基于FPGA+RLDRAM3实现高速流表的方法与流程
基于fpga+rldram3实现高速流表的方法
技术领域
1.本发明涉及网络流量筛选技术领域,具体涉及基于fpga+rldram3实现高速流表的方法。
背景技术:
2.在研发网络流量筛选平台、网络安全检测及过滤平台、dpi采集平台、网络流量清洗以及防火墙等网络安全领域的平台系统时,一个无法避免的重要功能及技术指标是系统支持的流表数量。依据中国移动统一dpi设备技术规范要求,相关平台设备每100g要求支持并发流数为2500万,同时要求至少满足的性能指标为平均报文长度256字节线速处理。但是随着网络接口速率的不断发展,接口速率从1g、2.5g、10g、40g、逐步发展到100g接口。如何在满足高速报文处理的前提下,实现大容量的流表是上述平台设备研发中需要解决的技术难题之一。
技术实现要素:
3.有鉴于此,本发明要解决的问题是提供基于fpga+rldram3实现高速流表的方法。
4.为解决上述技术问题,本发明采用的技术方案是:基于fpga+rldram3实现高速流表的方法,包括第一级流表通过fpga+rldram3承载,第二级流表通过x86+ddr4的通用服务器承载,第一级流表和第二级流表通过自定义的流记录联通;当一条流的首报文到达时,根据报文的五元组进行哈希计算得到哈希值,以哈希值为地址建立所述第一级流表,通过调取上报机制,当第一级流表上报流记录时,依据该流记录建立第二级流表,所述第二级流表再依据该流记录组帧产生xdr流记录输出。
5.在本发明中,优选地,所述上报机制包括溢出上报判定策略,对每个报文采用溢出上报策略,所述溢出上报判定策略配置有溢出上报门限值,所述溢出上报判定策略为将当前连接表中累积的报文数与溢出上报门限值进行比较,若当前连接表中累积的报文数大于溢出上报门限值,则启动溢出上报指令。
6.在本发明中,优选地,所述上报机制包括超时控制策略,所述超时控制策略以定时轮询方式进行判定,当tu大于超时时间门限阈值时则表明当前流出现超时,所述超时控制策略包括tcp结束快超时判定策略、短流快超时判定策略和哈希表冲突更新超时判定策略,分别对应tcp结束快超时类型、上报快超时类型以及哈希表冲突更新超时类型。
7.在本发明中,优选地,所述tcp结束快超时判定策略为判断当前流收到的报文是否带有tcp fin和rst标志,是则设置tcp快超时门限小于超时时间门限阈值,对应记录tcp结束快超时类型;否则不执行。
8.在本发明中,优选地,所述短流快超时判定策略配置有快超时门限值和报文数超时门限值,所述短流快超时判定策略为判断tu大于快超时门限值,且连接表中上下行报文数之和报文数小于门限值时,驱动快速超时,同时对应记录快超时类型。
9.在本发明中,优选地,所述哈希表冲突更新超时判定策略配置有哈希冲突更新超
时门限值,所述哈希表冲突更新超时判定策略为判断tu是否大于哈希冲突更新超时门限值,是则驱动删除原连接并上报哈希表冲突更新超时类型。
10.在本发明中,优选地,所述上报机制还包括定时上报判定策略,所述定时上报判定策略配置有定时上报门限值,所述定时上报判定策略为将距离前一流记录上报时间间隔与定时上报门限值比较,若距离前一流记录上报时间间隔大于定时上报门限值则启动定时上报指令。
11.在本发明中,优选地,所述流记录包括上报类型、特征id、协议类型、业务id、ip地址、上下行报文数和字节数以及流时间信息。
12.本发明具有的优点和积极效果是:本发明第一级流表通过fpga+rldram3承载,第二级流表通过x86+ddr4的通用服务器承载,第一级流表和第二级流表通过自定义的流记录联通,在不提高fpga规模资源的前提下,解决了单板实现400g以上的高速流表的技术难题,为实现支持多100g接口的相关处理平台提供可行性方法。
附图说明
13.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:图1是本发明的基于fpga+rldram3实现高速流表的方法的流表的结构示意图;图2是本发明的基于fpga+rldram3实现高速流表的方法的流程示意图;图3是本发明的基于fpga+rldram3实现高速流表的方法的tu大于超时时间门限阈值时的示意图;图4是本发明的基于fpga+rldram3实现高速流表的方法的哈希表冲突更新超时的示意图;图5是本发明的基于fpga+rldram3实现高速流表的方法流记录格式图;图6是图5中的a结构的局部放大示意图;图7是图5中的b结构的局部放大示意图;图8是图5中的c结构的局部放大示意图。
具体实施方式
14.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
15.需要说明的是,当组件被称为“固定于”另一个组件,它可以直接在另一个组件上或者也可以存在居中的组件。当一个组件被认为是“连接”另一个组件,它可以是直接连接到另一个组件或者可能同时存在居中组件。当一个组件被认为是“设置于”另一个组件,它可以是直接设置在另一个组件上或者可能同时存在居中组件。本文所使用的术语“垂直的”、
ꢀ“ꢀ
水平的”、
“ꢀ
左”、
“ꢀ
右”以及类似的表述只是为了说明的目的。
16.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具
体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。
17.实现上述平台的解决方案,目前主流的解决方案主要有两种,一种是基于多核x86+ddr内存的软件架构,另一种是以fpga+ddr(ddr3/ddr4)的硬件架构。由于100g及以上接口的平台对流表数量的要求都很大,上述两种实现方案目前主流的解决方案都是采用ddr3/ddr4内存作为流表的储存载体。以多核x86+ddr4的解决方案为例,流表实现在ddr4中,由于x86+ddr4中ddr4内存是作为软件系统的内存是整个处理系统共用的,实现流表只能是其需要承载的部分功能,同时一台服务器可以安装ddr4内数量有限,虽然在流表容量上是可以满足需求的,但ddr4访问性能必然不可避免成为系统设计的技术瓶颈。以目前的技术,在性价比可以接受的情况下,按256字节线速处理的要求,一台多核x86+ddr4可以实现的处理性能为60g~100g之间。故以多核x86+ddr4为主的软件架构在实现100g以内时尚且可以满足需求,当接口速率达到100g以上及多100g接口时,软件架构的解决方案就不可避免的遇到了性能瓶颈。
18.再说以fpga+ddr(ddr3/ddr4)为主的硬件架构解决方案,同样是采用ddr4作为流表的载体,所不同的是此时的ddr4内存可以提供给流表专用。ddr4作为一种sdram内存,尽管ddr4接口速率不断的提高,但其读写时序与传统的sdram大致是相同的,其基本的读写时序及命令是相似的。
19.ddr(ddr/ddr2/ddr3/ddr4)读写时序的特点:无论是读操作还是写操作都需要先激活act相应bank的行地址(row),然后才能读对应的列数据。
20.激活act操作后,再完成读或写之后,需要对打开的行进行预充电。
21.预充电完成后,才能对同一个bank的其余行进行读、写操作。
22.sdram除了在读写操作后需要进行预充电外,对sdram的所有bank的所有行,需要进行周期性的刷新操作。
23.为了提高读写性能,sdram通常采用的方法是采用多bank交织的读、写操作。
24.基于上述ddr sdram读写控制时序的特点及复杂性,软件架构的设计方案一般都是cpu+ddr内存的结构,在软件架构中是通过为cpu处理器增加一级、二级甚至三级缓存的方式来减少对外部ddr内存的访问频率来提高性能及降低访问延迟的。这种架构对于支持接口速率小于100g或多个10g接口时尚可以支撑,当接口速率达到100g及多个100g接口同时处理时,由于同时活跃的并发连接数和性能达到一定规模时,上述架构将无法满足对大容量流表在处理时延及性能上的设计需求。
25.基于fpga+ddr4为主的硬件架构也不可避免的会遇到读写时延与性能瓶颈问题,传统的解决方法是采用多bank交织读写的方式解决性能问题。读写时延问题则是无法解决。同时多bank交织读写的方式意味着需要fpga实现针对多bank的多队列报文缓存存储与多队列调度,通常按100g链路256字节平均报文长度来设计处理性能,一条ddr4要支持100g的处理性能,至少需要8个bank交织处理,需要占用大量的fpga内部资源来实现多队列报文存储与队列调度,导致整体实现难度增加和成本的增加。上诉技术难题和成本压力,使得以fpga+ddr4架构在单颗fpga中实现多100g接口的处理时对fpga芯片规模的要求及成本快速增加,成为设计类似平台架构是一个难以解决的技术难题。现有技术存在以软件架构为主
的设计方案,虽然利用cpu及多核系统自带的内存,可以解决流表的大容量的需求,但由于cpu外部的内存是整个系统共用的内存,因此无法解决100g以上接口速率对高性能及低时延的设计需求。
26.以fpga+ddr(ddr3/ddr4)硬件架构解决方案,虽然可以解决大容量流表的问题,但由于ddr3、ddr4内存的读写特性,完成一次流表读写操作的时延很大,同时想要达到足够高的性能,例如为了满足100g速率在平均报文256字节的线速处理,需要的处理性能为50m左右,而采用ddr4要到达这个要求,需要至少8bank以上的交织读写才能达到,这就需要每100g至少对应8个队列的报文缓存及队列调度,要完成上述功能需求,除了更复杂的设计外,还需要有更大规模的fpga芯片资源。设计复杂度及成本的增加,使得上述方案变得很大实现。
27.为解决上述技术难题,本发明研究一种新型dram器件存储器件rldram的同时,在充分的研究互联网流量特性的基础上,提出了一种以fpga+rldram3硬件架构为基础,结合x86+ddr4软件实现的两级流表实现方法,解决了上述技术难题,在不提高fpga规模资源的前提下,实现了单板处理4x100g接口流量,做到了性能与成本的合理解决。
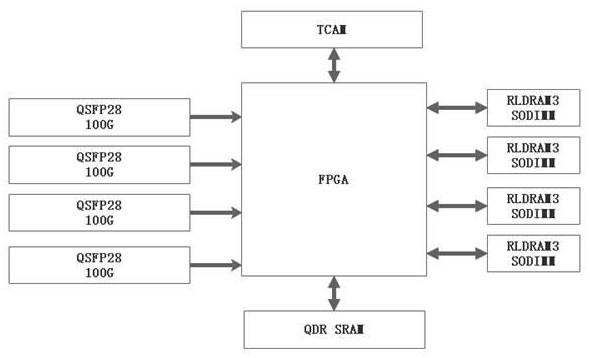
28.如图1所示,本发明提供基于fpga+rldram3实现高速流表的方法,包括第一级流表通过fpga+rldram3承载,第二级流表通过x86+ddr4的通用服务器承载,第一级流表和第二级流表通过自定义的流记录联通;将相同5元组(源ip、目的ip、源端口号、目的端口号、协议类型)的数据包定义为一条流,当一条流的首报文到达时,根据报文的五元组进行哈希计算得到哈希值,以哈希值为地址建立所述第一级流表,通过调取上报机制,当第一级流表上报流记录时,依据该流记录建立第二级流表,所述第二级流表再依据该流记录组帧产生xdr流记录输出。
29.在本实施例中,进一步地,所述上报机制包括溢出上报判定策略,对每条报文采用溢出上报策略,所述溢出上报判定策略配置有溢出上报门限值,所述溢出上报判定策略为将当前连接表中累积的报文数与溢出上报门限值进行比较,若当前连接表中累积的报文数大于溢出上报门限值,则启动溢出上报指令。
30.如图2所示,在本实施例中,进一步地,所述上报机制包括超时控制策略,所述超时控制策略以定时轮询方式进行判定,当tu大于超时时间门限阈值时则表明当前流出现超时,所述超时控制策略包括tcp结束快超时判定策略、短流快超时判定策略和哈希表冲突更新超时判定策略,分别对应tcp结束快超时类型、上报快超时类型以及哈希表冲突更新超时类型。
31.在本实施例中,进一步地,所述tcp结束快超时判定策略为判断当前流收到的报文是否带有tcp fin和rst标志,是则设置tcp快超时门限小于超时时间门限阈值,对应记录tcp结束快超时类型;否则不执行。
32.在本实施例中,进一步地,所述短流快超时判定策略配置有快超时门限值和报文数超时门限值,所述短流快超时判定策略为判断tu大于快超时门限值,且连接表中上下行报文数之和报文数小于门限值时,驱动快速超时,同时对应记录快超时类型。
33.如图3所示,在本实施例中,进一步地,所述哈希表冲突更新超时判定策略配置有哈希冲突更新超时门限值,所述哈希表冲突更新超时判定策略为判断tu是否大于哈希冲突更新超时门限值,是则驱动删除原连接并上报哈希表冲突更新超时类型。
34.在本实施例中,进一步地,所述上报机制还包括定时上报判定策略,所述定时上报判定策略配置有定时上报门限值,所述定时上报判定策略为将距离前一流记录上报时间间隔与定时上报门限值比较,若距离前一流记录上报时间间隔大于定时上报门限值则启动定时上报指令。通过设计定时上报判定策略目的是避免有些keep live的流长时间无法满足溢出上报的情况,导致长时间无流记录上报导致后台流记录处理超时。
35.如图5所示,在本实施例中,进一步地,第一级只上报流记录给第二级,所述流记录包括上报类型、特征id、协议类型、业务id、ip地址、上下行报文数和字节数以及流时间等各种信息,第二级流表根据上述信息完成基于流的统计、业务分析等功能,两级流表是独立管理的。f_t字段表示该流记录的上报类型,为0x0表示首报文驱动上报,首报文驱动上报的目的是为了节约前级硬件哈希表的资源,当连接的第一个报文到达时,建立哈希表的同时,将连接表的5元组信息及一些关键信息进行上报,这样信息就无需再储存到哈希表中。特别是对于ipv6协议报文,此机制大大的节约了连接表的数据空间;0x1表示新的连接到来时,发现上一个连接已经超时(报文触发);0x2表示连接已超时(定时轮询触发);0x3表示在某个时长内该连接的报文数小于某个数量,则生成流记录;0x4 tcp表示连接收到fin或rst导致的上报;0x5表示报文数目超出阈值上报;0x6表示按照设定的时长定时上报;0x7表示收到get/post上报文导致上报。
36.ser_t字段表示特征id,tcp_udp字段表示为ip层的协议类型,0x1表示tcp;0x2表示udp;0x3表示icmp;0x4表示其他协议;slid字段表示业务id,其映射表由网管数据库提供;in_ip字段表示内部ip地址,out_ip字段表示外部ip地址;up_pkt_cnt和up_byte_cnt字段分别表示上行报文数和字节数,dn_pkt_cnt和dn_byte_cnt字段分别表示下行报文数和字节数;setup_time和end_time字段分别表示流开始时间和结束时间。
37.第一级流表的超时可能是5、10、20秒。第二级的超时可以是60秒、2分钟、5分钟,第一级是高速的缓存,第二级的大容量的、后分析的,而且是全量保存的。分析基于统一dpi、安全平台、分流过滤平台对于流表数量的要求时,每条流的尾报文到达后仍要求当前流的超时时间达30~60秒以上,而实际的流在尾报文达到时应该是很快就可以超时的,合适的超时机制完全可以更高效的利用流表存储空间。基于上述原则,本发明可以根据tcp和udp协议的不同、针对不同流的特性,设计了不同的超时控制策略。
38.本发明的工作原理和工作过程如下:如图2所示,本发明以五元组来定义一条流,当一条流的首报文到达时,根据报文的5元组做哈希计算,以哈希值为地址建立一个流表,在处理高速接口的时,流表通常以硬件的方式建立,本案中是通过fpga加rldram3内存条,或fpga加uram、sram、qdr sram存储器方式建立流表。为了高效率的利用硬件的流表,每条流的统计信息通过溢出上报,定时上报等方式,以流记录的方式上报给后台软件系统。后台软件系统接收流记录,同样以5元组为索引,将每条流上报的流记录关联起来,产生xdr(x data record)记录。
39.图1是本发明采用的fpga+rldram3硬件架构的基本结构图,具体采用了四组自研rldram3内存条,每组用于承载实现100g接口的流表。为了满足100g接口对流表的容量要求,同时也是更高效的利用rldram3内存,我们将每流的流表内容定义为512比特,一组
rldram3最大支持的流表容量为1500万。但类似统一dpi的流采集设备对流表容量的要求为每100g流量2500万以上。本案为了满足上述设计要求,设计了两级流表的综合解决方案,将fpga+rldram3实现的高性能流表作为第一级,采用类似高速cache的思路,将rldram3实现的第一级流表设计为一个高性能,大容量的一级流表cache缓存,配合第二级流表,完成对流表容量的设计需求。通过将低时延的rldram3作为流表载体的另一个好处是,利用ddr4需要至少8 bank交织读写才能达到的性能指标,采用rldram3作为载体时只需要2 bank交织读写即可完成,大大的降低的设计难度与fpga资源占用率。
40.以上对本发明的实施例进行了详细说明,但所述内容仅为本发明的较佳实施例,不能被认为用于限定本发明的实施范围。凡依本发明范围所作的均等变化与改进等,均应仍归属于本专利涵盖范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1