基于统计的网络告警关联规则挖掘及故障定位方法、系统
本发明涉及数据挖掘以及网络故障定位,具体涉及一个基于统计的网络告警关联规则挖掘及故障定位方案。
背景技术:
1、数据挖掘(data mining),是通过分析数据,从大量数据中寻找其规律的技术。随着技术的发展与网络规模的扩大,网络系统中产生的告警信息也越来越多,如何有效地处理这些告警信息从而提高网络的稳定性显得十分重要。解决这一问题主要使用的是数据挖掘中的关联规则挖掘方法,这些方法通过扫描告警数据找出根源告警,得到关联规则,网络运营维护人员通过关联规则来定位网络中故障的发生位置,及时对网络中的故障进行修复,最终提高网络的稳定性。
2、e.stamoulakatou等人利用apache spark计算引擎实现了一种基于apriori的分布式顺序模式挖掘方法,该方法利用了原始序列中每个模式位置的先验属性和信息,减少了每次迭代的候选数,提高了操作效率。但该方法在数据量较大时运行效率有所降低。a.makanju在hadoop下使用mapreduce框架来加快fp-growth方法的运行速度。然而,传统的mapreduce不允许作业之间的自动同步,因此他们使用了父子mapreduceframework,该框架允许以分层父子方式动态创建和同步mapreducer任务。与并行fp-growth相结合,方法的计算速度显著提高。但该方法由于需要创建fp-tree,在内存占用方面表现不佳。j.wang等人认为,警报泛滥的真正原因是由于短时间内的异常传播而产生大量相关警报。因此,他们改进了prefixspan方法,并结合了报警之间的因果关系,成功地减少了由异常传播引起的后续报警,提高了获取关联规则的效率。这些方法都提高了运行效率,但都包括挖掘频繁项集的步骤,即在数据库中搜索支持度大于最小支持度的项集,该最小支持度是人为设置的。如何确定适当的最小支持度尤为关键。如果最小支持度过大或过小,将影响方法的执行效率和最终结果。所以,如何同时解决上述问题是极其困难的,所以需要一种可以同时解决上述问题的挖掘方法,以支持更及时有效的网络故障定位。
3、参考文献:
4、e.stamoulakatou,a.gulino and p.pinoli,"dla:a distributed,lo cation-based and apriori-based algorithm for biological sequence pattern mining,"2018ieee international conference on big data(big data),
5、2018,pp.1121-1126.
6、a.makanju,z.farzanyar,a.an,n.cercone,z.z.hu and y.hu,"deepparallelization of parallel fp-growth using parent-child mapred uce,"2016ieeeinternational conference on big data(big data),2016,pp.1422-1431.
7、j.wang,r.jia,j.zhou and m.zhou,"mining sequential alarm p atternbased on the incremental causality prefixspan algorithm,"in ie eetransactions on artificial intelligence,2022,pp.1-1.
技术实现思路
1、根据上述的现有技术缺陷,本发明提供一种基于统计的网络告警关联规则挖掘方案。
2、为达到上述目的,本发明采用的技术方案提供一种基于统计的网络告警关联规则挖掘方法,包括以下步骤,
3、步骤1,对网络告警数据进行预处理,移除其中频繁发生的颤动告警,减小告警数据的冗余度;
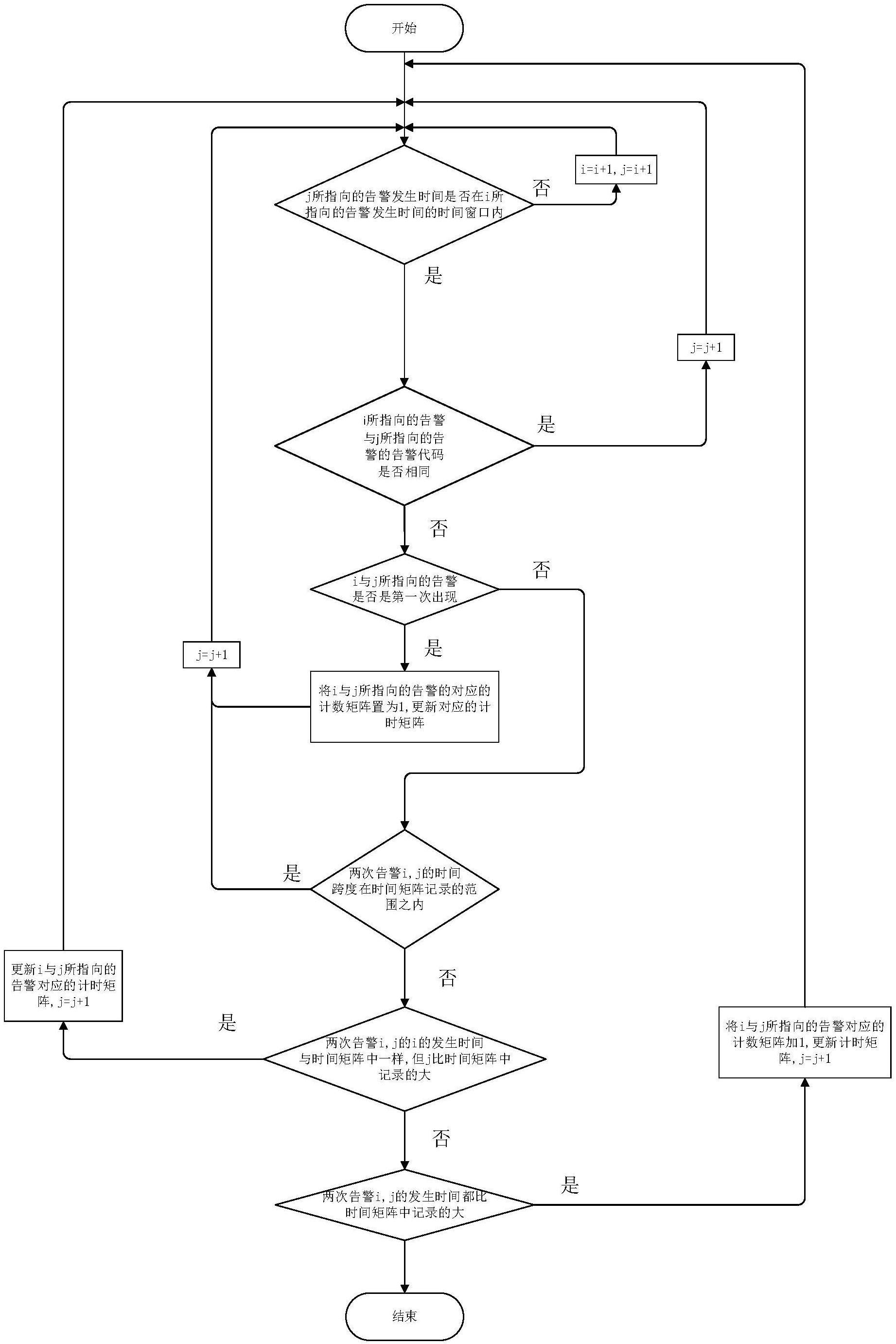
4、步骤2,扫描处理后的网络告警数据,计算其中的告警种类数,根据告警种类数建立计时矩阵与计数矩阵;
5、步骤3,扫描网络告警数据,使用滑动时间窗口法分段处理告警数据,包括对时间窗口内的告警,根据这些告警的告警代码、告警发生时间以及计时矩阵中对应记录来进行操作,将其中每对告警的共现次数信息记入计数矩阵,将每对告警的发生时间信息记入计时矩阵;在当前时间窗口扫描完毕后时间窗口进行滑动,窗口内包含新的告警数据,对这些告警数据重复上述操作,直至告警数据扫描完毕,进入步骤4;
6、步骤4,根据计数矩阵中的告警共现次数信息计算对应的告警关联规则的支持度与置信度,实现通过处理告警数据得到关联规则并输出。
7、而且,步骤1中,对网络告警数据进行预处理时,将告警视为由告警代码和告警发生时间组成的二元组。
8、而且,计数矩阵中每个元素为对应的两个告警代码的共现次数,计时矩阵中每个元素为对应的两个告警代码的告警发生时间组成的二元组。
9、而且,通过处理告警数据得到关联规则后,通过关联规则中的告警代码找寻告警发生的层次以及设备来定位故障。
10、另一方面,本发明提供一种基于统计的网络告警关联规则挖掘系统,用于实现如上所述的一种基于统计的网络告警关联规则挖掘方法。
11、而且,包括以下模块,
12、第一模块,用于对网络告警数据进行预处理,移除其中频繁发生的颤动告警,减小告警数据的冗余度;
13、第二模块,用于扫描处理后的网络告警数据,计算其中的告警种类数,根据告警种类数建立计时矩阵与计数矩阵;
14、第三模块,用于扫描网络告警数据,使用滑动时间窗口法分段处理告警数据,包括对时间窗口内的告警,根据这些告警的告警代码、告警发生时间以及计时矩阵中对应记录来进行操作,将其中每对告警的共现次数信息记入计数矩阵,将每对告警的发生时间信息记入计时矩阵;在当前时间窗口扫描完毕后时间窗口进行滑动,窗口内包含新的告警数据,对这些告警数据重复上述操作,直至告警数据扫描完毕;
15、第四模块,用于根据计数矩阵中的告警共现次数信息计算对应的告警关联规则的支持度与置信度,实现通过处理告警数据得到关联规则并输出。
16、或者,包括处理器和存储器,存储器用于存储程序指令,处理器用于调用存储器中的存储指令执行如上所述的一种基于统计的网络告警关联规则挖掘方法。
17、或者,包括可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序执行时,实现如上所述的一种基于统计的网络告警关联规则挖掘方法。
18、在本发明中,提出了基于统计的网络告警关联规则挖掘及故障定位方案,目的在于快速准确地找到根源告警。本发明具有以下特点:
19、1)告警数据的预处理。本发明定义了告警数据中的颤动告警,即在短时间内发生十分频繁的告警,这类告警大大增加了告警数据的冗余程度。并提出将一个时间段内的颤动告警用它的第一次发生来代替,这样既保留了告警数据的信息,也减小了告警数据的冗余度,加快了后续方法的运行效率。
20、2)基于统计的方法。本发明通过时间窗口来将告警数据分段处理,通过每个告警的告警代码与告警发生时间来记录不同告警之间的共现次数与发生时间,并将这些信息记入计数矩阵与计时矩阵中。当告警代码不同时,根据对应告警的发生时间是否在计时矩阵的记录之中来对计数矩阵进行相应的操作。
21、3)无需人为设置最小支持度。传统的关联规则挖掘方法都包括挖掘频繁项集的步骤,需要人为设置最小支持度。最小支持度过大会导致候选项集过少,得出的关联规则不具有代表性。而最小支持度过小会导致候选项集过多,影响方法的运行效率。而基于统计的方法无需人为设置最小支持度,通过滑动时间窗口方法与矩阵相结合来扫描告警数据。
22、因此,本发明能够很好地对网络告警数据进行处理并且同时考虑了方法运行效率与得出规则的正确性,从而实现更高效精确的网络故障定位,帮助网络运营维护人员提高网络的稳定性。
- 还没有人留言评论。精彩留言会获得点赞!