天基语义通信的知识库同步方法、系统及计算机可读介质
本发明主要涉及卫星通信领域,具体地涉及一种天基语义通信的知识库同步方法、系统及计算机可读介质。
背景技术:
1、卫星移动通信系统因其覆盖范围广、通信距离远等优点,已成为现代通信方式的重要组成部分。但与地面通信相比,卫星通信带宽较低,通信时延较长,随着通信业务数据量越来越大,卫星通信急需一种新的通信范式来提高其传输能力。由于语义通信可以将传输速率的要求大幅降低,将语义通信融入卫星通信成为一种新的研究热点。语义通信的核心是语义知识库,语义通信的发送端用户和接收端用户需要具备相同或者相似的语义知识库。
2、现有语义通信方式中,语义的定义信息受到预定义标签数据库的限制,因此语义知识库单一且固定,当遇到未知知识无法实现编解码时会出现通信双方无法通信的情况。为解决这一问题,专利文献cn114490920a提出一种语义知识库自动构建与更新方法,通过一种模型自动学习和更新的机制,将语义编解码器同时协同对语义知识库进行更新,实现高动态的语义通信。但是该方法在实现语义编解码器同时协同更新的过程中,需要接收方频繁通过语义评估器向发送方传递评估得分,发送方再根据该得分进行模型更新,该过程需要通信双方不断频繁通信,这对于卫星通信是不现实的。通常卫星在其轨道上相对地面高速运动,对于地面某通信端来说,一颗卫星的可见时间不长,若在卫星可见范围内发现需要更新语义知识库,则将花费大量时间进行模型更新,这与将语义通信应用于天基通信场景的目的背道而驰。另外,专利文献cn114490920a提出的方法在发送端更新模型直至模型收敛后,需要将更新好的模型发送给接收端才能继续通信,这额外增加了天基语义通信的开销,并且接收端丧失原有知识库,增加了与其他发送端通信时知识库需要更新的概率。
3、现有更新语义知识库的方式有基于联邦学习的方法。按数据来源不同,联邦学习可分为横向联邦学习、纵向联邦学习及联邦迁移学习。横向联邦学习适用于数据样本空间相似但数据特征空间不同的情况,纵向联邦学习适用于数据样本空间不同但特征空间相似的情况,联邦迁移学习则适用于数据样本空间和特征空间均不相似的情况。按网络架构不同,联邦学习可分为中心化联邦和去中心化联邦。针对联合多方用户的联邦学习场景,一般采用的是中心化联邦架构,企业作为服务器,起着协调全局模型的作用。而针对联合多家面临数据孤岛困境的企业进行模型训练的场景,一般可以采用去中心化联邦架构,因为难以从多家企业中选出进行协调的服务器方。目前联邦学习的研究主要集中在中心化联邦架构,然而由于卫星集群内没有可以和所有卫星长期相连的节点,因此无法采用中心化联邦架构来更新语义知识库。
4、此外,由于卫星绕地球运转,参与通信的卫星数量和地面终端数量庞大,为克服不同语义知识背景下的通信节点间的语义通信问题,每个通信节点需要储存多个语义知识库,且参与通信的节点越多,需储存的语义知识库越多,而卫星存储能力有限,无法存储大量语义知识库。因此,目前在天基语义通信的过程中,通信双方面临着语义知识库更新频率较高、通信开销大、需要频繁交换语义知识库、语义知识库更新耗时长、语义知识库通用性不高等诸多问题。
技术实现思路
1、本技术所要解决的技术问题是提供一种天基语义通信的知识库同步方法、系统及计算机可读介质,可以降低卫星通信系统中通信双方语义知识库更新频率,节约语义知识库同步所需的时间及带宽资源。
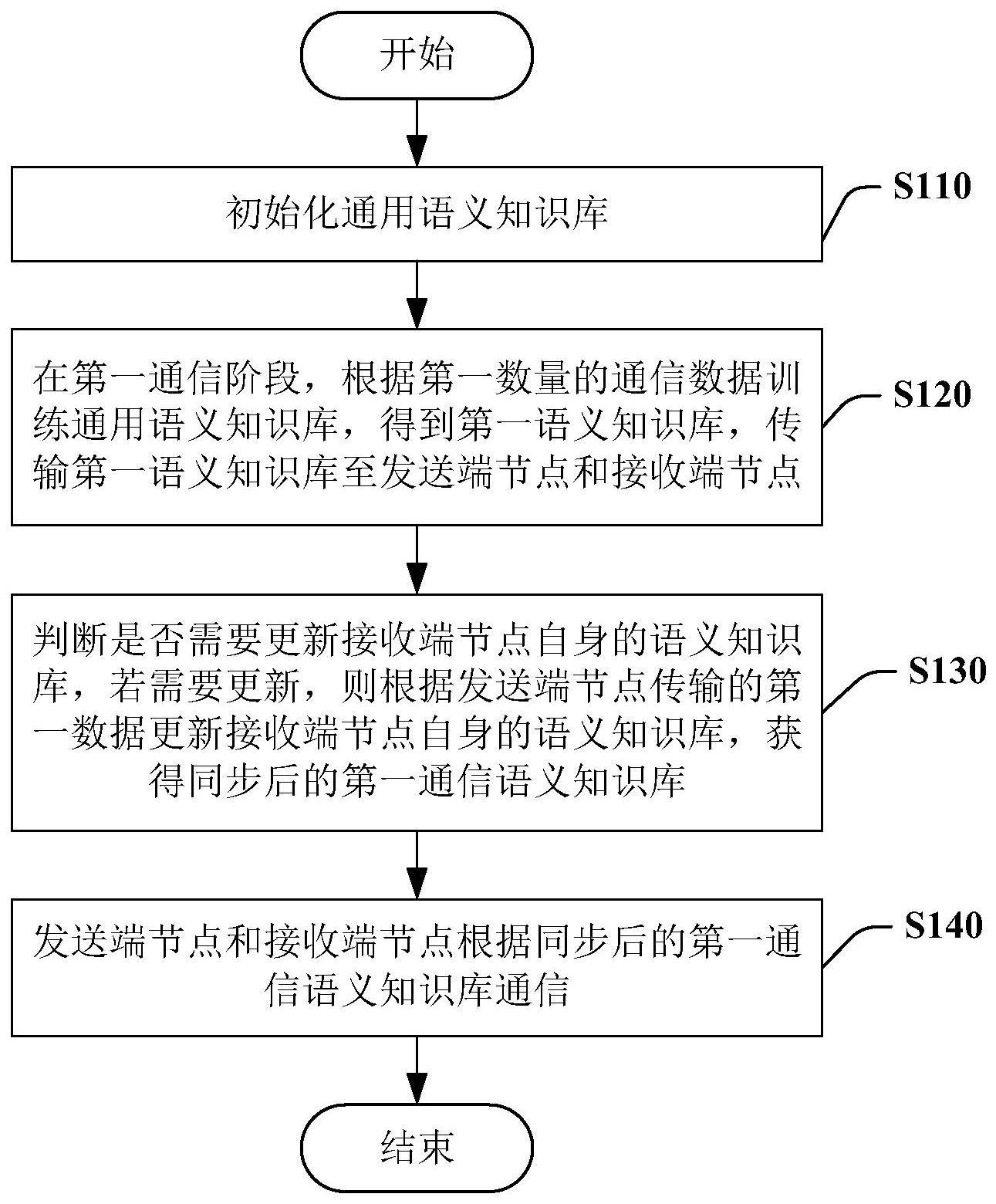
2、本技术为解决上述技术问题而采用的技术方案是一种天基语义通信的知识库同步方法,包括:初始化通用语义知识库;在第一通信阶段,根据第一数量的通信数据训练通用语义知识库,得到第一语义知识库,传输第一语义知识库至发送端节点和接收端节点;判断是否需要更新接收端节点自身的语义知识库,若需要更新,则根据发送端节点传输的第一数据更新接收端节点自身的语义知识库,获得同步后的第一通信语义知识库;发送端节点和接收端节点根据同步后的第一通信语义知识库通信。
3、在本技术的一实施例中,在发送端节点和接收端节点根据同步后的第一通信语义知识库通信的步骤之后,还包括:判断通信数据的数据量是否达到预设阈值,若达到预设阈值,则在第二通信阶段,根据第二数量的通信数据训练通用语义知识库,得到第二语义知识库,传输第二语义知识库至发送端节点和接收端节点,其中,第二数量大于第一数量;发送端节点根据联邦学习方法更新自身的语义知识库,得到联邦语义知识库;传输联邦语义知识库至接收端节点;发送端节点和接收端节点根据联邦语义知识库通信。
4、在本技术的一实施例中,地面训练端在发送端节点和接收端节点通信过程中持续收集通信数据,由地面训练端训练通用语义知识库,地面训练端通过掩码控制通用语义知识库的大小,从第一通信阶段至第二通信阶段训练通用语义知识库的过程中,逐渐减小掩码中0的比例,以逐渐增大通用语义知识库。
5、在本技术的一实施例中,判断是否需要更新接收端节点自身的语义知识库的步骤包括:发送端节点传输k条第一数据至接收端节点,k为大于等于1的正整数,第一数据包括源数据和源数据对应的经过语义编码的语义表示;根据语义表示解码接收端节点自身的语义知识库,接收端节点自身的每个语义知识库获得k条解码数据,针对第i个知识库版本,计算k条解码数据和源数据的平均相似性分数average_s imilarityi;使用下面的公式计算平均相似性分数的最大值score:
6、score=max(average_s imilarityi,i∈[1,m])
7、其中,m表示接收端节点自身的语义知识库的版本数量;
8、使用下面的公式计算平均相似性分数的最大值score对应的语义知识库的版本编号index:
9、index=argmax(average_s imilarityi,i∈[1,m])
10、判断平均相似性分数的最大值score是否达到预设相似性门限值,若未达到预设相似性门限值,需要更新接收端节点自身的语义知识库;若达到预设相似性门限值,根据版本编号index的语义知识库通信。
11、在本技术的一实施例中,根据发送端节点传输的第一数据更新接收端节点自身的语义知识库的步骤包括:接收端节点使用k条第一数据对版本编号index的语义知识库进行迁移训练。
12、在本技术的一实施例中,判断是否需要更新接收端节点自身的语义知识库的步骤包括:计算发送端节点的更新幅度αt以及计算接收端节点的更新幅度αr;分别判断发送端节点的更新幅度αt以及接收端节点的更新幅度αr是否大于预设更新阈值,若αt和αr均不大于预设更新阈值,根据已有语义知识库通信;若αt和/或αr大于预设更新阈值,需要更新接收端节点自身的语义知识库;发送端节点传输k条第一数据至接收端节点,k为大于等于1的正整数,第一数据包括源数据和源数据对应的经过语义编码的语义表示。
13、在本技术的一实施例中,计算发送端节点的更新幅度αt的步骤包括:将需发送数据使用第一通信阶段中的语义知识库副本进行编码,得到需发送数据的语义表示sold,输入语义表示sold及其对应的源数据至虚拟解码器,取虚拟解码器中softmax层的输出的平均值作为语义表示sold对应的源数据的相似性分数similarity_t,使用下面的公式计算发送端节点的更新幅度αt:
14、
15、其中,x为超参数;
16、以及,计算接收端节点的更新幅度αr的步骤包括:在通信过程中每隔一预设时长就随机存储一次收到的语义表示ct,构建测试集c={ct,t=0,...,j},其中,t_total为一次通信持续的时长,t为预设时长;在测试集c中随机选择一个语义表示ct,使用动态更新的语义知识库解码语义表示ct,获得语义表示ct的源数据cnew;使用第一通信阶段中的语义知识库副本解码语义表示ct,获得语义表示ct的源数据cold;计算源数据cnew及源数据cold的相似性分数similarity_r,使用下面的公式计算接收端节点的更新幅度αr:
17、
18、在本技术的一实施例中,根据发送端节点传输的第一数据更新接收端节点自身的语义知识库的步骤包括:使用下面的公式计算训练学习率α:
19、α=max(αt,αr)
20、其中,αt表示发送端节点的更新幅度,αr表示接收端节点的更新幅度αr;接收端节点将k条源数据作为标签,将k条语义表示作为输入,根据训练学习率α对语义知识库进行迁移训练。
21、在本技术的一实施例中,根据第一数量的通信数据训练通用语义知识库的步骤包括:构建包括发送端编码器和接收端解码器的端到端训练框架,端到端训练框架使用transformer机制;输入训练源数据s至发送端编码器,获得训练源数据s对应的语义表示;接收端解码器解码训练源数据s对应的语义表示,输出解码后的训练源数据以及获得训练好的端到端训练框架;输入第一数量的通信数据至训练好的端到端训练框架,将初始源数据及解码后的源数据的交叉熵作为loss函数更新发送端编码器、接收端解码器分别使用的语义知识库参数。
22、在本技术的一实施例中,第二数量的通信数据的数据结构包括:起始符、通信方名字、分隔符、数据、结束符,其中通信方名字包括发送端节点名字、接收端节点名字,数据为未进行语义编码的源数据。
23、在本技术的一实施例中,发送端节点根据联邦学习方法更新自身的语义知识库的步骤包括:所有发送端节点互相交换各自的语义知识库,直到每个发送端节点均获得除自身外其他发送端节点经过y次迭代后的语义知识库,其中y为大于等于1的正整数;每个发送端节点使用聚合算法合并自身的所有语义知识库。
24、在本技术的一实施例中,发送端节点i的联邦语义知识库需更新t轮,i和t为大于等于1的正整数,在第t轮联邦语义知识库更新过程中,发送端节点i在t+1时刻获得语义知识库的模型参数的步骤包括:步骤s1:发送端节点i在t时刻迭代自身的语义知识库的模型参数包括:构建包括虚拟发送端和虚拟接收端的端到端语义知识库自更新框架;端到端语义知识库自更新框架经过y次迭代下面的公式计算模型参数
25、
26、其中,η表示更新率,表示求梯度的运算符,l(·)表示loss函数,b表示训练数据集;步骤s2:发送端节点i将自身编号i加入自身的语义知识库名称列表listi,以及向其他发送端节点传输语义知识库名称列表listi;步骤s3:发送端节点i接收其他发送端节点j传输的语义知识库名称列表listj,j∈ni,ni表示其他发送端节点的集合;以及向发送端节点j传输语义知识库名称列表listi中除去语义知识库名称列表listj中包括的语义知识库以外的所有语义知识库信息,语义知识库信息的数据结构包括:知识库名称l、语义知识库本轮迭代使用的数据量bl、语义知识库参数步骤s4:当其他发送端节点j发生切换或语义知识库名称列表listi的内容发生变化时,重复步骤s2至步骤s3直至语义知识库名称列表listi已包括所有发送端节点;发送端节点i将自身编号i加入自身的确认信息列表list_acki,以及向其他发送端节点j传输确认信息列表list_acki;接收其他发送端节点j传输的确认信息ackj并存储至确认信息列表list_acki;步骤s5:当确认信息列表list_acki包括了所有发送端节点的确认信息时,使用下面的公式聚合所有语义知识库,获得联邦语义知识库z:
27、
28、其中,n表示所有语义知识库的数量。
29、本技术为解决上述技术问题还提出一种天基语义通信的知识库同步系统,包括:存储器,用于存储可由处理器执行的指令;处理器,用于执行指令以实现如上的天基语义通信的知识库同步方法。
30、本技术为解决上述技术问题还提出一种存储有计算机程序代码的计算机可读介质,计算机程序代码在由处理器执行时实现如上的天基语义通信的知识库同步方法。
31、本技术的技术方案通过初始化的方式生成自定义大小的通用语义知识库;在第一通信阶段,基于第一数量的通信数据训练通用语义知识库,得到第一语义知识库并将其传输至发送端节点和接收端节点,通信双方可以基于该语义知识库通信;通过判断是否需要更新接收端节点自身的语义知识库来决定更新频率,若判断为需要更新,则接收端节点基于发送端节点传输的第一数据更新自身的语义知识库,通信双方根据同步后的第一通信语义知识库通信;若判断为不需要更新,则通信双方根据各自已有的语义知识库通信。本技术这样设置,在能够保证通信的前提下,可以降低通信双方语义知识库的更新频率、降低通信开销、节约语义知识库同步所需的时间及带宽资源;接收端节点自己更新自身的语义知识库,避免需要通信双方交换语义知识库的情况,语义知识库的更新耗时较低,可通信时段内供数据通信的时间更长。
- 还没有人留言评论。精彩留言会获得点赞!