一种铁路列车模糊数据协议比对方法与流程
本发明属于轨道交通车辆领域,涉及一种铁路列车模糊数据协议比对方法。
背景技术:
1、智能运维系统离不开列车海量运营数据的支撑,但不具备列车数据采集传输功能的老旧车型成为了数据获取过程中的短板。在系统设计上,老旧车型通过加装具有采集和无线传输功能的记录仪便可完成数据获取。对老旧车型的列车数据解析过程中,因为列车扩编、大修、新增系统等技术原因,导致留存数据协议与现有车辆不符。早期老旧车型的运营方和国外制造商对于数据协议管理不规范,导致留存数据协议与现有车辆不符。列车数据协议的不准确严重影响了列车的数据解析准确性,阻碍了智能运维平台搭建的数据完整性进程。
技术实现思路
1、为了解决这种模糊数据协议确认、更新问题,本发明提供了一种列车模糊数据协议的比对方法,提高列车数据解析的准确性,补全智能运维平台的数据完整性。本发明提供的一种铁路列车模糊数据协议比对方法,针对留存数据协议文本与现车运行的数据协议内容不符的老旧车型,该方法是一种比对方法满足现有老旧车型的数据解析要求,以留存协议为基础,分析模糊的协议变量与留存协议中确定变量的相关性;
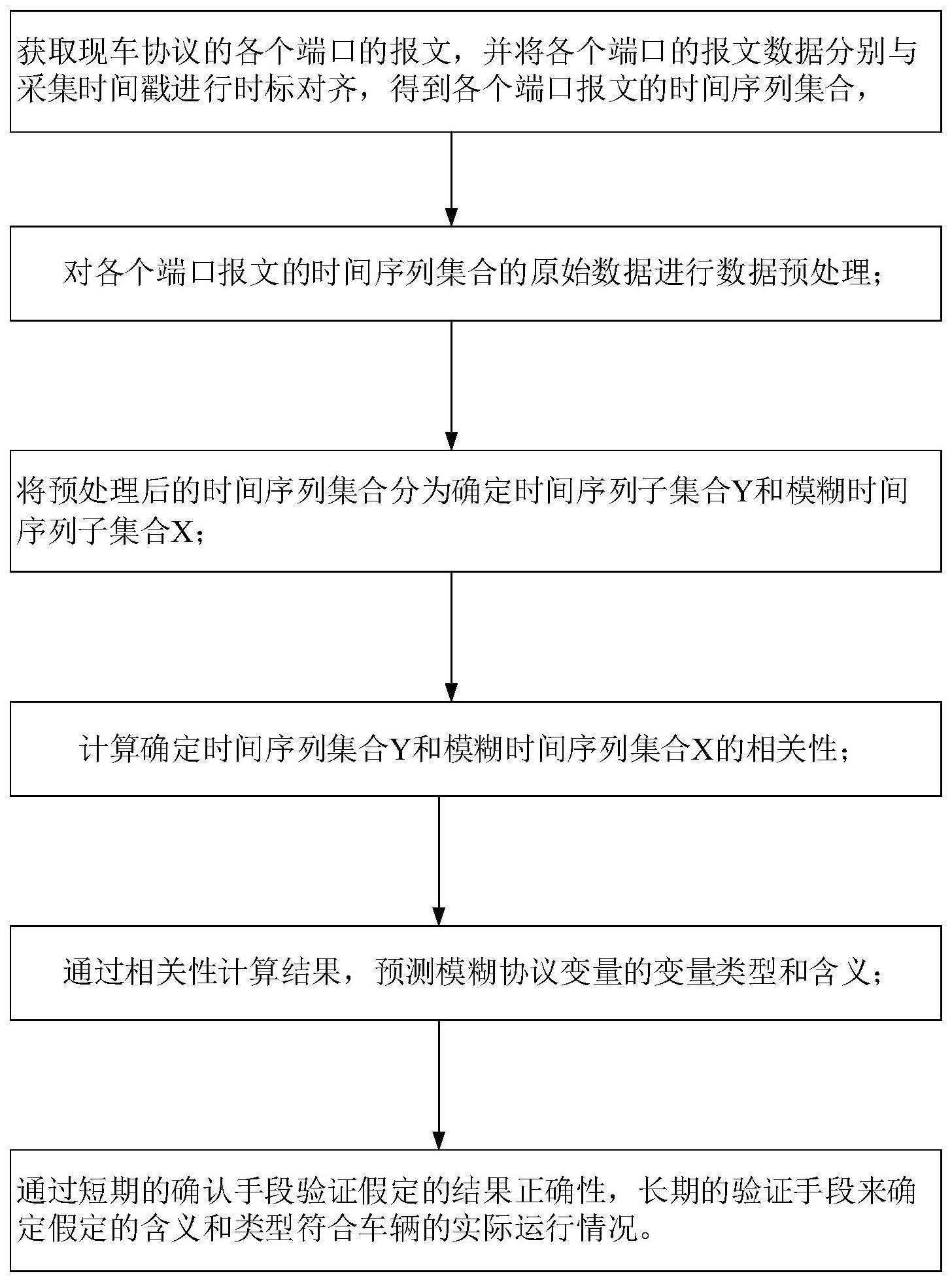
2、一种铁路列车模糊数据协议比对方法,包括以下步骤:
3、步骤1、获取现车协议的各个端口的报文,并将各个端口的报文数据分别与采集时间戳进行时标对齐,得到各个端口报文的时间序列集合;
4、步骤2、对各个端口报文的时间序列集合的原始数据进行数据预处理;
5、步骤3将预处理后的时间序列集合分为确定时间序列子集合y和模糊时间序列子集合x;
6、步骤4、计算确定时间序列集合y和模糊时间序列集合x的相关性;
7、步骤5、通过相关性计算结果,预测模糊协议变量的变量类型和含义;
8、步骤6、通过短期的确认手段验证假定的结果正确性,长期的验证手段来确定假定的含义和类型符合车辆的实际运行情况。
9、进一步地:对各个端口报文的时间序列集合的原始数据进行数据预处理的过程如下:
10、对所有的时间序列进行预处理,预处理的过程包含归一化、时间长度裁剪、逐段聚集平均三个过程;
11、s21:归一化处理,通过线性归一化,如公式(1)所示,将时间序列的值集中在[0,1]范围内:
12、
13、x代表某一时间序列的原始数据值,x′代表归一化处理过的时间序列值;
14、s22:列车运行数据记录的记录文件时间较长,以列车单方向运行时长t作为固定时长裁剪时间序列,t代表列车从起始站行驶到终点站的时长;以t为周期对时间序列集合进行裁剪,获得了长度统一的时间序列,并且以t为周期,整个列车的运行过程遍历了所有的运行场景和线路站点情况;
15、s23:通过逐段聚集平均的方法,缩减每条时间序列的维度,具体公式如下:
16、
17、其中,为处理后的序列集合x的第i个元素,n为预处理后的集合长度,n为原始输入序列长度;
18、在时间序列上滑动一个大小固定的滑动窗口,并计算滑动窗口中数据的均值作为整个窗口内数据的表示,将时间序列的采样点进行缩减,对序列的特征进行提取。
19、进一步地:所述相关性程度的度量通过皮尔逊系数来进行计算相关性数值,所述皮尔逊系数的计算公式如下:
20、
21、其中,n为序列x(ir和y(i)的长度,τ为时间延迟;
22、再通过相关性数值进行查表确定相关性程度。
23、进一步地:所述通过相关性计算结果,预测模糊协议变量的变量类型和含义的过程如下:
24、先假定xbyte集合所有时间序列对应的变量形式为字节变量,遍历xbyte集合内所有的子集,计算所有时间序列之间的皮尔逊系数,获得xbyte的皮尔逊系数矩阵p,p为对称矩阵,对于xbyte集合的时间序列i与所有时间序列的相关性,即为p矩阵的行向量pi;
25、若pi的元素都<0.6,则说明时间序列i与集合内其他时间序列都关联性较弱,则将前四个布尔量组成一个高四位半字节序列,由后四个布尔量组成一个低四位半字节序列,并计算两个半字节序列的皮尔逊系数并判断两个半字节序列的皮尔逊系数相关性;
26、若pi的任一元素都≥0.6,则说明时间序列i与集合内其他时间序列都关联性较强,可判定该序列对应的变量形式均以字节变量为基础,进一步结合两序列的取值范围以及变化趋势判断是否为字变量或者双字变量;
27、综上所述,对xbyte集合按照推测的变量形式将集合进行重组为x={xbool,xbyte,xword,xdword}。
28、进一步地:所述判断两个半字节序列的皮尔逊系数相关性的过程如下:
29、若两个半字节变量的皮尔逊系数大于≥0.6,则确定时间序列i的变量形式为字节变量,若两个半字节变量的皮尔逊系数<0.6,则确定时间序列i的变量形式为布尔变量。
30、一种铁路列车模糊数据协议比对装置,包括:
31、获取模块:用于获取现车协议的各个端口的报文,并将各个端口的报文数据分别与采集时间戳进行时标对齐,得到各个端口报文的时间序列集合;
32、预处理模块:用于对各个端口报文的时间序列集合的原始数据进行数据预处理;
33、划分模块:用于将预处理后的时间序列集合分为确定时间序列子集合y和模糊时间序列子集合x;
34、计算模块:用于计算确定时间序列集合y和模糊时间序列集合x的相关性;
35、预测模块:用于通过相关性计算结果,预测模糊协议变量的变量类型和含义;
36、确定模块:用于通过短期的确认手段验证假定的结果正确性,长期的验证手段来确定假定的含义和类型符合车辆的实际运行情况。
37、本发明提供的一种铁路列车模糊协议比对方法,便于快捷的确定模糊协议的含义,降低技术人员的工作强度,提高工作效率。提高列车数据解析的准确性,补全智能运维平台的数据获取的短板。
技术特征:
1.一种铁路列车模糊数据协议比对方法,其特征在于:包括以下步骤:
2.根据权利要求1所述的一种铁路列车模糊数据协议比对方法,其特征在于:对各个端口报文的时间序列集合的原始数据进行数据预处理的过程如下:
3.根据权利要求1所述的一种铁路列车模糊数据协议比对方法,其特征在于:所述相关性程度的度量通过皮尔逊系数来进行计算相关性数值,所述皮尔逊系数的计算公式如下:
4.根据权利要求1所述的一种铁路列车模糊数据协议比对方法,其特征在于:所述通过相关性计算结果,预测模糊协议变量的变量类型和含义的过程如下:
5.根据权利要求1所述的一种铁路列车模糊数据协议比对方法,其特征在于:所述判断两个半字节序列的皮尔逊系数相关性的过程如下:
6.一种铁路列车模糊数据协议比对装置,其特征在于:包括:
技术总结
本发明一种铁路列车模糊数据协议比对方法,包括以下步骤:获取现车协议的各个端口的报文,并将各个端口的报文数据分别与采集时间戳进行时标对齐,得到各个端口报文的时间序列集合;对各个端口报文的时间序列集合的原始数据进行数据预处理;将预处理后的时间序列集合分为确定时间序列子集合Y和模糊时间序列子集合X;计算确定时间序列集合Y和模糊时间序列集合X的相关性;通过相关性计算结果,预测模糊协议变量的变量类型和含义;通过短期的确认手段验证假定的结果正确性,长期的验证手段来确定假定的含义和类型符合车辆的实际运行情况。该方法便于快捷的确定模糊协议的含义,降低技术人员的工作强度,提高工作效率。
技术研发人员:程宝,王忠福,张福景,张增一,杨美慧
受保护的技术使用者:中车大连电力牵引研发中心有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!