集合达到一定数目时,最终预测结果由原始数据预测结果和动态更新数据集合预测结果共同决定;如果两个模型预测结果不一致的次数达到一定数目时,重置动态更新数据集合,避免预测结果和实际结果相差越来越大。
16.可选的,分类模型进行检测具体包括:
17.特征遍历选择(feature traversal selection):ddos攻击时,某些特征的值会急剧变大或者变小,选取特征值前30%小的数据和后30%大的数据不仅更有代表性而且可以只使用部分的数据,减少寻找特征的速度。依次将特征值从小到大进行排序后选取该特征前 30%数据,若该部分数据中恶意流量占比超过60%,将该特征加入集合1;选取该特征后 30%数据,若该部分数据中恶意流量占比超过60%,将该特征加入集合2。对两个集合的特征进行遍历、训练和预测,选择效果最好且数量较少的特征作为新的数据集。分类算法模型具体步骤如下:
18.1)计算测试数据与各个训练数据之间的距离;
19.2)按照距离递增的顺序进行排序;
20.3)选择距离最近的k个样本数据;
21.4)计算前k个样本所在类别的频率/均值;
22.5)返回前k个样本出现频率最高/(加权)均值作为测试数据的类别/预测值;
23.具体使用公式如下:
[0024][0025]
式中,d(x,y):计算的是测试数据与一个训练数据之间的距离;
[0026]
进一步地,所述的特征数值是根据如下公式计算得到:
[0027][0028]
式中:b_packet_i表示在t周期内发出的第i个数据包;
[0029]
f_packet__表示在t周期内接收第i个数据包的大小;
[0030]
b_packet__len表示在t周期内发出第i个数据包的大小;
[0031]
total bwd packets表示在t周期内源ip地址发出数据包的总数量;
[0032]
total length of fwd packets表示在t周期内目的ip地址接收数据包的总大小;
[0033]
total length of bwd packets表示在t周期内源ip地址发出数据包的总大小。
[0034]
本发明的软件定义网络中基于特征遍历选择和模型动态更新分类算法的分布式拒绝服务攻击检测方法,通过公开数据集cicids dataset(2017)作为训练数据,利用特征遍历选择,选取最有代表性的特征数据集,利用分类算法训练分类模型。然后将预测的数据和结果加入到动态更新数据集合,当动态更新数据集合大小达到3000条时,预测结果由两个模型共同决定。若判断结果不一样则判断为正常流量,两个模型预测结果不一样的次数增加1,如果两个模型预测结果不一样的次数超过30次,动态更新数据集合数据清零,防止预测结果和实际结果偏差过大。若判断为恶意流量处理流表并返回给交换机处理后的结果,从而保证网络的安全通信,避免造成资源耗尽、网络瘫痪等问题。不仅检测时间少、准确率高,而且实时适应网络流量的变化,更好适应软件定义网络攻击检测的需求。
附图说明
[0035]
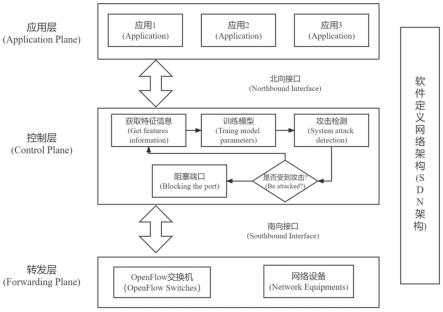
图1为本发明的基于特征遍历选择和模型动态更新分类算法的分布式拒绝服务攻击检测系统架构图;
[0036]
图2为软件定义网络拓扑结构示意图;
[0037]
图3为基于特征遍历选择和模型动态更新分类算法的分布式拒绝服务攻击检测模型的检测攻击步骤示意图;
[0038]
图4为使用数据的比例变化且数据中ddos占比变化时特征数量的变化示意图;
[0039]
图5为拓扑结构中openflow交换机的流表中多个周期内计算的total bwd packets、 total length of fwd packets、total length of bwd packets示意图;
[0040]
下面结合附图和具体实施例对本发明作进一步详细地解释和说明。
具体实施方式
[0041]
以下将结合附图和实施例中对本发明实施例中的技术方案进行清楚、完整地描述。需要说明的是,以下所描述的实施例仅是本发明较优的实施例,本发明不限于以下的实施例,凡是在本发明技术方案基础上,对技术特征进行添加或者简单替换,均属于本发明保护的范围。
[0042]
在以下的实施例中,整个过程都是针对软件定义网络(sdn),交换机都是sdn网络环境下的openflow交换机。sdn网络拓扑结构包括一台ryu控制器(一款开源软件定义网络控制器)、4台交换机和8台主机。
[0043]
如图1所示,本实施例给出一种软件定义网络中基于特征遍历选择和模型动态更新分类算法的分布式拒绝服务攻击检测方法,该方法在软件定义网络环境下,使用特征遍历选择和模型动态更新分类算法分类训练检测模型,使得模型适用于多种情况,可以快速、实时、准确检测攻击,并定位攻击主机删除攻击数据,尽可能的保护软件定义网络的安全,适应网络流量变化,减少网络资源的消耗,减少检测攻击所需的时间,提高攻击检测的准确率。除此之外,它还具有很好的适用性,利用多种公开数据集进行测试发现结果符合要求。
[0044]
具体包括以下步骤:
[0045]
步骤1,获取包含total bwd packets、total length of fwd packets和total length ofbwd packets的特征数据集,total bwd packets代表源ip地址在相同周期内发出数据包的总数量,total length of fwd packets代表目的ip地址在相同周期内接收数据包的总大小, total length of bwd packets代表源ip地址在相同周期内发出数据包的总大小。对特征进行遍历选择,选取具有代表性的几组特征数据,将其用于分类算法训练分类模型。
[0046]
步骤2,如图2所示,构建软件定义网络拓扑结构,使用软件定义网络拓扑结构连接控制器,利用控制器控制管理整个网络调度,数据平面只进行数据的传输,通过在控制平面获取数据层的交换机中的流表信息进行数据的采集;
[0047]
步骤3,通过步骤2获取到交换机的流表信息进行特征提取计算,计算得到t周期内源ip地址发出数据包的总数量、t周期内目的ip地址接收数据包的总大小和t周期内源ip地址发出数据包的总大小;
[0048]
其中,每个交换机的流表有多个流表项,每条流表项由三个要素组成:用于数据包匹配的包头域(header fields),用于统计匹配数据包个数的计数器(counters),用于展示匹配的数据包如何处理的动作(actions)。流表的包头域包含源端口、源mac(mediaaccesscontroladdress)地址、目的mac地址、ip协议、源ip地址和目的ip地址等12 个元组。openflow流表的计数器是对交换机中的每张流表、每个数据流、每个设备端口、每个转发队列进行维护,用于统计数据流量的相关信息。例如:针对每张流表,统计当前活动的表项数、数据包查询次数、数据包匹配次数等;针对每个数据流,统计接收到的数据包数、字节数、数据流持续时间等;openflow流表的动作用于指示交换机在收到匹配的数据包后应该如何对其进行处理。
[0049]
所获取的是交换机流表中的源ip地址、目的ip地址和数据包的大小,利用计数器计算各个数值的数量,然后在模型中检测特征变化,以此来检测攻击是否存在,若发生攻击,利用流表的删除动作删除流表项。
[0050]
在统计流表数据后,利用如下公式计算特征值:
[0051][0052]
式中:b_packet_i表示在t周期内发出的第i个数据包;
[0053]
f_packet_i_len表示在t周期内接收第i个数据包的大小;
[0054]
b_packet_i_len表示在t周期内发出第i个数据包的大小;
[0055]
total bwd packets表示在t周期内源ip地址发出数据包的总数量;
[0056]
total length of fwd packets表示在t周期内目的ip地址接收数据包的总大小;
[0057]
total length of bwd packets表示在t周期内源ip地址发出数据包的总大小;
[0058]
步骤4、5,如图3所示,针对每一个openflow交换机,使用步骤3计算得到的数据集作为输入数据,然后将数据用于knn算法分类模型进行训练后得到原始分类模型,并把输入数据和检测结果作为新的训练数据添加至动态更新数据集合。动态更新数据集合数据达到3000条时,并且动态更新分类模型和原始分类模型预测结果不一样的次数小于30次时,将数据用于knn算法分类模型进行训练后得到分类模型。若原始分类模型和动态更新分类模型判断结果一样且为恶意流量,控制器定位攻击目标,删除流表中的攻击流表项并返回给交换机当前的流表信息;若判断结果不一样则判断为正常流量,两个模型预测结果不一样的次数增加1,如果两个模型预测结果不一样的次数超过30次,动态更新数据集合数据清零,防止预测结果和实际结果偏差过大。若动态更新数据集合数据未达到3000条时,判断结果只取决于原始分类模型。
[0059]
基于特征遍历选择和模型动态更新分类算法的分布式拒绝服务攻击检测算法原理:
[0060]
(1)特征遍历选择(feature traversal selection):ddos攻击时,某些特征的值会急剧变大或者变小,选取特征值前30%小的数据和后30%大的数据不仅更有代表性而且可以只使用部分的数据,减少寻找特征的速度。依次将特征值从小到大进行排序后选取该特征前30%数据,若该部分数据中恶意流量占比超过60%,将该特征加入集合1;选取该特征后30%数据,若该部分数据中恶意流量占比超过60%,将该特征加入集合2。对两个集合的特征进行遍历、训练和预测,选择效果最好且数量较少的特征作为新的数据集。
[0061]
(2)knn算法模型具体步骤如下:
[0062]
1)计算测试数据与各个训练数据之间的距离;
[0063]
2)按照距离递增的顺序进行排序;
[0064]
3)选择距离最近的k个样本数据;
[0065]
4)计算前k个样本所在类别的频率/均值;
[0066]
5)返回前k个样本出现频率最高/(加权)均值作为测试数据的类别/预测值。具体使用公式如下:1ꢀ‑‑
rand-source-i u10000-c 1000 192.168.1.150命令对目标主机发起ddos攻击,使用随机源ip地址模式并改变发包的速度。通过控制器获取每个交换机的流表信息采集数据,将数据用于knn算法分类模型进行训练后得到原始分类模型,并把输入数据和检测结果作为新的训练数据添加至动态更新数据集合。
[0078]
步骤4,动态更新数据集合数据达到3000条时,并且动态更新分类模型和原始分类模型预测结果不一样的次数小于30次时,将数据用于knn算法分类模型进行训练后得到分类模型。若原始分类模型和动态更新分类模型判断结果一样且为恶意流量,控制器定位攻击目标,删除流表中的攻击流表项并返回给交换机当前的流表信息;若判断结果不一样则判断为正常流量,两个模型预测结果不一样的次数增加1,如果两个模型预测结果不一样的次数超过30次,动态更新数据集合数据清零,防止预测结果和实际结果偏差过大。若动态更新数据集合数据未达到3000条时,判断结果只取决于原始分类模型。只使用原始数据进行预测时,预测效果accuracy为97.18%,recall为97.60%,precision为 98.49%。使用模型动态更新分类算法时,预测效果accuracy为98.54%,recall为92.28%, precision为99.45%。
[0079]
下表1为只使用原始数据进行预测和使用模型动态更新分类算法一起预测进行比较,表明使用动态更新数据预测结果的效果更优。
[0080]
表1
[0081][0082]
实施例二:
[0083]
为了更好了体现模型的优势,使用更多的模型评估参数进行对比。利用公开数据集提取所需特征数据集,对数据进行预处理,将其按照6:4比例分为训练集和测试集,训练集用于训练模型确定模型参数,测试集用于评估模型,评估模型使用混淆矩阵来评判,混淆矩阵是能够比较全面的反映模型的性能,从混淆矩阵能够衍生出很多的指标。其中:
[0084]
tp(truepositive):真正例,实际为正预测为正;
[0085]
fp(falsepositive):假正例,实际为负但预测为正;
[0086]
fn(falsenegative):假反例,实际为正但预测为负;
[0087]
tn(truenegative):真反例,实际为负预测为负。
[0088]
首先针对准确率(accuracy)来评估模型,准确率(accuracy)的定义是:对于给定的测试集,分类模型正确分类的样本数与总样本数之比,其计算公式如下。通过测试得到如表2所示,通过比较得出,此发明方法检测的准确率比其他几种方法更优。
[0089]
利用精度(precision)和f1分数(f1 score)评估模型,精度定义为查准率,即正确预测为正占正确预测为正和错误预测为正的比例;f1分数定义为查准率和查全率的积占查准率和查全率的和的比例,是为了兼顾查准率和查全率,计算公式如下。
[0090][0091]
在公开数据集中以特征遍历选择的方法选出的特征为total backward packets、totallength of fwd packets和total length of bwd packets,选取对应的特征数据集,使用knn 分类算法,将其按照6:4比例分为训练集和测试集。得到效果accuracy为99.82%,f1 score 为99.84%,precision为99.78%。
[0092]
对比例1:
[0093]
在aksu et al.(2018)8中,选取的特征为fwd packet length mean、avg fwd segmentsize、fwd packet length max、bwd iat min和total length of fwd packets,选取对应的特征数据集,使用knn分类算法,将其按照6:4比例分为训练集和测试集。得到效果 accuracy为97.38%,f1 score为97.75%,precision为95.62%。
[0094]
对比例2:
[0095]
在aamir and zaidi(2019)中,选取的特征为bwd packet length std、average packetsize、flow duration和flow iat std,选取对应的特征数据集,使用随机森林分类算法,将其按照6:4比例分为训练集和测试集。得到效果accuracy为99.52%,f1 score为99.58%, precision为99.76%。
[0096]
对比例3:
[0097]
在salva et al.(2020)中,选取的特征为flows iat std、bwd packet length std、flowsduration和total avg packet size,选取对应的特征数据集,使用聚类算法。得到效果 accuracy为99.55%,precision为95.24%。
[0098]
下表2为在公开数据集中他人使用的特征数据集和自己使用的特征数据集进行预测的效果对比。
[0099]
表2
[0100][0101]
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,对各种可能的组合方式不再另行说明。
[0102]
此外,本实施例的各种不同的实施方式之间也可以进行任意组合,只要其不违背技术方案的设计思想,其同样应当视为所公开的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1