一种正负样本比例不平衡条件下的DGA域名检测方法与流程
本发明涉及互联网网络安全,尤其涉及一种正负样本比例不平衡条件下的dga域名检测方法。
背景技术:
1、恶意攻击者通常使用木马或僵尸程序来感染主机并组建僵尸网络,为后续开展ddos攻击、apt窃密攻击等恶意行为创造有利条件,为了控制僵尸网络,攻击者通常使用域名生成算法快速产生大量域名,并根据实际需求在域名服务商处注册其中某些域名,在利用僵尸网络发动攻击时,木马程序将根据事先设定好的算法查询dga域名来找到与控制服务器相对应的ip地址进而建立通信信道。实践证明,利用上述方式可以有效避开安全设备的追踪拦截,大幅提升安全研究人员的阻断代价,因此对于dga域名的检测、追踪以及封堵技术的研究成为当前网络安全领域的热点课题。
2、以采用的技术来划分,dga域名的检测工作主要经历了基于逆向过程的分析检测、基于机器学习技术的检测和基于深度学习技术的检测三个阶段。2016年,woodbridge等人率先将长短期记忆(long short-termmemory,lstm)网络应用于gda域名检测,该模型利用lstm层自动化提取字符词向量中的时序特征,在检测效率和精确率、召回率等指标方面明显优于基于统计特征和字符分布特征的隐马尔可夫模型和随机森林模型。qiao等人将全局注意力机制与lstm网络相结合用于dga域名的检测,在数量较少的dga域名样本上相较于对比模型有着不错的检测效果。此外,还有很多基于lstm网络的变种模型被用于dga域名的检测任务。
3、当前针对dga域名的检测技术已经实现了检测流程自动化,而且检测结果也有着较高的准确率,但是也面临着诸多新的挑战,具体表现为现有模型在网络搭建和选择算法的时候并没有充分考虑正常网络流量中dga域名与合法域名正负样本比例不平衡的问题,这将导致训练好的模型在真实的网络流量和训练数据上的表现有着明显差距。
技术实现思路
1、本发明提供了一种正负样本比例不平衡条件下的dga域名检测方法,目的是为了解决现有技术中存在的缺点。
2、为了实现上述目的,本发明提供如下技术方案:一种正负样本比例不平衡条件下的dga域名检测方法,包括如下步骤:
3、获取正样本的dga域名数据与负样本的alexa合法域名数据;
4、将所述dga域名数据与alexa合法域名数据进行预处理,并将预处理好的域名字符串按不同比例随机划分得到数据集;
5、构建损失敏感注意力bilstm分类模型;
6、将数据集中的数据输入损失敏感注意力bilstm分类模型进行训练;
7、获取待检测域名,将待检测域名输入训练好的损失敏感注意力bilstm分类模型,得到待检测域名属于dga域名的概率;
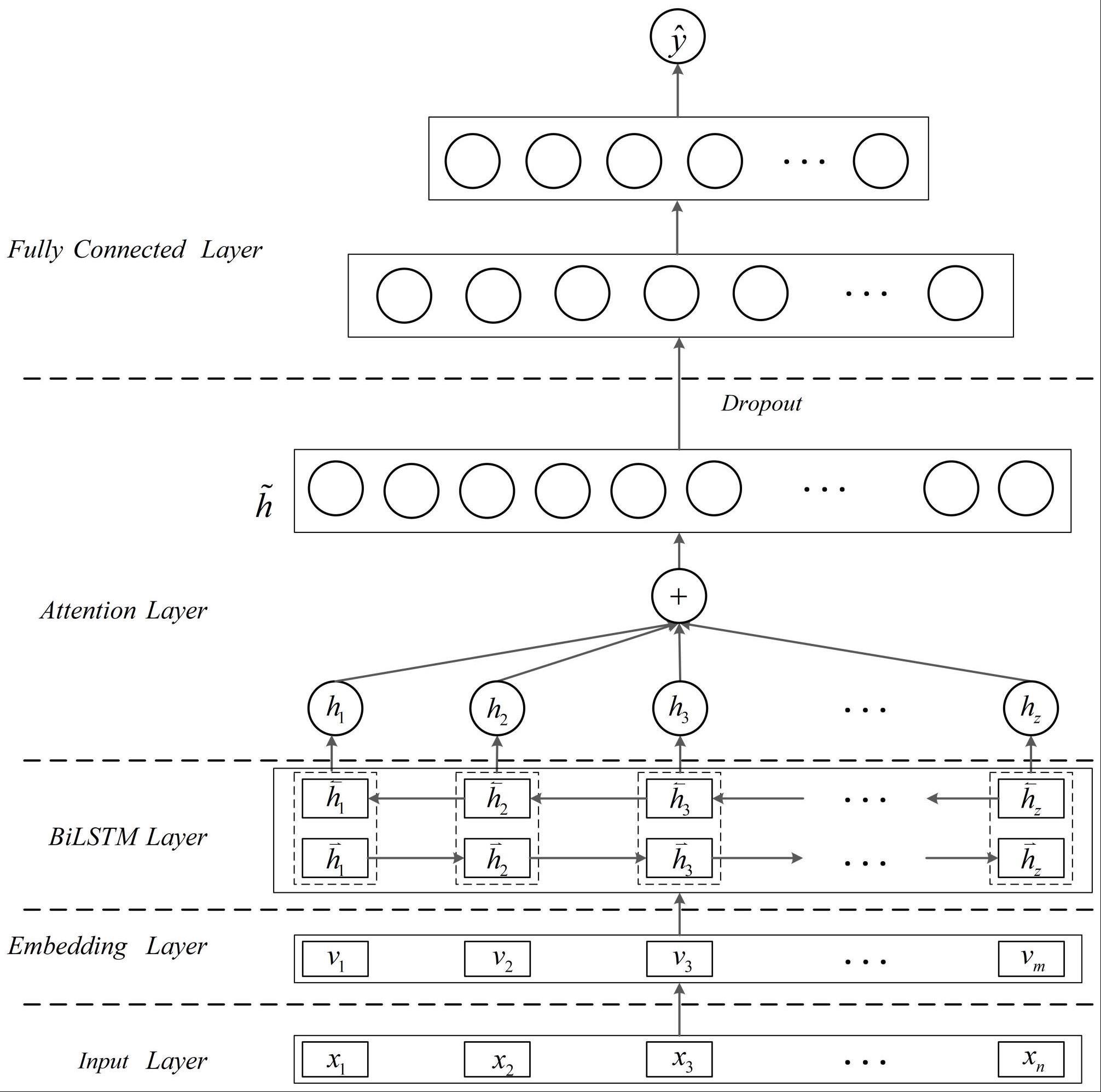
8、所述损失敏感注意力bilstm分类模型在bilstm网络的基础上使用代价敏感类函数focal loss作为损失函数,同时引入自注意力机制设计,模型结构包括输入层、词嵌入层、bilstm层、dropout层、全连接层与输出层。
9、优选的,对所述dga域名数据与alexa合法域名数据进行预处理,包括如下步骤:
10、去除dga域名数据与alexa合法域名数据中的一级域名和二级域名,只保留域名字符串;
11、利用域名字符串中的元素构建字典d;
12、选取固定值l作为所有域名字符串的统一长度值,在编码时对于长度大于l的只截取前l个字符,若长度不足l个字符则用数字0进行填充;
13、利用字典d对所有域名字符串进行编码处理,最终得到一个向量矩阵。
14、优选的,将预处理好的域名字符串按不同比例随机划分得到数据集,包括如下步骤:
15、使用预处理完毕的dga域名字符串和alexa合法域名字符串构建各自的样本库;
16、从dga域名样本库、alexa合法域名样本库中分别按照1:50、1:100、1:150、1:200不同的比例随机抽取相应的样本,来生成四组数据量均为30万条的实验所需数据集;
17、按照8:1:1的比例将每组数据集划分为训练集、验证集和测试集。
18、优选的,所述构建损失敏感注意力bilstm分类模型,具体包括如下步骤:
19、在bilstm网络中增加注意力机制,在网络每次更新状态时都会重新读取一遍之前所有时刻的状态并记录在上下文向量ci中,降低长距离依赖序列中有效信息被遗忘的概率,提升模型整体表现;
20、通过将代价敏感类损失函数focal loss作为bilstm网络的损失函数,解决数据集中正负样本比例不平衡的问题。
21、优选的,所述通过将代价敏感类损失函数focal loss作为bilstm网络的损失函数,解决数据集中正负样本比例不平衡的问题,具体包括如下步骤:
22、以标准交叉熵损失函数为基础构建focal loss损失函数,构建过程如下:
23、以二分类为例,交叉熵损失函数表达式为:
24、
25、其中,表示模型的预测值,样本的真实标签为y∈{0,1},为了便于表示,做如下变换:
26、
27、因此,交叉熵损失函数可表示为:
28、
29、在交叉熵损失函数中引入权重因子α来解决正负类样本比例之间不平衡的问题,取值范围为[0,1];
30、ce(p)=-αlog(p)
31、增加参数γ解决易分类样本和复杂样本之间的不平衡问题,取值范围为[0,5];
32、ce(p)=-(1-p)γlog(p)
33、将上述两式合并后得到focal loss损失函数的表达式:
34、fl(p)=-α(1-p)γlog(p)
35、带入参数p后得到focal loss损失函数的最终形式为:
36、
37、其中,ce表示交叉熵损失函数,fl表示focal loss损失函数,p表示样本预测值为正类的概率,表示样本预测标签值,y表示样本的真实标签值,α、γ均为focal loss损失函数的超参数。
38、优选的,所述将训练集中的数据输入损失敏感注意力bilstm分类模型进行训练,包括如下步骤:
39、所述训练集中通过输入层通过独热编码构建n*y维向量;
40、将n*y维向量输入x维的词嵌入层,获得n*x维的向量;
41、设模型初始学习率为0.001,采用自适应矩估计优化算法更新网络的权重;
42、通过bilstm层提取域名序列中的特征,输出n*隐藏神经元个数维的向量;
43、利用全连接层拉伸bilstm层的输出向量,将输出向量转换为低维数据;
44、采用sigmoid作为输出层的分类函数,输出(0,1)之间的实数,若输出结果位于(0,0.5)之间则判定为正常域名,输出结果位于[0.5,1)之间则判定为dga域名。
45、优选的,在所述bilstm训练时中对其进行优化,包括如下步骤:
46、采用focal loss函数作为损失函数,计算神经网络训练结果的损失值,利用反向传播机制调整网络参数,对神经网络进行训练优化;
47、采用dropout层来降低模型训练过程中出现过拟合现象的概率;
48、使用不同的数据批大小,考虑训练效率与模型表现,选择最优数据批大小。
49、优选的,通过评价指标对训练好的所述损失敏感注意力bilstm分类模型进行评价。
50、优选的,通过评价指标对训练好的所述损失敏感注意力bilstm分类模型进行评价,具体包括如下步骤:
51、选取分类任务中的召回率、精确率、f1值以及不平衡样本分类问题中的pr曲线precision-recall curve,prc与横轴、纵轴所组成的面积作为模型性能的评价指标,具体公式为:
52、
53、
54、
55、其中,recall为召回率,precision为精确率,f1-score为f1值,tp为真正例,表示真实类别为正类,预测类别也为正类;fp为假正例,表示真实类别为正类,预测类比为负类;fn为假负例,真实类别为负类,预测类别为正类;tn为真负例,真实类别为负类,预测类别却为负类。
56、本发明与现有技术相比具有以下有益效果:本发明使用代价敏感类函数focalloss代替传统的交叉熵损失函数,同时引入自注意力机制,设计了损失敏感注意力bilstm分类模型,然后在预处理好的正负样本比例不平衡的数据集上对模型进行训练并利用测试集验证模型表现。本发明考虑的正常网络流量中dga域名与合法域名正负样本比例不平衡的问题,提高了现有模型对于真实的网络流量和训练数据上的表现的平衡性,可以在不同正负样本比例不平衡条件下对dga域名进行有效识别。
- 还没有人留言评论。精彩留言会获得点赞!