一种基于多模态融合的诈骗网站识别方法及装置
本发明属于互联网信息安全,特别涉及一种基于多模态融合的诈骗网站识别方法及装置。
背景技术:
1、国内外与本发明方法相关研究主要集中在:1)传统诈骗网站识别方法;2)单一模态的深度学习诈骗网站识别方法;3)多模态的诈骗网站识别方法。
2、传统诈骗网站识别方法
3、目前诈骗网站识别方法主要有3种:基于黑白名单技术的识别方法、基于启发式规则的识别方法及基于机器学习的识别方法。基于黑白名单技术的识别方法检测速度快、易实现,但黑白名单需经常更新,而且之前未出现过的诈骗网站无法识别。基于启发式规则的识别方法通过诈骗网站之间的相似性设计启发式规则,其可识别之前未出现的诈骗网站,但误报率较高。对此研究人员提出基于机器学习的识别方法。杨鹏等人根据提取的url特征、html特征和网页文本向量特征,结合逻辑回归把高维与稀疏的文本特征转换成概率特征,建立xgbo ost网站分类模型,大大提高了识别精度(杨鹏,曾朋,赵广振,等.基于logistic回归和xgboost的钓鱼网站检测方法[j].东南大学学报(自然科学版),2019,49(02):207-212.)。胡向东等人提取页面标志图像特征与正规网站进行相似度匹配,判断是否为仿冒网站(胡向东,刘可,张峰,等.基于页面敏感特征的金融类钓鱼网页检测方法[j].网络与信息安全学报,2017,3(02):35-42.)。
4、单一模态的深度学习诈骗网站识别方法
5、机器学习方法尽管已展现出不错的识别效果,可是此类方法太过依赖人工特征选择,随着诈骗网站网页元素的增多,人工特征选择开始逐渐失效。深度学习方法相较传统机器学习具有更强的特征学习能力,可以自动捕获更抽象和高级别的特征,因此在网页识别领域被广泛应用。方勇等人利用lstm和随机森林混合架构挖掘钓鱼网站url序列的潜在特征,显著提高了钓鱼网站识别效率与准确率(方勇,龙啸,黄诚,刘亮.基于lstm与随机森林混合构架的钓鱼网站识别研究[j].工程科学与技术,2018,50(05):196-201.)。何颖等人将网页特征划分为域名特征、标签特征、搜索引擎收录特征、文本特征及图像特征等5个维度,并结合深度神经网络,构建了网站识别模型,实验发现该识别模型在各评估指标上均优于传统机器学习模型(何颖,杨频,王丛双,汤娟.基于深度神经网络的配资网站识别研究[j].四川大学学报(自然科学版),2021,58(03):97-103.)。sirinam等人利用基于卷积神经网络的vgg模型挖掘tor网页流单元序列特征,模型识别准确率达98%(sirinam p,imani m,juarez m,et al.deep fingerprinting:undermining website fingerprintingdefenses with deep
6、learning[c]//proceedings of the 2018acm sigsac conference on computerand communications security.2018:1928-1943.)。马陈城等人设计了一种基于深度神经网络burst特征分析的网站指纹攻击方法,分类准确率高达99.87%(马陈城,杜学绘,曹利峰,等.基于深度神经网络burst特征分析的网站指纹攻击方法[j].计算机研究与发展,2020,57(04):80-100.)。
7、多模态的诈骗网站识别方法
8、以上识别方法研究大多局限于单一模态,但是随着互联网技术的发展,网页中包含大量的图片、文本信息,极大的增强了诈骗网站的伪装性和隐蔽性,这时单一模态所反馈的信息往往是不完整且具有局限性。多模态融合能使数据生成全面、准确的描述。adebowale等人设计了自适应神经模糊推理系统,将钓鱼网站22个文本特征、8个框架特征及5个图像特征进行融合,并利用支持向量机进行分类预测(adebowale m a,lwin k t,sanchez e,et al.intelligent web-phishing detection and protection schemeusing integrated features of images,frames and text[j].expert systems withapplications,2019,115:300-313.)。但是当前基于多模态融合的诈骗网站识别方法依然处在探索阶段,如何高效融合不同模态,优化识别方法的准确率是目前研究热点。目前主要有三种方法:特征层融合、模型层融合及决策层融合。特征层融合直接对各模态特征进行拼接,并未考虑各模态之间的差异性。因此无法描述文本、图像、url等之间的关联。此外,当模态数增加时,容易引起维数灾难。模型层融合需考虑到各个模态之间的特征和模型流之间的关联,实现过于复杂。决策层融合是将各单模态识别结果经某种方法进行融合的方式。相较于特征层和模型层融合,决策层融合更容易实现,而且其能较为充分的考虑各模态间的差别,更为关键的是可以综合各模态的识别结果。
技术实现思路
1、本发明目的在于针对传统诈骗网站识别中误报率高、依赖于人工选择、模态单一的局限性等问题,提出一种基于多模态融合的诈骗网站识别方法及装置(multi-modalfraud website classifying method based on dissimilar model integration,mfwc-dmi)。
2、本发明的目的是通过以下技术方案来实现的:第一方面,本发明提供了一种基于多模态融合的诈骗网站识别方法,该方法包括以下步骤:
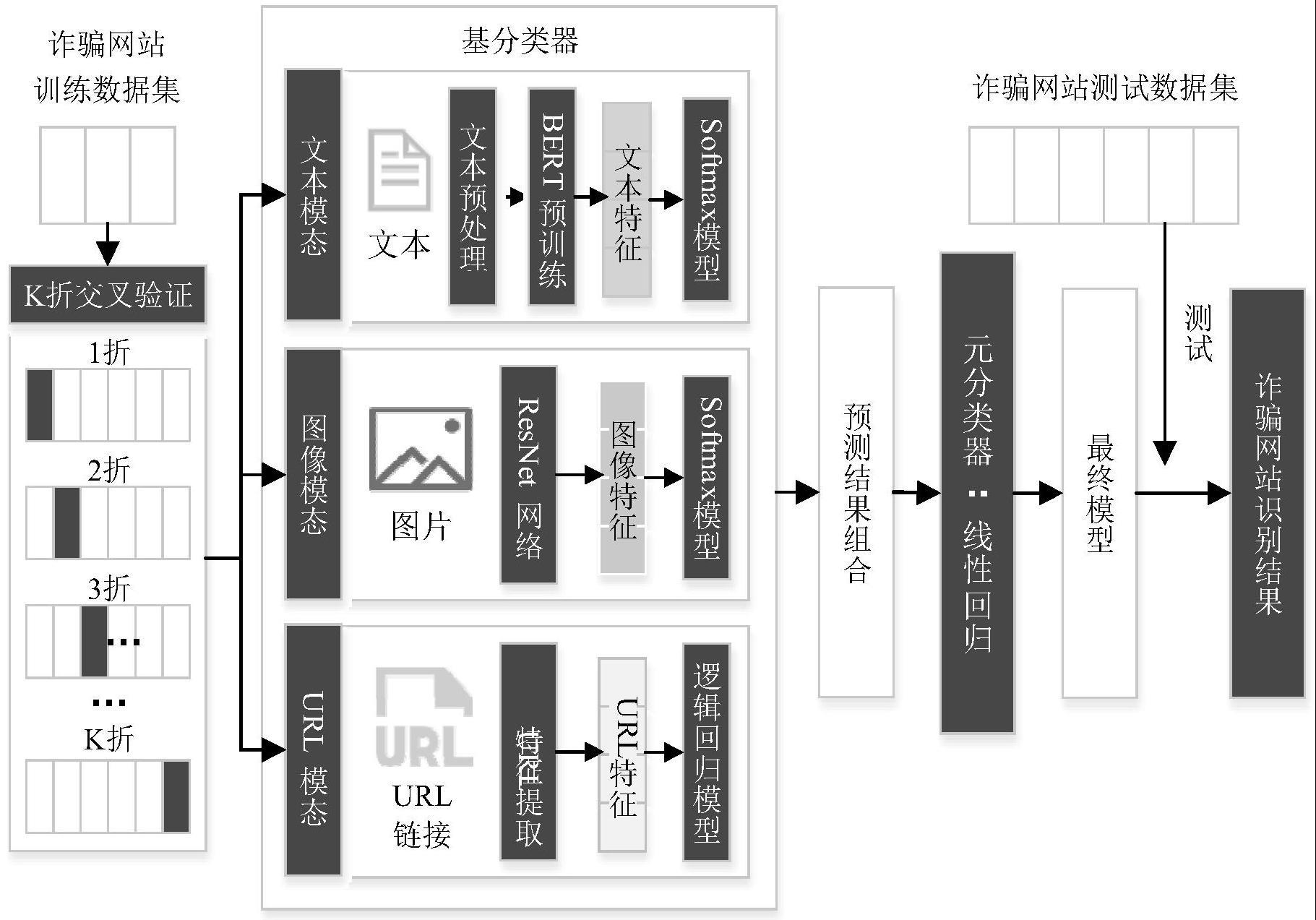
3、(1)获取诈骗网站图像模态特征、诈骗网站文本模态特征、诈骗网站url模态特征作为样本并获取样本对应的类标签,构建训练集;
4、(2)构建三个基分类器,分别对文本模态、图像模态和url模态进行识别;并通过训练集对基分类器训练;
5、(3)构建元分类器,将基分类器的预测值基于类标签组合得到新的特征向量集合,作为元分类器的训练样本集,对元分类器训练;
6、(4)将训练好的三个基分类器和元分类器结合,构建多模态融合的诈骗网站识别模型,将获取的诈骗网站图像特征、诈骗网站文本特征、诈骗网站url特征作为模型输入,得到诈骗网站的识别结果。
7、进一步地,将步骤(1)中的训练集分成k份,通过k折交叉验证的方式对三个基分类器进行训练。
8、进一步地,步骤(2)中,对文本模态识别具体过程如下:
9、1)对训练集中的文本数据进行分词、去停用词预处理;
10、2)构建bert模型并进行预训练;
11、3)bert模型获得的语义特征输入至softmax模型完成文本模态分类。
12、进一步地,步骤(2)中,对图像模态识别具体过程如下:
13、1)通过resnet网络进行图片特征提取;
14、2)利用inception模块进行池化层堆叠;
15、3)通过softmax回归层输出图像模态的分类。
16、进一步地,步骤(2)中,对url模态识别具体过程如下:
17、1)提取url的6个特征,分别为:是否为ip地址、是否含有可疑字符、url长度、域名中“.”的数量、敏感词汇和是否为https链接;
18、2)将提取的url特征输入到逻辑回归模型logistic regression进行分类。
19、进一步地,步骤(3)中元分类器选择线性回归模型。
20、进一步地,步骤(4)中,所述多模态融合的诈骗网站识别模型通过stacking集成学习,利用多模态决策级融合方法对文本、图像、url多个模态进行融合。
21、第二方面,本发明还提供了一种基于多模态融合的诈骗网站识别装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现所述的基于多模态融合的诈骗网站识别方法。
22、第三方面,本发明还提供了一种计算机可读存储介质,其上存储有程序,所述程序被处理器执行时,实现所述的基于多模态融合的诈骗网站识别方法。
23、本发明的有益效果:本发明从不同空间角度与数据角度构建基分类器,充分的考虑各模态间的差别,取长补短,最后通过元分类器进行stacking集成,提高方法的泛化能力,使其能够有效过滤干扰信息,识别隐藏诈骗信息,提高诈骗网站识别准确率。
- 还没有人留言评论。精彩留言会获得点赞!