一种基于启发式聚类算法的工业控制网络攻击流量分类方法与流程
1.本发明涉及网络安全领域,具体涉及一种基于启发式聚类算法的工业控制网络攻击流量分类方法。
背景技术:
2.威胁分析是网络安全态势理解阶段的重要环节,无论从哪个角度对工业控制系统中的网络攻击行为进行分析,对于网络攻击流量的分类都在其中扮演着重要的角色,其打开了对网络攻击行为进行进一步深入探索的大门。
3.网络攻击流量分类已经成为现代网络安全研究中一项重要的基础性技术。近年来对攻击流量分类的研究主要集中在将机器学习及深度学习技术应用于网络流量统计特征的分类方法上,许多有监督的分类方法和无监督的聚类方法已经被应用于攻击流量分类。基于不同的训练样本和防御目标,攻击流量分类方法能够被应用于不同的场景,主要包括检测恶意流量、区分已有类别攻击和发现未知种类攻击等。
4.论文“z.jun,c.chao,x.yang,z.wanlei,and a.v.vasilakos,an effective network traffic classification method with unknown flow detection[j].ieee trans.netw.serv.manage.2019,10(2):133-147.”提出了流量标签传播,从大量的无标签数据集中自动标记相关流量,以解决监督训练集小的问题,并使用半监督的方法来检测未知的网络流量。
[0005]
论文“a.a.ahmed,w.a.jabbar,a.s.sadiq,and h.patel.deep learning based classification model for botnet attack detection.j.ambient intell.hum.comput.,2020.”使用卷积神经网络对scada流量的突出时间模式进行建模,并确定网络攻击存在的时间窗口。特别是,这种方法设计了一个重新训练的方案来处理未知的攻击。
[0006]
论文“z.jun,c.chao,x.yang,z.wanlei,and a.v.vasilakos,an effective network traffic classification method with unknown flow detection[j].ieee trans.netw.serv.manage.2019,10(2):133-147.”提出了流量标签传播,以解决监督训练集小的问题。虽然这种方法减少了对监督训练数据的依赖,但它没有尝试对未知流量进行进一步分类。
[0007]
论文“a.a.ahmed,w.a.jabbar,a.s.sadiq,and h.patel.deep learning based classification model for botnet attack detection.j.ambient intell.hum.comput.,2020.”提出的方法依赖于scada系统操作员检查和标记新发现的攻击,这可能是非常耗时的。其次,重新训练方案需要足够数量的新攻击实例,这可能导致分类模型无法及时适应新出现的攻击。
[0008]
近些年来,虽然已有一些方法被提出用于发现未知种类的网络攻击,然而现阶段这些方法仍然面临3个主要挑战:1)无法直接对侦测到的未知攻击流量进行进一步的分类;2)主要依赖安全分析人员对未知攻击流量进行种类划分和打标签;3)需要足够多的未知种
类攻击流量样本进行分类模型的训练。
[0009]
本发明提出了一种能够在仅有正常工控网络攻击流量作为参考的情况下对目标工业控制网络中的未知攻击流量进行实时检测和分类的方法。从有监督学习的角度来看,该方法摆脱了对训练攻击样本的依赖。与已有无监督聚类方法相比,该方法的分类过程是实时的,且被发现的新的攻击流量类别将被直接保留在分类模型中,而不是每次都重新训练和生成新的簇。况且对原有攻击流量和新的攻击流量的重新聚类很难保证与前一次聚类结果的一致性,即原属于相同簇的攻击流量可能被新的聚类过程分配到不同的簇中,从而导致生成的簇无法始终代表某一类攻击流量,进而导致整个聚类结果失去代表性。
技术实现要素:
[0010]
本发明提出了一种基于启发式聚类算法的工业控制网络攻击流量分类方法,这是一种具有自增长能力的无监督分类方法,以解决仅基于正常工控网络攻击流量对未知攻击流量进行实时分类的难题。首先,由于缺乏足够的训练攻击样本,无监督聚类方法更适合解决该问题。其次,由于缺乏工业控制网络流量分布相关知识,自动化的聚类过程比预定义聚类结果更加符合实际需求。最后,由于攻击流量的种类是不确定的,且是逐渐出现的,因此对于攻击流量的持续性的、实时的检测和分类能力是非常重要的。
[0011]
本发明的技术方案如下:一种基于启发式聚类算法的工控网络攻击流量分类方法,工控网络攻击流量分为训练数据和测试数据,包括以下步骤:
[0012]
步骤一:从工控网络攻击流量中提取出工控网络攻击流量特征;使用流量会话作为基本单元分割工控网络攻击流量,流量会话进一步由活跃时间阈值t
activation
分割;
[0013]
步骤二:将步骤一获得的工控网络攻击流量特征进行特征离散化和标准化处理,获得格式化后的工控网络攻击流量特征输入至深度自编码器,深度自编码器的解码器部分对工控网络攻击流量特征进行降维,获得低维流量特征表示形式;
[0014]
步骤三:通过基于密度的启发式聚类算法(density-based heuristic clustering,dbhc),从低维流量特征表示形式中获取基础攻击流量分类器;
[0015]
步骤四:基于基础攻击流量分类器,采用测试数据构造自增长攻击流量分类器(self-growing attack traffic classifier,sgatc),用于持续检测和分类未知的攻击流量。
[0016]
所述步骤二中的深度自编码器包含三个隐藏层,每层均以relu作为激活函数;损失函数反映了格式化后的工控网络攻击流量特征与低维流量特征表示形式之间偏差平方的平均值,其中xi表示格式化后的工控网络攻击流量特征,表示低维流量特征表示形式,n表示数据量,即数据输出个数;
[0017][0018]
其中,e为输入数据与输出数据之间偏差平方的平均值。
[0019]
所述步骤三的具体步骤为:
[0020]
3.1将步骤二的低维流量特征表示形式视为数据点,计算每个数据点pi的局部密度ρi;
[0021][0022]
其中,d
ij
为数据点pi和pj之间的距离,dc为截断距离;
[0023]
3.2按局部密度降序排列数据点,形成序列n={p1,p2,
…
,pn|;
[0024]
3.3计算每个数据点pi和与其最近且密度更高的数据点qi间的距离δi,
[0025][0026]
3.4为数据点p1创建第一个簇c1,并选择p1为其质心o1;
[0027]
3.5按照序列n的顺序,除p1外,对每个数据点pi依次进行检验,当其距离δi小于等于截断距离dc时,pi被分配到与其最近且密度更高的数据点所属的簇c
x
中;通过直接平均法,用pi来更新簇c
x
的质心o
x
;
[0028]
3.6当pi的距离δi大于截断距离dc时,为pi创建一个新的簇,且pi被选为对应新簇的质心;
[0029]
3.7计算每个簇之间极限距离d
l
,极限距离为两个簇质心间最大距离,
[0030][0031]
3.8ca,cb两个簇质心的距离小于d
l
时,计算二者之间最小距离d
min
:
[0032][0033]
3.9d
min
小于截断距离dc时,ca,cb两个簇被合并成一个新的簇c
′a,并更新簇c
′a的质心o
′a,将cb标记成已合并;
[0034]
3.10遍历各个簇,删除所有标记为已合并的簇。
[0035]
所述步骤四的具体步骤为:
[0036]
4.1测试数据p
*
所属簇c
*
设为空,置为正整数,计算测试数据p
*
和基础攻击流量分类器中所有簇的极限距离d
l’,d
l’计算公式如下:
[0037][0038]
4.2p
*
和oi之间的距离不大于d
l’时,计算对应的最小距离d
min
,
[0039][0040]
4.3d
min
(p
*
,ci)不大于截断距离dc且小于更新为d
min
(p
*
,ci),将c
*
置为簇ci,c
*
不为空;否则c
*
为空;
[0041]
4.4当c
*
不为空时,|c
*
|小于更新系数m时,计算更新距离du:
[0042]du
=dc*|c
*
|/m
[0043]
|c
*
|不小于更新系数m时,计算更新距离du:
[0044]du
=dc[0045]
4.5dist(p
*
,o
*
)大于du时,p
*
来更新簇c
*
;
[0046]
4.6计算每个簇cj的簇c
*
之间极限距离d
l
;
[0047]
4.7c
*
,cj两个簇质心的距离小于等于d
l
时,进一步计算它们之间的最小距离d
min
(c
*
,cj);
[0048]
4.8d
min
(c
*
,cj)小于截断距离dc时,c
*
,cj两个簇将被合并成一个新的簇利用分配机制将映射到一个已有类别;
[0049]
4.9将簇赋给簇c
*
,将p
*
分类为c
*
所属类别;
[0050]
4.10当c
*
为空时,为p
*
创建一个新的簇并选择p
*
为其质心,分配一个新的类别给p
*
和
[0051]
所述训练数据经步骤一、步骤二和步骤三获取基础攻击流量分类器。
[0052]
所述测试数据经步骤一、步骤二和步骤四构造自增长攻击流量分类器。
[0053]
所述不小于105。
[0054]
本发明的有益效果:本发明解决了仅基于正常工控网络流量对未知攻击流量进行实时分类的难题。从有监督学习的角度来看,本发明提出的方法摆脱了对训练攻击样本的依赖。与已有无监督聚类方法相比,本发明提出的方法的分类过程是实时的,且被发现的新的攻击流量类别将被直接保留在分类模型中,而不是每次都重新训练和生成新的簇。况且对原有攻击流量和新的攻击流量的重新聚类很难保证与前一次聚类结果的一致性,即原属于相同簇的攻击流量可能被新的聚类过程分配到不同的簇中,从而导致生成的簇无法始终代表某一类攻击流量,进而导致整个聚类结果失去代表性。针对缺乏足够的训练攻击样本、缺乏工业控制网络流量分布相关知识以及攻击流量的种类是不确定的,且是逐渐出现的特点,本方法实现对攻击流量进行持续性的、实时的检测和分类。
附图说明
[0055]
图1为未知攻击流量分类系统模型;
[0056]
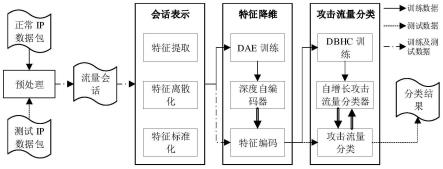
图2为基于启发式聚类算法的工业控制网络攻击流量分类方法过程流程图;
[0057]
图3为本发明与四种比较算法的性能对比图。
具体实施方式
[0058]
下面结合附图和实施例,对本发明的具体实施方式做进一步详细描述。
[0059]
一种基于启发式聚类算法的工业控制网络攻击流量分类方法,算法步骤如下:
[0060]
步骤一:用流量会话的形式表示工控网络攻击流量,作为it特征的补充,用工控网络攻击流量特征来表示数据单元。
[0061]
步骤二:采用特征离散化和标准化的数据处理方法,格式化被提取的工控网络攻击流量特征以适应接下来的深度学习方法。
[0062]
步骤三:使用一个包含三个隐藏层的深度自编码器来对工控网络攻击流量特征进行降维,该深度自编码器的所有层均采用relu作为激活函数,其为一个简单的非线性函数,如果输入值为正值,则返回输入值,否返回0。其次,选择mse作为损失函数,其反映了输入与输出之间偏差平方的平均值。mse计算式如下:
[0063][0064]
步骤四:通过dbhc对由正常工控网络攻击流量组成的训练数据集进行建模,具体包括:
[0065]
①
计算每个数据点pi的局部密度ρi,其中,dc为截断距离,设置为0.03;
[0066][0067]
②
按局部密度降序排列数据点,形成序列n={p1,p2,
…
,pn};
[0068]
③
计算每个数据点pi和与具有更高密度的且与其最近的数据点qi间的距离δi,生成二元组《qi,δi》,δi计算公式如下:
[0069][0070]
④
为数据点p1创建第一个簇c1,并选择p1为其质心o1;
[0071]
⑤
按照序列n的顺序,除p1外,每个数据点pi依次进行检验,当其距离δi小于等于截断距离dc时,pi被分配到具有更高密度的且与其最近的数据点所属的簇c
x
中。同时,通过直接平均法,用pi来更新簇c
x
的质心o
x
;
[0072]
⑥
当pi的距离δi大于截断距离dc时,为pi创建一个新的簇,且pi被选为对应新簇的质心;
[0073]
⑦
经过上述步骤,共创建了k个簇,对每个簇进行簇之间极限距离d
l
的计算,极限距离被定义为两个簇质心间最大可能距离,计算公式如下:
[0074][0075]
⑧
如果ca,cb两个簇质心的距离小于d
l
时,进一步计算它们之间的最小距离d
min
:
[0076][0077]
⑨
当d
min
小于截断距离dc时,ca,cb两个簇将被合并成一个新的簇c
′a,并更新其质心o
′a,同时将cb标记成已合并;
[0078]
⑩
遍历一遍k个簇,将所有标记为已合并的簇删除。
[0079]
步骤五:构造sgatc,用于持续检测和分类未知的攻击流量,具体步骤为:
[0080]
①
p
*
所属簇c
*
置为空,置为较大正整数,计算测试数据p
*
和原始簇集合中所有簇的质心oi的距离,同时计算极限距离d
l’,d
l’计算公式如下:
[0081][0082]
②
如果p
*
和oi之间的距离小于等于d
l’,那么计算它们对应的最小距离d
min
,公式如下:
[0083]
[0084]
③
当d
min
(p
*
,ci)小于等于截断距离dc且小于更新为d
min
(p
*
,ci),将c
*
置为簇ci;
[0085]
④
当c
*
不为空时,如果|c
*
|小于更新系数m,m设置为50,计算更新距离du:
[0086]du
=dc*|c
*
|/m
[0087]
如果|c
*
|不小于更新系数m,计算更新距离du:
[0088]du
=dc[0089]
⑤
当dist(p
*
,o
*
)大于du时,用p
*
来更新簇c
*
;
[0090]
⑥
经过上述步骤,当前模型中有m个簇,对每个簇cj计算其与簇c
*
之间的极限距离d
l
;
[0091]
⑦
如果c
*
,cj两个簇质心的距离小于等于d
l
时,进一步计算它们之间的最小距离d
min
(c
*
,cj);
[0092]
⑧
当d
min
(c
*
,cj)小于截断距离dc时,c
*
,cj两个簇将被合并成一个新的簇利用分配机制将映射到一个已有类别;
[0093]
⑨
将簇赋给簇c
*
,将p
*
分类为c
*
所属类别;
[0094]
⑩
当c
*
为空时,为p
*
创建一个新的簇并选择p
*
为其质心,分配一个新的类别给p
*
和
[0095]
本实施例使用scada系统及相应的网络流量数据集作为实验数据,以正常网络流量“run1_6rtu”作为训练数据,以其余所有种类的攻击流量作为测试数据。主要目的在于检测攻击流量的同时对其种类进行区分,以便于与来自其他工控网络的攻击流量以及来自分布式工控蜜网的攻击流量进行比对分析。此外,为丰富实验数据中攻击流量的种类,本实施例使用7个攻击工具对5个暴露在互联网上的基于modbus的工控设备进行了10次独立的扫描,进而形成攻击工具数据。进一步,为增加攻击工具数据的识别和分类难度,将5个被扫描的工控设备映射到scada系统中的前5个rtu,即将相应的ip地址替换成rtu的ip地址。具体的数据分布情况如表1所示。
[0096]
表1攻击流量数据集详细表
[0097][0098]
为了验证本发明提出方法的有效性,通过一组实验将该系统模型与4种较为先进的无监督聚类算法,包括k-means、em、hierarchical agglomerative clustering(hac)及dbscan,在检测和分类未知攻击流量方面进行了比较。注意,4种比较算法皆在无监督模式下同时以训练和测试数据作为它们的输入。为使上述4种比较算法适用于攻击流量的检测和分类,本发明中的两条规则也被应用于它们。一方面,一旦测试流量会话被分配到训练流量会话所在的簇中,则被判定为正常。另一方面,不包含任何训练流量会话的簇被判定为异常,其类别通过概率分配机制来决定。
[0099]
图3展示了该系统模型与4种比较算法的性能。显然,该系统模型在各个评价指标上都优于其他比较算法。例如,该系统模型的分类准确率比次优算法,dbscan,高出0.04以上。尽管hac算法在检测率和总体准确率方面与该系统模型相当,但其在分类准确率上出现
了急剧的下降,这暗示着其在分类工控网络攻击流量的过程中可能出现了过拟合现象。这是因为参数“簇的总数量”能够迫使hac算法产生足够多的簇从而将攻击流量从正常流量中分离出来,但是其没有考虑攻击流量的分布情况,这并不利于区分不同种类的攻击流量。而且,攻击流量的数量远少于正常流量的数量,这也使得其难以为不同种类的攻击流量形成具有代表性的簇。这也是基于原型的聚类算法(k-means和em)能够获得比基于密度的聚类算法(dbscan)更高的检测率和总体准确率的原因。但是基于密度的聚类算法试图探索数据点的分布情况,并将相似的数据点分配到相同的簇中,因此其更善于分类攻击流量。
[0100]
鉴于上述观察,该系统模型采用了更加严格的聚类条件来划分数据点,并利用更新操作来合并相似的簇以减小分类模型的规模。通过这种方式,该系统模型能够充分利用工控网络攻击流量的分布特征,并获得比4种比较算法更好的检测和分类性能。而且,该系统模型无需再训练便能够实时持续地发现新类别的攻击流量。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1