基于DPU的高性能网络加速方法及系统
本发明涉及互联网,具体地,涉及基于dpu的高性能网络加速方法及系统。
背景技术:
1、当前,随着大数据和云计算的发展,本地计算集群自带的存储硬盘已经无法满足日益增长的存储需求。在分布式存储领域,大量优秀的架构已经被提出,其高性能、高可靠、易拓展的优点被广泛青睐。存算分离的思想已经成为主流的趋势。大规模的数据通过网络对分布式存储集群进行远程读写的场景对网络性能的需求带来了新的挑战。对于传统网卡而言,其主要完成数据链路层和物理层的功能,而更高层的任务,如网络协议的解析则需要交给cpu来完成。所以,在传统网络功能方案中,远程存储集群密集的网络通信会频繁的将网络协议解析下陷到计算节点的主机内核态进行处理,对计算节点的主机cpu占用产生额外开销,如上下文切换对缓存的污染、逐包中断、内核态与用户态的内存拷贝等。这对于本就cpu需求密集的计算节点会直接占用宝贵的计算资源,同时大量的网络中断与计算线程的cpu争用,也导致了计算节点的网络通信性能下降。更重要的是,随着nfv和sdn技术的兴起,open flow,open vswitch等虚拟交换机的引入,大量的软件栈的引入使得网络数据面的复杂性不断增加,对主机的cpu会造成难以承受的压力。
2、目前,为了解决主机网络数据处理性能以及网络功能占用cpu过高的问题,学术界从软件和硬件的角度做出了各样的研究。
3、在软件方面,linux社区在2011年推出了netmap网络架构,它是一个基于零拷贝思想和高速io的架构。其零拷贝的思想有dba实现,将应用程序直接跑在内核态或者将内核中的缓存数据直接暴露给用户态的数据结构。然而netmap自身需要驱动的支持,并且还是依赖于中断机制,没有从根本上解决cpu上下文切换带来的性能瓶颈。sr-iov技术在nfv领域应用十分广泛。其将pf(physical function)映射为多个vf(virtual function),使得每个vf都可以绑定到虚拟机。这样做确实可以让cpu使用率和网络性能带来提升,但是其固定性的架构一方面增加了复杂性,一方面也限制了拓展性。一个支持sr-iov的网卡只能提供有限的vf接口。2010年,intel公司推出了dpdk(data plane development kit)高性能包转发协议。与netmap类似,其基本思想也是通过绕过内核的方式,通过用户态直接对网络包进行解析。与netmap不同的是,dpdk采用了轮询机制,不断探测网口有无数据包的收发。这样的机制可以迅速对网络包进行处理,同时避免了中断机制带来的内核切换上下文开销。然而,轮询机制也需要大量的cpu资源,通常的做法是绑定轮询线程到特定的核,让其占满该核的使用率。
4、在硬件方面,近几年越来越多的可编程dpu产品的相继出现代表了另一种减少主机处理开销方法。dpu的核心支持远程数据结构访问,并且dpu具有高效的包处理、低dma写入延迟、含有丰富的硬件接口如异步操作和批量操作等优势。dpu的存在对于主机端的网络处理功能的有效卸载和可编程的智能核心无疑为存算分离架构下,计算节点获取更高性能的网络通信提供了潜在的研究方向。然而,由于dpu的受限于其处理核心的计算能力以及有限的内存,将主机端的网络功能简单的移植将大幅降低吞吐量。如何对dpu进行卸载以及如果利用dpu自身的硬件特性搭建网络处理栈对提升网络性能成为了目前需要考虑的问题。
5、专利文献cn110892380a(申请号:201880046042.5)公开了一种利用数据处理单元(dpu)的新处理体系结构。与以中央处理单元(cpu)为中心的传统计算模型不同,dpu被设计用于以数据为中心的计算模型,在该以数据为中心的计算模型中,数据处理任务以dpu为中心。dpu可以看作是高度可编程的高性能i/o和数据处理集线器,其被设计为聚合和处理去往和来自其他设备的网络和存储i/o。dpu包括用于直接连接到网络的网络接口、用于直接连接到一个或多个应用处理器(例如cpu)或存储设备的一个或多个应用处理器接口,以及多核处理器,其中每个处理核执行运行至完成数据平面操作系统。数据平面操作系统被配置为支持控制平面软件堆栈和用于执行数据处理任务的软件功能的库。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种基于dpu的高性能网络加速方法及系统。
2、根据本发明提供的一种基于dpu的高性能网络加速方法,包括:
3、将dpdk软件栈部署在dpu上,并读取远端存储节点发送的数据包进行网络数据解析,通过dma接口将处理后的数据发送至主机的用户态应用程序;
4、所述dpdk接收用户态应用程序发送的数据包,并将接收到的数据包进行封装,将封装后的数据包发送至相应ip的存储节点。
5、优选地,包括:
6、dpu配置模块:用于连接主机与dpu,配置dpu的本地ip,使dpu与主机进行ip转发;
7、dpu运行模式配置模块:用于切换dpu的separated host mode和embedded mode运行模式;
8、dpdk编译模块:用于编译dpdk环境,在ubuntu20.04系统环境下采用dpdk-22.03进行dpdk文件编译;
9、大页配置模块:用于实现大页内存配置,在dpdk编译完后,设置nr_hugepages=1g;
10、核绑定模块:用于将不同功能的线程与内核进行绑定,将预设常驻线程固定于某些cpu单独运行;
11、pktgen编译模块:用于编译pktgen,测试不同流场景,不同的dpu核绑定方式下dpdk优化模块的实时吞吐量。
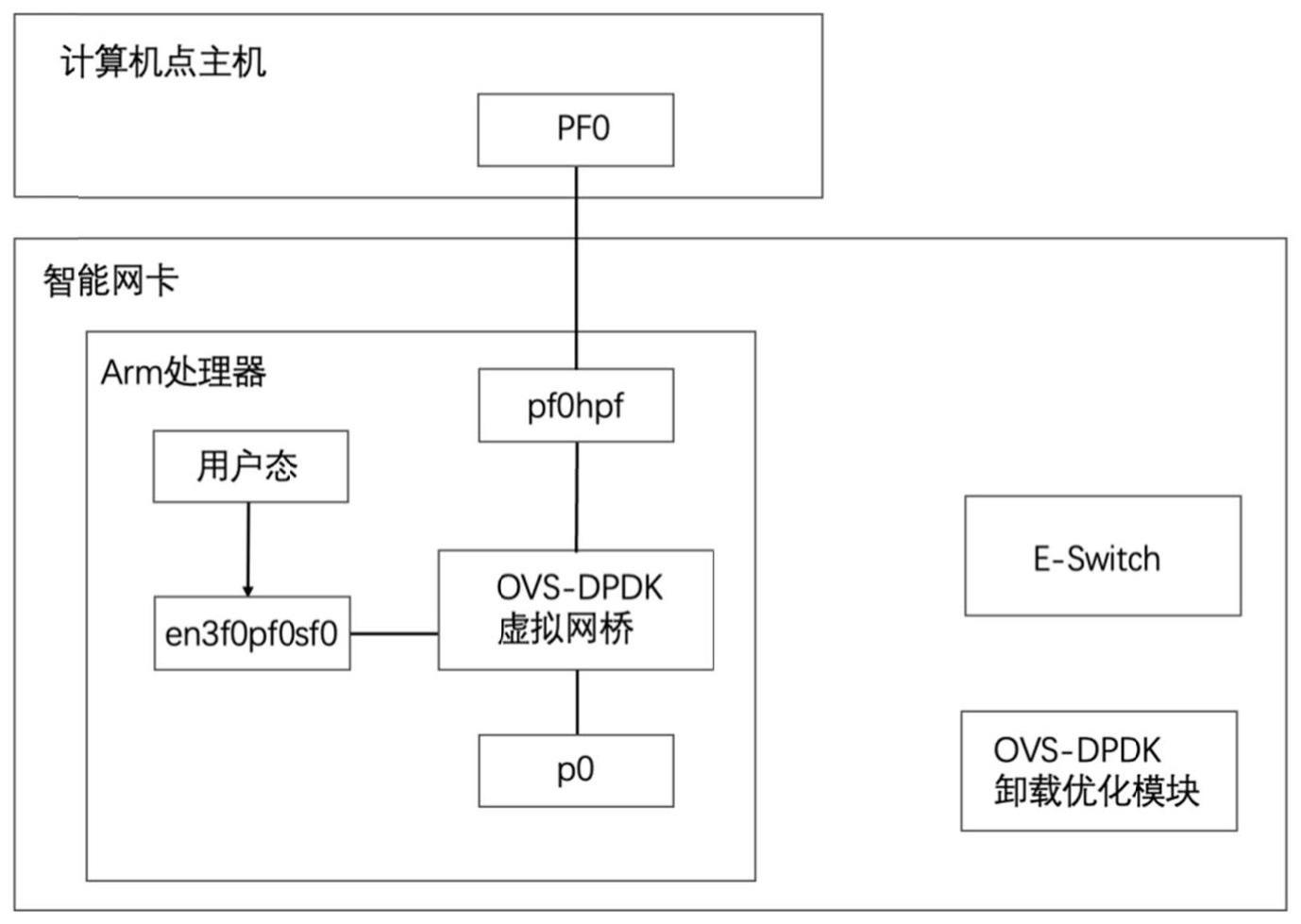
12、优选地,基于ovs对dpdk的数据路径进行硬件卸载,使用dpu的硬件进行流的识别与分类,并对流量进行批处理。
13、优选地,基于ovs与dpdk设置虚拟网桥,虚拟网桥一端是物理端口,另一端是representor的逻辑端口。
14、优选地,使用所述dpu运行模式配置模块将dpu运行模式切换为embedded mode,确保所有的网络数据包均通过dpu进行收发。
15、优选地,使用所述大页配置模块为ovs分配大页内存。
16、根据本发明提供的一种基于dpu的高性能网络加速系统,包括:
17、将dpdk软件栈部署在dpu上,并读取远端存储节点发送的数据包进行网络数据解析,通过dma接口将处理后的数据发送至主机的用户态应用程序;
18、所述dpdk接收用户态应用程序发送的数据包,并将接收到的数据包进行封装,将封装后的数据包发送至相应ip的存储节点。
19、优选地,包括:
20、dpu配置模块:用于连接主机与dpu,配置dpu的本地ip,使dpu与主机进行ip转发;
21、dpu运行模式配置模块:用于切换dpu的separated host mode和embedded mode运行模式;
22、dpdk编译模块:用于编译dpdk环境,在ubuntu20.04系统环境下采用dpdk-22.03进行dpdk文件编译;
23、大页配置模块:用于实现大页内存配置,在dpdk编译完后,设置nr_hugepages=1g;
24、核绑定模块:用于将不同功能的线程与内核进行绑定,将预设常驻线程固定于某些cpu单独运行;
25、pktgen编译模块:用于编译pktgen,测试不同流场景,不同的dpu核绑定方式下dpdk优化模块的实时吞吐量。
26、优选地,基于ovs对dpdk的数据路径进行硬件卸载,使用dpu的硬件进行流的识别与分类,并对流量进行批处理。
27、优选地,基于ovs与dpdk设置虚拟网桥,虚拟网桥一端是物理端口,另一端是representor的逻辑端口。
28、与现有技术相比,本发明具有如下的有益效果:
29、1、基于dpdk的网络包转发模块使得网络数据包直接转发给用户态进行网络包的处理,该方式绕过了内核态对网络解析是发生的内核调用,并使用的轮询机制代替中断,避免了大量收发数据包是发生的中断处理的上下文切换开销。轮询机制也使得网络数据可以第一时间进行处理,在读写密集的存算分离流量较大的场景下,转发性能明显提升;
30、2、dpdk优化模块将dpdk从主机端移植到dpu,解决了dpdk的轮询机制占用主机端cpu的情况,极大程度缓解了主机端的cpu处理网络功能的使用率;
31、3、针对dpu有限的计算资源和内存,实现dpdk端大页内存,内核绑定的模块。大页内存模块提升了tlb的命中率,通过将线程与cpu绑定进一步提高了cpu的缓存命中率。专核专用的模式也极大地提升了dpucpu的处理效率,避免了无效的线程切换,降低了网络数据包的处理延迟;
32、4、卸载优化模块实现了基于ovs的数据路径卸载,将本属于dpu软件栈的流分类工作交给并发性更好的硬件来完成。利用dpu的高效批处理接口,将网络数据根据不同的action分类到不同的流表,并对其进行批处理。在进一步减轻dpucpu负载的情况下,提升了网卡的吞吐量;
33、5、卸载优化模块针对ovs自身流处理的性能瓶颈进行了进一步的优化。观测到在流增大的情况下,ovs的back-end pipeline在mmio操作中会遇到长时间的延迟。针对此类在流表匹配增多,同一批的数据在数量很少的时候就触发了mmio操作的场景,卸载优化模块对mmio触发机制进行了优化,设置了数据包超时刷新和队列中数据包计数器的方式,进一步提升了dpu硬件批处理的性能;
34、6、本发明实现软硬协同的混合解决方案,在软件方面,利用dpu的可编程处理核心实现了基于dpdk的高效包转发逻辑,采用大页内存机制和核绑定机制提高了cpu的缓存和内存命中率,解决了dpdk的轮询机制占用主机端cpu的情况。在硬件方面,基于ovs对dpdk的部分网络功能实现了进行硬件卸载,弥补了dpu有限的内存、cpu对软件栈数据处理造成的性能影响,并对硬件高并发的批处理接口进行了包转发触发机制,进一步提升了dpu硬件批处理的性能。
- 还没有人留言评论。精彩留言会获得点赞!