虚拟路由器流处理系统及方法与流程
1.本发明涉及网络技术领域,特别是涉及一种虚拟路由器流处理系统及方法。
背景技术:
2.现有的虚拟路由器(vrouter),无法在运维层面直接查看虚拟路由器下的数据流及数据包;在发生故障或进行性能调优时,需要登入主机或设备网络进行抓包,需要繁琐的方式来实现排障和定位。
技术实现要素:
3.本发明的目的在于,提供一种虚拟路由器流处理系统及方法用于解决现有的虚拟路由器在发生故障或进行性能调优时,需要登入主机或设备网络进行抓包,需要繁琐的方式来实现排障和定位的等问题。
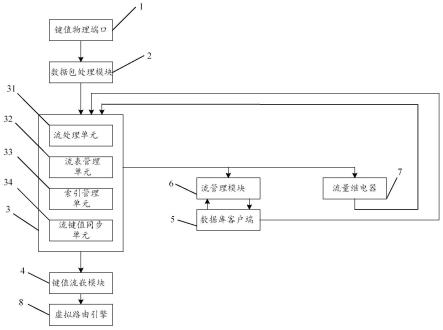
4.为解决现有技术中的问题,第一方面,本发明提供一种虚拟路由器流处理系统,包括:
5.键值物理端口,与虚拟路由器相连接,用于从所述虚拟路由器中获取数据包,并将所述数据包进行排队;所述数据包包括流信息;
6.数据包处理模块,与所述键值物理端口相连接,用于将排队后的数据包进行分类;
7.流量模块,与所述数据包处理模块相连接,用于将分类后的数据包进行散列处理,并对散列处理后的数据包中的流信息进行处理;
8.键值流嵌模块,与所述流量模块相连接,用于将所述流量模块处理后且需要发送至所述虚拟路由器的数据包中的流信息排成信息队列,并将所述信息队列与任务请求捆绑后发送至所述虚拟路由器。
9.可选地,所述键值物理端口还用于在将所述数据包进行排队之前,将获取的所述数据包增加代理标头;所述键值物理端口用于将具有代理标头的数据包进行排布。
10.可选地,分类后的数据包进行散列处理后分布于不同的分区;所述流量模块包括:流处理器、流表管理单元、索引管理单元及流键值同步单元;其中,
11.所述流处理器用于设置所述数据流的属性信息;
12.所述流表管理单元用于维护各分区中所有流条目的树、识别重复流、进行策略匹配、将不一致状态的数据流标记为短流、将数据流从nat流转换为非nat流、调用新的数据流的索引管理器、添加更改或删除数据流;
13.所述索引管理单元用于生成身份码,以确保只有一个数据流主动使用索引;
14.所述流键值同步单元用于确保数据流与索引引用下一跳及镜像索引的依赖关系,并对数据流进行编码或解码。
15.可选地,还包括:
16.数据库客户端,用于在接收到数据流调整通知时,判断所述数据流调整通知是否涉及修改数据流感兴趣的字段;若是,则生成数据流调整请求;
17.流管理模块,与所述数据库客户端及所述流量管理模块相连接,用于基于所述数据流调整请求对所述流量管理模块中的数据流进行调整。
18.可选地,数据流调整包括数据流添加、数据流更改或数据流删除。
19.可选地,所述流管理模块还用于维护数据流到该数据流依赖的数据条目的列表及数据条目到依赖于该数据条目的数据流的列表。
20.可选地,还包括:流量继电器,用于清除所述流量模块中超过预设长度或停留时间超过预设时间的数据流。
21.第二方面,本发明还提供一种虚拟路由器流处理方法,其特征在于,包括:
22.从虚拟路由器中获取数据包,并将所述数据包进行排队;所述数据包包括流信息;
23.将排队后的数据包进行分类;
24.将分类后的数据包进行散列处理,并对散列处理后的数据包中的流信息进行处理;
25.将所述流量模块处理后且需要发送至所述虚拟路由器的数据包中的流信息排成信息队列,并将所述信息队列与任务请求捆绑后发送至所述虚拟路由器。
26.如上所述,本发明的虚拟路由器流处理系统及方法,具有以下有益效果:本发明的虚拟路由器流处理系统通过设置键值物理端口、数据包处理模块、流量模块及键值流嵌模块,可以实现数据包的分类及散列处理,可以实现数据包的重组及流量模块的分区,从而使得可以在运维层面查看到虚拟路由器下的数据流及数据包;在故障发生及性能调优时,不需要登入主机或设备网络进行抓包,也不需要繁琐的方式即可实现排障和定位。同时,本发明的虚拟路由器流处理系统是支持多协议的overlay(叠加或覆盖)网络,传统的基本要么只支持vxlan(virtual extensible lan),要么支持gre(generic routing encapsulation,通用路由封装),而本发明的虚拟路由器流处理系统可以同时支持vxlan和基于mpls(multiprotocol label switching)over gre,还有mpls over udp(user datagram protocol,用户数据报协议)。另一个亮点在于mpls over udp可以在三层网络也是现实ecmp(equal-cost multipath routing)的功能,传统的vxlan只能在二层网络实现ecmp,但在现在的网络环境及未来趋势,三层的ecmp也是需要得到支持。
附图说明
27.图1为本发明的虚拟路由器流处理系统的结构框图。
28.图2为本发明的虚拟路由器流处理方法的流程图。
29.标号说明:
30.1、键值物理端口,2、数据包处理模块,3、流量模块,31、流处理器,32、流表管理单元,33、索引管理单元,34、流键值同步单元,4、键值流嵌模块,5、数据客户端,6、流管理模块,7、流量继电器,8虚拟路由器引擎。
具体实施方式
31.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他
实施例,都属于本发明保护的范围。
32.以下描述中的优选实施例只作为举例,本领域技术人员可以想到其他显而易见的变型。在以下描述中界定的本发明的基本原理可以应用于其他实施方案、变形方案、改进方案、等同方案以及没有背离本发明的精神和范围的其他技术方案。
33.本领域技术人员应理解的是,在本发明的揭露中,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”等指示的方位或位置关系是基于附图所示的方位或位置关系,其仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此上述术语不能理解为对本发明的限制。
34.实施例一
35.请参阅图1所示,本发明提供一种虚拟路由器流处理系统,所述虚拟路由器流处理系统包括:
36.键值物理端口1,所述键值物理端口1与虚拟路由器(未示出)相连接,用于从所述虚拟路由器中获取数据包,并将所述数据包进行排队;所述数据包包括流信息;
37.数据包处理模块2,所述数据包处理模块2与所述键值物理端口1相连接,用于将排队后的数据包进行分类;
38.流量模块3,所述流量模块3与所述数据包处理模块2相连接,用于将分类后的数据包进行散列处理,并对散列处理后的数据包中的流信息进行处理;
39.键值流嵌模块4,所述键值流嵌模块4与所述流量模块3相连接,用于将所述流量模块3处理后且需要发送至所述虚拟路由器的数据包中的流信息排成信息队列,并将所述信息队列与任务请求捆绑后发送至所述虚拟路由器。
40.本发明的虚拟路由器流处理系统通过设置所述键值物理端口1、所述数据包处理模块2、所述流量模块3及所述键值流嵌模块4,可以实现数据包的分类及散列处理,可以实现数据包的重组及所述流量模块3的分区,从而使得可以在运维层面查看到虚拟路由器下的数据流及数据包;在故障发生及性能调优时,不需要登入主机或设备网络进行抓包,也不需要繁琐的方式即可实现排障和定位。
41.同时,本发明的虚拟路由器流处理系统是支持多协议的overlay网络,传统的基本要么只支持vxlan,要么支持gre,而本发明的虚拟路由器流处理系统可以同时支持vxlan和基于mpls over gre,还有mpls over udp。另一个亮点在于mpls over udp可以在三层网络也是现实ecmp的功能,传统的vxlan只能在二层网络实现ecmp,但在现在的网络环境及未来趋势,三层的ecmp也是需要得到支持。
42.作为示例,所述键值物理端口1还用于在将所述数据包进行排队之前,将获取的所述数据包增加代理标头;所述键值物理端口1用于将具有代理标头的数据包进行排布。
43.具体的,所述键值物理端口1(pk0)接口用来在代理和虚拟路由器之间交换数据包。通过pk0接口交换的所有数据包都将带有专有代理标头,即所述键值物理端口1会给获取的所有所述数据包都带上转有的代理标头。上面给出了代理头的格式代理在pkt0接口上打开一个套接字,并向boost asio库注册i/o。当接口上接收到数据包时,boost asio库会通知代理。收到来自boost asio库的通知后,代理会立即读取数据包,将数据包入队到所述数据包处理模块2,而无需解析数据包。
44.pk0通知发生在代理进程的主线程上下文中。由于主线程在任务库之外运行,因此模块不应访问代理中管理的任何数据库。收到数据包后,立即将其排入“数据包处理程序”。
45.在一示例中,所述数据包处理模块2接收由所述键值物理端口1排队的数据包。虚拟路由器将不同类型的数据包捕获到代理。例如,用于流设置的数据包、对网关ip的ping数据包、arp(address resolution protocol,地址解析协议)响应数据包等,分类后,数据包被排队到正确的模块。
46.所述流量模块3实现水平缩放以支持高流速。默认情况下,它有4个可以并行运行的“分区”。通过对数据包中的5元组进行散列处理,所述流信息分布在各个分区中。只有被vrouter(路由器)捕获的正向流被散列到一个分区。反向流将始终使用与其对应的正向流相同的分区。其中,数据包中的5元组可以包括源ip、目的ip、协议、源端口和目的端口。
47.进一步的,在数据转发中是存在包转发模式和流转发模式,用户可以自己去定义使用那种方式去做互通。
48.作为示例,分类后的数据包进行散列处理后分布于不同的分区;所述流量模块3包括:流处理器31、流表管理单元32、索引管理单元33及流键值同步单元34;其中,
49.所述流处理器31用于设置所述数据流的属性信息;
50.所述流表管理单元32用于维护各分区中所有流条目的树、识别重复流、进行策略匹配、将不一致状态的数据流标记为短流、将数据流从nat流转换为非nat流、调用新的数据流的索引管理器、添加更改或删除数据流;
51.所述索引管理单元33用于生成身份码(-id),以确保只有一个数据流主动使用索引;
52.所述流键值同步单元34用于确保数据流与索引引用下一跳及镜像索引的依赖关系,并对数据流进行编码或解码。
53.具体的,所述数据流的属性信息可以包括浮动ip、ecmp负载均衡、rpf下一跳、vrf翻译、元数据流和链接本地流。
54.所述流表管理单元32还可以通过查找网络策略和安全组来进行策略匹配。
55.具体的,所述虚拟路由器使用流头字节作为流的键值,代理引擎使用6-tuple作为键值。由于这种不一致,代理可能会看到多个使用相同索引的流(作为过渡状态)。
56.所述索引管理器单元33确保只有一个流会主动使用索引。为此,它使用成-id。生成-id值最高的流(即前面所述的流信息)可以拥有索引并对虚拟路由器进行操作。具有较旧生成-id的流被视为驱逐流并被删除。
57.一旦索引管理将索引的所有权授予流,它将调用所述流键值同步单元34将消息发送到所述虚拟路由器。
58.又一示例中,所述流键值同步单元34可以有如下两个主要功能:
59.(1)确保对象依赖,
60.流可以通过索引引用下一跳和镜像条目。所述流键值同步单元34确保在对流进行编程之前,将流指向的下一跳和镜像索引编程到所述虚拟路由器。
61.流键值同步提供了一种机制来确保上面列出的依赖关系。但是,ksync依赖跟踪不是多线程安全的,它期望在处理流键值同步消息时不会运行流设置。因此,所述流键值同步单元34支持简单的重试机制来确保依赖关系,而不是使用流键值同步依赖关系跟踪。
62.(2)消息编码
63.所述流键值同步单元34负责对流信息进行编码/解码到虚拟路由器。所述流信息在编码后排队到同步键值嵌套。
64.作为示例,所述虚拟路由器可以包括虚拟路由器引擎8,所述键值流嵌模块4将信息队列与任务请求捆绑后发送至虚拟路由器引擎8。
65.作为示例,所述虚拟路由器流处理还可以包括:
66.数据库客户端5,所述数据客户端5用于在接收到数据流调整通知时,判断所述数据流调整通知是否涉及修改数据流感兴趣的字段;若是,则生成数据流调整请求;
67.流管理模块6,所述流管理模块6与所述数据库客户端5及所述流量管理模块6相连接,用于基于所述数据流调整请求对所述流量管理模块中的数据流进行调整。
68.具体的,所述数据库客户端5将根据各种数据库表的当前内容进行设置。当配置更改时(例如安全组、网络策略等的更改),需要重新评估流程以与最新配置保持一致。所述数据库客户端5和“所述流管理模块6使流动作与最新配置保持一致。
69.所述数据库客户端5收到有关添加/删除/更改dbentries的通知。在接收到通知时,它会检查是否修改了流感兴趣的字段(例如:在接口通知中更改了安全组)。如果是这样,它会将请求排入所述流管理模块6以处理通知。在通知上下文中进行大量计算并不是一个好主意,因此它只会将消息排入所述流管理模块6。
70.作为示例,数据流调整可以包括数据流添加、数据流更改或数据流删除。
71.作为示例,所述流管理模块6还用于维护数据流到该数据流依赖的数据条目的列表及数据条目到依赖于该数据条目的数据流的列表。
72.具体的,所述流管理模块6获取不同类型的通知;
73.所述流表管理单元32中的流添加/更改/删除;
74.从所述数据客户端5添加/更改/删除数据库条目。
75.所述流管理模块6维护以下信息以跟踪流和数据条目之间的依赖关系:
76.流向它所依赖的数据条目列表(比如flow-to-dbentry树);
77.数据条目到依赖于数据条目的流列表(例如dbentry-to-flow树)。
78.当所述流管理模块6收到添加/更改/删除流的通知时,它将使用最新的依赖信息更新flow-to-dbentry树。数据条目通知的处理取决于数据条目的类型。
79.作为示例,所述虚拟路由器处理系统还可以包括:流量继电器7,所述流量继电器7用于清除所述流量模块3中超过预设长度或停留时间超过预设时间的数据流。
80.具体的,所述流量继电器7负责流的老化。老化算法具有以下参数:老化时间和扫描间隔。缺省情况下,老化时间为180秒。扫描间隔这是一次扫描完整流表的时间;这设置为老化时间的25%。因此,流动老化时间可以容忍老化时间的25%。
81.具体的,流表需要释放,特别是一些长链接的流表或者僵尸流表如果一直驻留在内部,很容易导致崩溃,所以需要有老化极致,一旦老化的话清除那么相应的一定要通知到所述流管理模块6和所述数据库客户端5,否则就会出来流量偏差和数据库锁死的问题,因为信息不匹配了。
82.实施例二
83.请结合图1参阅图2,本实施例中还提供一种虚拟路由器流处理方法,所述虚拟路
由器流处理方法包括:
84.s10:从虚拟路由器中获取数据包,并将所述数据包进行排队;所述数据包包括流信息;
85.s20:将排队后的数据包进行分类;
86.s30:将分类后的数据包进行散列处理,并对散列处理后的数据包中的流信息进行处理;
87.s40:将所述流量模块处理后且需要发送至所述虚拟路由器的数据包中的流信息排成信息队列,并将所述信息队列与任务请求捆绑后发送至所述虚拟路由器。
88.对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
89.此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1