一种海量终端蜜罐自动化部署与撤销的方法和装置与流程
1.本发明涉及网络攻击蜜罐部署防护技术领域,特别提供了一种海量终端蜜罐自动化部署与撤销的方法和装置。
背景技术:
2.随着计算机信息系统应用的深入,计算机信息系统正逐步从单机向局域网、广域网发展,特别是internet的迅速发展,网络变得更加复杂,计算机信息系统安全面临新的、更严峻的挑战。同时现有的网络安全防护技术,包括防火墙技术、入侵检测技术、病毒防护技术、数据加密和认证技术等,主要都是基于已知的事实和攻击模式,在攻击者攻击时对系统只能进行被动的防护,面对复杂而多变的网络攻击常常力不从心。
3.传统网络安全理念注重构建安全的网络环境,旨在将安全威胁抵御在网络之外。随着ids规避和防火墙穿透技术的发展,网络安全面临着严峻挑战。近年来,蜜罐(honey pot)成为安全界关注与研究的热点。它采取主动方式,利用虚假的服务或信息来迷惑攻击者,转移并容纳有限度的威胁,将攻击从网络中比较重要的机器上转移开,同时在黑客攻击蜜罐期间对其行为和过程进行深入分析和研究,发现新型攻击,检索新型黑客工具,了解黑客和黑客团体的背景、目的、活动规律等。蜜罐不但具有准确的威胁、判定能力,还能发现新的攻击手段和工具。这样一来,当攻击者入侵时,蜜罐来拖延攻击者对真正目标的攻击,让攻击者在蜜罐上浪费时间,有效防护业务网络,同时了解对手,研究自身受到的威胁。
4.相似方案:一种基于docker的自动化蜜罐搭建及威胁感知方法。相似方案中方法只是单纯利用docker技术搭建蜜罐,但仍需要人工判断搭建时间位置与操作,本发明真正实现了自动化,根据入侵检测系统结果进行自动化搭建。相似方案中方法是对蜜罐中数据进行分析再进行威胁感知,本发明是先判断流量异常,将异常流量引入蜜罐,响应速度更快,安全性更高。
5.蜜罐系统是一个模拟真实系统,但存在一定漏洞的系统,面向攻击者时,该系统表现出的特性与真实系统并无明显差别;面向用户时,蜜罐系统又是可以定制的,用户可以根据自己的系统类型,部署相似的蜜罐系统。蜜罐系统的部署,可以将攻击者绝大部分的攻击流量流向蜜罐系统中,进而在很大程度上减轻用户主系统的负担。所以,在使用各种防范技术的同时,也需要制造大量蜜罐以迷惑已知与未知的恶意攻击并保护网络信息,蜜罐中的行为数据也可用于后期恶意行为的溯源分析。但是,在部署与删除过程中过度依赖人工,布置繁琐,蜜罐的自动化配置有一定的难度。
技术实现要素:
6.为了解决上述技术问题,本发明提供了一种海量终端蜜罐自动化部署与撤销的方法和装置。
7.本发明是这样实现的,提供一种海量终端蜜罐自动化部署与撤销的方法,包括如下步骤:
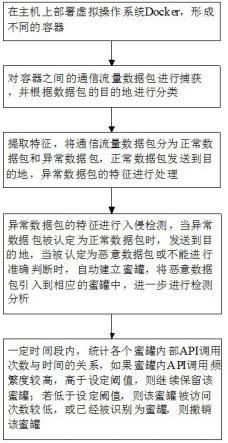
1)在主机上部署虚拟操作系统docker,形成不同的容器;2)对容器之间的通信流量数据包进行捕获,并根据数据包的目的地进行分类;3)将分类好的数据包进行特征提取,根据提取的特征,将通信流量数据包分为正常数据包和异常数据包,将正常数据包发送到目的地,将异常数据包的特征进行处理;4)将处理后的异常数据包的特征进行入侵检测,当异常数据包被认定为正常数据包时,将其发送到目的地,当异常数据包被认定为恶意数据包或不能进行准确判断时,自动建立蜜罐,将恶意数据包引入到相应的蜜罐中,进一步进行检测分析;5)一定时间段内,统计各个蜜罐内部api调用次数与时间的关系,如果蜜罐内api调用频繁度较高,高于设定阈值,则继续保留该蜜罐;若低于设定阈值,则该蜜罐被访问次数较低,或已经被识别为蜜罐,则撤销该蜜罐。
8.优选的,所述步骤2)中,通过利用现有软件监听主机网卡接口的方式来捕获容器之间的通信流量数据包。
9.进一步优选,所述步骤3)中,依据基于pca的特征提取模型对通信流量数据包进行特征提取,具体包括如下步骤:1)将分类后的通信流量数据包进行pca特征提取:计算原始样本空间x的协方差矩阵s;通过协方差矩阵s计算其正交矩阵q及特征值λ1≥λ2≥
…
≥λn;设置累计贡献率t的阈值,计算得到标准正交向量ui及降维后的样本空间u={u1,u2,
…
ud},并得到投影后的主分量特征 y={u1,u2,
…
ud}
t
xi,形成新的候选特征子集f1,n、d、i均代表常数,t代表转置;2)自适应选择pca的二次特征选择模块:201)当需要确定降维后特征子集f1的关键特征时,进行基于关联过滤器的特征选择,检查每个特征的相关性,即,使属性特征与类属性关联度最大化,且使属性与属性之间的冗余度最小化,结合启发式序列后向算法搜索策略,得到候选的关键特征子集f2;202)当不需要确定特征子集f1的关键特征时,跳过特征提取,获得相对较高的分类精度;3)在pca特征提取模型、pca二次特征选择模型的最优特征子集上,形成数据集并进行svm分类训练,在测试集上得到通信流量数据包的分类结果,即分类为正常数据包和异常数据包。
10.进一步优选,所述步骤4)中,通过蜜罐进一步对恶意数据包进行检测分析后,如果仍被认定为有入侵行为的恶意数据包,则执行黑名单策略,将对应的恶意数据包丢弃,或执行报警策略。
11.本发明还提供一种海量终端蜜罐自动化部署与撤销的装置,包括如下单元:虚拟操作系统docker,用于部署在主机上;数据捕获模块,用于对容器之间的通信流量数据包进行捕获,并根据数据包的目的地进行分类;特征提取模块,用于将分类好的数据包进行特征提取,根据提取的特征,将通信流量数据包分为正常数据包和异常数据包,将正常数据包发送到目的地,将异常数据包的特征进行处理;入侵检测模块,用于将处理后的异常数据包的特征进行入侵检测;蜜罐,用于对被认定为恶意数据包或不能进行准确判断的数据包,进一步进行检
测分析;频繁度计算模块,用于在一定时间段内,统计各个蜜罐内部api调用次数与时间的关系,如果蜜罐内api调用频繁度较高,高于设定阈值,则继续保留该蜜罐;若低于设定阈值,则该蜜罐被访问次数较低,或已经被识别为蜜罐,则撤销该蜜罐。
12.与现有技术相比,本发明的优点在于:本发明可以自动化部署海量终端蜜罐,节省人力与成本,使部署蜜罐方法简单,可操作性强,可对网络进行有效防护。
13.(1)减少资源的消耗且部署便捷:传统的入侵检测系统是需要根据不同的要求进行配置,但在本发明中,为了简化入侵检测系统的部署,使用了docker技术中的容器。在容器中可以运行不同的入侵检测系统,同时运行在容器中的入侵检测系统在启动时仅仅需要一些配置脚本就可以启动,这就大大简化了配置操作。同时本设计中的入侵检测系统并不依赖于环境,具有很好的可移植性,只要主机环境中将docker的相关环境配置好,就可以运行相关的脚本实现入侵检测。
14.传统的蜜罐都是基于主机进行相同硬件环境的配置,在配置过程中,不仅配置过程繁琐复杂,而且还需要相同的硬件环境。相比传统的蜜罐技术,减少了配置过程,因为可以根据镜像来建立多个容器实例,这样就使得配置过程大大简化。建立好环境后可以直接将攻击者引诱到建立的蜜罐中,进一步对攻击者的行为进行分析和鉴别。
15.(2)以较少资源开销同时建立自适应的多个蜜罐:无需人工设计部署蜜罐,可在需要的时间及时部署蜜罐,不需要时及时撤销。一台主机就可以实现整个集数据控制,是数据捕获和数据分析于一体的多功能多蜜罐高交互蜜网的体系架构。
附图说明
16.图1为本发明提供的海量终端蜜罐自动化部署与撤销的方法流程图;图2为本发明提供的海量终端蜜罐自动化部署与撤销的装置模块连接图。
具体实施方式
17.为了使本发明的目的、技术方案及优点更加清楚明白,下面结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用于解释本发明,并不用于限定本发明。
18.目前,单一的蜜罐系统不能很好的应用于今天的互联网系统,主要有着以下几个方面的问题:1)系统架构部署和维护还比较复杂,批量自动化部署难,难以有效控制风险,不能满足大规模网络环境的需要;2)模拟服务交互程度低,容易被识别;3)若被黑客攻击第三方网络造成破坏,就会被受害方提出诉讼,触犯法律问题;4)模拟服务交互程度低,难以实现自适应网络变化。
19.传统的蜜罐都是基于主机进行相同硬件环境的配置,在配置过程中,不仅配置过程繁琐复杂,不能自动化部署,而且还需要相同的硬件环境。针对这些问题,本发明利用虚
拟操作系统docker,集合入侵检测系统完成蜜罐自动构建,运行;基于调用api频繁度完成蜜罐撤销,以实现海量终端蜜罐的自动化部署。
20.参考图1,本发明提供一种海量终端蜜罐自动化部署与撤销的方法,包括如下步骤:1)在主机上部署虚拟操作系统docker,形成不同的容器;2)对容器之间的通信流量数据包进行捕获,并根据数据包的目的地进行分类;在本步骤中,通过利用现有软件监听主机网卡接口的方式来捕获容器之间的通信流量数据包。
21.3)将分类好的数据包进行特征提取,根据提取的特征,将通信流量数据包分为正常数据包和异常数据包,将正常数据包发送到目的地,将异常数据包的特征进行处理;本步骤中,依据基于pca的特征提取模型对通信流量数据包进行特征提取,具体包括如下步骤:1)将分类后的通信流量数据包进行pca特征提取:计算原始样本空间x的协方差矩阵s;通过协方差矩阵s计算其正交矩阵q及特征值λ1≥λ2≥
…
≥λn;设置累计贡献率t的阈值,计算得到标准正交向量ui及降维后的样本空间u={u1,u2,
…
ud},并得到投影后的主分量特征 y={u1,u2,
…
ud}
t
xi,形成新的候选特征子集f1,n、d、i均代表常数,t代表转置;2)自适应选择pca的二次特征选择模块:201)当需要确定降维后特征子集f1的关键特征时,进行基于关联过滤器的特征选择,检查每个特征的相关性,即,使属性特征与类属性关联度最大化,且使属性与属性之间的冗余度最小化,结合启发式序列后向算法搜索策略,得到候选的关键特征子集f2;202)当不需要确定特征子集f1的关键特征时,跳过特征提取,获得相对较高的分类精度;3)在pca特征提取模型、pca二次特征选择模型的最优特征子集上,形成数据集并进行svm分类训练,在测试集上得到通信流量数据包的分类结果,即分类为正常数据包和异常数据包。
22.4)将处理后的异常数据包的特征进行入侵检测,当异常数据包被认定为正常数据包时,将其发送到目的地,当异常数据包被认定为恶意数据包或不能进行准确判断时,自动建立蜜罐,将恶意数据包引入到相应的蜜罐中,进一步进行检测分析;在本步骤中,通过蜜罐进一步对恶意数据包进行检测分析后,如果仍被认定为有入侵行为的恶意数据包,则执行黑名单策略,将对应的恶意数据包丢弃,或执行报警策略。
23.5)一定时间段内,统计各个蜜罐内部api调用次数与时间的关系,如果蜜罐内api调用频繁度较高,高于设定阈值,则继续保留该蜜罐;若低于设定阈值,则该蜜罐被访问次数较低,或已经被识别为蜜罐,则撤销该蜜罐。即:其中,为调用频繁度,为t时间段内调用api次数,为固定的检测时间段。若t大于阈值则继续隔段时间检测;若t小于阈值则启动撤销脚本撤销该蜜罐。
24.参考图2,本发明还提供一种海量终端蜜罐自动化部署与撤销的装置,包括如下单
元:虚拟操作系统docker,用于部署在主机上;数据捕获模块,用于对容器之间的通信流量数据包进行捕获,并根据数据包的目的地进行分类;特征提取模块,用于将分类好的数据包进行特征提取,根据提取的特征,将通信流量数据包分为正常数据包和异常数据包,将正常数据包发送到目的地,将异常数据包的特征进行处理;入侵检测模块,用于将处理后的异常数据包的特征进行入侵检测;蜜罐,用于对被认定为恶意数据包或不能进行准确判断的数据包,进一步进行检测分析;频繁度计算模块,用于在一定时间段内,统计各个蜜罐内部api调用次数与时间的关系,如果蜜罐内api调用频繁度较高,高于设定阈值,则继续保留该蜜罐;若低于设定阈值,则该蜜罐被访问次数较低,或已经被识别为蜜罐,则撤销该蜜罐。
25.综上所述,本发明设计了一种海量终端蜜罐自动化部署方法,可以自动化完成蜜罐的构建,运行,撤销。
26.在构建方面,根据入侵检测系统的结果判断是否自启动蜜罐生成脚本,若检测到恶意流量则自动触发脚本生成蜜罐。生成的蜜罐可与流量进行不同程度的交互。
27.在撤销方面,可以根据调用api频繁度触发撤销脚本,自动撤销蜜罐,节约成本。频繁度阈值可根据实际情况自己设定,若资源充足可将阈值调高,保留一些交互不频繁的蜜罐,若资源有限,可只保留最易受攻击的蜜罐以保证最高效率。
28.上面对本发明的实施方式做了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1