一种分布式数据库实时采集入湖方法及系统与流程
本发明属于数据传输,具体涉及一种分布式数据库实时采集入湖方法以及系统。
背景技术:
1、数据库变化数据捕获(cdc,change data capture)采集技术已经是现在数据库同步和数据库采集中的主流技术,cdc通过源数据库捕获到数据和数据结构的增量变更,近乎实时地将这些变更情况传播到其他数据库或应用程序之处。通过这种方式,cdc能够向数据仓库提供高效、低延迟的数据传输,以便信息被及时转换并交付给专供分析的应用程序。
2、数据湖技术作为数仓存储的新技术,凭借其高效实时的摄入、读取效率以及对于传统大数据数仓技术较好的兼容性,开始被很多公司引入到大数据平台中。数据湖的典型技术为hudi。
3、通过数据库cdc技术采集数据库数据入湖已经是主流的数据库数据采集方案了。主流技术一般通过cdc的数据先通过cdc工具导入kafka或者pulsar,再通过flink或者是spark流式消费写到hudi里。
4、但是,目前主流的cdc技术采集数据库数据入湖,一方面,因为cdc都是实时采集,cdc工具都是以服务的形式于整个采集链路中。并且一般由于采集源分散在网络的各种位置上,往往一个数据库对应于一个独立的cdc服务,而大量这种独立的服务对于采集配置变更以及维护工作是非常麻烦的。另一方面,多个cdc服务和入湖服务本身是相对独立的,入湖过程中湖表的schema定义往往提前约定好并通过硬编码的方式到入湖过程中的,对于采集源数据表的schema的变化是无法感知的。
技术实现思路
1、本发明实施例的目的是提供一种分布式数据库实时采集入湖方法以及系统,能够解决现有的数据入湖技术中大量独立的cdc服务对于采集配置变更以及维护工作是非常麻烦的,多个cdc服务和入湖服务本身是相对独立的,入湖过程中无法感知源数据表的schema的变化,导致数据入湖流程冗余、效率低下的技术问题。
2、为了解决上述技术问题,本发明是这样实现的:
3、第一方面
4、本发明实施例提供了一种分布式数据库实时采集入湖方法,包括:
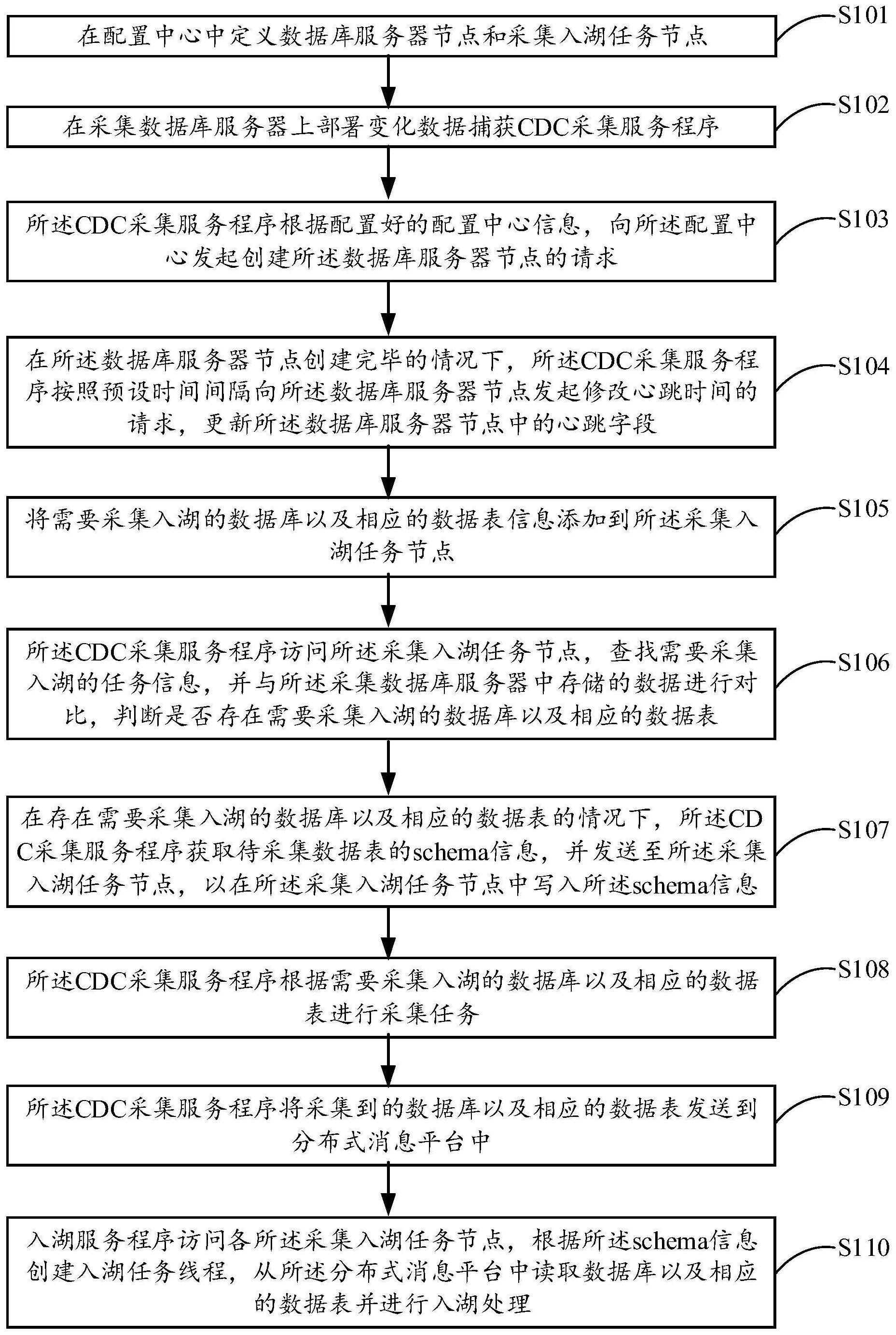
5、s101:在配置中心中定义数据库服务器节点和采集入湖任务节点;
6、s102:在采集数据库服务器上部署变化数据捕获cdc采集服务程序;
7、s103:cdc采集服务程序根据配置好的配置中心信息,向配置中心发起创建数据库服务器节点的请求;
8、s104:在数据库服务器节点创建完毕的情况下,cdc采集服务程序按照预设时间间隔向数据库服务器节点发起修改心跳时间的请求,更新数据库服务器节点中的心跳字段;
9、s105:将需要采集入湖的数据库以及相应的数据表信息添加到采集入湖任务节点;
10、s106:cdc采集服务程序访问采集入湖任务节点,查找需要采集入湖的任务信息,并与采集数据库服务器中存储的数据进行对比,判断是否存在需要采集入湖的数据库以及相应的数据表;
11、s107:在存在需要采集入湖的数据库以及相应的数据表的情况下,cdc采集服务程序获取待采集数据表的schema信息,并发送至采集入湖任务节点,以在采集入湖任务节点中写入schema信息;
12、s108:cdc采集服务程序根据需要采集入湖的数据库以及相应的数据表进行采集任务;
13、s109:cdc采集服务程序将采集到的数据库以及相应的数据表发送到分布式消息平台中;
14、s110:入湖服务程序访问各采集入湖任务节点,根据schema信息创建入湖任务线程,从分布式消息平台中读取数据库以及相应的数据表并进行入湖处理。
15、进一步地,数据库服务器节点的名称为采集数据库服务器的地址,数据库服务器节点的内容为采集数据库服务器的连接时间以及心跳时间。
16、进一步地,采集入湖任务节点的名称为采集数据库和相应的采集数据表的名称,数据库服务器节点的内容为采集数据表的schema信息,schema信息包括各个字段的名称、类型、长度、顺序以及入湖任务的库、表。
17、进一步地,在s104之后,还包括:
18、s104a:告警程序遍历所有的数据库服务器节点,比较当前时间与各采集数据库服务器的最后心跳时间之间的差值,根据差值与预设超时时间的比较结果,判断采集数据库服务器是否存在服务异常。
19、进一步地,s108具体为:
20、cdc采集服务程序采用snapshot全量+binlog增量的方式采集需要采集入湖的数据库以及相应的数据表。
21、第二方面
22、本发明实施例提供了一种分布式数据库实时采集入湖系统,包括:
23、定义模块,用于在配置中心中定义数据库服务器节点和采集入湖任务节点;
24、部署模块,用于在采集数据库服务器上部署变化数据捕获cdc采集服务程序;
25、第一请求模块,用于cdc采集服务程序根据配置好的配置中心信息,向配置中心发起创建数据库服务器节点的请求;
26、第二请求模块,用于在数据库服务器节点创建完毕的情况下,cdc采集服务程序按照预设时间间隔向数据库服务器节点发起修改心跳时间的请求,更新数据库服务器节点中的心跳字段;
27、添加模块,用于将需要采集入湖的数据库以及相应的数据表信息添加到采集入湖任务节点;
28、对比模块,用于cdc采集服务程序访问采集入湖任务节点,查找需要采集入湖的任务信息,并与采集数据库服务器中存储的数据进行对比,判断是否存在需要采集入湖的数据库以及相应的数据表;
29、写入模块,用于在存在需要采集入湖的数据库以及相应的数据表的情况下,cdc采集服务程序获取待采集数据表的schema信息,并发送至采集入湖任务节点,以在采集入湖任务节点中写入schema信息;
30、采集模块,用于cdc采集服务程序根据需要采集入湖的数据库以及相应的数据表进行采集任务;
31、发送模块,用于cdc采集服务程序将采集到的数据库以及相应的数据表发送到分布式消息平台中;
32、入湖模块,用于入湖服务程序访问各采集入湖任务节点,根据schema信息创建入湖任务线程,从分布式消息平台中读取数据库以及相应的数据表并进行入湖处理。
33、进一步地,数据库服务器节点的名称为采集数据库服务器的地址,数据库服务器节点的内容为采集数据库服务器的连接时间以及心跳时间。
34、进一步地,采集入湖任务节点的名称为采集数据库和相应的采集数据表的名称,数据库服务器节点的内容为采集数据表的schema信息,schema信息包括各个字段的名称、类型、长度、顺序以及入湖任务的库、表。
35、进一步地,分布式数据库实时采集入湖系统还包括:
36、告警模块,用于告警程序遍历所有的数据库服务器节点,比较当前时间与各采集数据库服务器的最后心跳时间之间的差值,根据差值与预设超时时间的比较结果,判断采集数据库服务器是否存在服务异常。
37、进一步地,采集模块具体用于:
38、cdc采集服务程序采用snapshot全量+binlog增量的方式采集需要采集入湖的数据库以及相应的数据表。
39、本发明至少具有以下有益效果:
40、在本发明实施例中,通过在配置中心中定义数据库服务器节点和采集入湖任务节点,之后利用数据库服务器节点和采集入湖任务节点将所有的采集入湖服务进行统一管理,使得采集配置变更以及维护工作更加简单化,降低了运维管理成本,入湖过程中通过采集入湖任务节点动态感知源数据表的schema的变化,并且根据schema的变化调整入湖策略,简化数据入湖流程,提升数据入湖的效率。
- 还没有人留言评论。精彩留言会获得点赞!