基于深度强化学习的智能路由决策方法、系统及存储介质与流程
本发明涉及人工智能,尤其是一种基于深度强化学习的智能路由决策方法、系统及存储介质。
背景技术:
1、随着物联网的快速发展,物联网规模的不断扩大,接入设备数量和种类逐渐增多,传统的物联网体系架构在异构互连、资源管理、业务处理等方面面临着极大的挑战。其中,海量数据流量传输与处理需求问题尤为突出。传统网络中路由方式有多种,最简单和广泛被使用的方法包括开放式最短路径优先协议和能将流量均匀地分到多条可用路径上的等价多路径路由。
2、开放式最短路径优先协议是基于迪杰斯特拉算法(dijkstra)的一种内部网关协议。最短路径算法只考虑了源节点至目的节点之间的最短跳数,没有考虑网络流量增多的情况。当网络中接入设备数量较少时,此时网络的数据传输能力可以满足网络中的数据流量传输需求,然而在网络接入设备增多,需要对海量数据进行传输时,容易造成因链路带宽利用率过高而产生网络拥塞。此外,最短路径算法没有考虑到网络中带宽、时延等网络实时信息,在应对海量数据传输时,容易引发网络负载均衡问题,也会造成网络拥塞。
3、等价多路径路由是一种多路径路由的路由策略。在计算源节点到目的节点之间的路由路径时,会得出多条相同开销的路由路径,这样就可以使用多条路由路径来转发流量。等价多路径路由最大的特点是实现了路由路径在相同权值情况下多路径负载均衡和链路冗余备份。但是在实际情况下,各路径的带宽、时延等不一样,在各路径权值一样的情况下,不能很好地利用带宽,尤其在路径间带宽差异大时,效果会非常不理想。
技术实现思路
1、本发明的目的在于至少一定程度上解决现有技术中存在的技术问题之一。
2、为此,本发明实施例的一个目的在于提供一种基于深度强化学习的智能路由决策方法,该方法能够实现物联网海量数据流量的负载均衡,提高了物联网的网络性能。
3、本发明实施例的另一个目的在于提供一种基于深度强化学习的智能路由决策系统。
4、为了达到上述技术目的,本发明实施例所采取的技术方案包括:
5、第一方面,本发明实施例提供了一种基于深度强化学习的智能路由决策方法,包括以下步骤:
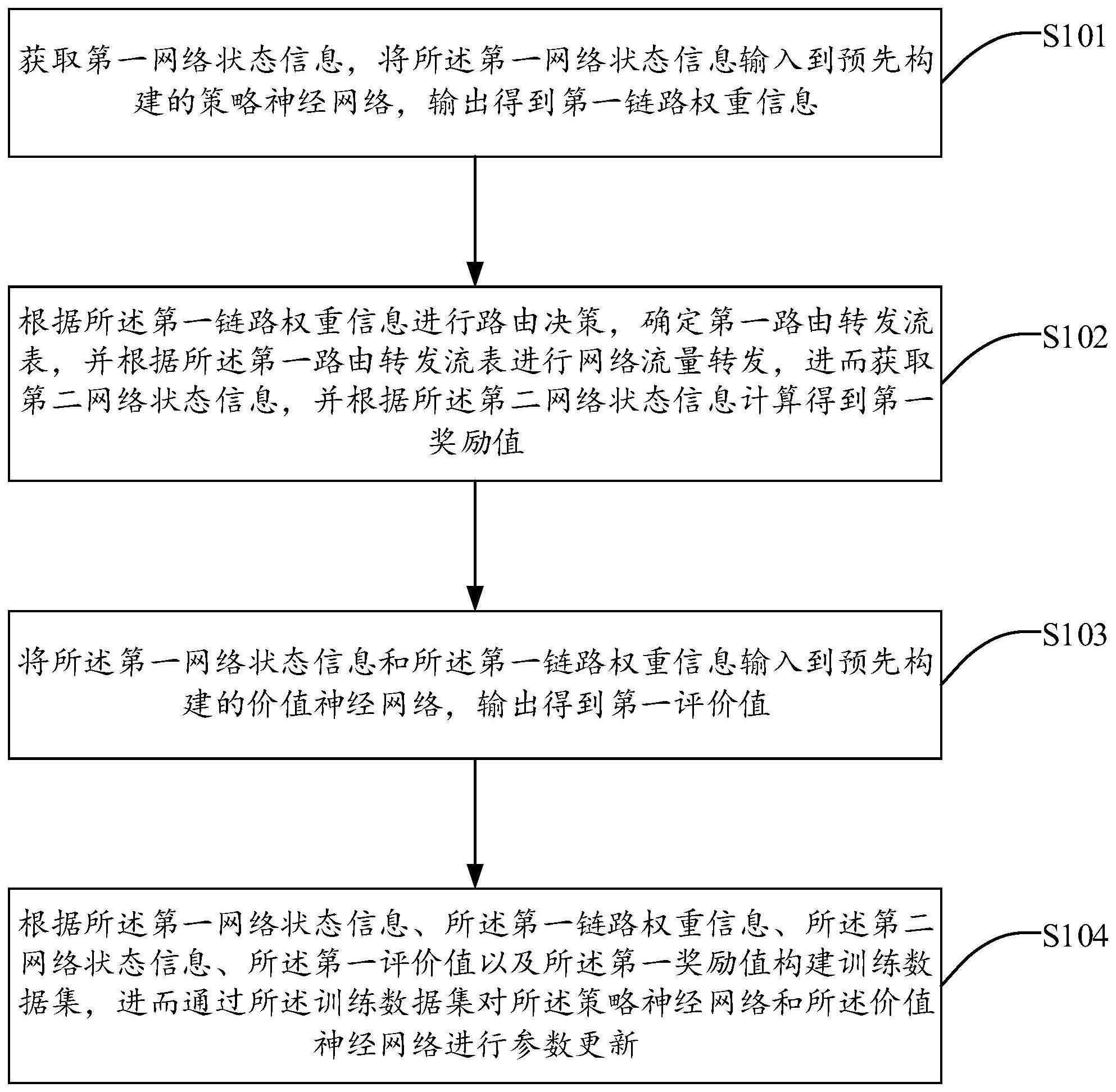
6、获取第一网络状态信息,将所述第一网络状态信息输入到预先构建的策略神经网络,输出得到第一链路权重信息;
7、根据所述第一链路权重信息进行路由决策,确定第一路由转发流表,并根据所述第一路由转发流表进行网络流量转发,进而获取第二网络状态信息,并根据所述第二网络状态信息计算得到第一奖励值;
8、将所述第一网络状态信息和所述第一链路权重信息输入到预先构建的价值神经网络,输出得到第一评价值;
9、根据所述第一网络状态信息、所述第一链路权重信息、所述第二网络状态信息、所述第一评价值以及所述第一奖励值构建训练数据集,进而通过所述训练数据集对所述策略神经网络和所述价值神经网络进行参数更新。
10、进一步地,在本发明的一个实施例中,所述获取第一网络状态信息这一步骤,其具体为:
11、通过sdn控制器获取各个网络链路的带宽利用率、各所述网络链路对应的两个交换机之间的传输时延以及各所述交换机的丢包率,根据所述带宽利用率、所述传输时延以及所述丢包率确定所述第一网络状态信息。
12、进一步地,在本发明的一个实施例中,所述根据所述第一链路权重信息进行路由决策,确定第一路由转发流表,并根据所述第一路由转发流表进行网络流量转发这一步骤,其具体包括:
13、根据所述第一链路权重信息确定各所述网络链路的链路权重;
14、根据所述链路权重通过floyd算法计算各所述交换机之间的加权最短路径,并根据所述加权最短路径确定所述第一路由转发流表;
15、通过所述sdn控制器将所述第一路由转发流表下发至所述交换机,使得所述交换机根据所述第一路由转发流表进行网络流量转发。
16、进一步地,在本发明的一个实施例中,所述获取第二网络状态信息,并根据所述第二网络状态信息计算得到第一奖励值这一步骤,其具体包括:
17、当所述交换机根据所述第一路由转发流表进行网络流量转发后,获取第二网络状态信息,所述第二网络状态信息包括更新后所述带宽利用率、所述传输时延以及所述丢包率;
18、根据更新后的所述带宽利用率、所述传输时延以及所述丢包率计算得到所述第一奖励值。
19、进一步地,在本发明的一个实施例中,所述通过所述训练数据集对所述策略神经网络和所述价值神经网络进行参数更新这一步骤,其具体包括:
20、根据所述训练数据集对所述价值神经网络的第一网络参数进行更新;
21、当所述第一网络参数的更新次数达到预设的第一阈值,根据所述训练数据集对所述策略神经网络的第二网络参数进行更新。
22、进一步地,在本发明的一个实施例中,所述根据所述训练数据集对所述价值神经网络的第一网络参数进行更新这一步骤,其具体包括:
23、将所述第二网络状态信息输入到所述策略神经网络,输出得到第二链路权重信息;
24、将所述第二网络状态信息和所述第二链路权重信息输入到所述价值神经网络,输出得到第二评价值;
25、根据所述第一评价值、所述第二评价值以及所述第一奖励值确定所述价值神经网络的第一损失值;
26、根据所述第一损失值利用梯度下降算法更新所述第一网络参数。
27、进一步地,在本发明的一个实施例中,所述根据所述训练数据集对所述策略神经网络的第二网络参数进行更新这一步骤,其具体包括:
28、将所述第一网络状态信息和所述第一链路权重信息输入到参数更新后的所述价值神经网络,输出得到第三评价值;
29、根据所述第三评价值利用梯度上升算法更新所述第二网络参数。
30、第二方面,本发明实施例提供了一种基于深度强化学习的智能路由决策系统,包括:
31、链路权重确定模块,用于获取第一网络状态信息,将所述第一网络状态信息输入到预先构建的策略神经网络,输出得到第一链路权重信息;
32、奖励值计算模块,用于根据所述第一链路权重信息进行路由决策,确定第一路由转发流表,并根据所述第一路由转发流表进行网络流量转发,进而获取第二网络状态信息,并根据所述第二网络状态信息计算得到第一奖励值;
33、评价值确定模块,用于将所述第一网络状态信息和所述第一链路权重信息输入到预先构建的价值神经网络,输出得到第一评价值;
34、网络参数更新模块,用于根据所述第一网络状态信息、所述第一链路权重信息、所述第二网络状态信息、所述第一评价值以及所述第一奖励值构建训练数据集,进而通过所述训练数据集对所述策略神经网络和所述价值神经网络进行参数更新。
35、第三方面,本发明实施例提供了一种基于深度强化学习的智能路由决策装置,包括:
36、至少一个处理器;
37、至少一个存储器,用于存储至少一个程序;
38、当所述至少一个程序被所述至少一个处理器执行时,使得所述至少一个处理器实现上述的一种基于深度强化学习的智能路由决策方法。
39、第四方面,本发明实施例还提供了一种计算机可读存储介质,其中存储有处理器可执行的程序,所述处理器可执行的程序在由处理器执行时用于执行上述的一种基于深度强化学习的智能路由决策方法。
40、本发明的优点和有益效果将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到:
41、本发明实施例结合深度强化学习技术来实现物联网中智能路由决策,基于深度强化学习的强大的感知能力和决策能力,来解决物联网中的路由决策问题。获取第一网络状态信息,将第一网络状态信息输入到预先构建的策略神经网络,输出得到第一链路权重信息,然后根据第一链路权重信息进行路由决策,确定第一路由转发流表,并根据第一路由转发流表进行网络流量转发,从而可以对网络中的流量转发进行精准控制;获取第二网络状态信息,并根据第二网络状态信息计算得到第一奖励值,将第一网络状态信息和第一链路权重信息输入到预先构建的价值神经网络,输出得到第一评价值,然后根据第一网络状态信息、第一链路权重信息、第二网络状态信息、第一评价值以及第一奖励值构建训练数据集,进而通过训练数据集对策略神经网络和价值神经网络进行参数更新,从而可以在下一次进行路由决策时提供更加精准的流量转发控制,实现了物联网海量数据流量的负载均衡,提高了物联网的网络性能。
- 还没有人留言评论。精彩留言会获得点赞!