一种EH-NOMA系统基于LSTM-DDPG的有源RIS控制方法
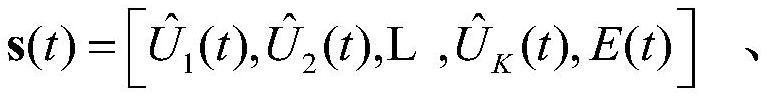
本发明属于深度强化学习与通信,尤其涉及一种eh-noma系统基于lstm-ddpg的有源ris控制方法。
背景技术:
1、为了能够向无线通信中的通信双方提供额外的级联信道,智能反射表面(ris)能够显著提高通信系统的性能。ris是一个由大量无源元件组成的平面阵列,通过ris控制器对这些元件的振幅和相位进行合理的设计,可以实现对电磁波的有效反射,从而有效提高通信质量。然而,针对ris的已有研究中往往是在假设系统中直接链路质量较差或直接链路被障碍物阻断的场景。因为在这些场景下,ris级联信道中的噪声是可以忽略不计的。相反,当系统中的直接链路质量不是很差时,传统ris将由于信道的乘性衰落效益而无法实现有效的性能增益。
2、为了解决传统ris的这一应用瓶颈,有源ris的概念被提出。与传统ris不同,有源ris的每个元件处均配置了一个功率放大器,可以实现对反射信号的放大。通过引入功率放大器,对反射信号放大可以有效削弱乘性衰落效益。
3、目前有源ris存在以下技术问题:
4、1.有源ris仅仅考虑对反射信号进行放大,而没有考虑能量资源大量消耗的问题。
5、2.已有的有源ris相关文献没有考虑无线通信系统中的频谱资源紧缺问题。
6、3、已有针对ris的相位偏移矩阵进行设计的相关文献中,几乎均假设能够准确获知系统中的全局信道状态信息(csi),这在实际应用中很难实现。
7、4、目前已有文献未对有源ris辅助下的eh-noma系统同时进行放大矩阵和相位偏移矩阵设计。
8、导致原因如下:
9、1、在有源ris中,为了对反射信号进行功率放大,需要消耗的能量将远远大于无源ris。这与ris的低能耗、低成本的绿色设计理念相违背。另外,在实际的应用场景中,ris往往安装在高层建筑的表面,很难为每个ris元件提供稳定可靠的能量供应。
10、2、频谱资源一直是无线通信领域最为珍贵的资源之一,随着无线通信设备数量的急剧攀升,现有的频谱资源已经很难满足日益增长的用户通信需求。因此,急需提高各种无线通信系统中的频谱资源利用率。在已有的有源ris相关文献中还没有考虑用户频谱资源紧缺问题。
11、3、在对ris进行设计时,csi是重要的依据。为了获取准确的csi,需要ris具备估计csi,即准确处理、分析导频信号的能力。而在有源ris结构简单,没有处理和分析导频信号的能力。
12、综上,如何在无法获知准确csi的前提下,进行有源ris的放大矩阵和相位偏移矩阵的设计,是亟需解决的问题。
技术实现思路
1、为了解决在有源ris辅助下的eh-noma无线通信系统中ris的放大矩阵及相位偏移矩阵的设计问题,本发明提出了一种eh-noma系统基于lstm-ddpg的有源ris控制方法,具体技术方案如下:
2、一种eh-noma系统基于lstm-ddpg的有源ris控制方法,包括以下步骤:
3、s1、针对有源ris系统建立基于能量收集和非正交多址的有源ris通信系统模型;
4、s2、建立以ris控制器为智能体的马尔科夫过程,其环境状态动作奖励其中环境状态包括由lstm算法估计获得的所有用户的通信状态以及当前ris电池中剩余的电量;所述动作为功率放大矩阵和相位偏移矩阵的对角元素和θm,其中0≤θm<2π,m∈m;所述奖励中r是奖励系数,是个正的常数;
5、s3、更新critic主网络和actor主网络的网络参数。
6、具体地说,步骤s1中的通信系统模型包括作为智能体的ris控制器、基站、k个用户端,所述智能体接收基站信息并发送信号至用户端,所述用户端获取基站以及ris转发来的混合信息;所述智能体集中安装在高层建筑表面,智能体中每个元件处均设置有放大设备,对接受到的信号进行放大,所述系统还包括用于给智能体功能的电源。
7、具体地说,步骤s2中环境状态步骤如下:
8、sa21、确定有源ris通信系统模型,首先确定用户k接收的信号;所有用户采用noma模式共享一个频谱信道资源,假设所有用户在不同时隙上的通信状态是动态变化的,系统中所有用户的通信状态是动态变化的,每个用户的通信概率为独立同分布的,均服从“random walk”模型,用户k接受到的混合信号为:
9、
10、其中uk(t)和pk为t时刻用户k的通信状态和基站对用户k的功率;hs,k为ris与用户k之间的信道,hk(t)=hb,k(t)+hs,k(t)pθhb,s(t)为基站到ris,ris到用户k间的等效级联信道,p和θ为需要设计的ris功率放大矩阵以及相位偏移矩阵,z表示为ris处的噪声,nk表示为用户k处的噪声;xk(t)为发送给用户k的信号;uj(t)为用户j是否通信的二进制标识,当其通信时uj(t)=1,否则uj(t)=0;hj(t)为用户j与基站之间的等效级联信道,pj(t)为基站对其的发送功率,xj(t)表示为用户j的信号;
11、在每个用户处执行连续干扰消除技术;执行连续干扰消除后,用户k接受到的干扰表示为:
12、
13、其中,χjk(t)为二进制标识,χjk(t)=1表示用户j的信号强度比用户k的要强,否则χjk(t)=0,二进制标识dj(t)用于表征j用户是否被解码成功,当dj(t)=1标识用户j已经被成功解码,否则dj(t)=0;
14、用户k获得的速率表示为:
15、
16、其中gk=uk(t)|hk(t)|2pk(t)表示为用户k的自身信号强度,表示为ris处噪声的功率,δ2表示为用户k处的噪声的功率;
17、sa22、基于lstm的用户通信状态估计算法,预测出下一时刻用户的通信情况。
18、具体地说,经过能量收集eh获得的能量存储在电池中,令t时刻之初,电池中的能量为e(t),则在下一时刻,其电池中的能量为:
19、e(t+1)=min{e(t)+eh(t)-ec(t),emax}
20、其中eh(t)=eh(t)η和分别为t时刻ris收集的能量和消耗的能量,η为能量转化因子。
21、具体地说,步骤sa22具体为:
22、sa221、构建数据集;基于“random walk”模型生成了若干个时刻的用户通信概率数据,该数据集将按照设定比例分别用于lstm网络的训练和测试;
23、sa222、将所有数据进行分块;按照顺序分成若干组,每组数据后的1个数据为这组数据对应的真实预测结果;
24、sa223、搭建lstm网络模型;所述lstm网络模型包含两层lstm神经元,每个lstm神经元包含三个门,分别是遗忘门f(t),输入门d(t)和输出门oo(t);对应的相关函数表示为:
25、
26、
27、
28、lstm的输出为:其中
29、
30、
31、基于输出h(t),当前用户的预测通信概率表示为:
32、
33、sa224、对lstm网络模型进行训练;lstm算法中的网络为三层网络结构,即输入层,lstm层以及lstm输出层,其中lstm层以及lstm输出层的激励函数均为tanh函数,整个网络的优化器为rmsprop;
34、sa225、应用lstm网络模型;训练好的模型用未训练的用户通信状态数据集上进行评估。
35、具体地说,步骤s2中对动作的计算为:sb2、基于环境状态输出动作;即针对lstm算法的预测结果,利用深度强化学习drl算法-ddpg对ris的功率放大矩阵和相位偏移矩阵进行联合控制,输出对应的ris功率放大矩阵p和相位偏移矩阵θ,具体步骤如下:
36、sb21、智能体探索系统环境获得经验数据;在每个时隙t观察当前的环境状态s(t),并将其输入actor主网络,actor主网络输出对应的动作a(t),对输出的动作进行调整,调整的动作如下
37、
38、其中是不进行任何功率放大时ris消耗的能量,此时为ris消耗的能量;表示为主actor网络计算输出的功率,和分别表示为调整后的功率动作和相位偏移动作,θm(t)表示为主actor网络输出,l表示为最大放大系数;另外对动作进行加噪,即:
39、a(t)=μ(s(t)∣θμ(t))+no(t)
40、其中s(t)表示为当前时刻系统的状态,θμ(t)表示为当前时刻主actor网络的网络参数,μ(s(t)∣θμ(t))表示为基于网络参数θμ(t)的策略,no(t)是探索噪声,执行该调整和加噪后的动作与系统,智能体获得奖励r(t),系统环境进行下一个状态s(t+1),基于该次探索,获得一条经验数据将其存入缓存器d中。
41、具体地说,步骤s3步骤具体如下:
42、s31、从缓存器d中采样获得数据集ω,选择随机采样机制;
43、s32、通过最小化样本集损失函数更新critic主网络的网络参数;计算损失函数更新critic主网络的网络参数;通过反向传输td误差,计算critic主网络的损失函数如下:
44、
45、其中ω表示为训练样本的模,q(s(i),μ(s(i)|θμ)|θq(i))表示当前critic主网络在状态s(i),策略μ(s(i)|θμ)下的状态值函数,ω为该参数下对应的策略,q'(i)是目标状态值函数,是目标critic网络的输出,通过贝尔曼方程计算得到:q′(i)=r(i)+γq′(s(i+1),μ′(s(i+1)|θμ′(i))|θq′(i)),其中γ为折扣因子,r(i)为系统当前的奖励,q'(s(i+1),μ'(s(i+1)|θμ'(i))|θq'(i))为目标critic网络在状态s(i+1)、策略μ'下的状态值函数,θq'和θv'分别是目标critic网络和目标actor网络的网络参数;
46、通过最小化损失函数,critic主网络的网络参数更新如下:
47、
48、s33、通过梯度下降更新主actor网络参数;主actor网络根据以下的策略梯度进行更新:
49、
50、s34、软更新目标critic网络和目标actor网络;每隔c步需要对目标critic网络和目标actor网络进行软更新
51、θμ'(t)=τμθμ(t)+(1-τμ)θμ'(t),
52、θq'(t)=τqθq(t)+(1-τq)θq'(t)
53、s35、主actor网络和critic主网络进行tall回合的探索训练,将逐渐趋于收敛。
54、本发明的优点在于:
55、(1)本技术针对有源ris系统设计的一种基于能量收集(eh)和非正交多址(noma)的有源ris通信系统模型,有源ris利用eh实现能量供应,所有用户采用noma方式接入同一频谱资源与基站(bs)进行通信,从而可以提高频谱效率。
56、(2)本技术针对有源ris系统无法获知系统csi的问题,基于lstm的用户通信状态预测算法,并基于预测的通信状态结果进行有源ris的设计。
57、(3)针对eh-noma有源ris通信系统,利用深度强化学习(drl)算法对ris的放大矩阵和相位偏移矩阵进行联合设计,以进一步提高系统性能。
- 还没有人留言评论。精彩留言会获得点赞!