基于上下文强化学习的码率自适应方法及控制器构建方法
本发明涉及视频通信,特别涉及一种基于上下文强化学习的码率自适应方法及控制器构建方法。
背景技术:
1、目前,随着网络在线观看视频的需求不断增长,视频流媒体传输已经成为了整个通信网络中不可忽略的流量组成部分。而用户在线观看流媒体视频时,不同用户的网络环境会导致不同用户的整体观看体验不同,包括不同的观看画面质量、卡顿和延迟。
2、动态流媒体码率自适应技术是为了最大化用户在线观看视频的体验质量而提出的一种网络服务优化方案。具体的,在视频服务器端,视频服务提供商将给定视频切分为固定播放长度的视频切片序列,每一个视频切片编码多个不同码率的版本。在用户端,流媒体播放器通过观测用户网络环境及播放器视频缓冲区状况通过码率自适应分配方法以最大化用户观看该视频时的总体体验质量为目标,为每一个视频切片选择一个最佳的码率版本进行下载和播放。由于网络吞吐量动态变化、难以预测,优化变量维度高且复杂,因此码率自适应分配问题是一个np-hard问题,无法在多项式时间内取得最优解。此外,现有的深度神经网络的码率自适应方法尽管可以在多项式时间内以较小的计算开销进行最优推断,但是这些方法只能对于与训练样本数据分布相似的环境数据下获得比较好的效果,而不能使用异构的用户网络条件,因此解决码率自适应方法的泛化问题是一个码率自适应方法面临的一大挑战。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种基于上下文强化学习的码率自适应方法及控制器构建方法。
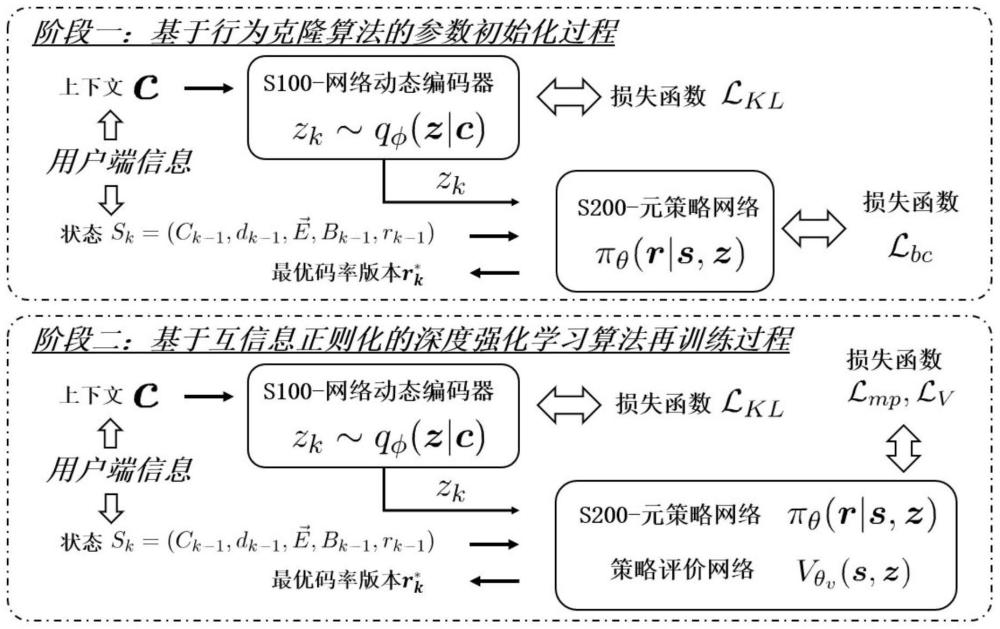
2、根据本发明的一个方面,提供一种基于上下文强化学习的码率自适应控制器的构建方法,包括:
3、构建以网络吞吐上下文信息为输入、当前网络动态隐变量表示为输出的网络动态编码器;
4、构建以用户端信息和所述当前网络动态隐变量表示为输入、当前视频切片的最优码率版本为输出的码率自适应元策略网络;
5、对所述网络动态编码器和码率自适应元策略网络组成的全局模型通过行为克隆方法进行预训练,利用基于互信息正则化的近端策略优化方法进行再训练,获得最优的所述网络动态编码器和元策略网络神经网络参数,基于异构的用户端,对所述神经网络参数微调,获得码率自适应控制器。
6、优选地,用户端请求下载第k个视频切片时,所述用户端信息表示为:
7、
8、其中:ck-1为下载第k-1个视频切片期间记录的平均网络吞吐量;dk-1为下载第k-1个视频切片期间记录的平均下载时间;为第k个视频切片所有码率版本的流文件大小信息;bk-1为用户端的当前播放器缓冲区大小;rk-1为所下载的第k-1个视频切片的码率版本;此外,将从下载第k-p个视频切片到下载第k-1个视频切片期间记录的平均下载时间和平均网络吞吐量定义网络上下文信息c={(ck-p,dk-p),…,(ck-1,dk-1)}。
9、优选地,所述网络动态编码器由输入层、中间层和输出层共三层神经网络以串联方式依次连接构成,其中:
10、所述输入层为激活函数为leakyrelu函数的一维卷积神经网络,所述中间层为激活函数为leakyrelu函数的全连接神经网络,所述输出层为两个无激活函数的全连接神经网络,输出维度均为nz,神经网络参数统一表示为φ;
11、所述输出层有两个输出,分别代表隐变量表示概率分布的均值μk和方差σk,其中当前网络动态隐变量表示zk从μk、σk构建的高斯分布中进行一次采样获取,即c为上下文信息,z和zk一致,表示当前网络动态隐变量。
12、优选地,所述元策略网络πθ(r|s,z)由输入层、中间层和输出层共三层神经网络以串联方式依次连接构成,其中:
13、所述输入层包括六个并行的神经网络单元:激活函数为leakyrelu函数的用于处理所述用户端信息的的一维卷积神经网络,激活函数为leakyrelu函数的用于分别处理所述用户端信息的{ck-1,dk-1,bk-1,rk-1,zk}的五个全连接神经网络,同时,以上网络的输出结果经过拼接后形成一个张量,作为中间层的输入;所述中间层是激活函数为leakyrelu函数的全连接神经网络;所述输出层是一个激活函数为softmax函数的全连接神经网络,输出维度为m,神经网络参数统一表示为θ;
14、所述输出层的输出为{πθ(r1|s,z),…,πθ(rm|s,z)},其中πθ(ri|s,z)表示为第i个码率版本是最优码率版本的概率,m为可供下载的码率版本个数,通过贪婪策略选择最优码率版本此处,s和sk一致,表示客户端信息。
15、优选地,所述通过行为克隆方法进行预训练,包括:
16、定义行为克隆损失函数:
17、
18、为给定用户状态信息s条件下随机变量z和随机变量r的条件互信息,λ为权重系数,πe(r|s)为码率自适应专家策略,为专家策略选择的码率版本;
19、定义kl散度损失函数
20、
21、其中dkl(·||·)为两个概率分布之间的kl散度计算函数,β为权重系数,p(z)为隐变量表示z的先验概率分布;
22、对神经网络参数集合(φ,θ)进行优化:
23、
24、其中,α3,α1分别为网络动态编码器qφ(z|c)和元策略网络πθ(r|s,z)的学习率参数,▽表示梯度算符。
25、优选地,所述利用基于互信息正则化的近端策略优化方法进行再训练,包括:
26、额外构建一个参数为θv的策略评价神经网络输出结果表示为在策略πθ(r|s,z)下当前状态s和隐变量表示z所能获得的期望收益,该神经网络除输出层为无激活函数的单个神经元外,其余网络架构与所述元策略网络πθ(r|s,z)相同;
27、所述再训练,包括基于互信息正则化的近端策略优化损失函数值函数损失函数和kl散度损失函数其中,损失函数和为:
28、
29、
30、ρ(θ)=πθ(r|s,z)/πθ′(r|s,z),z~qφ(z|c),
31、
32、
33、
34、gk=qoek+γqoek+1+γ2qoek+2+…
35、其中,clip[ρ(θ),1-∈,1+∈]对ρ(θ)进行数值裁剪,确保ρ(θ)的值始终在(1-∈,1+∈)之间,ε∈(0,1),γ∈(0,1),θ′为上一轮参数迭代优化之前的旧参数值,qoek为用户下载第k个视频切片的第个码率版本并播放后获得的观看体验质量值,为元策略网络πθ(r|s,z)的推断的最优码率版本;
36、对神经网络参数集合(φ,θ,θv)进行优化,其中,网络动态编码器的参数更新只使用损失函数和的梯度:
37、
38、α3,α1,α2分别为网络动态编码器qφ(z|c)、元策略网络πθ(r|s,z)和策略评价神经网络的学习率参数,表示梯度算符。
39、优选地,所述互信息正则项的数学表达式为:
40、
41、
42、其中,nsa为采样次数,p(z)为隐变量表示z的先验概率分布。
43、优选地,将训练好的全局模型部署到分布式的、异构的用户端进行最优码率决策;
44、在用户端,根据本地网络状态,即用户端本地记录的历史带宽数据集对全局模型进行参数微调,成为本地模型;其中,微调过程进行少量的参数迭代即可快速自适应本地网络状态。
45、优选地,所述参数微调采用与所述全局模型相同的基于互信息正则化的深度强化学习方法。
46、根据本发明的第二个方面,提供一种基于上下文强化学习的码率自适应方法,包括:
47、在视频服务器端,将视频流在时间上切分为k个固定播放长度的视频切片序列,每一个所述视频切片编码为m个不同码率的版本并缓存;
48、将用户端信息和第k个视频切片请求信息反馈给码率自适应控制器;所述码率自适应控制器采用任一项所述方法构建;
49、码率自适应控制器基于所述用户端信息和第k个视频切片请求信息,推断所述第k个视频切片的最优码率版本并将该版本信息和第k个视频切片请求信息发送至视频服务器端;
50、所述视频服务器端依据所述最优码率版本信息将对应码率视频切片发送至用户端。
51、与现有技术相比,本发明具有如下的有益效果:
52、本发明实施例中的基于上下文强化学习的码率自适应方法及控制器构建方法,通过构建以网络吞吐上下文信息c为输入、当前网络动态隐变量表示zk为输出的网络动态编码器和以用户状态信息sk和当前网络动态隐变量表示zk为输入、当前视频切片的最优码率版本为输出的码率自适应元策略网络πθ(r|s,z),利用基于互信息正则化的近端策略优化方法优化该模型的网络参数,最终获得最优的网络动态编码器和元策略网络神经网络参数,能够快速自适应异构用户的本地网络带宽环境,从而最大化用户的整体观看体验质量,提高了网络视频流传输的带宽利用率和鲁棒性;
53、本发明实施例中的基于上下文元强化学习的码率自适应方法,通过设计可以为任意现有码率自适应方法或人工标记方法得出的码率自适应专家策略,并通过行为克隆方式快速学习较好的神经网络参数,以较低的训练代价获得一个较好的参数初始化,进而极大地提高参数训练的样本采样效率,提高了模型训练速度,减少了模型训练计算开销。
- 还没有人留言评论。精彩留言会获得点赞!