一种高效可伸缩的CDN日志处理方法及系统与流程
一种高效可伸缩的cdn日志处理方法及系统
技术领域
1.本发明涉及cdn日志处理领域,具体涉及一种高效可伸缩的cdn日志处理方法及系统。
背景技术:
2.作为云服务提供商,需要为海量客户提供服务,其中cdn加速业务中会产生大量的访问日志。每个加速域名的cdn访问日志是客户用来做问题排查、数据分析以及核对账单等业务的重要依据。
3.从cdn边缘节点收集的访问日志称为原始日志,是压缩文件形式,每个文件记录了在一段时间内所有访问该cdn边缘主机的http请求信息。全网cdn节点的原始日志会源源不断地上报到数据中心,并最终保存在分布式存储集群中。
4.原技术方案是采用业界流行的大数据处理框架进行统一的日志处理,但实际使用下来,发现这种方案有如下不足:
5.(1)为满足通用处理场景,资源消耗巨大,需要投入较多的硬件资源和较高的维护成本;
6.(2)数据模型过于理想,解决实际问题的效率不高;
7.(3)受限于框架,开发灵活度不高;
8.(4)日志热点分析耗时过长,且资源消耗过多。
技术实现要素:
9.本发明的第一个目的是提供一种高效可伸缩的cdn日志处理方法及系统,能够根据不同业务规模动态伸缩处理节点的实例数量,能够更高效地利用机器资源,同时提高系统整体可用性,降低维护人员负担。
10.实现本发明的第一个目的的技术方案是:
11.一种高效可伸缩的cdn日志处理方法,包括以下步骤:
12.1)获取边缘节点上报的日志文件,保存到分布式存储模块;
13.2)存储事件监听模块监测到分布式存储模块有新的日志文件存入,将新存入的日志文件路径包含在新创建的日志处理任务中,将日志处理任务发送到分布式消息引擎模块;
14.3)分布式消息引擎模块,接收日志处理任务,将日志处理任务缓存在任务处理队列中等待拉取;
15.4)原始日志读取模块,从分布式消息引擎模块拉取到日志处理任务,解析并执行日志处理任务,将保存在分布式存储模块的日志文件按流式读取,将读出的日志,批量发送给日志分流投递模块;
16.5)日志分流投递模块,通过解析日志中的域名字段或域名桶字段,将字段值计算哈希并取模,得到消息主题的索引号,日志分流投递模块将日志发送到分布式消息引擎模
块,由计算的索引号确定对应的消息主题;
17.步骤5)中,将字段值计算哈希并取模来确定消息主题的索引号,可以确保相同的域名的日志发送到同一个消息主题中,方便后续日志聚合处理;
18.将字段值计算哈希并取模来确定消息主题的索引号,有助于为每个消息主题分配数量大致相同的域名,实现消息主题之间的负载均衡。
19.6)日志聚合处理模块拉取消息主题的日志消息,将日志消息按特定格式解析,提取出域名字段和域名桶字段,按照配置好的聚合规则依据域名字段或域名桶字段进行日志消息聚合,分别按标准格式写入到不同的日志文件,再将保存的日志文件上传到分布式存储模块,此时保存的日志称为标准日志,最终会提供给客户;
20.步骤6)中,同一个消息主题可以分配多个日志聚合处理模块,日志聚合处理模块是无状态服务,可以根据不同域名的日志数据量不同灵活伸缩实例数量。
21.7)日志热点分析模块,对保存在分布式存储模块的标准日志,进行扫描并生成分析报告。
22.步骤1)中,获取边缘节点上报的日志文件,具体包括:
23.1.1)边缘节点日志上报模块通过http请求把边缘节点上的日志文件上传到日志存储代理服务模块;
24.http请求包括http请求体、http请求参数;
25.1.2)日志存储代理服务模块根据http请求中的参数获取日志元信息,根据日志元信息拼接出目标路径,用目标路径以及http请求体构建rpc请求,发给分布式存储模块;
26.日志元信息包括边缘节点的主机ip以及日志文件的类型。
27.步骤7)中,扫描并生成分析报告,具体包括:
28.7.1)日志热点分析模块选取一个域名目录,逐个对标准日志文件进行流式读取;
29.7.2)日志热点分析模块从日志中解析出各指标,使用filtered-space saving(fss)流数据算法,统计不同热门指标的请求次数和请求大小。读取完所有标准日志文件,即可导出前k条热点统计结果,格式化导出为热点分析报告
30.步骤7.2)中,使用fss流数据算法为每个指标创建topk算子,每条日志中解析出的对应指标值按照siphash算法计算64位哈希摘要后作为存储键。其优点在于:
31.统计热门指标的传统方法是利用小根堆算法,但是面对海量日志请求,该算法需要消耗大量内存,且效率随数据量增长而下降。选用fss流数据算法,可以将内存消耗控制在稳定范围,其代价仅仅是牺牲少量准确性,我们生成热门分析报告准确度达到99%即可满足需求,所以牺牲少量准确性,就能让计算资源需求可控,且统计热门资源更加高效;另外使用结合使用siphash算法预处理存储键,进一步提高计算性能。
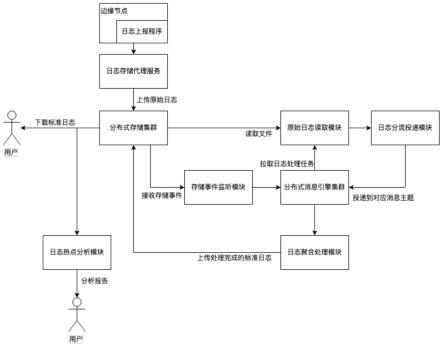
32.一种高效可伸缩的cdn日志处理系统,包括边缘节点日志上报程序、日志存储代理服务,分布式存储集群、存储事件监听模块、分布式消息引擎集群、原始日志读取模块、日志分流投递模块、日志聚合处理模块、日志热点分析模块。
33.与现有技术相比,本发明具有如下优点:
34.一、本发明提供高效可伸缩的cdn日志处理系统,可以满足特定的cdn日志处理需求,而无需消耗过多机器资源;
35.二、本发明的各个处理模块均实现多实例化,可方便伸缩,没有单点故障隐患,大
大提高了系统整体可用性;
36.三、本发明通过多个模块组合,提高零活度,因而更方便实现热点分析功能的迭代;
37.四、本发明通过采用fss流数据算法提高热点分析效率,节省计算资源。
附图说明
38.图1为本发明一种高效可伸缩的cdn日志处理系统的数据流图。
39.图2为本发明日志代理服务的处理流程图。
40.图3为本发明一种高效的热点分析方法处理流程图。
具体实施方式
41.具体地,一种高效可伸缩的cdn日志处理系统,包括;
42.边缘节点日志上报模块,通过http请求把边缘节点上的日志文件上传到日志存储代理服务模块;http请求包括http请求体、http请求参数
43.日志存储代理服务模块,根据http请求中的参数获取日志元信息,根据日志元信息拼接出目标路径,用目标路径以及http请求体构建rpc请求,发给分布式存储模块;日志元信息包括边缘节点的主机ip以及日志文件的类型;
44.分布式存储模块,分布式存储模块接收到日志存储代理服务模块发送的rpc请求,将日志文件保存到目标位置;
45.存储事件监听模块,监测到分布式存储模块有新的日志文件存入,将新存入的日志文件路径包含在新创建的日志处理任务中,将日志处理任务发送到分布式消息引擎模块;
46.分布式消息引擎模块,接收日志处理任务;
47.原始日志读取模块,从分布式消息引擎模块拉取到日志处理任务,解析并执行日志处理任务,将保存在分布式存储模块的日志文件按流式读取,将读出的日志,批量发送给日志分流投递模块;
48.日志分流投递模块,通过解析日志中的域名字段或域名桶字段,将字段值计算哈希并取模,得到消息主题的索引号,日志分流投递模块将日志发送到分布式消息引擎模块,由计算的索引号确定对应的消息主题;
49.日志聚合处理模块,拉取消息主题的日志消息,将日志消息按照域名字段或域名桶字段聚合,分别按标准格式写入到不同的日志文件,再将保存的日志文件上传到分布式存储模块,保存的日志称为标准日志;
50.日志热点分析模块,对保存在分布式存储模块的标准日志,进行扫描并生成分析报告。
51.该系统包括如下处理流程:
52.(1)边缘节点日志上报程序,运行在cdn边缘主机上,每隔5分钟将cdn访问日志截断保存、压缩、上传给数据中心的日志存储代理服务。
53.(2)日志存储代理服务接收到上传日志的http请求,将接收到的请求体内容转存至分布式存储集群。
54.(3)存储事件监听模块,监测到分布式存储集群有新的日志文件存入,将新存入的日志文件路径包含在新创建的日志处理任务中,将日志处理任务发送到分布式消息引擎集群
55.(4)原始日志读取模块,作为分布式消息引擎的消费端,拉取到日志处理任务;
56.(5)原始日志读取模块解析并执行日志处理任务,将保存在分布式存储集群的日志文件按流式读取;
57.(6)原始日志读取模块将读出的日志,批量发送给日志分流投递模块;
58.(7)日志分流投递模块,通过解析日志中的域名字段或域名桶字段,将字段值计算哈希并取模,得到消息主题的索引号;
59.(8)日志分流投递模块将日志发送到分布式消息引擎集群,由(7)中计算的索引号确定对应的消息主题;
60.(9)日志聚合处理模块,作为分布式消息引擎的消费端,拉取特定消息主题的日志消息;
61.(10)日志聚合处理模块,将日志按照域名字段或域名桶字段聚合,分别保存到不同文件中;
62.(11)日志聚合处理模块,记录每个文件的最后写入时间,若文件超过1分钟没有新的写入,则认为文件写入结束,再将保存的日志文件上传到分布式存储集群,此时保存的日志称为标准日志;
63.每隔24小时,日志热点分析模块,对保存在分布式存储集群的标准日志,进行扫描并生成分析报告。
64.步骤(2)中,日志代理服务是多实例可伸缩的http服务端程序,其转存日志文件包括以下步骤:
65.2.1)收到日志上报程序发送的http put请求;
66.2.2)从http请求参数中获取日志元数据信息,包括日志所属节点ip、日志产生时间、日志文件格式;
67.2.3)将http请求体读取到内存;
68.2.4)请求分布式存储集群,创建一个待写入的目标文件,保持tcp连接;
69.2.5)将内存中的数据写入分布式存储集群中的目标文件;
70.2.6)若文件写入完成,关闭tcp连接,进入步骤2.7);若文件写入失败,关闭tcp连接,进入步骤2.8);
71.2.7)向日志上报程序响应200状态码,表示日志保存成功,进入步骤2.9)。
72.2.8)向日志上报程序响应500状态码,并返回失败原因;
73.2.9)结束。
74.步骤2.4)中,待写入的目标文件路径由2)中的日志元数据信息拼接而来。
75.本发明的第二个目的是提供一种高效的热点分析方法,能够以可容忍的精确度损失,换取可观的热点分析性能。
76.实现本发明的第二个目的的技术方案是:一种高效的热点分析方法,包括以下步骤:
77.(a)热点分析模块选取一个域名目录,逐个读取标准日志文件;
78.(b)热点分析模块从日志中解析出请求大小、url、请求状态码、useragent等等信息;
79.(c)热点分析模块使用filtered-space saving(fss)流数据算法,统计不同热门指标的请求次数和请求大小;
80.(d)fss算法统计前k条的热点值,为了平衡精确度损失和内存资源消耗,分析程序会申请大于k个节点的空间,取值在1.5k至2k;
81.(e)读取完所有标准日志文件,即可导出前k条热点统计结果,格式化导出为热点分析报告。
82.如图1所示,本实施例包括边缘节点日志上报程序、日志存储代理服务,分布式存储集群、存储事件监听模块、分布式消息引擎集群、原始日志读取模块、日志分流投递模块、日志聚合处理模块、日志热点分析模块,以及用户。
83.日志存储代理服务为高性能http网关服务;分布式存储集群为商用对象存储服务集群或大规模hdfs集群;分布式消息引擎集群一般采用kafka集群。
84.本实施例包括以下步骤:
85.(1)边缘节点日志上报程序,每隔5分钟将cdn访问日志收集上传给数据中心的日志存储代理服务;
86.(2)日志存储代理服务将上传的日志文件转存至分布式存储集群;
87.(3)存储事件监听模块将新的日志处理任务发送到分布式消息引擎集群;
88.(4)原始日志读取模块,收到并执行日志处理任务,将保存在分布式存储集群的日志文件逐行读取,再批量发送给日志分流投递模块;
89.(5)日志分流投递模块,通过日志中特定字段算出消息主题的索引号,在将日志发送到分布式消息引擎集群;
90.(6)日志聚合处理模块,拉取特定消息主题的日志消息,将日志按照域名字段或域名桶字段聚合,分别保存到不同文件中,最终上传至分布式存储集群;
91.(7)日志热点分析模块,每隔24小时,对保存在分布式存储集群的标准日志,进行扫描并生成分析报告。
92.其中(1)中上传的日志称为原始日志;(6)上传的日志称为标准日志,仅标准日志可提供给用户下载;(7)中的分析报告,每24小时生成,针对用户的每个域名产生一份;可供用户查看。
93.如图2所示,步骤(2)中,日志存储代理服务将上传的日志文件转存至分布式存储集群包括以下步骤:
94.(2.1)收到日志上报程序发送的http put请求;
95.(2.2)从http请求参数中获取日志元数据信息;
96.(2.3)将http请求体读取到内存;
97.(2.4)请求分布式存储集群,创建一个待写入的目标文件;
98.(2.5)将内存中的数据写入分布式存储集群中的目标文件;
99.(2.6)若文件写入完成,向日志上报程序响应200状态码;若文件写入失败,向日志上报程序响应500状态码。
100.如图3所示,步骤(7)中日志热点分析模块的工作流程,包括以下步骤:
101.(7.1)选取一个域名目录进行遍历;
102.(7.2)逐行读取一个标准日志文件;
103.(7.3)从日志中解析出请求大小、url、请求状态码、useragent等等信息;
104.(7.4)使用filtered-space saving(fss)流数据算法,先检查是否已经初始化,若未初始化,先申请1.5k至2k个节点空间,满足topk统计需求。
105.(7.5)将待统计的指标数据输入fss算法,将统计不同热门指标的请求次数和请求大小;
106.(7.6)若还有文件需要读取,回到步骤(7.2);
107.(7.7)读取完所有标准日志文件,则导出前k条热点统计结果,格式化导出为热点分析报告。
108.如表4所示,采用这种高效可伸缩的cdn日志处理系统方案达到降本增效的目的,整个日志处理链路的每个模块均具备按照实际业务规模灵活伸缩实例数量的能力。
109.表4
110.
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1