一种基于转发图的域内路由保护方法
1.本发明属于互联网中域内路由保护的技术领域,具体涉及一种基于转发图的域内路由保护方法。
背景技术:
2.在过去的几十年里,互联网已经从一个最初支持发送邮件等业务的小型网络迅速演变为支持社交网络、在线交易和即时通信等的大型基础设施。与此同时,互联网服务提供商(internet service provider,isp)在服务质量方面面临着越来越高的要求,例如向最终用户提供优质的服务质量,包括无间断服务、低延迟、高带宽等。
3.在上述互联网服务遇到的问题中,isp如何向用户提供无间断的服务面临严峻的挑战。针对这个问题,学术界提出利用npc,dc,mara,jnhor-sp,not-via和段路由(segment routing,sr)等技术来提供无间断服务,应对网络中的突发故障情形。虽然npc和dc的实现方式简单,但是故障保护率较低。mara的核心思想是将网络拓扑转换为dag。但是这些方案和网络拓扑结构密切相关,在某些拓扑结构中故障保护率较低.在dag图中,每条链路仅仅有一个方向,这个要求大大降低了结点可以计算出无环路备份下一跳的的可能性。jnhor-sp利用路由排序和joker链路来提高dag图的故障保护率,网络中的joker链路具有两个方向,但是由于计算joker链路算法的缺陷,jnhor-sp平均可以提供95%左右的故障保护率。lfid通过扩展dag,将部分链路修改为双向链路,从而同时解决网络故障和网络拥塞问题,但是lfid的故障保护率在88.9%~98.2%之间。not-via和段路由虽然可以保护网络所有可能的单故障,但是二者需要借助辅助机制的协助,在实际中部署比较困难。
4.因此,目前已有的路由保护算法仍存在以下几个方面的问题:(1)无法应对网络中所有可能的单故障情形;(2)需要额外辅助机制的协助;(3)不支持增强部署;(4)存储多个备份下一跳。
技术实现要素:
5.为了方便描述,我们先定义一些标记,这些标记适用于整个发明。
6.一个网络拓扑可以表示为图g=(v,e)。在图g中v用来代表网络拓扑中所有结点的集合,e用来表示网络拓扑中所有链路的集合。我们用r(d)表示目的结点为d的反向最短路径树,用g(d)表示目的结点为d的转发图。
7.我们利用遗传算法来构造转发图,染色体的编码规则为:将图g中所有边的方向用两个数字a,b来表示,每个数字的取值为0或1,所以一条边(u,v)可能对应的编码有四种情况,00代表u不可到达v,v也不可到达u;01表示u
→
v;10表示u
←
v;11表示我们用p(g(d))表示以结点d为目的结点的故障保护率,取值范围为[0,1],故障保护率的计算方法为其中当节点v被保护时f(v,d)=1,否则f(v,d)=0。我们用s(g(d))表示以结点d为目的结点的路径拉伸度,路径拉伸度的计算公式为
其中d(v,d)表示从v到d的最短路径的代价,bd(v,d,b)表示当故障结点为b时,从v到d的备份路径的代价。我们用fit(c)来表示适应度,其中fit表示适应度函数,c表示一个染色体。
[0008]
在遗传算法中,我们同时使用p(g(d))和s(g(d))来表示适应度,当两个适应度比较时,考虑两种情况:若两个适应度的p(g(d))都等于1,那么s(g(d))越小适应度越好;否则p(g(d))越大适应度越好。
[0009]
在遗传算法中,基因有一定几率发生变异,在本方法中,基因的变异代表了边方向的改变,为了保证每次基因变异后网络中都不会产生环路,我们在基因变异后检测网络中是否存在环路,若存在,就取消这次变异。在一定几率下,染色体会发生交叉互换,与另一个染色体交换基因。
[0010]
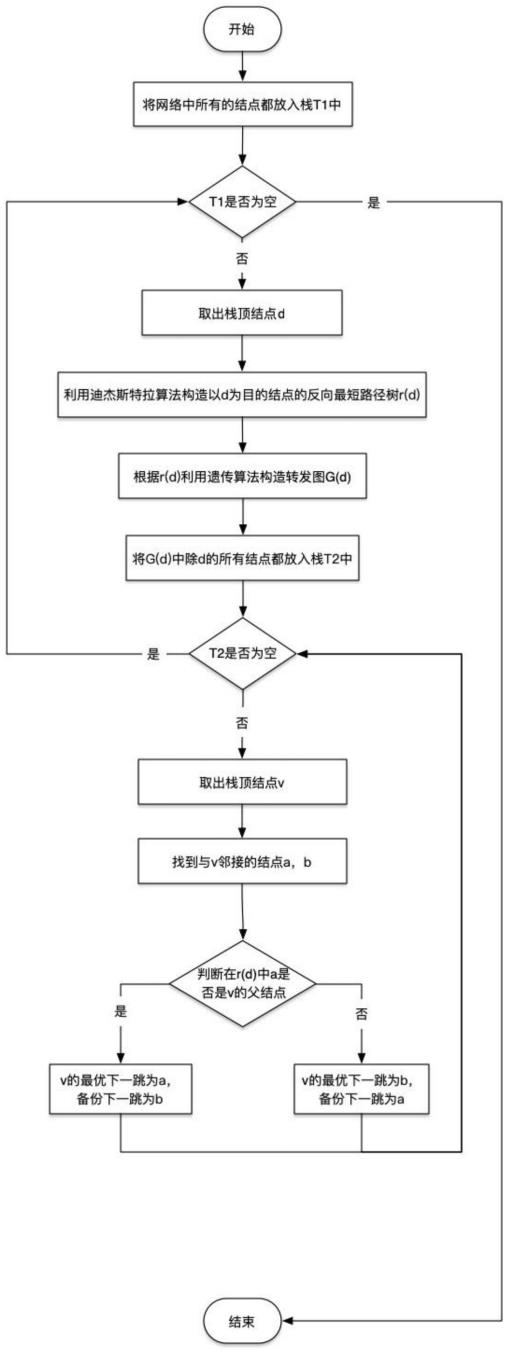
为了解决背景技术中已有的路由保护算法存在诸多问题,本发明在互联网内路由保护中首次引入遗传算法来构造转发图,为此,我们提供了一种基于转发图的域内路由保护方法,其主要包括以下步骤:
[0011]
步骤1:将网络中所有的结点都放入栈t1中;
[0012]
步骤2:判断栈t1是否为空,如果不成立,执行步骤3,否则,结束算法;
[0013]
步骤3:在栈t1中取出栈顶结点d;
[0014]
步骤4:利用迪杰斯特拉算法构造以d为目的结点的反向最短路径树r(d);
[0015]
步骤5:根据反向最短路径树r(d)利用遗传算法构造转发图g(d);
[0016]
步骤6:将g(d)中除目的结点d外的所有结点都放入栈t2中,执行步骤7;
[0017]
步骤7:判断栈t2是否为空,如果不成立,执行步骤8,否则,执行步骤2;
[0018]
步骤8:在栈t2中取出栈顶结点v;
[0019]
步骤9:在转发图g(d)中,找到与v邻接的两个结点a,b,执行步骤10;
[0020]
步骤10:在反向最短路径树r(d)中,判断a是否为v的父结点,如果成立,将a设置为v的最优下一跳,b设置为v的备份下一跳,否则,将b设置为v的最优下一跳,a设置为v的备份下一跳,执行步骤7。
[0021]
在上述技术方案中,其中算法步骤5中关于利用遗传算法构造转发图g(d)的方法为:
[0022]
步骤1设置遗传算法中种群规模n、进化轮数m、变异概率p、交叉概率q的参数;
[0023]
步骤2:初始化列表c;
[0024]
步骤3:将图g中所有的边都放入栈t中,执行步骤4;
[0025]
步骤4:判断栈t是否为空,如果不成立,执行步骤10,否则,执行步骤5;
[0026]
步骤5取出栈顶边(u,v);
[0027]
步骤6:判断(u,v)是否属于反向最短路径树r(d),如果成立,执行步骤7,否则,执行步骤8;
[0028]
步骤7:在反向最短路径树r(d)中,判断u是否为v的父结点,如果成立,将10添加到列表c中,否则,将01添加到序列c中,执行步骤4;
[0029]
步骤8:将00添加到列表c中;
[0030]
步骤9:执行步骤4;
[0031]
步骤10:将列表c复制n份,得到c1,c2,
…cn
,执行步骤11;
[0032]
步骤11:初始化变量i=1,执行步骤12;
[0033]
步骤12:判断i是否小于等于m,如果成立,执行步骤13,否则,执行步骤18;
[0034]
步骤13:计算每个染色体适应度,得到f1,f2,
…fn
,执行步骤14;
[0035]
步骤14:将所有染色体根据适应度高低排序,淘汰适应度较低的一半染色体,保留适应度高的一半的染色体,也就是个染色体,执行步骤15;
[0036]
步骤15:通过变异交叉,生成个新的染色体,在该步骤中,初始状态为1的基因不会变异,因为这些位置对应的是最优下一跳;
[0037]
步骤16:对i重新赋值i=i+1;
[0038]
步骤17:执行步骤12;
[0039]
步骤18:将所有染色体根据适应度高低排序,挑出适应度最高的染色体执行步骤19;
[0040]
步骤19:初始化转发图g(d),只保留图g中的所有结点,执行步骤20;
[0041]
步骤20:将染色体中的编码两个一组,以及对应的边放入栈t中,执行步骤21;
[0042]
步骤21:判断栈t是否为空,如果不成立,执行步骤22,否则,结束算法;
[0043]
步骤22:取出栈顶元素(a,b,u,v),其中a,b为边(u,v)对应的编码,执行步骤23;
[0044]
步骤23:判断a是否为1,如果成立,在g(d)中添加边u
←
v,执行步骤24,否则,执行步骤24;
[0045]
步骤24:判断b是否为1,如果成立,在g(d)中添加边u
→
v,执行步骤25,否则执行步骤25;
[0046]
步骤25:执行步骤21。
[0047]
与现有不同域内路由保护算法相比,本发明具有如下优点:
[0048]
1、本发明的域内路由保护方法中,在每个路由器只存储两个下一跳,其中一个为最优下一跳,另外一个为备份下一跳,相比于现有的路由保护方法,这样可以大大降低存储开销。2、本发明的域内路由保护方法可以应对网络中所有可能出现的单故障情形,故障保护率可以达到100%。除此之外,该方法不需要额外辅助机制的协助,更容易部署且支持增量部署。因此,本发明的域内路由保护方法可以为isp解决域内路由可用性提供一种有效的解决方案。
附图说明
[0049]
图1是本发明的基于转发图的域内路由保护方法流程示意图;
[0050]
图2是本发明的基于遗传算法构造转发图的算法流程示意图;
[0051]
图3是图2中部分算法流程的放大图一;
[0052]
图4是图2中部分算法流程的放大图二;
[0053]
图5是图2中部分算法流程的放大图三;
[0054]
图6是本发明实施例中网络拓扑结构g示意图;
[0055]
图7是图g以结点d为目的结点的反向最短路径树;
[0056]
图8是通过遗传算法生成的以结点d为目的结点的转发图;
[0057]
图9是不同域内路由保护算法在故障保护率方面进行仿真实验数值对比图;
[0058]
图10是不同域内路由保护算法在路径拉伸度方面进行仿真实验数值对比图
[0059]
其中,为了便于本领域技术人员更清楚地了解利用遗传算法根据反向最短路径树r(d)构造转发图g(d)的算法流程,我们将图2分割成图3至图5三幅附图。另外在图9和图10中,将图中列表“rpbfg”命名为本发明的域内路由保护算法。
具体实施方式
[0060]
为使本发明的目的、技术方案和优点更加清楚,以下结合附图对本发明作进一步地详细说明。
[0061]
如附图1至8所示,基于上述发明内容记载的算法流程,下面详细说明本实施例的各个步骤,为了便于说明,这里我们将种群规模仅设置为4,进化轮数仅设置为2,因为,对于每个目的结点算法的执行过程是相似的,所以下面介绍以目的结点为d的算法步骤:
[0062]
步骤1:利用迪杰斯特拉算法构造目的结点为d的反向最短路径树r(d),如图7所示;
[0063]
步骤2:设置遗传算法的参数,种群规模n=4、进化轮数m=2、变异概率p=0.03、交叉概率q=0.7;
[0064]
步骤3:初始化列表c,此时c为空;
[0065]
步骤4:将图中所有的边放入栈t,t=[(d,a),(d,b),(a,b),(a,c),(c,f),(f,g),(g,e),(g,h),(h,e),(e,b)];
[0066]
步骤5:此时栈t不为空,执行步骤6;
[0067]
步骤6:取出栈顶边(e,b),此时t=[(d,a),(d,b),(a,b),(a,c),(c,f),(f,g),(g,e),(g,h),(h,e)];
[0068]
步骤7:(e,b)在r(d)中,执行步骤8;
[0069]
步骤8:在r(d)中,e不是b的父结点,将01添加到c中,此时c=[01];
[0070]
步骤5:此时栈t不为空,执行步骤6;
[0071]
步骤6:取出栈顶边(h,e),此时t=[(d,a),(d,b),(a,b),(a,c),(c,f),(f,g),(g,e),(g,h)]
[0072]
步骤7:(h,e)在r(d)中,执行步骤8;
[0073]
步骤8:在r(d)中,h不是e的父结点,将01添加到c中,此时c=[0101];
[0074]
步骤5:此时栈t不为空,执行步骤6;
[0075]
步骤6:取出栈顶边(g,h),此时t=[(d,a),(d,b),(a,b),(a,c),(c,f),(f,g),(g,e)]
[0076]
步骤7:(g,h)不在r(d)中,执行步骤9;
[0077]
步骤9:将00添加到c中,此时c=[010100]
[0078]
步骤5:此时栈t不为空,执行步骤6;
[0079]
步骤6:取出栈顶元素(g,e),此时t=[(d,a),(d,b),(a,b),(a,c),(c,f),(f,g)]
[0080]
步骤7:(g,e)在r(d)中,执行步骤8;
[0081]
步骤8:在r(d)中,g不是e的父结点,将01添加到c中,此时c=[01010001];
[0082]
步骤5:此时栈t不为空,执行步骤6;
[0083]
步骤6:取出栈顶元素(f,g),此时t=[(d,a),(d,b),(a,b),(a,c),(c,f)]
[0084]
步骤7:(f,g)不在r(d)中,执行步骤9;
[0085]
步骤9:将00添加到c中,此时c=[0101000100];
[0086]
步骤5:此时栈t不为空,执行步骤6;
[0087]
步骤6:取出栈顶元素(c,f),此时t=[(d,a),(d,b),(a,b),(a,c)]
[0088]
步骤7:(c,f)在r(d)中,执行步骤8;
[0089]
步骤8:在r(d)中,c是f的父结点,将10添加到c中,此时c=[010100010010];
[0090]
步骤5:此时栈t不为空,执行步骤6;
[0091]
步骤6:取出栈顶元素(a,c),此时t=[(d,a),(d,b),(a,b)]
[0092]
步骤7:(a,c)在r(d)中,执行步骤8;
[0093]
步骤8:在r(d)中,a是c的父结点,将10添加到c中,此时c=[01010001001010];
[0094]
步骤5:此时栈t不为空,执行步骤6;
[0095]
步骤6:取出栈顶元素(a,b),此时t=[(d,a),(d,b)]
[0096]
步骤7:(a,b)不在r(d)中,执行步骤9;
[0097]
步骤9:将00添加到c中,此时c=[0101000100101000];
[0098]
步骤5:此时栈t不为空,执行步骤6;
[0099]
步骤6:取出栈顶元素(d,b),此时t=[(d,a)]
[0100]
步骤7:(d,b)在r(d)中,执行步骤8;
[0101]
步骤8:在r(d)中,d是b的父结点,将10添加到c中,此时c=[010100010010100010];步骤5:此时栈t不为空,执行步骤6;
[0102]
步骤6:取出栈顶元素(d,a),此时t=[]
[0103]
步骤7:(d,a)在r(d)中,执行步骤8;
[0104]
步骤8:在r(d)中,d是a的父结点,将10添加到c中,此时c=[01010001001010001010];步骤5:此时栈t为空,执行步骤11;
[0105]
步骤11:将c复制4份,得到c1=c2=c3=c4=[01010001001010001010];
[0106]
步骤12:初始化变量i=1;
[0107]
步骤13:此时i小于等于m,执行步骤14;
[0108]
步骤14:为每个染色体分别计算适应度,得到f1=f2=f3=f4=(0,+∞);
[0109]
步骤15:保留排序后的前一半染色体,剩余c1,c2;
[0110]
步骤16:通过变异交叉,生成两个新的染色体c3=[01011001111010111010],c4=[01011001111010100010]
[0111]
步骤17:i=i+1;
[0112]
步骤13:此时i=2,i小于等于m,执行步骤14;
[0113]
步骤14:为每个染色体分别计算适应度,得到f1=f2=(0,+∞),f3=(0.625,s3),f4=(0.375,s4);
[0114]
步骤15:根据适应度将染色体排序,保留前面一半的染色体,留下c3,c4;
[0115]
步骤16:通过变异交叉,生成两个新的染色体c1=[01011011111110111010],c2=01011011111110111010];
[0116]
步骤17:i=i+1;
[0117]
步骤13:此时i=3,i大于m,执行步骤19;
[0118]
步骤19:初始化转发图g(d),其中只保留网络拓扑图中的所有点;
[0119]
步骤20:计算各个染色体的适应度f1=(1,s1),f2=(1,s2),f3=((0.625,s3),f4=(0.375,s4),从所有的染色体中挑出适应度最好的染色体这里假设s1《s2,所以
[0120]
步骤21:将染色体中的编码两个一组,以及对应的边放入栈t中,此时t=[(10da),(10db),(11ab),(10ac),(11cf),(11fg),(11ge),(10gh),(01he),(01eb)];
[0121]
步骤22:栈t不为空,执行步骤23;
[0122]
步骤23:取出栈顶元素(01eb),其中01为边(e,b)对应的编码;
[0123]
步骤24:在g(d)中添加边b
←
e;
[0124]
步骤25:在g(d)中添加边b
←
e;
[0125]
步骤22:栈t不为空,执行步骤23;
[0126]
步骤23:取出栈顶元素(01he);
[0127]
步骤24:在g(d)中添加边e
←
h;
[0128]
步骤25:在g(d)中添加边e
←
h;
[0129]
步骤22:栈t不为空,执行步骤23;
[0130]
步骤23:取出栈顶元素(10gh);
[0131]
步骤24:在g(d)中添加边g
←
h;
[0132]
步骤25:在g(d)中添加边g
←
h;
[0133]
步骤22:栈t不为空,执行步骤23;
[0134]
步骤23:取出栈顶元素(11ge);
[0135]
步骤24:在g(d)中添加边
[0136]
步骤25:在g(d)中添加边
[0137]
步骤22:栈t不为空,执行步骤23;
[0138]
步骤23:取出栈顶元素;
[0139]
步骤24:在g(d)中添加边
[0140]
步骤25:在g(d)中添加边
[0141]
步骤22:栈t不为空,执行步骤23;
[0142]
步骤23:取出栈顶元素(11cf);
[0143]
步骤24:在g(d)中添加边
[0144]
步骤25:在g(d)中添加边
[0145]
步骤22:栈t不为空,执行步骤23;
[0146]
步骤23:取出栈顶元素(10ac);
[0147]
步骤24:在g(d)中添加边a
←
c;
[0148]
步骤25:在g(d)中添加边a
←
c;
[0149]
步骤22:栈t不为空,执行步骤23;
[0150]
步骤23:取出栈顶元素(11ab);
[0151]
步骤24:在g(d)中添加边
[0152]
步骤25:在g(d)中添加边
[0153]
步骤22:栈t不为空,执行步骤23;
[0154]
步骤23:取出栈顶元素(10db);
[0155]
步骤24:在g(d)中添加边d
←
b;
[0156]
步骤25:在g(d)中添加边d
←
b;
[0157]
步骤22:栈t不为空,执行步骤23;
[0158]
步骤23:取出栈顶元素(10da);
[0159]
步骤24:在g(d)中添加边d
←
a;
[0160]
步骤25:在g(d)中添加边d
←
a;
[0161]
步骤22:栈t为空,执行步骤26;
[0162]
步骤26:将g(d)中除d外的所有结点都放入栈t中,此时t=[a,b,c,e,f,g,h],如附图8所示;
[0163]
步骤27:栈t不为空,执行步骤28;
[0164]
步骤28:取出栈顶元素h;
[0165]
步骤29:h的邻接结点是e,g;
[0166]
步骤30:将h的最优下一跳设置为e,备份下一跳设置为g;
[0167]
步骤27:栈t不为空,执行步骤28;
[0168]
步骤28:取出栈顶元素g;
[0169]
步骤29:g的邻接结点是e,f;
[0170]
步骤30:将g的最优下一跳设置为e,备份下一跳设置为f;
[0171]
步骤27:栈t不为空,执行步骤28;
[0172]
步骤28:取出栈顶元素f;
[0173]
步骤29:f的邻接结点是c,g;
[0174]
步骤30:将f的最优下一跳设置为c,备份下一跳设置为g;
[0175]
步骤27:栈t不为空,执行步骤28;
[0176]
步骤28:取出栈顶元素f;
[0177]
步骤29:f的邻接结点是c,g;
[0178]
步骤30:将f的最优下一跳设置为c,备份下一跳设置为g;
[0179]
步骤27:栈t不为空,执行步骤28;
[0180]
步骤28:取出栈顶元素e;
[0181]
步骤29:e的邻接结点是b,g;
[0182]
步骤30:将e的最优下一跳设置为b,备份下一跳设置为g;
[0183]
步骤27:栈t不为空,执行步骤28;
[0184]
步骤28:取出栈顶元素c;
[0185]
步骤29:c的邻接结点是a,f;
[0186]
步骤30:将c的最优下一跳设置为a,备份下一跳设置为f;
[0187]
步骤27:栈t不为空,执行步骤28;
[0188]
步骤28:取出栈顶元素b;
[0189]
步骤29:b的邻接结点是d,a;
[0190]
步骤30:将b的最优下一跳设置为d,备份下一跳设置为a;
[0191]
步骤27:栈t不为空,执行步骤28;
[0192]
步骤28:取出栈顶元素a;
[0193]
步骤29:a的邻接结点是d,b;
[0194]
步骤30:将a的最优下一跳设置为d,备份下一跳设置为b;
[0195]
我们将本发明的算法叫rpbfg,与npc,u-turn,mara-ma和mara-spe分别在11个真实网络拓扑上进行对比,故障保护率如附图9的柱状图所示,rpbfg与另外四个算法分别对比的路径拉伸度如附图10所示。通过仿真实验,我们可以看出,在故障保护率方面本发明达到了100%的故障保护率,在路径拉伸度方面本方案都表现的更好,在应对单链路故障时,本发明显然具有强更大的应对能力,可以应对绝大部分单链路故障带来的影响。
[0196]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1