基于深度学习的精细化帧内预测信号的视频编解码方法和装置与流程
本发明涉及基于深度学习的精细化帧内预测的预测的信号的视频编码方法和装置。
背景技术:
1、本部分中的陈述仅提供与本发明有关的背景技术信息,并不一定构成现有技术。
2、由于视频数据与音频数据或静止影像数据相比具有较大的数据量,视频数据需要大量的硬件资源(包括存储器)来存储或发送未经压缩处理的视频数据。
3、相应地,编码器通常用于压缩并存储或发送视频数据。解码器接收压缩的视频数据,解压接收到的压缩的视频数据,并且播放解压的视频数据。视频压缩技术包括h.264/avc、高效率视频编解码(high efficiency video coding,hevc)和多功能视频编解码(versatile video coding,vvc),所述多功能视频编解码(vvc)比hevc的编解码效率提高了大约30%或更多。
4、然而,由于影像大小、分辨率和帧速率逐渐增加,要编码的数据量也在增多。相应地,需要一种与现有的压缩技术相比提供更高的编解码效率和改善的影像增强效果的新的压缩技术。
5、对于要编码的视频中的当前块,在现有的帧内预测方法中,基于固定规则从相邻的重新配置的参考样本生成预测块,因此,可能难以生成复杂内容的预测块。此外,由于可以用作参考样本的信息量小于时间相邻信息量,帧内预测方法的编解码性能低于帧间预测方法的编解码性能。因此,可以使用滤波器或深度学习技术,以通过改进预测块来减少与原始块的差异信号。
6、作为利用滤波器的传统技术,存在利用固定规则生成当前块的预测块,然后利用滤波器对预测块进行滤波的方法。利用固定规则的帧内预测方法仅使用有限的信息,因此可能不适合如上所述处理复杂内容。例如,帧内预测的方向模式在选择的方向以外的方向上不使用参考样本。为了解决这个问题,可以对预测块应用滤波。然而,当利用固定滤波器执行滤波时,存在相邻参考样本和整个预测块的信息不能被考虑的问题。
7、作为其他技术,存在通过根据固定规则和滤波器替换帧内预测,利用深度学习技术,在接收相邻参考样本时生成预测块的帧内预测方法。这些技术提出了一种深度学习网络,用于利用相邻参考样本作为输入来生成精确的预测块。因此,基于深度学习的预测方法可以被添加为视频编解码装置中的帧内预测模式的一种,或者替换所有的帧内预测模式。然而,由于基于深度学习的预测方法没有根据现有的帧内预测来利用预测块的信息,存在生成的预测的信号可能不准确的问题。例如,根据现有帧内预测的方向模式生成的预测块是基于方向性来预测的,因此它可以用作当前块的近似结构性信息,但是基于深度学习的预测方法不利用这样的信息。
8、作为另一种技术,存在基于深度学习的预测方法,该方法使用方向模式下预测的相邻参考样本和块,同时利用深度学习技术。尽管除了参考样本之外,在利用预测块的信息方面存在精细化,但是该方法也具有不适应于与参考样本和预测块相关的信息以及需要额外的信号通知来指示该方法的应用的缺点。
9、因此,为了通过改进预测块来提高视频编解码效率并提供视频质量,利用基于深度学习的帧内预测方法,该方法同时使用相邻参考样本和预测块。此外,还需要考虑自适应地使用与参考样本和预测块相关的信息的方法。
技术实现思路
1、技术问题
2、本发明旨在提供一种视频编解码方法和装置,用于生成精细化的帧内预测的信号,以提高视频编解码效率和视频质量。视频编解码方法和装置可以将根据当前块的帧内预测的预测块、与当前块相关的块信息以及相邻重构的参考样本自适应地输入到深度学习网络中。
3、技术方案
4、本发明的至少一个方面提供了一种视频解码装置。视频解码装置包括熵解码器,其配置为从比特流解码当前块的信息和当前块的残差值。当前块的信息包括当前块的帧内预测模式、当前块的高度、宽度或纵横比、当前块的颜色、包括当前块的图像的类型以及当前块的量化参数。视频解码装置还包括帧内预测器,其配置为利用帧内预测模式从当前块周围的重构的参考样本生成当前块的预测块。视频解码装置还包括预测的信号精细化单元,其配置为基于当前块的信息的全部或一些自适应地选择基于深度学习的精细化模型,并且将包括预测块和重构的参考样本的输入块输入到选择的基于深度学习的精细化模型中,以生成精细化的预测块。视频解码装置还包括加法器,其配置为将残差值添加到精细化的预测块,以生成当前块的重构的块。
5、本发明的另一个方面提供了由视频解码装置执行的对当前块执行帧内预测的视频解码方法。视频解码方法包括从比特流解码当前块的信息和当前块的残差值。当前块的信息包括当前块的帧内预测模式、当前块的高度、宽度或纵横比、当前块的颜色、包括当前块的图像的类型以及当前块的量化参数。视频解码方法还包括利用帧内预测模式从当前块周围的重构的参考样本生成当前块的预测块。视频解码方法还包括基于当前块的信息的全部或一些自适应地选择基于深度学习的精细化模型,并且通过将包括预测块和重构的参考样本的输入块输入到选择的基于深度学习的精细化模型中来生成精细化的预测块。视频解码方法还包括通过将残差值添加到精细化的预测块来生成当前块的重构的块。
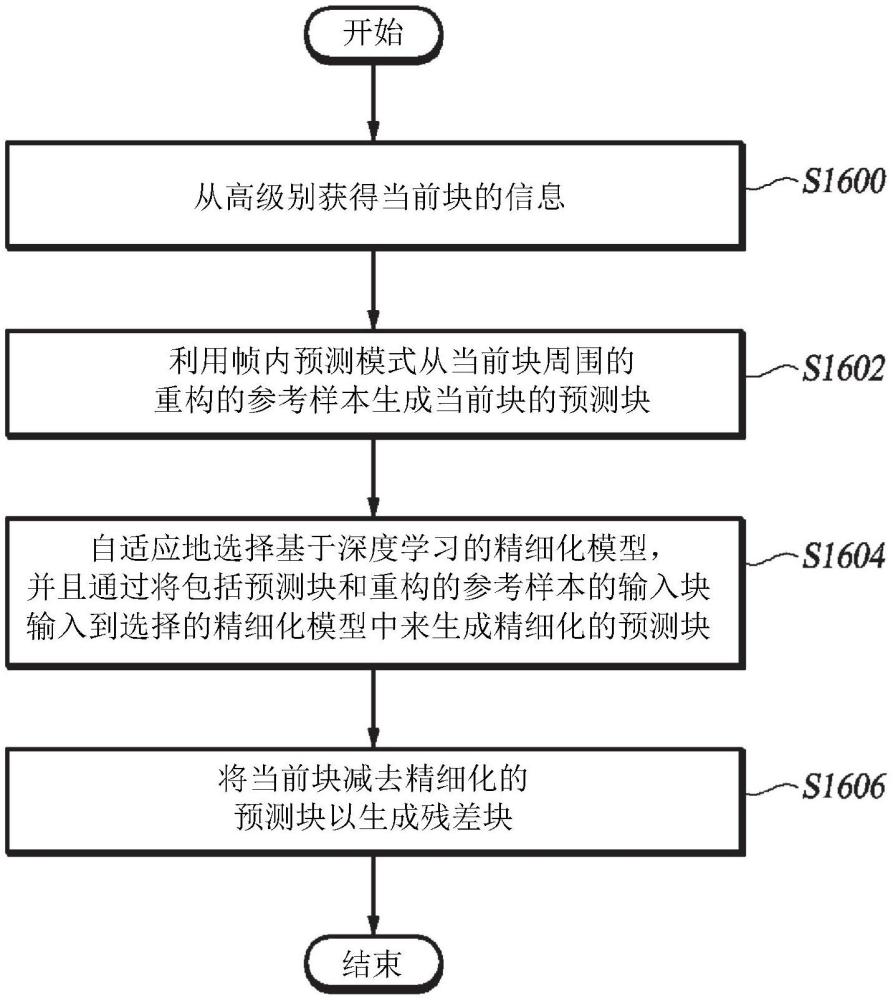
6、本发明的又一个方面提供了由视频解码装置执行的对当前块进行帧内预测的视频编码方法。视频编码方法包括从高级别获得当前块的信息。当前块的信息包括当前块的帧内预测模式、当前块的高度、宽度或纵横比、当前块的颜色、包括当前块的图像的类型以及当前块的量化参数。视频编码方法还包括利用帧内预测模式从当前块周围的重构的参考样本生成当前块的预测块。视频编码方法还包括基于当前块的信息的全部或一些自适应地选择基于深度学习的精细化模型,并且通过将包括预测块和重构的参考样本的输入块输入到选择的基于深度学习的精细化模型中来生成精细化的预测块。视频编码方法还包括通过将当前块减去精细化的预测块来生成残差块。
7、有益效果
8、如上所述,本发明提供了一种视频编解码方法和装置,通过将根据当前块的帧内预测的预测块、与当前块相关的块信息以及相邻重构的参考样本自适应地输入到深度学习网络中来生成精细化的帧内预测的信号。因此,视频编解码方法和装置可以提高视频编解码效率和视频质量。
技术特征:
1.一种视频解码装置,包括:
2.根据权利要求1所述的视频解码装置,其中,
3.根据权利要求1所述的视频解码装置,其中,
4.根据权利要求1所述的视频解码装置,其中,
5.根据权利要求1所述的视频解码装置,其中,
6.根据权利要求1所述的视频解码装置,其中,
7.根据权利要求1所述的视频解码装置,其中,
8.根据权利要求7所述的视频解码装置,其中,
9.根据权利要求7所述的视频解码装置,其中,
10.根据权利要求9所述的视频解码装置,其中,
11.根据权利要求7所述的视频解码装置,其中,
12.根据权利要求11所述的视频解码装置,其中,
13.根据权利要求7所述的视频解码装置,其中,
14.一种由视频解码装置执行的对当前块进行帧内预测的视频解码方法,所述视频解码方法包括:
15.一种由视频解码装置执行的对当前块进行帧内预测的视频编码方法,所述视频编码方法包括:
16.根据权利要求15所述的视频编码方法,其中,生成精细化的预测块包括:
17.根据权利要求15所述的视频编码方法,其中,生成精细化的预测块包括:
18.根据权利要求15所述的视频编码方法,其中,生成精细化的预测块包括:
19.根据权利要求15所述的视频编码方法,其中,基于深度学习的精细化模型是包括全连接层的深度学习网络,并且根据学习块的信息来预先进行自适应训练。
技术总结
公开了基于深度学习的精细化帧内预测信号的视频编解码方法和装置,并且为了增强视频编码的效率并提高视频质量,本实施方案提供了这样一种视频编解码方法和装置,其通过将相邻重构的参考样本、基于当前块的帧内预测的预测块以及与当前块相关的块信息自适应地输入到深度学习网络来生成精细化的帧内预测信号。
技术研发人员:姜制远,郑惠善,朴胜煜,许镇
受保护的技术使用者:现代自动车株式会社
技术研发日:
技术公布日:2024/3/12
- 还没有人留言评论。精彩留言会获得点赞!