一种基于DDPG的5G-TSN联合资源调度装置及方法
一种基于ddpg的5g-tsn联合资源调度装置及方法
技术领域
1.本发明涉及通信技术领域,特别涉及一种基于ddpg(deep deterministic policy gradient,深度确定性策略梯度算法)的5g-tsn(time sensitive networking,时间敏感网络)联合资源调度装置及方法。
背景技术:
2.时间敏感网络(tsn, time sensitive networking)是由ieee802.1 tsn任务组制定的一系列ieee802以太网标准。在工业互联网应用领域,由于工业现场网络传输的低时延要求和高可靠性要求,使得时间敏感网络成为该领域的研究热点之一。时间敏感网络具有确定时延保障和多业务承载能力,可用于实时确定性的、一定范围内的、低时延的工业通信,具有时间同步、延时保证等确保实时性的功能,也具有低抖动和极低数据包丢失率的功能,从而使得以太网能适用于高可靠性和低时延要求的时间敏感型应用场景。
3.5g r16定义了5g-tsn协同架构,5g整个网络包括终端、无线、承载和核心网,在tsn网络中作为一个透明的网桥。如图1所示为3gpp标准定义的5g-tsn网络架构模型。
4.为了与tsn网络进行适配,5gs(5g system)一方面新增了网元功能。控制面新增了tsn应用功能实体(tsn-af),使得5gs与tsn网络可以进行信息交互,同时tsn-af与5g核心网中策略控制功能(pcf, policy control function)、会话管理功能(smf, session management function)等实体的交互,实现tsn业务流关键参数在5g时钟下的修正与传递,实现qos(quality of service)保障;在用户面新增加了tsn转换器作为网关,包括设备侧的tsn转换器(ds-tt, device side tsn translator)和网络侧的tsn转换器(nw-tt, network side tsn translator)。它们同时支持ieee802.1as、802.1ab等协议,可以减少tsn协议转换对5g新空口造成过多影响。通过这两个网关,5g网络相关信息可以经过ds-tt和nw-tt提供tsn入口和出口端口传输到tsn网络,另外关于进行qos业务保障需要的5g qos配置信息也经由这两个网关传输到5g网桥。传输数据到达网关处队列后,根据网关处设置的周期性门控列表(gcl,gate control list),进行队列中缓存数据的传输。
5.另一方面,5g系统对原有的核心网元进行了功能增强,增强pcf策略控制功能实现对tsn业务的策略决策和下发/通知;增强接入及移动性管理功能(amf, access and management function)、smf、统一数据管理(udm, unified data manager)功能、upf等网元实现对tsn业务的pdu会话的管理,以及与ds-tt间的tsn参数和策略互通;增强upf实现 nw-tt与tsn业务网络间的tsn时钟同步,使得5g网络与tsn网络具备跨域业务参数交互(时间信息、优先级信息、包大小及间隔、流方向等)、端口及队列管理、qos映射等功能。
6.目前,现有技术主要存在以下问题:一方面,3gpp提出的5g-tsn架构,只定义了功能实体与网络架构。但实际上,5g-tsn会承载多业务的传输,除了时间敏感性业务外,还有5g业务,如视频流。当其同时到达基站时,如何对其调度是没有解决的。另一方面,在5g-tsn架构中,对于空口资源的调度不仅仅需要考虑无线信道状态、基站队列,还要考虑nw-tt与ds-tt的门控,结合门控配置情况,
对空口资源进行分配是一种更优策略。因为,当nw-ds-tt的门控是关的,即使基站对该时间敏感性业务进行调度,该业务也会在ds-tt进行等待。
技术实现要素:
7.本发明提供了一种基于ddpg的5g-tsn联合资源调度装置及方法,以解决多业务在5g-tsn协同传输架构上进行跨网传输的资源调度问题。
8.为解决上述技术问题,本发明提供了如下技术方案:一方面,本发明提供了一种基于ddpg的5g-tsn联合资源调度装置,适用于5g-tsn的网络设备,所述装置包括:状态信息采集模块,调度决策模块和配置模块,所述状态信息采集模块和配置模块均与所述调度决策模块相连;所述状态信息采集模块用于采集底层网络信息,并对采集的底层网络信息进行处理,得到状态信息,并将状态信息传输至所述调度决策模块;其中,所述底层网络信息包括信道信息、tsn域的门控列表信息和基站中的队列信息;所述调度决策模块使用基于ddpg的强化学习模型,根据所述状态信息采集模块输出的状态信息,得到决策结果,并将决策结果传输至所述配置模块;其中,所述决策结果包括是否为当前队列分配资源和当前队列实际分配的资源数目;所述配置模块用于将决策结果转换为基站能理解的指令,对基站进行配置。
9.进一步地,所述状态信息采集模块具体用于:采集底层网络信息,包括:dw-tt的门控状态、基站各用户队列的长度、队头的等待时延和5g系统中信道质量;对采集的底层网络信息进行处理,得到状态信息,包括:根据信道质量映射一个资源块能够承载的比特数目:其中,是接收当前队列的信道质量,表示一个资源块能够承载的比特数目,是映射函数;根据信道信息和队列信息计算每一个队列需要的资源数目:其中,表示队列的数据包大小,为队列的队长,表示队列需要的资源数目;对每一种业务设置截止时间,根据截止时间对时延进行归一化:其中,表示归一化后的等待时延,表示业务的截止时间,表示业务在基站
队列的等待时间;将得到的状态信息传输至所述调度决策模块;其中,所述状态信息包括各队列需要的资源数目、各队列长度、归一化后的等待时延以及门控状态。
10.进一步地,队列实际分配的资源数目由下式得到:其中,表示队列实际分配的资源数目,表示总资源数目,表示队列是否分配到资源,是基站中待调度的队列数目。
11.进一步地,当数据为视频流时,强化学习模型使用的奖励函数,为:对于时间敏感流,强化学习模型使用的奖励函数,为:其中,表示业务的截止时间,表示业务在基站队列的等待时间,
△
表示一个预设的正数;表示当前视频流所获得的平均吞吐量,表示视频流业务需要满足的最低平均吞吐量,是两个参数,分别用于调控门控开启或关闭下不同等待时间的业务奖励值,表示势函数。
12.另一方面,本发明还提供了一种基于ddpg的5g-tsn联合资源调度方法,适用于5g-tsn的网络设备,所述5g-tsn联合资源调度方法包括:采集底层网络信息,并对采集的底层网络信息进行处理,得到状态信息;其中,底层网络信息包括信道信息、tsn域的门控列表信息和基站中的队列信息;使用基于ddpg的强化学习模型,根据所述状态信息,得到决策结果;其中,所述决策结果包括是否为当前队列分配资源和当前队列实际分配的资源数目;将决策结果转换为基站能理解的指令,对基站进行配置。
13.进一步地,所述采集底层网络信息,并对采集的底层网络信息进行处理,得到状态
信息,包括:采集底层网络信息,包括:dw-tt的门控状态、基站各用户队列的长度、队头的等待时延和5g系统中信道质量;对采集的底层网络信息进行处理,得到状态信息,包括:根据信道质量映射一个资源块能够承载的比特数目:其中,是接收当前队列的信道质量,表示一个资源块能够承载的比特数目,是映射函数;根据信道信息和队列信息计算每一个队列需要的资源数目:其中,表示队列的数据包大小,为队列的队长,表示队列需要的资源数目;对每一种业务设置截止时间,根据截止时间对时延进行归一化:其中,表示归一化后的等待时延,表示业务的截止时间,表示业务在基站队列的等待时间;最终得到状态信息;其中,所述状态信息包括各队列需要的资源数目、各队列长度、归一化后的等待时延以及门控状态。
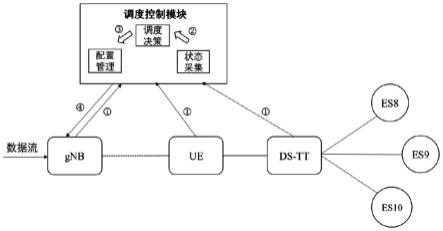
14.进一步地,队列实际分配的资源数目由下式得到:其中,表示队列实际分配的资源数目,表示总资源数目,表示队列是否分配到资源,是基站中待调度的队列数目。
15.进一步地,当数据为视频流时,强化学习模型使用的奖励函数,为:
对于时间敏感流,强化学习模型使用的奖励函数,为:其中,表示业务的截止时间,表示业务在基站队列的等待时间,
△
表示一个预设的正数;表示当前视频流所获得的平均吞吐量,表示视频流业务需要满足的最低平均吞吐量,是两个参数,分别用于调控门控开启或关闭下不同等待时间的业务奖励值,表示势函数。
16.再一方面,本发明还提供了一种电子设备,其包括处理器和存储器;其中,存储器中存储有至少一条指令,所述指令由处理器加载并执行以实现上述方法。
17.又一方面,本发明还提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令,所述指令由处理器加载并执行以实现上述方法。
18.本发明提供的技术方案带来的有益效果至少包括:本发明针对5g-tsn架构下,对基站空口处多业务流调度这一问题提出了一种基于强化学习的多业务的空口调度策略。实现了ds-tt门控状态与基站调度的联动,保障了时间敏感业务的时延要求,并提高了其他业务传输吞吐量。
附图说明
19.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
20.图1是3gpp定义的5g tsn网络架构示意图;图2是本发明实施例提供的基于ddpg的下行链路资源调度网络模块示意图;图3是本发明实施例提供的ddpg算法示意图;图4是本发明实施例提供的信道质量与资源承载量的关系示意图;图5是本发明实施例提供的与等待时间的关系示意图;图6是本发明实施例提供的ds-tt门控状态设置示意图;图7是本发明实施例提供的算法训练过程示意图;其中,(a)为算法输出动作对应的平均奖励值随着算法训练的变化示意图,(b)为执行算法输出的动作得到的时间敏感业
务的端到端时延随着算法训练的变化示意图;图8是三种算法对比示意图;其中,(a)为在比例公平(pf)、最早截止时间优先(edf)和基于ddpg算法下,随着用户数目的增多,时间敏感业务的平均时延的变化示意图,(b)为在pf、edf和基于ddpg算法下,随着用户数目的增多,系统吞吐量的变化示意图。
具体实施方式
21.为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
22.第一实施例在数据进行5g-tsn跨网传输时,需要经过端口网关ds-tt,待传输数据暂时缓存在端口网关队列内。基站在调度时不仅要考虑时间敏感业务的时延要求、信道传输质量等信息,同时要考虑不影响其他业务传输的吞吐量,还需要考虑ds-tt处门控列表gcl的门控状态。基于此,本实施例提供了一种在考虑ds-tt状态下,基于强化学习ddpg的5g-tsn联合资源调度机制,该调度机制可以保障时间敏感业务的时延要求,同时一定程度上提高其他业务的吞吐量。
23.基于上述,本实施例设计了基于ddpg的下行链路资源调度控制模块(scnm)。scnm包括状态采集模块,调度决策模块和配置管理模块,其连接方式如图2所示,scnm与5g-tsn的网络设备相连,状态采集模块和配置管理模块分别与调度决策模块相连,调度决策模块用于根据收集的状态信息做出决策,并将决策结果发送给配置管理模块,对基站统一配置。各模块具体的功能说明如下:状态信息采集模块:用于底层网络信息的采集,包括:信道信息、tsn域的门控列表信息、基站中的队列信息等。
24.调度决策模块:调度决策模块使用ddpg算法确定决策,该算法模块由critic网络和actor网络组成,输入是状态,输出是动作,即决策,如图3所示。调度决策模块分为线下训练和线上执行过程。训练过程critic网络和actor网络均参与,执行过程,只有actor网络参与。
25.配置管理模块:基于调度决策模块得到的全局优化结果,将决策结果转换为基站能理解的消息命令,对基站进行统一配置。
26.进一步地,本实施例的scnm实现决策的具体流程如下:s1,tsn的dw-tt和5g基站、ue向scnm上传状态信息s,包括:dw-tt的门控状态、基站各用户队列的长度、队头的等待时延和5g系统中信道质量。
27.s2,状态采集模块将上述信息进行处理并发送给调度决策模块。处理过程:s21,根据信道质量映射一个资源块能够承载的比特数目:其中,是接收当前队列的信道质量,表示一个资源块能够承载的比特数目,是映射函数,如图4所示。
28.s22,根据信道信息和队列信息计算每一个队列需要的资源数目:
其中,表示队列的数据包大小,为队列的队长,表示队列需要的资源数目;s23,对每一种业务设置截止时间,根据截止时间对时延进行归一化:其中,表示归一化后的等待时延,表示业务的截止时间,表示业务在基站队列的等待时间;s24,得到处理后的状态信息。
29.s3,调度决策模块根据状态采集模块处理后的信息进行决策。决策流程分为线下训练流程和线上执行流程,现具体说明如下:1、调度决策模块线下训练流程:1)数据集产生过程:a)调度决策模块接收传来的时刻的状态信息,并根据初始化的网络参数输出决策,网络输出的决策只有0与1两个值,即,其中,是基站中待调度的队列数目。0表示该队列不分配资源,1表示分配资源。队列实际分配的资源数目由下式得到:其中,表示总资源数目,表示队列是否分配到资源。
30.b)在执行动作和分配资源数目后,下式为初始的奖励函数:上述函数是各业务的截止时间减去业务在基站队列的等待时间加上一个较小的正数的倒数。这一函数的目的是为了让各业务在尽可能离截止时间近的时候发送。既保障时延满足截止时间的要求,又给时间敏感业务外的其他业务空余了大量的传输时间。此外,对于非时间敏感性业务会有吞吐量约束,当非时间敏感业务的吞吐量不满足下式时,会导
致奖励函数为0,因此算法输出的动作会尽量保证吞吐量满足约束,此时存在大于0的奖励值,而不是接近截止时间——此时奖励极有可能是0。
31.其中,,是5g的调度时隙间隔因此对于视频流的奖励函数,相应变为,进一步的,对于时间敏感流,需要考虑ds-tt的门控状态,因此,构造势函数来体现不同的等待时延时,门控的状态的重要程度。势函数中的参数如图5所示,对于时间敏感业务的奖励值首先与ds-tt的门控有关,当门控为开时,此时调度时间敏感业务获得的奖励值,此外,当离截止时间越远时,奖励值较小反之越大,因此构造奖励函数,如下式其中,表示业务的截止时间,表示业务在基站队列的等待时间,
△
表示一个预设的正数;表示当前视频流所获得的平均吞吐量,表示视频流业务需要满足的最低平均吞吐量,是两个参数,分别用于调控门控开启或关闭下不同等待时间的业务奖励值,表示势函数。
32.综上,c)当执行动作后,环境会进入到下一个状态,因此,会得到一组训练集,重复此过程,会得到多组数据集。
33.2)基于ddpg算法的调度决策模块训练过程:ddpg结构如图3所示,包括critic网络和actor网络。actor网络作用是根据环境的状态输出动作,critic网络是对actor输出的动作打分。ddpg在训练时,会对critic和actor均进行训练。训练actor的目的是使actor输出的动作更“迎合”critic,能够让critic打高分,训练critic的目的是使critic对动作打分更接近实际值。训练过程如下:a)输入一组状态转移集
b)critic网络根据时刻的状态对做出的动作打分,得分记为。
34.c)actor网络根据t+1时刻的状态输出动作,然后,critic网络对打分,得分记为。
35.d)根据bellman公式,求误差:e)使用梯度下降法更新critic网络:f)使用梯度上升法更新actor网络:2、调度决策模块线上预测流程:线下ddpg模型训练收敛后保存模型参数。调度决策模块在线上执行的时候,导入保存的模型,然后,使用actor模块输出动作后,调度决策模块将所做出决策结果发送给配置管理模块。
36.s4,配置管理模块将收到的决策转化为网络交换设备能理解的消息命令,并发送给基站。
37.下面,采用仿真的方式对本实施例调度策略的有效性进行说明。
38.对数据源模型、无线信道模型和门控状态进行设置:数据包产生服从0-1分布,其中概率p是0.5,产生的数据包服从1-3的均匀分布。
39.无线信道的衰减服从瑞利分布,另外,用户和基站的增加或减少的概率服从概率是0.5的0-1分布。
40.门控的状态如图6所示.基于此流程进行仿真,仿真结果如下。
41.图7中的(a)表明,随着ddpg模型的不断训练,所有用户每期的平均奖励逐渐增加,经过约230个训练片段后,奖励的波动减小,最终收敛在1.6 ~ 1.8之间。图7中的(b)展示了基于ddpg模型的资源调度决策的时间敏感流的时延要求。根据设计的奖励函数,如果时间敏感流的5g系统时延超过emlr,则相关的奖励为负,这使得agent避免指向这些负奖励的动作。另一方面,如果5g系统延迟更接近但不超过时间敏感流的emlr,则可以获得更多奖励。这就是为什么时敏流的5g系统延迟在训练开始时很低,在接近80集之前不断增加,并逐渐收敛到4ms的原因。
42.由图8的(a)可以看出,edf对时敏流的性能最好,因为视频的emlr比tsn的时敏流的emlr要大得多,因此时敏流的延迟更接近截止日期,所以时敏流的调度优先级最高。然而,pf算法更关心的是实现的数据速率,而不是延迟的保证。因此,带pf的5g系统时延随着终端数的增加而增大,当终端数达到16时,5g系统时延甚至超过emlr 6ms。基于ddpg的资源
调度算法具有比pf更好的时延保证性能,随着终端数量的增加,使用ddpg的5g系统时延几乎保持在4ms左右,高于edf,但仍能满足时敏流的emlr。
43.与时间敏感流不同,视频流更关心吞吐量。多流量共存场景下的系统吞吐量性能如图8中的(b)所示。edf倾向于调度时间敏感的流,这意味着更少的可用资源用于视频流。因此使用edf的吞吐量随着终端数量的增加而下降。然而,无论是ddpg还是pf调度算法,吞吐量都随着终端数量的增加而增加。由于设计了奖励函数,基于ddpg的调度算法为视频流提供了更多的调度机会,对时间敏感的流的时延要求较低,因此,基于ddpg的调度算法性能最好,吞吐量比pf提高了近0.05%。
44.由上可知,本实施例提出的基于ddpg的下行链路资源调度控制策略满足了强实时性业务的时延要求,同时提高了系统的吞吐量。
45.综上,本实施例针对5g-tsn架构下,对基站空口处多业务流调度这一问题提出了一种基于强化学习的业务调度模块(scnm模块)。实现了ds-tt门控状态与基站调度的联动,提出一种基于强化学习的多业务的空口调度策略,保障了时间敏感业务的时延要求,提高了其他业务传输吞吐量。
46.第二实施例本实施例提供一种电子设备,其包括处理器和存储器;其中,存储器中存储有至少一条指令,所述指令由处理器加载并执行,以实现第一实施例的策略。
47.该电子设备可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上处理器(central processing units,cpu)和一个或一个以上的存储器,其中,存储器中存储有至少一条指令,所述指令由处理器加载并执行上述策略。
48.第三实施例本实施例提供一种计算机可读存储介质,该存储介质中存储有至少一条指令,所述指令由处理器加载并执行,以实现上述策略。其中,该计算机可读存储介质可以是rom、随机存取存储器(ram)、cd-rom、磁带、软盘和光数据存储设备等。其内存储的指令可由终端中的处理器加载并执行上述策略。
49.此外,需要说明的是,本发明可提供为方法、装置或计算机程序产品。因此,本发明实施例可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本发明实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质上实施的计算机程序产品的形式。
50.本发明实施例是参照根据本发明实施例的方法、终端设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、嵌入式处理机或其他可编程数据处理终端设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理终端设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
51.这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理终端设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方
框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理终端设备上,使得在计算机或其他可编程终端设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程终端设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
52.还需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的相同要素。
53.最后需要说明的是,以上所述是本发明优选实施方式,应当指出,尽管已描述了本发明优选实施例,但对于本技术领域的技术人员来说,一旦得知了本发明的基本创造性概念,在不脱离本发明所述原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明实施例范围的所有变更和修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1