用于确定HRTF的方法和听力设备与流程
本发明涉及一种用于确定hrtf的方法以及听力设备,在这种听力设备中可以使用这种hrtf。hrtf意为“head related transfer function”,即头部相关传递函数。
背景技术:
1、听力设备一般用于向用户输出音频信号。为此,听力设备具有至少一个听筒(也称为扬声器或者接收器),借助其将音频信号转换为声音信号。听力设备通常由用户佩戴在耳朵中或者上。在一个可能的设计方案中,听力设备尤其用于供应听力受损的用户。为此,听力设备具有麦克风,麦克风接收来自环境的声音信号并且由此产生作为电输入信号的音频信号。将该电输入信号馈送到听力设备的信号处理装置,以进行修改。例如根据与听力设备相关联的用户个人的听力图(audiogramm)来进行修改,从而补偿用户个人的听力缺陷。信号处理装置作为结果输出作为修改后的音频信号的电输出信号,然后又经由听力设备的听筒将电输出信号转换为声音信号,并且向用户输出。
2、听力设备要么是单耳的,然后仅佩戴在头部的一侧,要么是双耳的,然后具有佩戴在头部的不同侧的两个单设备。根据类型,听力设备佩戴在耳朵上、耳朵内或耳朵后或者其组合上。常见的听力设备类型例如是bte、ric和ite听力设备。这些设备的不同之处特别是在于其结构形式和佩戴方式。
3、hrtf是如下的传递函数(“transfer function”),该传递函数给出来自环境的声音信号在进入人的耳道的过程中如何被他们的身体形状、尤其是他们的头部形状(“headrelated(头部相关)”)所修改。hrtf是特定于声音信号(即声学信号)的传递函数。在听力设备中,hrtf以合适的方式在信号处理装置中进行修改时使用,并且在此特别是使得能够保持或生成空间噪声信息(所谓的“空间线索(spatial cues)”),使得用户能够更好地定位相应的噪声源。
4、一般而言,来自音频源的声音信号在环境中传播,由此也到达听力设备用户的耳朵和耳道中。声音信号到达耳道中的路径也称为声学路径。声音信号沿声学路径的修改取决于用户的身体,尤其是是躯干和头部的相应的形状,特别是耳朵的形状,尤其是外耳(即耳廓(pinna))的形状。因此,实际的hrtf通常是针对个人的,并且对于每个用户都是不同的。然而,一般使用非个人的hrtf,其例如借助假人(例如kemar)来确定,然后用于大量有时不同的用户。然而,因此,用户个体的身体形状通常没有得到充分考虑,在任何情况下都保持没有考虑到与假人的可能的偏差。
5、原则上,可以想到为相应的用户确定单独的hrtf。为此,将用户放置在一个尽可能无回声的空间中,并暴露于来自不同侧面的声音信号中。为此,多个扬声器被放置在用户周围的固定的预定给定的位置。接收声音信号的麦克风被放置在听力设备的听筒稍后将所在的位置,即在用户的耳朵中或耳朵上。然后,可以通过将发射的声音信号与接收的声音信号进行比较来确定单独的hrtf。这种方法产生了非常好的结果,但是成本也非常高昂。
6、us 9 591 427 b1描述了一种由智能电话执行的方法,用于生成佩戴耳机的人的hrtf。利用智能电话中的照相机,基于人脸的图像来确定智能电话相对于人脸的位置。在智能电话位于人的一只手上并靠近人脸时,利用智能电话产生声音,其中,还存储智能电话相对于人脸的位置。然后,利用人的左耳中的耳机的左麦克风和人的右耳中的耳机的右麦克风来检测该声音。最后,利用智能电话生成左hrtf和右hrtf。
技术实现思路
1、在这种背景下,本发明要解决的技术问题是,尽可能以特定于用户的方式确定hrtf并且为此考虑用户个体的身体形状。在此,hrtf的确定应当尽可能简单,并且尽可能不干扰用户。为此,要给出一种用于确定hrtf的方法,用于与听力设备一起使用。此外,要给出一种对应的听力设备。
2、根据本发明,上述技术问题通过具有本发明的特征的方法以及通过具有本发明的特征的听力设备来解决。有利的设计方案、扩展方案和变形方案是下面的描述的主题。结合方法的描述同样也适用于听力设备,反之亦然。如果下面描述方法的步骤,则特别是通过听力设备具有控制设备,控制设备被构造为用于执行这些步骤中的一个或多个,适宜地得到针对听力设备的设计方案。
3、本发明的核心思想特别是在于使用音频源来确定针对特定用户的hrtf,音频源可以以声学方式和非声学方式输出音频信号。音频源优选地是媒体设备,即特别是用于输出和/或回放媒体(例如音频、视频)的设备。特别是,用户在日常生活中反复使用音频源。以声学方式输出的音频信号沿着声学路径传播到用户,尤其是传播到用户的听力设备的麦克风,并且通过用户的圣体形状沿着声学路径进行修改。这种修改由对应于用户实际的个人的hrtf的传递函数来定义。另一方面,以非声学方式输出的音频信号不会被该hrtf修改,从而可以通过比较两个不同地传输的音频信号来为用户单独确定hrtf。在此,实现这一点,以便随后以特定于用户的方式确定hrtf。同时,该方法可以有利地在用户的日常生活中以及在听力设备的常规使用期间使用各种音频源来执行,也就是说,不需要任何特殊的测量环境或测量设备,而且仅最少地或根本不干扰用户。
4、这里描述的方法通常用于确定hrtf(即“head-related transfer function”或头部相关传递函数)。hrtf特别是用于用户的听力设备的常规运行。hrtf有利地是以特定于用户的方式针对该用户确定的。“确定”特别是指确定或测量hrtf。hrtf要么从头开始确定,要么从不特定于用户的基本hrtf开始确定,然后在所述方法的过程中进行调整和优选优化,以便作为结果获得特定于用户的hrtf。hrtf例如是具有一个或多个参数的参数化的函数,这些参数在确定hrtf的过程中被选择和/或调整。
5、在所述方法中,音频源输出源音频信号,即以声学方式作为声音信号以及以非声学方式作为数据信号输出源音频信号。源音频信号是音频信号并且本身特别地是电信号。源音频信号也称为“原始音频信号”。对于源音频信号的声学方式输出,音频源具有扬声器,即电声转换器,通过起将源音频信号转换为声音信号并输出。相同的源音频信号也在另一个非声学通道上输出,即作为数据信号输出。对于源音频信号的非声学方式输出,音频源具有数据输出端,该数据输出端将源音频信号作为数据信号输出,并且为此可能将其转换为合适的数据格式。数据输出优选地是用于无线电连接(例如蓝牙或wifi)的天线,从而无线地传输数据信号。有线传输也是可以想到的并且是合适的,数据输出端是相应的连接端(例如音频插座或usb端口)。最初重要的是相同的音频信号(即源音频信号)在两个不同的通道上输出,即一次以声学方式作为声音信号,一次以非声学(例如电、电磁、光学)方式作为数据信号输出。
6、声音信号被听力设备接收并被听力设备再次转换为音频信号,即转换为第一音频信号。该第一音频信号也称为“声学传输的音频信号”,因为它是通过将源音频信号转换为声音信号并从该声音信号重新转换而得到的。尤其是在用于供应听力受损的用户的听力设备的情况下,接收来自环境的声音信号是听力设备的原始功能。
7、数据信号由听力设备或由从数据信号产生第二音频信号的另一设备接收,特别是通过数据输入,例如天线。该另一设备(如果存在)尤其是连接到听力设备以进行数据交换的附加设备,例如通过蓝牙或wifi。例如,该另一设备是智能电话。原则上,音频源本身也可以是该另一设备,但在下面在不限制一般性的情况下假设不是这种情况。第二音频信号也称为“非声学传输的音频信号”,因为它由源音频信号产生或者甚至与其相同而没有以声学方式进行传输。除了声音信号和数据信号在物理上看以两种不同的方式传输之外,声音信号和数据信号优选地也在不同的频率范围内传输。因此,声音信号特别是在从20hz到20khz的可听频率范围内传输,数据信号在例如在1mhz和10ghz之间的通信频率范围内传输,并且在任何情况下在大几个数量级的频率下传输。
8、第一和第二音频信号分别是源音频信号的传输的(并且因此也可能是修改后的)版本。为了完整起见,也将源音频信号称为“第三音频信号”。
9、将第一音频信号和第二音频信号,即在不同通道上传输的音频信号,相互进行比较,并基于此,即基于比较,确定hrtf。这基于第二音频信号通常在很大程度上于源音频信号一致并且至少不受hrtf影响的考虑。相比之下,声音信号已被hrtf修改,因此第一音频信号相应地与源音频信号不同。因此,在一阶近似中,在声学传输的第一音频信号a1和非声学传输的第二音频信号之间适用以下关系:a2:a2=hrtf(a1)。具体如何进行比较本身是无关紧要的。更重要的是,通过数据信号,可以获得不受hrtf影响的音频信号,将该音频信号用作参考信号,来确定实际的、特定于用户的hrtf。
10、在一个合适的设计方案中,为了确定hrtf,将第一音频信号用作目标信号并且将第二音频信号用作实际信号。以这种方式,hrtf取决于声音信号和数据信号之间的差异(更准确地说,取决于第一和第二音频信号之间的差异)来确定。具体如何计算hrtf最初是无关紧要的,尤其取决于hrtf的参数化方式,即它是由哪些参数定义的。原则上,可以通过对应的计算能力进行数值优化。在此,各个参数(包括系数)会发生变化,直到达到最小偏差(即最小值或至少是稳定的并且可能只是局部最小值)为止。例如,一种合适的优化算法是lasso(即“least absolute shrinkage and selection operator(最小绝对收缩和选择算子)”)。
11、以上面提到的方式确定的hrtf特别是存储在听力设备中并且优选地在运行期间由听力设备的信号处理装置使用,以便最终使听力设备输出的声音信号适应于用户。hrtf的具体用途这里不再重要。hrtf的可能用途例如是生成带有空间信息注释并且适用于为步行用户进行导航的声学提示,将空间信息添加到流信号中,以便用户听起来好像它来自音频源,例如来自特定空间方向的电视。hrtf的另一个示例性的用途是虚拟操作元件,其中,例如通过空间效果以声学方式表示操作元件(例如滑块)的位置(例如根据操作元件的位置强调右侧或左侧)。尤其是使用hrtf来修改音频输出对于“入耳式”耳机是有利的。
12、在一个具体的合适的设计方案中,为了确定hrtf,仅从第一和第二音频信号中分别提取片段、即所谓的样本并存储为数据组。相应的数据组的两个片段(来自第一音频信号的片段和来自第二音频信号的片段)优选地源自相同的时间间隔或者具有一致的时间戳。由此确保实际上也通过比较两个部分来正确地确定hrtf。通常,记录、存储和评估大量此类数据组,以确定hrtf。这可以在听力设备上、所描述的附加设备上或单独的计算机(例如服务器)上进行。
13、如已经指出的,hrtf优选地是参数化的,即是具有多个参数的函数,这些参数可以根据用户而变化。在确定hrtf时,这些参数尤其被优化,因此以特定于用户的方式进行调整。hrtf优选地被连续确定,从而所使用的hrtf随着时间越来越接近实际的单独的hrtf。就此而言,于是所述方法是迭代的。此外,由此,也有利地考虑了用户的身体形状的变化。
14、在不限制一般性的情况下,在此假设听力设备是用于供应听力受损的用户的听力设备。然而,本发明也可以应用于附加地具有一个或多个麦克风的其他听力设备,例如头戴式耳机。用于供应听力受损的用户的听力设备通常具有输入转换器、信号处理装置和输出转换器。这里,输入转换器是麦克风,用于接收来自环境的声音信号,即这里也用于接收由音频源发出的声音信号。输出转换器通常是听筒,其也称为扬声器或接收器。在此,在不限制一般性的情况下假设具有听筒的听力设备,但其他输出转换器也适用于向用户进行输出。听力设备通常与单个用户相关联,并且仅由该用户使用。输入转换器通常产生输入信号,该输入信号被馈送到信号处理装置。在此,输入转换器尤其是也产生第一音频信号,其相应地是输入信号。信号处理装置修改输入信号并由此产生输出信号,该输出信号因此是修改后的输入信号。为了补偿听力损失,例如根据用户的听力图,利用与频率相关的放大因子来放大输入信号。替换地或附加地,根据hrtf修改输入信号。输出信号最终通过输出转换器输出给用户。
15、前面描述的具有电层面上的修改的声音信号的记录和再次输出是听力设备运行时的通常情况,这也称为听力设备的“正常操作”。除了正常操作之外,这里描述的听力设备优选地还具有流式操作,其中向用户的输出基于由音频源发出的数据信号。流式操作的优点是可以省去并且优选地也省去了声音信号的来回转换,并且音频信号没有损失并且不受影响地从音频源传输到用户。流式操作例如用于将音频信号从电视设备、计算机或智能电话,一般地来说从音频源,传输到听力设备。听力设备相应地具有数据输入端,该数据输入端被构造为作为音频源的数据输出端的补充,优选地也作为天线。关于数据输出的描述类似地也适用于数据输入,反之亦然。听力设备被合适地构造为,用户可以在正常操作和流式操作之间切换。
16、对于耳机等,可能取消上面描述的正常操作,而流式操作是通常情况。
17、在此,有利地将正常操作和流式操作的功能联合来确定hrtf。一方面,听力设备通过麦克风接收来自音频源的声音信号,因此使用正常操作的功能。另一方面,听力设备从音频源接收数据信号,因此使用流式操作的功能。然后两个音频信号(第一和第二音频信号)中的哪一个实际上再次通过耳机输出给用户并不重要并且适宜听凭用户。与这里描述的方法相关的首先仅仅是存在两个音频信号,以便基于此来确定hrtf。
18、此外,对于这里描述的方法来说,听力设备具有流式操作或一般地来说接收数据信号不是绝对必要的,数据信号也可以由另一个设备来接收。第一和第二音频信号只需要在某个设备上汇集在一起,以便在那里进行比较并基于此来确定hrtf。原则上,听力设备适用于此,但是计算机、特别是服务器同样也适用,其通常的特点是计算能力明显高于听力设备。也可以想到,虽然由听力设备接收数据信号,但是hrtf不由听力设备来确定,而是例如由智能电话或服务器来确定,听力设备向其发送音频信号或相应的数据组。
19、然而,听力设备接收到声音信号对于正确确定hrtf是很重要的,因为听力设备是由用户佩戴的,而任何其他设备通常位于远离用户的位置,因此不适合接收沿着声学路径传播到用户耳朵的声音信号。在一个优选的设计方案中,听力设备相应地通过麦克风接收声音信号,麦克风是听力设备的一部分。听力设备必要时甚至具有多个麦克风,通过这些麦克风接收声音信号并生成第一音频信号。听力设备适宜地被构造为,在佩戴状态下,麦克风位于用户的耳朵中或耳朵上。特别是,麦克风因此被定位在用户的耳朵后、耳朵中或耳道中。麦克风的确切位置取决于听力设备的类型。在bte设备的情况下,麦克风位于耳后,在ric设备的情况下位于耳道中,在ite设备的情况下位于耳朵中并且在耳道前方。因此必要时不考虑直到耳道中的整个声学路径,并且相应地仅针对声学路径的一部分确定hrtf,即仅针对声学路径的一个或几个、而不是所有部分确定hrtf。
20、听力设备要么是单耳的,然后仅佩戴在头部的一侧(左侧或右侧),要么是双耳的,然后具有两个单设备,佩戴在头部的不同侧(即左侧和右侧)。在双耳听力设备的情况下,两个单设备分别具有一个或多个麦克风,用于接收声音信号。
21、在确定hrtf时,优选地还考虑关于用户的空间情况。该空间情况优选地选自如下的空间情况的集合,该集合包括并且特别是仅由以下各项构成:用户相对于音频源的位置,用户相对于音频源的距离,用户相对于音频源的朝向,用户的头部相对于其躯干的朝向,用户的姿势。在此,用户的头部相对于他的躯干的朝向是一种特殊的姿势,其他姿势例如是坐、躺、站。头部相对于躯干的朝向优选地是头部围绕用户的纵向身体轴线旋转、头部围绕用户的横向轴线倾斜(即向前/向后点头)或横向弯曲(即头部向一侧倾斜)。
22、然后,在一个合适的设计方案中,确定并且在确定hrtf时考虑相应的空间情况。这基于如下考虑,即,声学路径通常取决于用户的身体相对于音频源如何取向和/或用户采用什么姿势,即声音信号例如是从前方、从后方还是从侧面到达用户,以及其自己的身体、尤其是躯干如何遮挡声音信号。对应地,声音信号在其传播到用户耳朵期间的修改取决于用户与音频源之间的相对空间关系以及用户的姿势,从而hrtf通常也是与情况相关的,特别是与方向相关的和与姿势相关的。为了尽可能最佳地确定hrtf,对应地有利的是,不仅一般地记录尽可能多的数据组,而且记录关于尽可能多的空间情况的数据组,即在尽可能多的不同的用户相对于音频源的相对空间关系和/或针对用户的尽可能多的姿势。由此,于是对应地有利地以与情况相关、尤其是与方向相关和/或与姿势相关的方式来确定hrtf。
23、在此,如何准确地确定空间情况是次要的,因此这里不进一步讨论;原则上,任何已知的用于此目的的方法都是合适的。在一个合适的设计方案中,听力设备为双耳听力设备,并且相应地从两侧的音频源接收声音信号。然后,例如使用在两侧接收到的声音信号的时间偏移或幅度差来确定用户相对于音频源的朝向。也可以想到并且合适的是跟随(即“跟踪(tracking)”)用户,例如使用音频源的照相机或用户佩戴的附加设备中的信标。如下的设计方案也是合适的,在这种设计方案中,相应地确定音频源和听力设备的绝对位置,然后通过计算位置之间的差来确定相对空间关系。例如使用特别是听力设备的陀螺仪或磁力计,通过对用户的视频观察,来确定头部的朝向,或者假设如果较长的时间(例如至少1分钟)没有改变朝向,则朝向是“直视前方”。
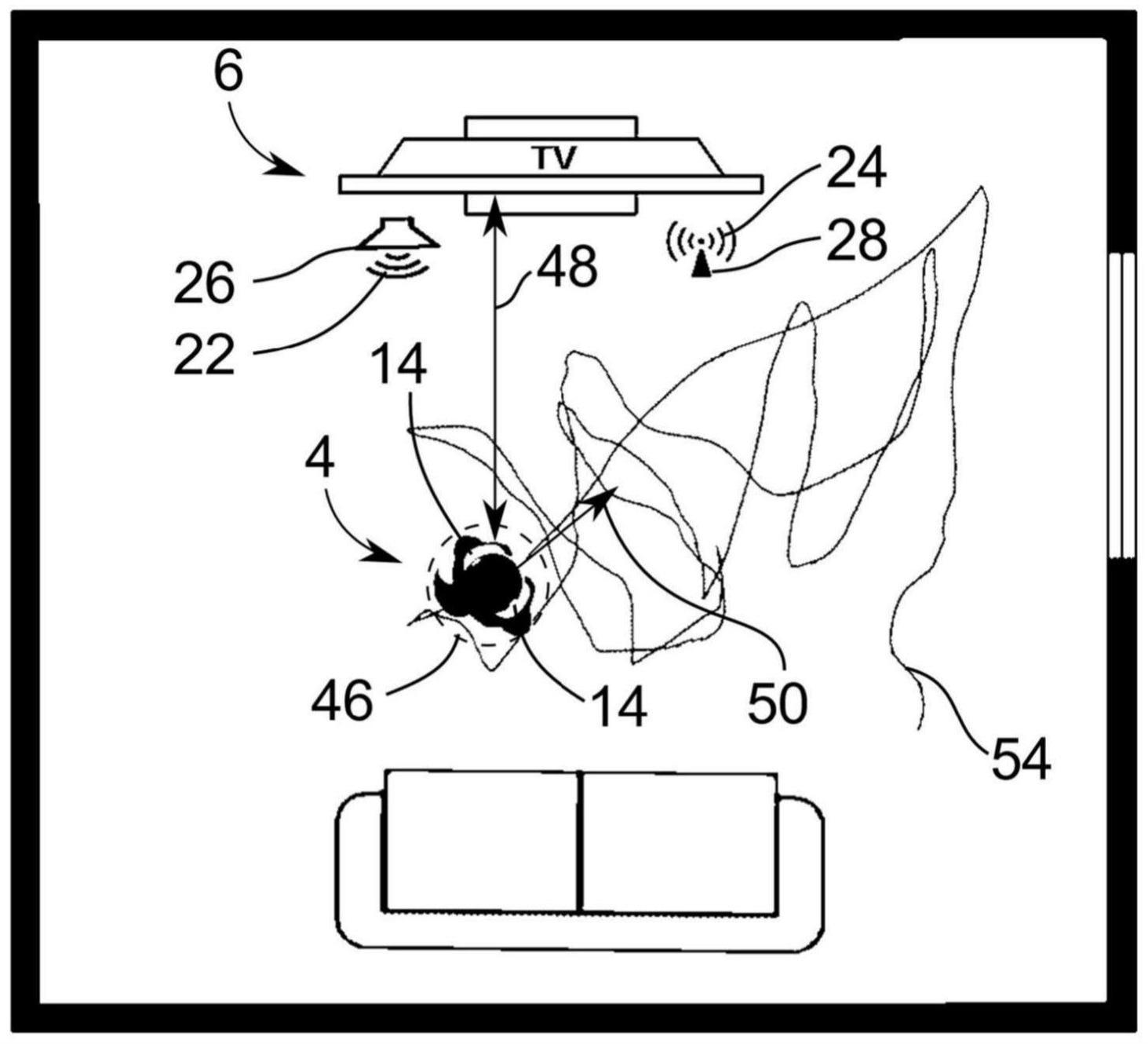
24、为了确定hrtf,适当地作为数据组共同存储第一和第二音频信号中的相应的片段以及关于用户的空间情况。相应的数据组于是不仅包含两个音频信号的样本,而且还附加地包含关于用户相对于音频源的相对空间关系和/或这些样本的时间点的用户姿势的信息。
25、可以以不同的方式来生成数据组,特别是利用用户的不同的参与程度以及在对音频源进行或不进行特殊控制的情况下。
26、首先,如下的设计方案是合适的,在该设计方案中,连续生成数据组,而无需用户采取任何动作或者特殊地控制音频源。因此,在常规使用时,可以说所述方法在后台执行,因此不干扰用户。
27、在一个合适的设计方案中,控制音频源,使得在存在如下的关于用户的空间情况时,即,对于该空间情况仍然不存在最小数量的数据组,音频源输出源音频信号,以便针对该空间情况产生数据组。在这种设计方案中,因此尤其是控制音频源,以便针对性地针对如下的空间情况产生数据组,即,对于这些空间情况,尚不存在足够多的数据组来足够好地确定hrtf。对于相应的空间情况实际需要多少数据组,即最小数量有多大,最初是无关紧要的。例如,最小数量仅为1,或者替换地为10、100或1000。在这种设计方案中,也不需要用户参与,但是专门控制音频源,以便针对性地生成尽可能有意义的数据组。听力设备或另一设备例如检查当前存在哪个位置、距离、朝向和/或身体姿势,以及已经存在的数据组的数量是否至少对应于最小数量。如果不是这种情况,则相应地控制音频源,以便在这种情况下将源音频信号既作为声音信号又作为数据信号输出,从而于是针对当前位置、距离、朝向和/姿势生成数据组。
28、在一个合适的设计方案中,向所述用户输出用于创建一个或多个空间情况的指令,在这些空间情况下,音频源然后相应地输出源音频信号,用于针对这些空间情况相应地产生数据组。该指令例如由听力设备、音频源或另一设备输出。该指令例如是声音的或视觉的。用户是否实际遵循指令取决于他或她自己。但是在任何情况下都存在如下的可能性,即,用户根据指令创建所需的空间情况,从而于是可以针对性地针对其并且也针对其生成数据组。所述方法然后利用用户的参与,但是对音频源的特殊控制不是绝对必要的。
29、如下的设计方案也是有利的,在该设计方案中,听力设备具有测试模式并且在测试模式下向用户输出具有空间噪声信息(即“空间提示”,例如空间定位的噪声)的输出信号,用于促使用户向规定的方向运动或者定向,即特别是噪声可能来自的地方。此外,然后确定用户向哪个实际方向运动或者定向,并将其与规定的方向进行比较,以确定hrtf与用户的匹配度。匹配度特别是给出当前确定的hrtf与实际hrtf的一致程度。这在测试模式中通过以下方式来检查,即,使用当前确定的hrtf来生成输出信号。如果当前确定的hrtf偏离实际hrtf,则用户将错误地将噪声定位在与噪声实际来自的规定的方向不同的方向上,并且通过实际hrtf来修改噪声。因此,测试模式使得能够检查迄今为止确定的hrtf,也可以确定迄今为止确定的hrtf与用户的实际hrtf的一致程度。在一个示例性的设计方案中,促使用户在瞳孔处于中立位置时看向特定的方向。适宜地使用由此于是获得的数据组来测试匹配度。这种方法对用户的要求比让他们运动通过空间时低。由此还附加地适宜地记录关于头部相对于躯干的朝向方面的缺失的空间情况的数据组。
30、原则上,hrtf本身可以分解为几个单独的传递函数,它们对声学路径的各个部分进行建模,然后当它们组合时,产生整个声学路径的hrtf。在某些情况下,不需要或者甚至不可能以所描述的方式确定整个声学路径的hrtf,而仅确定一个或多个单独的部分,尤其是最靠近用户的部分的hrtf。然后特别是通过相应的标准函数对其余部分进行建模。
31、在一个适宜的设计方案中,hrtf的确定基于基础hrtf来进行,基础hrtf是仅用于从音频源到用户的耳道的声学路径的第一部分的传递函数,从而主要针对声学路径的另外的第二部分来确定hrtf。这基于如下考虑,即,hrtf通常由用户的耳朵、尤其是其耳廓最强烈地定义,而较少由用户的躯干或一般头部形状来定义。因此,第二部分尤其包含声学路径的包含耳廓的部分。基本hrtf于是例如是假人的hrtf并且主要考虑用户的身体形状和一般头部形状。然后通过本方法以考虑用户耳廓的特殊形状的方式来优化该基本hrtf,从而总体上以特定于用户的方式来确定hrtf。为此,听力设备被适宜地构造为,其麦克风在佩戴状态下位于用户的耳道中或耳朵中,而不仅仅位于耳朵后。
32、如前所述,hrtf不一定由听力设备来确定。hrtf优选地由计算机来确定,特别是服务器,其被构造为与听力设备和音频源分开。下面,在不限制一般性的情况下,假设服务器是计算机。数据组为此究竟如何到达服务器并不相关,而是也取决于所选择的方法的设计方案、听力设备、音频源和可能涉及的其他设备。例如,听力设备将声学传输的第一音频信号或其片段发送到服务器,并且声学传输的第二音频信号或其片段同样由听力设备或另一设备(例如智能电话或音频源)发送到服务器。然后,服务器又适宜地将hrtf发送到听力设备。
33、音频源优选地是固定设备。“固定”特别是应当理解为不运动的,但通常不一定是不可运动的。换句话说:音频源通常停留在环境、例如空间中的相同的位置,而用户相对于音频源运动,一般地来说,关于用户的空间情况改变。固定设备特别是具有如下优点,即,用户的任何运动自动产生空间情况的变化,从而可以对应地以简单的方式生成关于不同的空间情况的数据组。
34、特别优选音频源是电视设备(也称为电视)的设计方案。电视设备特别地是固定设备。在这里描述的方法中使用电视设备作为音频源具有各种优点。一方面,电视设备通常具有一个或多个扬声器,这些扬声器具有高输出质量,由此覆盖特别宽的频谱,并且还以特别真实的方式输出源音频信号。与智能电话相比这特别适用。此外,用户通常处于相对于电视设备几米的距离处,这与如上所述在无回声空间中确定hrtf时的距离相似并且对于确定hrtf是最佳的。此外,电视设备通常总是放置在环境中的相同位置,因此在确定hrtf时可以更好地考虑附加的空间声学效应,尤其是沿着hrtf未映射的声学路径的部分。最后,与例如在来自智能电话的声音信号的情况下不同,还预期来自电视设备的声音信号不包含任何敏感的个人数据。
35、优选地在用户看电视期间执行这里描述的方法,特别是使用音频源,即在作为电视设备的音频源被打开并且用户在其附近(例如在距离音频源小于5m的距离内)期间。在此,不一定需要用户跟踪或者特别关注电视设备发出的内容。在用户看电视时执行所述方法具有各种优点。一方面,预期用户在更长的时间段(例如1到2小时)内看电视,从而将相应地记录特别多的数据组。还预期用户反复看电视,从而重复记录相应数量的数据组。此外,用户在看电视时通常不与其他人进行任何私人对话,从而确保不记录敏感的个人数据。如果记录敏感的个人数据,它们适宜地将被丢弃。例如听力设备通过如下方式来识别个人对话,即,相关的声音信号从与来自音频源的声音信号不同的方向到达。在看电视时通常也不存在其他干扰噪声,因为其他噪声源通常被用户关闭,从而总体上生成质量非常好的数据组。
36、此外,电视设备的使用是有利的,因为尽管电视设备通常具有多个扬声器,但是在此也可以以仅使用单个扬声器来输出声音信号的方式运行。由此,hrtf的确定明显更准确,因为现在仅存在一个声源,因此非常精确地定义了声学路径。这也一般地适用于具有多个扬声器的所有音频源。因此,在一个有利的设计方案中,控制音频源,使得音频源仅通过单个扬声器将音频信号作为声音信号输出。至少就如下方面而言仅通过一个扬声器进行输出对用户来说不是限制性的,即,其有利地必要时也借助流式操作作为数据信号来接收源音频信号,并且对应地不依赖于音频源的声音输出。因此,听力设备优选地在所述方法期间以流式操作运行。如果感觉到附加的声音输出令人不适,则例如听力设备借助anc单元(anc意为“active noise cancelling”,即主动降噪)滤除该声音信号。
37、在一个适宜的设计方案中,确定环境的声学参数,以便特别是量化一个或多个空间声学效应(raumakustische effekte),并且在确定hrtf时考虑。空间声学效果例如是声音信号在墙壁或附近物体上的反射或混响,尤其是在房间中。相应地,环境的声学参数为量化环境的脉冲响应、环境的早期反射(所谓的“early reflection”)或环境的混响(“reverberation”)的时间或幅度。例如使用听力设备或其他设备来确定声学参数。在空间中放置一个附加的麦克风以确定环境中的声学参数也是适宜的。
38、根据本发明的听力设备具有控制单元,该控制单元被构造为用于执行前面描述的方法,必要时与音频源和/或所描述的另一设备组合。
39、此外,上述技术问题通过计算机和/或另一设备、例如上面描述的智能电话来解决。
- 还没有人留言评论。精彩留言会获得点赞!