数据编码的方法及装置与流程
本技术涉及存储领域,尤其涉及一种数据编码的方法及装置。
背景技术:
1、众所周知,随着数据爆炸式地增长,分布式存储节点越来越多。为了使得分布式存储系统具备一定的容错能力,技术人员通常采用纠删码(erasure coding,ec)技术来保证存储数据的可靠性以及可用性。上述纠删码技术是一种数据保护方法,它主要是将原始数据进行编码得到冗余数据,再将原始数据和冗余数据存储起来,若原始数据和冗余数据中的部分数据丢失,还可以利用剩余的数据恢复丢失的数据,从而达到容错的目的。
2、原始数据编码完成后,需要将原始数据和冗余数据从内存分离系统的计算节点传输至存储节点。现有技术通常是计算节点负责将大的数据对象拆分为小的数据对象并对小的数据对象进行编码计算,随后采用高速传输网络将编码后的数据对象传输至存储节点以完成数据存储。随着网络传输速度越来越快,数据编码速度与网络传输速度的差距越来越大,从而导致高速传输网络传输数据的时间与编码数据所需要的时间不匹配,进而造成数据传输流水线阻塞,最终,影响分布式存储系统部署纠删码的效率。因此,如何提高编码计算的效率是当前急需解决的问题。
技术实现思路
1、本技术提供一种数据编码的方法及装置,解决了现有技术中编码计算的效率低的问题。
2、为达到上述目的,本技术采用如下技术方案:
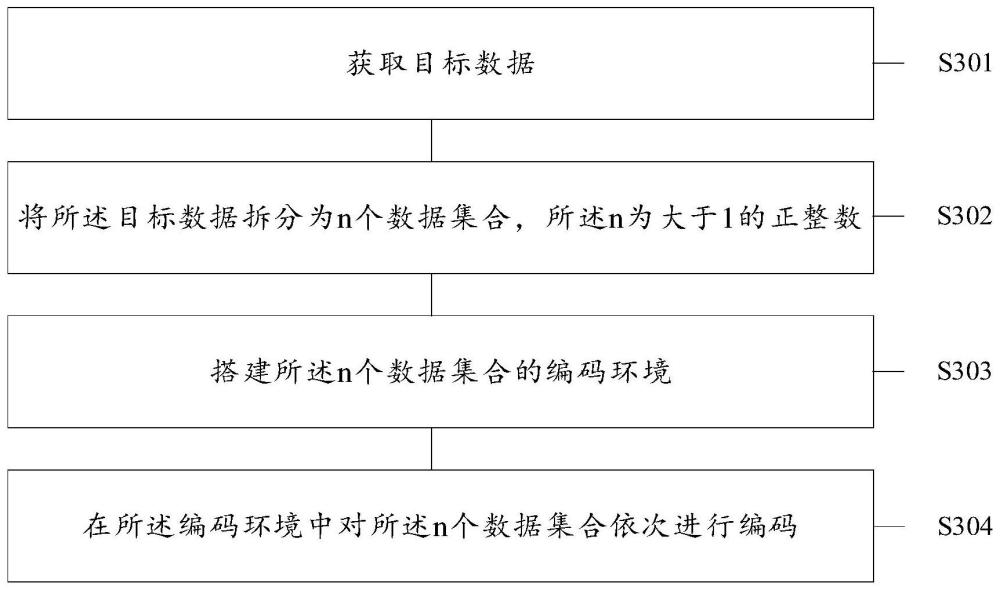
3、第一方面,提供一种数据编码的方法,所述方法包括:获取目标数据;将所述目标数据拆分为n个数据集合,所述n为大于1的正整数;搭建所述n个数据集合的编码环境;在所述编码环境中对所述n个数据集合依次进行编码。
4、上述方法在对目标数据进行编码时,先将目标数据拆分为n个数据集合(即n个数据块),之后,对每个数据集合(即每个块数据)进行编码;随后,在对n个数据集合编码前搭建编码n个数据集合共用的编码环境。相比现有技术中每次编码一个数据块都需要提前搭建一次编码环境,本技术编码n个数据块只需要搭建一次编码环境,就可以满足所有数据块在该编码环境中进行编码,不仅避免了多次搭建编码环境占用计算机资源的情况,还缩短了编码n个数据集合所需的编码时间,提高了编码计算的效率。
5、可选地,所述n个数据集合中各个数据集合的大小小于处理器的一级缓存的大小。
6、与现有技术中将目标数据拆分为任意大小的数据块的方案相比,本实施例拆分得到的n个数据集合中单个数据集合的大小需要适配处理器的一级缓存的大小(即,各个数据集合的大小小于处理器的一级缓存的大小),这样拆分的原因在于,一级缓存内置在处理器内部并与处理器同速运行,若待编码的单个数据集合的大小能适配一级缓存的大小,则该单个数据集合就可以一次性加载至一级缓存中,而无需多次加载,从而减小了处理器等待单个数据集合的时间,进而提高处理器编码计算的效率。
7、可选地,所述搭建所述n个数据集合的编码环境,包括:在内存中为所述n个数据集合中的第一数据集合分配缓冲区;在所述一级缓存中加载编码矩阵;在所述一级缓存中生成无符号数乘法指令表;在所述一级缓存中加载编码所述第一数据集合的编码指令集。
8、在本实施例中,由于编码n个数据集合中的每个数据集合均需要经过分配缓冲区、加载编码矩阵、生成乘法指令表以及加载编码指令集这些处理步骤,现有技术通常每编码一个数据集合经历一次上述处理步骤,显然,既浪费计算机资源也影响编码效率;为此,本实施例基于一级缓存的时间局部性(即一级缓存对于正在使用的相关数据不会立即清除的特性),在第一次编码n个数据集合中某个数据集合时,就在一级缓存中将上述处理步骤搭建为一个共用的编码环境,这样,n个数据集合中的各个数据集合均可以使用一级缓存中的上述编码环境,无需每编码一个数据集合就搭建一次编码环境,从而节省了计算机资源以及提高了编码效率。
9、可选地,所述在所述编码环境中对所述n个数据集合依次进行编码,包括:在所述一级缓存中加载所述第一数据集合及其对应的奇偶校验块;使用所述缓冲区、所述编码矩阵、所述无符号数乘法指令表和所述编码指令集对所述第一数据集合进行编码;所述第一数据集合编码完成后,在所述一级缓存中加载所述第二数据集合及其对应的所述奇偶校验块;使用所述缓冲区、所述编码矩阵、所述无符号数乘法指令表和所述编码指令集对所述第二数据集合进行编码。
10、在本实施例中,在对第一数据集合进行编码计算时,已经在一级缓存中搭建好n个数据集合共用的编码环境;当对第一数据集合进行编码计算时,可以直接使用上述编码环境(即使用缓冲区、编码矩阵、无符号数乘法指令表和编码指令集)对第一数据集合进行编码;由于一级缓存的时间局部性(即一级缓存对于正在使用的相关数据不会立即清除的特性),当第一数据集合编码结束后,一级缓存并不会立即清除上述编码环境;因此,在编码第二数据集合时无需重新搭建上述编码环境,可以直接复用第一数据集合编码时在一级缓存中搭建的编码环境进行编码,从而避免了每次编码均需要搭建编码环境所耗费的时间资源和一级缓存资源,进而提高编码计算的效率。
11、可选地,所述n个数据集合包括第一数据集合,所述第一数据集合包括多个数据,所述对所述n个数据集合依次进行编码之前,还包括:从所述第一数据集合的第一地址开始读取所述多个数据,所述第一地址为所述多个数据的存储空间的起始地址。
12、相比现有技术中将上述n个数据集合存储在不同物理磁盘上而产生的巨大磁盘开销,本实施例将n个数据集合存储在同一个物理位置上的不同内存地址范围内,并且,每个数据集合所在的地址是连续的。这样在读取n个数据集合(比如,第一数据集合)时,只需要从每个数据集合的起始地址(比如,第一数据集合的第一地址)依次读取,而无需跨磁盘读取;这样不仅节省了磁盘开销,还可以高效且连续地读取n个数据集合。
13、可选地,对所述n个数据集合中的g个数据集合的编码结果进行合并,生成第一合并数据包,所述第一合并数据包的大小小于或等于预设网络传输粒度,所述g为大于1且小于n的正整数;通过所述传输网络发送所述第一合并数据包。
14、随着网络传输速度以及带宽提高,通过网络传输小数据包不仅浪费网络资源而且传输效率低下;本实施例将g个数据集合的编码结果(即编码数据)进行合并,得到匹配(即小于或等于)网络传输粒度的第一合并数据包,并通过网络传输该第一合并数据包,这样不仅节省网络传输资源而且传输效率高。
15、可选地,所述对所述n个数据集合依次进行编码,包括:在生成所述g个数据集合的编码结果后,并且,在生成所述第一合并数据包前,对所述n个数据集合中的第g+1个数据集合进行编码。
16、在本实施例中,cpu在对g个数据集合编码结束后,并且,在生成第一合并数据包前,就开始对第g+1个数据集合进行编码;而不是等待第一合并数据包发送结束后才开始对第g+1个数据集合进行编码,这样不仅避免了cpu编码与网络传输的流水线阻塞的问题,还缩短了cpu编码n个数据集合的时间,进而提高了编码效率。
17、可选地,对所述n个数据集合中的第g+1个数据集合至第2g个数据集合的编码结果进行合并,生成第二合并数据包,所述第二合并数据包的大小小于或等于所述预设网络传输粒度,所述第二合并数据包的生成时刻与所述第一合并数据包的发送结束时刻相同;通过所述传输网络发送所述第二合并数据包。
18、在本实施例中,第二合并数据包的生成时刻与第一合并数据包的发送结束时刻相同,说明生成第二合并数据包的时刻与发送第一合并数据包的时刻之间没有间隔,这样,网络传输相邻合并数据包(如第一合并数据包和第二合并数据包)之间无空闲时间,从而形成编码与网络传输的无阻塞(即高效)流水线,提高了网络传输效率。
19、第二方面,提供一种数据编码的装置,所述装置包括获取模块、拆分模块、搭建模块和编码模块,所述获取模块,用于获取目标数据;所述拆分模块,用于将所述目标数据拆分为n个数据集合,所述n为大于1的正整数;所述搭建模块,用于搭建所述n个数据集合的编码环境;所述编码模块,用于在所述编码环境中对所述n个数据集合依次进行编码。
20、第三方面,提供了一种电子设备,包括处理器和存储器,所述存储器用于存储计算机程序,所述处理器用于从所述存储器中调用并运行所述计算机程序,使得所述电子设备执行第一方面中任一项所述的方法。
21、第四方面,提供了一种计算机可读存储介质,所述计算机可读存储介质存储了计算机程序,当所述计算机程序被处理器执行时,使得所述处理器执行第一方面中任一项的方法。
22、第五方面,提供了一种计算机程序产品,所述计算机程序产品包括:计算机程序代码,当所述计算机程序代码被数据编码的装置运行时,使得该装置执行第一方面中任一种方法。
23、在本技术的第二方面、第三方面、第四方面和第五方面的技术方案的有益效果与第一方面的技术方案的有益效果相同,不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!