一种面向下一代光纤通信标准的oFEC译码系统
一种面向下一代光纤通信标准的ofec译码系统
技术领域
1.本发明涉及一种面向下一代光纤通信标准的ofec译码系统。
背景技术:
2.光纤通信是现代通信系统中的关键组成部分,其吞吐量巨大的特点完美契合当代互联网通信的需求。为了保证如此庞大的传输数据量的可靠性,前向纠错码(fec)在光纤通信中发挥着至关重要的作用。纠错码也叫做差错控制编码,亦称为信道编码,目的是为了克服信道噪声对传输数据的干扰,接收端可以通过某种译码算法对接收到的信息自行进行错误纠正。纠错功能的实现需要以冗余作为代价,牺牲有效数据,提升数据传输的可靠性,越多的冗余意味着越高的纠错能力。
3.目前,400g光纤通信系统的标准化工作已经完成,下一代800g光纤通信也进入研究阶段。400g光纤通信标准400zr已经被提出。400g光纤通信系统采用的纠错码是staircase码,该码可提供高达400gbps的吞吐量。随着对400g光纤通信系统的研究不断深入,以及相关产品的问世和商用,吞吐量高达800gbps的下一代光纤通信系统引起了广泛的关注。目前,open roadm标准化工作中提出下一代光纤通信标准中采用的纠错码为ofec码,该码的本质是一种以bch码为子码的卷积码。bch的译码算法包括berlekamp-massey(bm)算法、欧几里得算法、彼得森(peterson-gorenstein-zierler,pgz)算法等。其中,彼得森算法适用于纠错能力小的bch码。
4.现有的光纤通信系统采用的是400zr标准中所提出的设计方案。该系统采用的纠错码是staircase码,在当前公开的设计中(参考文献:truhachev d,el-sankary k,karami a,et al.efficient implementation of 400gbps optical communication fec[j].circuits and systems i:regular papers,ieee transactions on,2020,pp(99)),针对staircase码的译码器能达到的最大吞吐量为511gbps,并不能满足下一代光纤通信的吞吐量需求。
技术实现要素:
[0005]
发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种面向下一代光纤通信标准的ofec译码系统,包括ofec码译码器,所述ofec码译码器遵循单指令多数据simd过程,即每条指令下对p个bch子码进行译码,其中p为并行度。
[0006]
所述ofec码译码器包括存储器、bch译码器、输入转置模块和输出转置模块;
[0007]
所述ofec码译码器通过如下操作完成译码过程:
[0008]
读rd操作:所述ofec码译码器的输入是ofec码的p行,这也是p个bch码字的后半部分;同时,从存储器中读出p个bch码字的前半部分;所述p个bch码字的前半部分是存储格式的,后半部分是译码格式的;
[0009]
输入转置tp操作:输入转置模块将输入的存储格式的bch码字前半部分转换为用于译码器进行译码的格式输出,与bch码字的后半部分直接拼接成p个完整的bch码字,准备
译码;
[0010]
译码dec操作:bch译码器对bch码字进行译码;
[0011]
输出转置tb操作:输出转置模块在译码后把输出bch译码器的bch码字转换成存储格式;
[0012]
写wr操作:将存储格式的bch码字写入存储器;
[0013]
输出out操作:已译码的ofec的p行从存储器中读出作为输出。
[0014]
所述ofec译码器的吞吐量θ由下面的公式来定义:
[0015][0016]
其中t为时钟周期,cpi表示每个指令的时钟周期,n为ofec码一行的比特数,rate为bch码的码率。
[0017]
所述存储器由两块完全相同的双端口存储器组成,记做奇偶两块,双端口存储器中一个端口用于读rd操作,另一个端口用于写wr操作。
[0018]
所述存储器采用转发技术,即使用选择器,将输出转置模块输出的可能与存储器读出的数据产生数据冒险的数据提前输出。
[0019]
所述输入转置模块用于,将bch码字前半部分的比特取出存储器后进行转置,再与输入ofec译码器的后半部分进行拼接;
[0020]
所述输出转置模块用于,在译码结束后将bch码字后半部分比特转置后放回到bch码前半部分在存储器中被取出的位置。
[0021]
所述输入转置模块将二维的存储格式的数据转换成一维的译码格式的数据,输出转置模块将一维的译码格式的数据转换成二维的存储格式的数据,且转置操作直接通过硬件走线来实现,具体是通过走线将二维二进制方阵中的元素连接到一维向量的对应位置,公式如下:
[0022][0023]
由于矩阵是二进制的,参数ai,bi,
…
,di均为0或1,0≤i≤n-1。
[0024]
所述bch译码器基于彼得森算法进行设计,一个周期即能够完成整个bch码的译码,且在bch译码器中插入一级流水线。
[0025]
本发明针对在open reconfigurable optical add/drop multiplexers(roadm)标准化工作中提出的下一代800g高速光纤通信系统所采用的码字open forward error correction(ofec)码,基于流水线技术和单指令多数据(single instruction multiple data,simd)技术,实现了吞吐率超800gbps的ofec码的译码架构。但是,译码器流水化实现会带来转置冒险、结构冒险和数据冒险问题。本发明通过数据降维和硬件连线、存储奇偶分块和转发技术分别解决了上述冒险问题。
[0026]
本发明是基于open roadm中提出的方案进行了相应的译码器的设计,与400g的光纤通信系统相比,采用的是全新的ofec纠错码。与staircase相比,ofec采取的是完全不同的译码策略,且本发明所述的架构可以达到超800gbps的吞吐量,满足下一代光纤通讯的吞
吐量需求。
[0027]
本发明具有如下有益效果:
[0028]
(1)本发明提出一种吞吐量高达800gbps的ofec码译码系统。本系统基于simd的思想,将译码过程划分为rd、td、dt、wr和out这5个阶段,并且引入了流水线技术,提高了吞吐率;
[0029]
(2)提出了高效的数据存储形式和转置方案。将二维数据降至一维方便存储,且对于小规模的一维数据,转置操作直接采用硬件走线实现,规避转置冒险减小硬件开销;
[0030]
(3)提出了一种高效的译码存储策略。本发明通过推导得到ofec码的在存储器中的位置遵循一定规律,进而通过使用奇偶两块完全一致的双端口存储器,有效地解决了译码过程中存在的结构冒险问题;通过额外的硬件开销解决译码输出时的数据冒险问题。上述手段避免了流水线停顿,提升了吞吐率。
附图说明
[0031]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
[0032]
图1是一个ofec码字示意图。
[0033]
图2是ofec码的单周期译码架构示意图。
[0034]
图3是流水线化的译码流程图。
[0035]
图4是与图3对应的第4和第5周期奇偶存储器的读写示意图。
具体实施方式
[0036]
1.ofec码基础及其编译码算法
[0037]
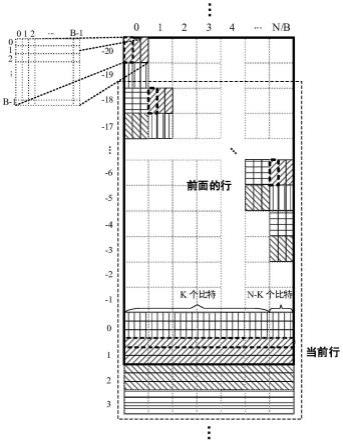
首先对本发明所采用的ofec码进行介绍。ofec码是一种以bch码为子码的卷积码。ofec中的码字是一个半无限的比特集合,被存放在一个具有半无限行数和n列的矩阵中。这个半无限的矩阵能够被划分为很多个大小为b
×
b的方块,如图1所示,即每个方块每行存放b个比特,每列也存放b个比特。该矩阵每行有n/b个这样的方块,每个方块由方块行号r和方块列号c来标识(0≤c<n/b),分别出现在图1大矩阵的左侧和顶部。方块内的每一个比特用它的行数r和列数c标识,其中0≤r<b,0≤c<b。总的来说,此半无限矩阵中的每个比特可以用四元数组{r,r,c,c}来进行标识。
[0038]
矩阵的每一行都是k个信息位和n-k个奇偶校验位组成的。因为ofec是卷积码,n-k个奇偶校验位不仅由当前行的k个信息位决定,还由前面行的n个特定比特决定。来自前面行的n个比特和n个当前行的比特共同组成了一个(2n,n+k)的bch子码。ofec码中的某一行比特由二元数组{r,r}或式子rb+r标识,两种标识方法中均含有一个方块行号r和一个比特行号r。一个bch码字可以通过包含该码字的后半部分的所有比特的行的数量来标识。bch码字{r,r}的第i个比特可以用四元数组{r(i),r(i),c(i),c(i)}来标识。其中r(i)表示第i个比特所在方块在整个半无限矩阵中的所在的行值关于i的位置函数,c(i)表示第i个比特所在方块在整个半无限矩阵中的所在的列值关于i的位置函数,r(i)表示第i个比特在方块内部所在行值关于i的位置函数,c(i)表示第i个比特在方块内部所在列值关于i的位置函数;
[0039]
对于bch码字的后半部分(n≤i<2n),位置函数为:
[0040]
r(i)=r
ꢀꢀ
(1)
[0041]
r(i)=r
ꢀꢀ
(2)
[0042][0043]
c(i)=(k%b)
⊕
t
ꢀꢀ
(4)
[0044]
对于bch码字的前半部分(0≤i<n),位置函数为:
[0045][0046]
r(i)=(k%b)
⊕rꢀꢀ
(6)
[0047][0048]
c(i)=r
ꢀꢀ
(8)
[0049]
其中,%表示取模操作,表示向下取整,
⊕
表示异或操作。
[0050]
下面对本发明采用的ofec的编码和译码过程进行介绍。
[0051]
ofec的编码基于一个编码窗口进行,如图1中大的黑色粗线矩形框所示。首先输入端输入k个比特,这k个比特与从前面的块中取出的n个比特(如图1所示,在前面的块中按照列来取,具体取哪些比特由bch码字的前半部分的位置函数给出)共同组成bch的n+k个信息位,然后进行bch编码,输入的k个比特和编码得到的n-k个校验比特放到当前行(每个比特具体存放在哪个位置由bch码字的后半部分的位置函数给出)。如图1所示,属于同一bch码字的比特用同种花纹来标识,例如,图1中前面行粗线竖虚线框中的比特和当前行粗线横虚线框中的比特顺次拼接共同构成一个(2n,n+k)bch码。每轮编码都会填满两行块,如果当前的编码窗口被填满,编码窗口会向下滑动,空闲出新的行块,窗口之外的数据将不再被保存,编码基于新窗口中的数据进行。例如,图1中黑色粗线矩形框是上一时刻的编码窗口,当它最后一行的方块都被填满时,窗口向下滑动,新的编码窗口由图中虚线矩形框标识,此时空闲出新的行,继续进行下一轮编码直到被填满。一般来说,由如下公式计算内存块行地址ar:
[0052]ar
=(r+w)%(w+2)
ꢀꢀ
(9)
[0053]
其中,w+2是窗口的大小,且w为偶数。
[0054]
ofec的译码过程可以看做是编码过程的逆过程。译码过程同样基于一个和编码窗口大小相同的译码窗口。译码器接收到新输入的比特序列与前面行的比特组成完整的bch码,然后进行bch译码。译码后的前面的行的比特存放回到取出的位置,译码后的新输入的比特序列存放到窗口最下面的行块中。最后,窗口下滑,空闲出新的行块,准备接收新的比特序列开始下一轮译码,而由于滑动而不再包含在窗口中的比特作为ofec码的输出。
[0055]
2.ofec码译码器
[0056]
本发明提出的ofec码单周期译码架构如图2所示,其中包括存储器、bch译码器和两个转置模块。译码器遵循“单指令多数据(simd)”过程,即每条指令下对p个码字进行译码,其中p为并行度。本发明将ofec码的译码过程分为6个操作:
[0057]
(1)读(rd)操作:输入是ofec码的p行,这也是p个bch码字的后半部分。同时,从存储器中读出此p个bch码字的前半部分。这p个bch码字的前半部分现在是存储格式的,后半
部分是译码格式的。
[0058]
(2)输入转置(tp)操作:输入转置模块将存储格式的bch码字前半部分转换为方便译码器进行译码的格式输出,与bch码字的后半部分直接拼接成p个完整的bch码字,准备译码。
[0059]
(3)译码(dec)操作:bch译码器对bch码字进行译码。
[0060]
(4)输出转置(tb)操作:译码后的bch码字被转换回存储格式。
[0061]
(5)写(wr)操作:将存储格式的bch码字写入存储器。
[0062]
(6)输出(out)操作:已译码的ofec的p行从存储器中读出作为输出。
[0063]
ofec译码器的吞吐量θ由下面的公式来定义:
[0064][0065]
其中t为时钟周期,cpi表示每个指令的时钟周期,rate为bch码的码率。对于本发明所提出的单周期译码器,cpi的值为1。为了提升吞吐量,本发明采用流水线技术,为了减小关键路径,本发明在bch译码器中插入流水线将译码(dec)指令分为两部分,分别与输入转置(tp)和输出转置(tb)操作结合,以td和dt指令来标识。整个译码器的工作时序如图2和图3所示,需要5个周期来完成rd、td、dt、wr和out指令。
[0066]
本发明中流水线的应用使得译码过程中存在转置冒险、结构冒险和数据冒险,这会造成流水线停顿,降低吞吐率。针对这些潜在的冒险,本发明做了专门的设计来进行规避,下面对本发明中ofec码译码器的各个部分进行说明。
[0067]
存储器:
[0068]
在bch译码前需要从存储器中读取bch码字,且在bch译码完成后要将译码完成的码字写回存储器。由于ofec码的译码特性需要同时从存储器读出两组码字并且将两组译码后的码字写入存储器,因此需要同一时刻对存储器读两次,写两次,需要真四端口存储器才能实现,这将会造成更大的面积开销。如果使用一块双端口存储器,将会导致同一时刻对存储器的同个地址同时进行读写操作,即发生结构冒险。但是对于ofec码字,其bch译码过程中的内存访问具有如下两个定理:
[0069]
定理1:如果bch码字的后半部分位于偶数(奇数)块行中,则bch码字的前半部分位于奇数(偶数)块行中;
[0070]
定理2:如果bch码字的后半部分位于偶数(奇数)内存地址,则bch码字的前半部部分位于奇数(偶数)内存地址。
[0071]
其证明如下:
[0072]
设定bch码字的前半部分和后半部分(前半部分和后半部分是两等分)的块行分别为r1(i)和r2(i),两部分行块数目相等。从公式(1)和(5)可以得到,(i),两部分行块数目相等。从公式(1)和(5)可以得到,r2(i)=r。对这两个式子进行模2操作,可以得到r1(i)%2=(r
⊕
1)%2,r2(i)%2=r%2。因此,如果r2是偶数(奇数),那么r是偶数(奇数)。因此,r
⊕
1是奇数(偶数),然后,得到r1(i)是奇数(偶数)。设定bch码字的前半部分和后半部分的内存地址分别为a1(i)和a2(i),从式(9)可知,a1(i)=(r1(i)+w)%(w+2),a2(i)=(r2(i)+w)%(w+2)。对a1(i)模2,由于w是偶数,得到a1(i)%2=r1(i)%2,a2(i)%2=r2(i)%2。因此在满足定理1的同时,如果a2(i)是偶数
(奇数),那么a1(i)是奇数(偶数)。
[0073]
根据上述定理,本发明将存储器分为奇偶两块,可以解决结构冒险。图4所示的是第4和第5个周期时存储器的读写情况,图4中存储方块的图案与图3中指令的图案相对应。在本发明中,主要考虑使用双端口存储器,一个端口用于读(rd)操作,另一个端口用于写(wr)操作,因此同一个存储块中同时出现r和w时,不会造成冲突。
[0074]
此外,这是即使进行了存储分块,依然存在如图4周期数为4时偶数块中黑色粗线矩形框中所示的对同一地址同时读写的情况。在周期4中,对于i0,偶数内存块中地址0处(竖线填充)的数据被读出作为输出。但是,c=0处的内存块(黑色粗线矩形框标出)中地址0处的数据尚未更新,发生数据冒险。本发明采用转发技术通过添加额外的硬件来解决数据冒险问题。如图3中黑色粗线矩形框所示,i1的dt周期中的译码数据被转发到i0的输出。带有转发的硬件架构如图2所示,硬件开销大约是一个选择器。
[0075]
转置模块:
[0076]
本发明设计的系统中存在两个转置模块:输入转置(tp)模块和输出转置(tb)模块。如前面ofec码基础部分所述,在从存储器中取出bch码字时,需要同时分别读取一个bch码的前半部分和后半部分,前半部分在存储器中按列排列,后半部分在存储器中按行排列;同样地,在bch译码结束后,需要按照同样的方式将译码后的码字放回。对于同一块存储器,只能有按行或者按列一种组织方式。因此,需要将bch码字前半部分的比特取出后进行转置再与后半部分进行拼接才能进行译码;同样地,译码结束后需要将前半部分比特转置后放回。本发明将一个方块内的二维数据降至一维,因此可以方便地存在存储器的一个单元中,且转置操作直接通过硬件连线来实现,由于转置的比特矩阵规模较小,不会产生过大的开销。取出和放回的转置方式是一致的,理论上可以采用同一块转置电路,但是由于流水线的存在会发生对转置模块的抢占,因此本发明通过增加相同硬件的方式来规避转置冒险,设计了输入转置(tp)和输出转置(tb)两个转置模块。
[0077]
bch译码器:
[0078]
由于ofec码字中采用的bch码纠错能力较小且码长较短,为了减少译码单个码字的时钟周期数,本发明所使用的bch译码器基于彼得森算法进行设计,一个周期即可完成整个bch码的译码。为了减小关键路径,在bch译码器中插入一级流水线。
[0079]
本发明基于上述模块设计,使得流水线的引入不会发生停顿和冒险,cpi达到1。
[0080]
实施例:
[0081]
以基于ebch(256,239)的ofec码为例进行说明。n=128,b=16,即每个方块的大小为16*16。译码窗口的行数为w+2=22,列数为n/b=128/16=8。并行度为p=32,即每次要对两行块的bch码进行译码。按照本发明中的存储策略,存储块分为奇偶两块,每块的大小为11*8,由8个宽度为16*16=256,深度为11的ram组成。采用smic 28nm工艺进行综合仿真,将得到的结果与论文“truhachev d,el-sankary k,karami a,et al.efficient implementation of 400gbps optical communication fec[j].circuits and systems i:regular papers,ieee transactions on,2020,pp(99)”中提出的400g staircase方案进行对比,结果如表1所示:
[0082]
表1
[0083][0084]
本发明提供了一种面向下一代光纤通信标准的ofec译码系统,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1