一种基于联邦强化学习的车联网边缘内容缓存决策方法
本发明涉及无线通信,尤其涉及一种基于联邦强化学习的车联网边缘内容缓存决策方法。
背景技术:
1、近年来,在第六代移动通信技术的驱动下,车联网汽车产业、大数据以及人工智能等新一代信息技术深度融合的新兴领域,可以提供高效可靠的通信服务。然而,随着车辆数目的增多,日益增长的实时通信业务对车联网超低时延与超高可靠性提出了更高的要求。为应对上述挑战,边缘缓存技术通过在边缘节点部署缓存资源以完成本地内容分发,避免对云端集中式交付的依赖,从而减少内容交付的延迟(zhang y,zhao j,cao g.roadcast:apopularity aware content sharing scheme in vanets[j].acm sigmobile mobilecomputing and communications review,2010,13(4):1-14.)。然而,由于边缘节点存储容量有限,急剧增长的车联网应用数据请求无法完全缓存至边缘节点;其次,鉴于车联网高移动性、频繁变化的内容要求以及恶劣的通信环境,故需要针对车联网的场景设计高效的边缘内容缓存方法。
2、考虑到车联网智能边缘内容缓存问题本质上为无模型的离散序列决策问题,故可采用共享训练信息即可完成本地决策的多智能体强化学习方法求解。相比于传统优化算法,深度强化学习可以通过智能体与不确定环境交互而学习经验,以解决动态决策问题。即使无法提前预知动态的环境变化,智能体仍可以学习如何采取行动或如何将获取的信息映射到行动,实现系统奖励的最大化。近年来,国内外研究学者着眼于研究智能边缘内容缓存决策,以在车联网动态无线传输环境下高效利用边缘缓存资源。比如,qiao等人采用深度确定性策略梯度算法,通过利用车辆用户本地观测信息学习车联网无线环境的变化规律,提出了一种协作式边缘缓存方法,以最小化系统内容传输时延与缓存开销的长期权衡(qiaog,leng s,maharjan s,et al.deep reinforcement learning for cooperative contentcaching in vehicular edge computing and networks[j].ieee internet of thingsjournal,2019,7(1):247-257.)。然而,现有的车联网边缘内容缓存方案大多建立在中心化的网络架构之上,并未充分利用边缘节点密集异构的部署特性。此外,考虑到车联网通信方式的开放性,车辆用户个体数据的隐私保护也成了不可忽视的内容。因此,在边缘节点密集异构部署的环境下,如何在隐私保护的基础上,利用去中心化网络架构实现高容量、低缓存开销以及车载通信无缝覆盖,仍然需要进一步的研究。
技术实现思路
1、为克服相关技术中存在的问题,本发明公开实施例提供了一种基于联邦强化学习的车联网边缘内容缓存决策方法。所述技术方法如下:
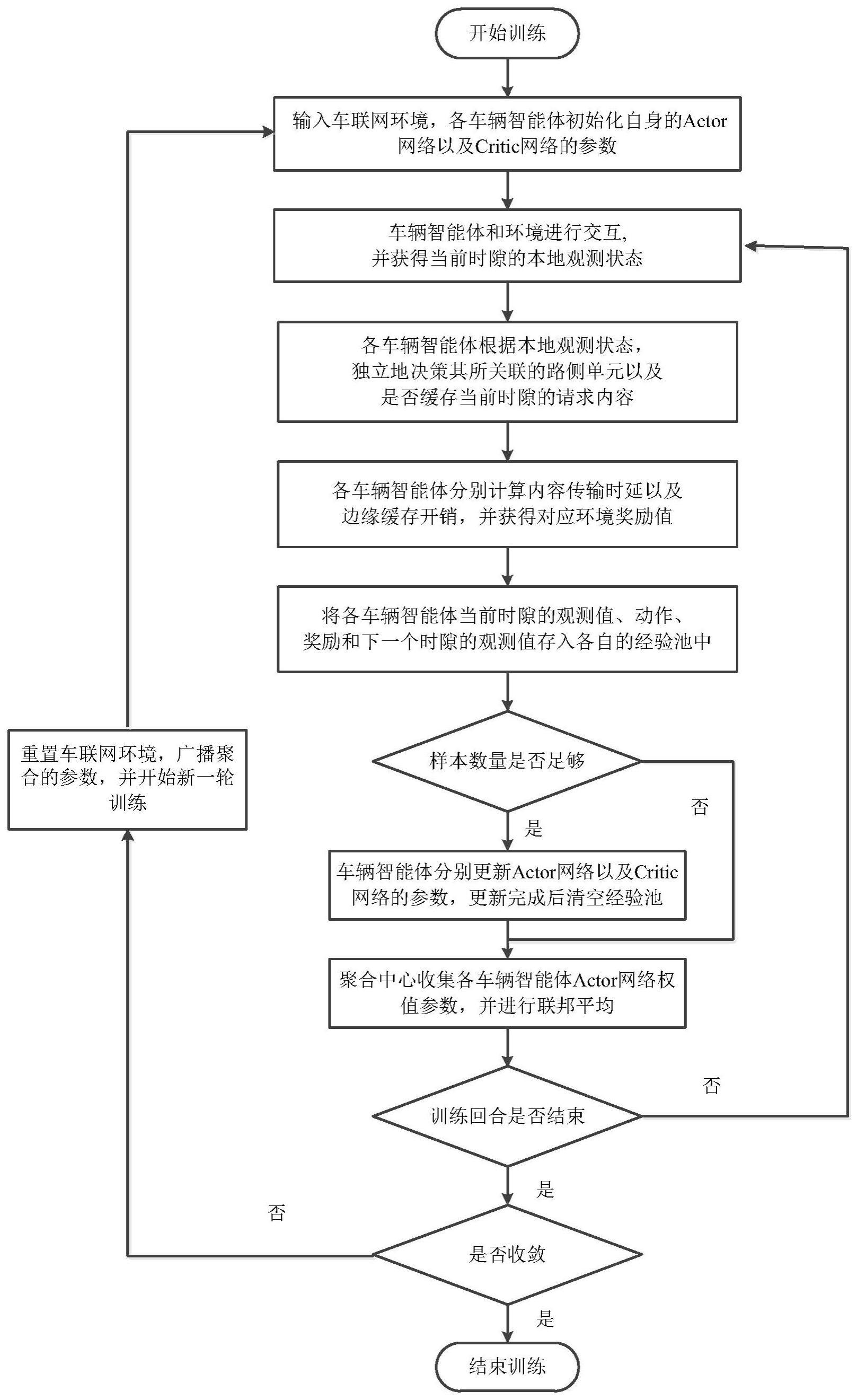
2、步骤1、输入车联网环境,各车辆智能体初始化自身actor网络和critic网络的参数,并对优化问题建模;
3、步骤2、在当前时隙中,各车辆智能体与观测范围内的路侧单元交互,以获得其与路侧单元之间的距离、路侧单元的缓存状态以及路侧单元的剩余缓存容量等观测信息;
4、步骤3、根据本地观测信息,各车辆智能体可独立决策边缘节点集群中关联的路侧单元,以及在集群内部决策是否缓存当前时隙的请求内容;
5、步骤4、执行完动作决策后,各车辆智能体获取车联网环境反馈的系统总内容交付时延与边缘缓存开销的权衡奖励,同时所有的样本数据缓存至经验复用池;
6、步骤5、判断样本数量是否足够,如果是则进入步骤6,否则进入步骤7;
7、步骤6、当样本数量足够时,各车辆智能体根据柔性演员-评论家算法更新自身的actor网络和critic网络参数;
8、步骤7、聚合中心收集各车辆智能体的actor网络权值参数,并进行联邦聚合,聚合的参数在一个训练回合广播给车辆用户以进行本地训练;
9、步骤8、判断当前训练回合是否结束,如果否则返回步骤2开始下一个回合的训练,如果是则进入步骤9;
10、步骤9、判断是否收敛,如果否则重置车联网环境,返回步骤1;如果是则训练结束,完成车联网边缘内容缓存决策。
11、本发明与现有技术相比,其显著优点为:(1)针对车联网缓存场景中心化网络架构导致的链路拥堵负荷,本发明利用密集边缘节点的部署特性,设计以用户为中心的边缘节点集群,以实现高容量、低缓存开销以及车载通信无缝覆盖;(2)针对智能算法集中式训练带来的大量信息交互问题以及隐私泄露问题,本发明利用联邦学习的隐私保护优势,通过共享本地模型神经网络权值,实现车辆用户协作决策,以降低系统内容长期传输时延以及边缘缓存开销。
12、下面结合附图对本发明做进一步的仔细描述。
技术特征:
1.一种基于联邦强化学习的车联网边缘内容缓存决策方法,其特征在于,具体步骤包括:
2.根据权利要求1所述基于联邦多智能体强化学习的车联网边缘缓存决策方法,其特征在于,步骤1中所述的输入车联网环境,具体包括:
3.根据权利要求2所述的基于联邦多智能体强化学习的车联网边缘内容缓存决策方法,其特征在于,步骤1所述对优化问题建模,具体为:
4.根据权利要求3所述的基于联邦多智能体强化学习的车联网边缘内容缓存决策方法,其特征在于,步骤2所述各车辆智能体与观测范围内的路侧单元交互,以获得其与路侧单元之间的距离、路侧单元的缓存状态以及路侧单元的剩余缓存容量等观测信息,具体为:
5.根据权利要求4所述的基于联邦多智能体强化学习的车联网边缘内容缓存决策方法,其特征在于,步骤3所述根据本地观测信息,各车辆智能体可独立决策边缘节点集群中关联的路侧单元,以及在集群内部决策是否缓存当前时隙的请求内容,具体为:
6.根据权利要求5所述的基于联邦多智能体强化学习的车联网边缘内容缓存决策方法,其特征在于,步骤4所述执行完动作决策后,各车辆智能体获取车联网环境反馈的系统总内容交付时延与边缘缓存开销的权衡奖励,具体为:
7.根据权利要求6所述的基于联邦多智能体强化学习的车联网边缘内容缓存决策方法,其特征在于,步骤6所述各车辆智能体根据柔性演员-评论家算法更新自身的actor网络和critic网络参数,具体为:
8.根据权利要求7所述的基于联邦多智能体强化学习的车联网边缘内容缓存决策方法,其特征在于,步骤7所述聚合中心收集各车辆智能体的actor网络权值参数,并进行联邦聚合,聚合的参数在一个训练回合广播给车辆用户以进行本地训练,具体为:
技术总结
本发明公开了一种基于联邦强化学习的车联网边缘内容缓存决策方法,具体为:输入车联网环境,初始化各车辆的网络参数;在当前时隙,各车辆与路侧单元交互以获得观测信息;根据观测信息,各车辆独立决策动作;执行完动作后,各车辆获得环境反馈的奖励,并将样本数据缓存至经验复用池;当样本数量足够时,各车辆根据柔性演员‑评论家算法更新网络;聚合中心收集本地网络参数进行联邦聚合,并将聚合参数广播至本地以训练;当前训练结束后,重置车联网环境,开始下一回合的训练。本发明旨在车联网环境下,利用以用户为中心的网络架构,使得车辆在隐私保护的前提下完成边缘缓存分布式决策,实现系统内容传输时延以及边缘缓存开销权衡的最小化。
技术研发人员:林艳,包金鸣,邹骏,张一晋,李骏,束锋
受保护的技术使用者:南京理工大学
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!