一种基于SDN的面向分布式机器学习的流量调度方法
一种基于sdn的面向分布式机器学习的流量调度方法
技术领域
1.本发明涉及人工智能技术领域,特别是一种基于sdn的面向分布式机器学习的流量调度方法。
背景技术:
2.近年来,以机器学习为基础的人工智能技术全面爆发,在计算机视觉、语音识别以及无人驾驶等领域取得巨大成功。随着互联网数据量呈现指数级的增长,以及训练模型的日益复杂,使得模型精度得到显著提高,与此同时也大大增加了机器学习模型训练所需的时间和资源,使得依靠单个gpu,无法在短时间范围内将模型训练至收敛。因此,机器学习训练的分布式化实现已成为解决大规模数据场景的重要手段。
3.分布式机器学习通过将计算分散到多个计算节点上,以减少每个计算节点的计算量,节省训练时间,这些计算节点之间需要相互通信来同步模型参数。通常计算节点数量的增加意味着计算时间的减少,但与此同时,参数同步所需的通信时间也会增加。因此,解决计算和通信时间的不平衡问题,以降低分布式系统的通信计算时间比成,为一个关键问题。
4.软件定义网络(sdn)将数据的转发和控制进行分离,使得每个交换设备仅仅包含转发部分,而控制部分集中交给控制器做逻辑上统一管理。sdn这种集中控制特性,在网络性能优化、网络管理以及接入新的网络功能等方面都有着重要意义。
5.目前已有大量的研究来缓解通信瓶颈,如改进分布式机器学习算法或者压缩通信量、减少通信次数等。然而这些解决方案都是在应用层上对任务进行粗粒度的调度,以达到提升通信效率的目的,对于计算机节点的个体差异和链路带宽的利用率不能做到很好的均衡。
技术实现要素:
6.本发明的目的在于提供一种在减少平均流完成时间的同时,提升链路带宽的利用率,实现负载平衡的面向分布式机器学习的流量调度方法。
7.实现本发明能够目的的技术解决方案为:一种基于sdn的面向分布式机器学习的流量调度方法,包括以下步骤:
8.步骤1、边缘层交换机接收并检测数据流,根据数据流是否具有先验知识,选择不同的优先级算法;
9.步骤2、基于多级反馈队列,建立优先级的离散化框架;
10.步骤3、将流经相同源交换机、目的交换机以及具有相似优先级的数据流进行聚合,得到聚合流f
s,d
={f1,f2,...,fn};
11.步骤4、使用改进的果蝇优化调度算法,以平均负载均衡程度为目标,获得聚合流的最优调度路径;
12.步骤5、由sdn控制器根据最优调度路径,下发流量表给sdn交换机,由交换机执行对应的路由策略,实现流量调度。
13.进一步地,步骤1所述的边缘层交换机接收并检测数据流,根据数据流是否具有先验知识,选择不同的优先级算法,具体如下:
14.边缘层交换机接收并检测数据流,根据数据流是否具有先验知识,即已知数据流的截止时限,选择不同的优先级算法:
15.若已知数据流的截止时限,则使用基于最早截止最短剩余时间优先的优先级算法,确定数据流的优先级;
16.若未知数据流的截止时限,则使用基于最少获得服务优先级算法,确定数据流的优先级。
17.进一步地,所述的基于最短截止最早剩余时间优先的优先级算法,公式如下:
[0018][0019]
其中,p(fn)表示数据流fn的优先级,d(fn)、r(fn)和d(fn)表示数据流的截止时限、松弛时间和带宽需求,其中松弛时间r(fn)=d(fn)-period,period表示通过sdn控制器获取到的从数据流发出时刻到当前时刻的时间间隔,d(fn)=v(fn)
×
8/(c
×
1000)。其中,v(fn)表示数据流fn的传输速率,c表示链路容量。
[0020]
进一步地,步骤2所述的基于多级反馈队列,建立优先级的离散化框架,具体如下:
[0021]
维护k个优先级队列(q1,q2,...,qk),用四个生命周期事件期间采取的行动来决定数据流的优先级:
[0022]
到达:如果有可用资源时,新数据流启动时进入最高优先级队列q1;
[0023]
活动:当数据流的优先级超过队列阈值时,数据流将从qi降级到q
i-1
;
[0024]
饥饿:如果数据流被抢占时间过长,重置数据流的优先级;
[0025]
完成:数据流完成后将数据流从当前队列中删除。
[0026]
进一步地,步骤3所述的将流经相同源交换机、目的交换机以及具有相似优先级的数据流进行聚合,得到聚合流f
s,d
={f1,f2,...,fn},具体如下:
[0027]
步骤3.1、初始化集合f
s,d
=φ;
[0028]
步骤3.2、通过检测每条数据流所包含信息中的源ip地址和目的ip地址,判断其是否同源同宿;
[0029]
步骤3.3、将同源同宿的数据流进行进一步分组,将具有相似优先级的数据流进行聚合,得到聚合流,放入集合f
s,d
={f1,f2,...,fn}中。
[0030]
进一步地,步骤4所述的使用改进的果蝇优化调度算法,以平均负载均衡程度为目标,获得聚合流的最优调度路径,具体如下:
[0031]
步骤4.1、初始化聚合流的组数s
p
,以及最大迭代次数maxgen;
[0032]
步骤4.2、利用k-最短路径算法求出源与目的地之间的前k条路径,作为待调度聚合流的备选路径集p
′
s,d
={p
′1,p
′2,...,p
′k};
[0033]
步骤4.3、随机初始化聚合流的分配矩阵;
[0034]
步骤4.4、随机更新聚合流中n个个体的纵坐标;
[0035]
步骤4.5、对于每一组聚合流,计算聚合流分配路径的平均负载均衡程度;
[0036]
步骤4.6、找出最优的平均负载均衡程度,并保留最优分配策略;
[0037]
步骤4.7、循环迭代步骤4.4-步骤4.6,直至达到最大迭代次数。
[0038]
进一步地,步骤4.3所述的随机初始化聚合流的分配矩阵,公式为:
[0039][0040]
其中m表示聚合流的组数,n表示每组聚合流中流的数目,矩阵中的值k
mn
表示聚合流m中为第n条数据流分配的路径序号,每一横行都表示聚合流的一组可行解。
[0041]
进一步地,步骤4.4所述的随机更新聚合流中n个个体的纵坐标,公式为:
[0042][0043]
其中表示第g次迭代时第m个聚合流中的第i条数据流选择的路径序号,random()为取值范围为[0.0,1.0)的随机数发生器,k表示备选路径集的路径个数。
[0044]
进一步地,步骤4.5中所述的计算聚合流分配路径的平均负载均衡程度,公式为:
[0045][0046]
其中u
ji
表示第j条分配路径中链路i的链路带宽利用率,tj表示第j条分配路径的链路数量,表示聚合流j条分配路径的平均链路带宽利用率,即
[0047]
进一步地,步骤4.6所述的找出最优的平均负载均衡程度,并保留最优分配策略,具体如下:
[0048]
找出最优的平均负载均衡程度best_b=min(albn),并保留最优分配策略k
best
=albn.index(best_b),即保留best_b在分配矩阵k所在的行
[0049]
本发明与现有技术相比,其显著优点在于:(1)本发明针对分布式学习场景下通信传输庞大的场景,通过在网络层对数据流在空间和时间两个维度实现基于sdn的优先级调度方法,在实现最小化流完成时间的同时,提高了带宽的利用率,实现了负载均衡;(2)使用改进的果蝇优化算法统一调度数据流经源交换机、目的交换机以及具有优先级的聚合流,提高了带宽的利用率和平均吞吐量,实现了负载平衡。
附图说明
[0050]
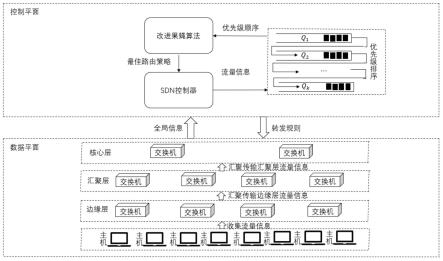
图1是本发明一种基于sdn的面向分布式机器学习的流量调度方法的整体框架图。
[0051]
图2是本发明一种基于sdn的面向分布式机器学习的流量调度方法的流程示意图。
[0052]
图3是本发明中的优先级离散化的状态转移的流程示意图。
[0053]
图4是本发明中的改进果蝇算法的流程示意图。
[0054]
图5是本发明实施例中数据流传输时间的累积分布曲线图。
[0055]
图6是本发明实施例中的链路带宽利用率的累积分布曲线图。
[0056]
具体实施方法
[0057]
下面结合附图和具体实施例,对本发明做进一步的详细说明。
[0058]
结合图1、图2,本发明一种基于sdn的面向分布式机器学习的流量调度方法,包括以下步骤:
[0059]
步骤1、边缘层交换机接收并检测数据流,根据数据流是否具有先验知识,选择不同的优先级算法;
[0060]
步骤2、基于多级反馈队列,建立优先级的离散化框架;
[0061]
步骤3、将流经相同源交换机、目的交换机以及具有相似优先级的数据流进行聚合,得到聚合流f
s,d
={f1,f2,...,fn};
[0062]
步骤4、使用改进的果蝇优化调度算法,以平均负载均衡程度为目标,获得聚合流的最优调度路径;
[0063]
步骤5、由sdn控制器根据最优调度路径,下发流量表给sdn交换机,由交换机执行对应的路由策略,实现流量调度。
[0064]
进一步地,步骤1所述的边缘层交换机接收并检测数据流,根据数据流是否具有先验知识,选择不同的优先级算法,具体如下:
[0065]
边缘层交换机接收并检测数据流,根据数据流是否具有先验知识,即已知数据流的截止时限,选择不同的优先级算法:
[0066]
若已知数据流的截止时限,则使用基于最早截止最短剩余时间优先的优先级算法,确定数据流的优先级;
[0067]
若未知数据流的截止时限,则使用基于最少获得服务优先级算法,确定数据流的优先级。
[0068]
进一步地,所述的基于最短截止最早剩余时间优先的优先级算法,公式如下:
[0069][0070]
其中,p(fn)表示数据流fn的优先级,d(fn)、r(fn)和d(fn)表示数据流的截止时限、松弛时间和带宽需求,其中松弛时间r(fn)=d(fn)-period,period表示通过sdn控制器获取到的从数据流发出时刻到当前时刻的时间间隔,d(fn)=v(fn)
×
8/(c
×
1000)。其中,v(fn)表示数据流fn的传输速率,c表示链路容量。
[0071]
进一步地,步骤2所述的基于多级反馈队列,建立优先级的离散化框架,结合图3,具体如下:
[0072]
维护k个优先级队列(q1,q2,...,qk),用四个生命周期事件期间采取的行动来决定数据流的优先级:
[0073]
到达:如果有可用资源时,新数据流启动时进入最高优先级队列q1;
[0074]
活动:当数据流的优先级超过队列阈值时,数据流将从qi降级到q
i-1
;
[0075]
饥饿:如果数据流被抢占时间过长,重置数据流的优先级;
[0076]
完成:数据流完成后将数据流从当前队列中删除。
[0077]
进一步地,步骤3所述的将流经相同源交换机、目的交换机以及具有相似优先级的数据流进行聚合,得到聚合流f
s,d
={f1,f2,...,fn},具体如下:
[0078]
步骤3.1、初始化集合f
s,d
=φ;
[0079]
步骤3.2、通过检测每条数据流所包含信息中的源ip地址和目的ip地址,判断其是否同源同宿;
[0080]
步骤3.3、将同源同宿的数据流进行进一步分组,将具有相似优先级的数据流进行聚合,得到聚合流,放入集合f
s,d
={f1,f2,...,fn}中。
[0081]
进一步地,步骤4所述的使用改进的果蝇优化调度算法,以平均负载均衡程度为目标,获得聚合流的最优调度路径,结合图4,具体如下:
[0082]
步骤4.1、初始化聚合流的组数s
p
,以及最大迭代次数maxgen;
[0083]
步骤4.2、利用k-最短路径算法求出源与目的地之间的前k条路径,作为待调度聚合流的备选路径集ps′
,d
={p1′
,p2′
,...,pk′
};
[0084]
步骤4.3、随机初始化聚合流的分配矩阵;
[0085]
步骤4.4、随机更新聚合流中n个个体的纵坐标;
[0086]
步骤4.5、对于每一组聚合流,计算聚合流分配路径的平均负载均衡程度;
[0087]
步骤4.6、找出最优的平均负载均衡程度,并保留最优分配策略;
[0088]
步骤4.7、循环迭代步骤4.4-步骤4.6,直至达到最大迭代次数。
[0089]
进一步地,步骤4.3所述的随机初始化聚合流的分配矩阵,公式为:
[0090][0091]
其中m表示聚合流的组数,n表示每组聚合流中流的数目,矩阵中的值k
mn
表示聚合流m中为第n条数据流分配的路径序号,每一横行都表示聚合流的一组可行解。
[0092]
进一步地,步骤4.4所述的随机更新聚合流中n个个体的纵坐标,公式为:
[0093][0094]
其中表示第g次迭代时第m个聚合流中的第i条数据流选择的路径序号,random()为取值范围为[0.0,1.0)的随机数发生器,k表示备选路径集的路径个数。
[0095]
进一步地,步骤4.5中所述的计算聚合流分配路径的平均负载均衡程度,公式为:
[0096][0097]
其中u
ji
表示第j条分配路径中链路i的链路带宽利用率,tj表示第j条分配路径的链路数量,表示聚合流j条分配路径的平均链路带宽利用率,即
[0098]
进一步地,步骤4.6所述的找出最优的平均负载均衡程度,并保留最优分配策略,具体如下:
[0099]
找出最优的平均负载均衡程度best_b=min(albn),并保留最优分配策略k
best
=
albn.index(best_b),即保留best_b在分配矩阵k所在的行。
[0100]
实施例1
[0101]
本实施例采用ryu控制器作为开源的sdn控制器,并通过mininet仿真平台对整个网络进行模拟。整个网络由一个sdn控制器、20个sdn交换机组成。
[0102]
结合图1、图2,本实施例提供的基于sdn的面向分布式机器学习的流量调度方法,包括以下步骤:
[0103]
步骤1、边缘层交换机接收并检测数据流,根据数据流是否具有先验知识,选择不同的优先级算法,具体如下:
[0104]
边缘层交换机接收并检测数据流,根据数据流是否具有先验知识,即已知数据流的截止时限,选择不同的优先级算法:
[0105]
若已知数据流的截止时限,则使用基于最早截止最短剩余时间优先的优先级算法,确定数据流的优先级;
[0106]
若未知数据流的截止时限,则使用基于最少获得服务优先级算法,确定数据流的优先级。
[0107]
进一步地,所述的基于最短截止最早剩余时间优先的优先级算法,公式如下:
[0108][0109]
其中,p(fn)表示数据流fn的优先级,d(fn)、r(fn)和d(fn)表示数据流的截止时限、松弛时间和带宽需求,其中松弛时间r(fn)=d(fn)-period,period表示通过sdn控制器获取到的从数据流发出时刻到当前时刻的时间间隔,d(fn)=v(fn)
×
8/(c
×
1000)。其中,v(fn)表示数据流fn的传输速率,c表示链路容量。
[0110]
步骤2、为了避免大量抢占所导致的大量通信时间,基于传统的多级反馈队列,建立优先级离散化框架;
[0111]
进一步地,维护k个优先级队列(q1,q2,...,qk),用四个生命周期事件期间采取的行动来决定数据流的优先级,其状态转移图如图3所示;
[0112]
到达:如果有可用资源时,新数据流启动时进入最高优先级队列q1;
[0113]
活动:当数据流的优先级超过队列阈值时,数据流将从qi降级到q
i-1
;
[0114]
饥饿:如果数据流被抢占时间过长,将重置数据流的优先级;
[0115]
完成:数据流完成后将数据流从当前队列中删除。
[0116]
步骤3、将流经相同源交换机、目的交换机以及具有相似优先级的数据流进行聚合,得到聚合流f
s,d
={f1,f2,...,fn},具体如下:
[0117]
步骤3.1、初始化集合f
s,d
=φ;
[0118]
步骤3.2、通过检测每条数据流所包含信息中的源ip地址和目的ip地址判断其是否同源同宿;
[0119]
步骤3.3、将同源同宿的数据流进行进一步分组,将具有相似优先级的数据流进行聚合,得到聚合流,放入集合f
s,d
={f1,f2,...,fn}中。
[0120]
步骤4、使用改进的果蝇优化调度算法,以平均负载均衡程度为目标,获得聚合流的最优调度路径,结合图4,具体如下:
[0121]
步骤4.1、初始化聚合流的组数s
p
=10以及最大迭代次数maxgen=50;
[0122]
步骤4.2、利用k-最短路径算法求出源与目的地之间的前5条路径,作为待调度聚合流的备选路径集p
′
s,d
={p
′1,p
′2,...,p
′k};
[0123]
步骤4.3、随机初始化聚合流的分配矩阵,公式为:
[0124][0125]
其中m表示聚合流的组数,n表示每组聚合流中流的数目,矩阵中的值k
mn
表示聚合流m中为第n条数据流分配的路径序号,每一横行都表示聚合流的一组可行解;
[0126]
步骤4.4、随机更新聚合流中n个个体的纵坐标,公式为:
[0127][0128]
其中表示第g次迭代时第m个聚合流中的第i条数据流选择的路径序号,random()为取值范围为[0.0,1.0)的随机数发生器,k表示备选路径集的路径个数;
[0129]
步骤4.5、对于每一组聚合流,计算聚合流分配路径的平均负载均衡程度,公式为:
[0130][0131]
其中u
ji
表示第j条分配路径中链路i的链路带宽利用率,tj表示第j条分配路径的链路数量,表示聚合流j条分配路径的平均链路带宽利用率,即
[0132]
步骤4.6、找出最优的平均负载均衡程度,并保留最优分配策略,具体如下:
[0133]
找出最优的平均负载均衡程度best_b=min(albn),并保留最优分配策略k
best
=albn.index(best_b),即保留best_b在分配矩阵k所在的行;
[0134]
步骤4.7、循环迭代步骤4.4-步骤4.6,直至达到最大迭代次数。
[0135]
步骤5、由sdn控制器根据最优调度路径,下发流量表给sdn交换机,由交换机执行对应的路由策略,实现流量调度。
[0136]
根据本发明在实施例中的执行流程,设置使用ecmp算法作为对比实验,ecmp算法是目前负载均衡程度较高的调度方法。本实施例的调度结果如图5和图6所示。图5表示本实施例流传输时间的累积分布函数曲线,即小于等于当前传输时间的数据流占整个网络总数据流的比例,可以观察到本实施例的平均流完成时间较小。图6表示本实施例链路带宽利用率的累积分布函数,即小于等于当前链路带宽利用率的链路数目占整个网络总链路数目的比例,可以观察到本实施例平均带宽利用率较高。由图5、图6,可以看出本发明在本实施例中效率良好,在最小化流完成时间的同时,带宽利用率有较大提升。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1