一种利用声源定位技术的音视频采集追踪方法及装置与流程
本申请涉及监控,具体涉及一种利用声源定位技术的音视频采集追踪方法以及利用声源定位技术的音视频采集追踪装置。
背景技术:
1、现有技术中,视频监控摄像机仅支持音频输入输出功能,由于监控用拾音器及话筒的局限性,仅能做到在视频图像上叠加音频,在智能化应用的今天,已不能满足音视频采集的智能化需求。本发明意在解决音视频单一采集数据的技术瓶颈,采用音频采集的声源定位技术,通过摄像机及拾音器的定向部署,将智能音频与摄像机智能采集相结合,通过几个拾音器拾取的音频情况,对音源的位置进行定位,并将定位的坐标或位置信息传输给可旋转摄像机,旋转摄像机根据拾音器提供的音源位置旋转至音源发生地,完成音视频图像定向采集;通过智能音频分析技术与摄像机智能分析技术,可完成异常事件定向采集功能。
2、因此,希望有一种技术方案来解决或至少减轻现有技术的上述不足。
技术实现思路
1、本发明的目的在于提供一种利用声源定位技术的音视频采集追踪方法来至少解决上述的一个技术问题。
2、本发明的一个方面,提供一种利用声源定位技术的音视频采集追踪方法,所述利用声源定位技术的音视频采集追踪方法包括:
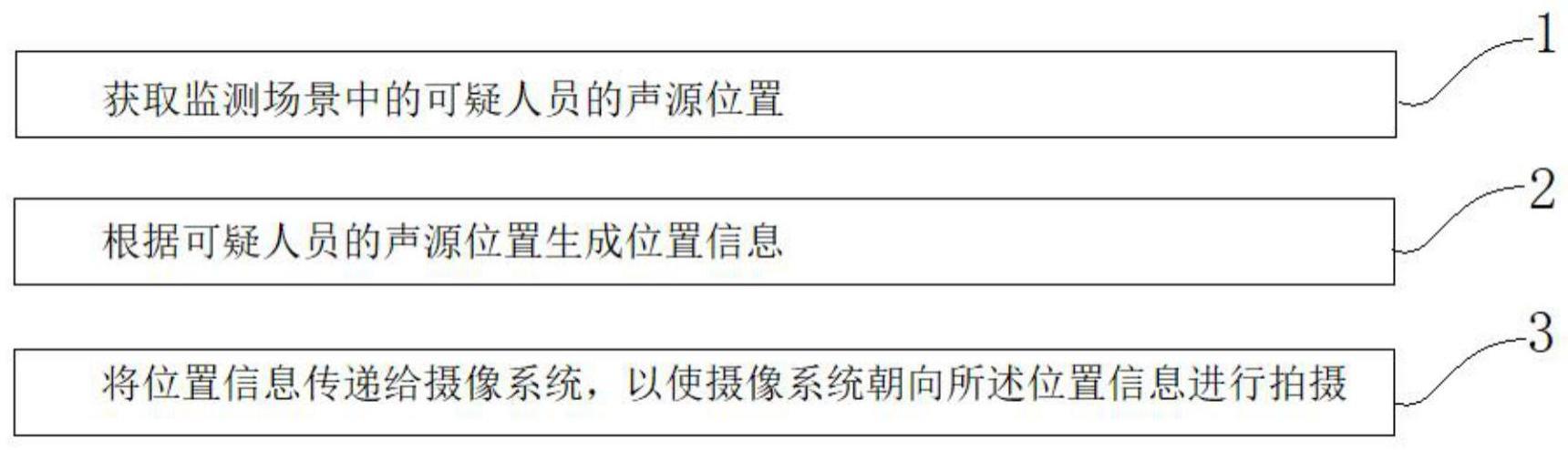
3、获取监测场景中的可疑人员的声源位置;
4、根据可疑人员的声源位置生成位置信息;
5、将位置信息传递给摄像系统,以使摄像系统朝向所述位置信息进行拍摄。
6、可选地,在所述获取可疑人员的声源位置之前,所述利用声源定位技术的音视频采集追踪方法进一步包括:
7、获取监测场景的阵列内声源位置数据。
8、可选地,所述获取监测场景的阵列内声源位置数据包括:
9、通过深层神经网络模型训练模拟出现场rir情况;
10、通过四个拾音器组成阵列,经过现场训练后可得到阵列内声源位置数据。
11、可选地,所述获取监测场景中的可疑人员的声源位置包括:
12、获取检测场景中的声纹信息;
13、获取预设数据库,所述预设数据库包括至少一个预设声纹信息;
14、判断所述声纹信息是否与一个预设声纹信息匹配,若是,则
15、获取该声纹信息的声源位置。
16、可选地,所述根据可疑人员的声源位置生成位置信息包括:
17、以获取声纹信息的位置为原点建立球坐标系;
18、提取所述声纹信息中的特征信息;
19、获取声学传播模型;
20、将所述特征信息输入至所述声学传播模型,从而获取声源位置在所述球坐标系中的位置信息。
21、可选地,所述利用声源定位技术的音视频采集追踪方法进一步包括:
22、获取摄像系统朝向所述位置信息进行拍摄所获取的图像信息;
23、识别所述图像信息,从而获取图像信息中的人脸信息;
24、获取人脸数据库,所述人脸数据库包括至少一个预设人脸信息;
25、判断所述人脸信息是否与一个所述预设人脸信息的相似度超过第一人脸相似度阈值,若是,则
26、生成报警信息。
27、可选地,所述利用声源定位技术的音视频采集追踪方法进一步包括:
28、获取摄像系统朝向所述位置信息进行拍摄所获取的图像信息;
29、识别所述图像信息,从而获取图像信息中的步态信息;
30、获取步态数据库,所述步态数据库包括至少一个预设步态信息;
31、判断所述步态信息是否与一个所述预设步态信息的相似度超过第一步态相似度阈值,若是,则
32、生成报警信息。
33、可选地,在生成报警信息之前,所述利用声源定位技术的音视频采集追踪方法进一步包括:
34、根据所述预设人脸信息生成人脸置信度;
35、根据所述步态信息生成步态置信度;
36、根据所述人脸置信度以及所述步态置信度判断是否生成报警信息,若是,则
37、生成报警信息。
38、可选地,所述根据所述人脸置信度以及所述步态置信度判断是否生成报警信息包括:
39、获取人脸信息与超过第一人脸相似度阈值的预设人脸信息的相似度值作为第一相似度值;
40、获取步态信息与超过第一步态相似度阈值的预设步态信息的相似度值作为第二相似度值;
41、获取预设因子库,所述预设因子库包括因子值,每个因子值对应一个预设比值信息;
42、获取第一相似度值与所述第二相似度值的比值信息;
43、获取预设因子库内的与比值信息相同的预设比值信息所对应的因子值;
44、将所述因子值与第一相似度值相乘后再除以第二相似度值从而获取最终置信度值;
45、判断获取的最终置信度值是否超过预设置信度值,若是,则
46、生成报警信息。
47、本申请还提供了一种利用声源定位技术的音视频采集追踪装置,所述利用声源定位技术的音视频采集追踪装置包括:
48、声源位置获取模块,所述声源位置获取模块用于获取监测场景中的可疑人员的声源位置;
49、位置信息生成模块,位置信息生成模块用于根据可疑人员的声源位置生成位置信息;
50、传输模块,所述传输模块用于将位置信息传递给摄像系统,以使摄像系统朝向所述位置信息进行拍摄。
51、有益效果
52、本申请通过声源定位追踪技术,将前端采集数据更精准化,使采集到的数据更有价值。完成异常事件定向采集功能。
技术特征:
1.一种利用声源定位技术的音视频采集追踪方法,其特征在于,所述利用声源定位技术的音视频采集追踪方法包括:
2.如权利要求1所述的利用声源定位技术的音视频采集追踪方法,其特征在于,在所述获取可疑人员的声源位置之前,所述利用声源定位技术的音视频采集追踪方法进一步包括:
3.如权利要求2所述的利用声源定位技术的音视频采集追踪方法,其特征在于,所述获取监测场景的阵列内声源位置数据包括:
4.如权利要求3所述的利用声源定位技术的音视频采集追踪方法,其特征在于,所述获取监测场景中的可疑人员的声源位置包括:
5.如权利要求4所述的利用声源定位技术的音视频采集追踪方法,其特征在于,所述根据可疑人员的声源位置生成位置信息包括:
6.如权利要求5所述的利用声源定位技术的音视频采集追踪方法,其特征在于,所述利用声源定位技术的音视频采集追踪方法进一步包括:
7.如权利要求6所述的利用声源定位技术的音视频采集追踪方法,其特征在于,所述利用声源定位技术的音视频采集追踪方法进一步包括:
8.如权利要求7所述的利用声源定位技术的音视频采集追踪方法,其特征在于,在生成报警信息之前,所述利用声源定位技术的音视频采集追踪方法进一步包括:
9.如权利要求8所述的利用声源定位技术的音视频采集追踪方法,其特征在于,所述根据所述人脸置信度以及所述步态置信度判断是否生成报警信息包括:
10.一种利用声源定位技术的音视频采集追踪装置,其特征在于,所述利用声源定位技术的音视频采集追踪装置包括:
技术总结
本申请公开了一种利用声源定位技术的音视频采集追踪方法及装置。所述利用声源定位技术的音视频采集追踪方法包括:获取监测场景中的可疑人员的声源位置;根据可疑人员的声源位置生成位置信息;将位置信息传递给摄像系统,以使摄像系统朝向所述位置信息进行拍摄。本申请通过声源定位追踪技术,将前端采集数据更精准化,使采集到的数据更有价值。完成异常事件定向采集功能。
技术研发人员:杨晓东,刘海东,安俊峰,何延华,李罡,刘新,潘雷,张统彪,张和强,李美,景元广,邵永佳,张继伟,孙戈,王建军
受保护的技术使用者:济南轨道交通集团有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!