基于共享交叉节点的横向拆分Crossbar交换网络系统
本发明属于通信,具体涉及一种基于共享交叉节点的横向拆分crossbar交换网络系统。
背景技术:
1、目前,主流的单级交换结构主要分为共享总线,共享缓存以及crossbar三种结构。共享总线结构中所有输入端口的所有数据以时分复用的形式在总线上传输,因此共享总线结构要求总线速率大于所有端口速率之和,才能保证不出现阻塞。因为共享总线结构交换容量受限于总线速率且可扩展性不高,所以一般不使用这种结构。共享缓存结构通过对同一片缓存区域的读写来实现数据帧的接收和发送,相较于共享总线的结构是很容易达到数据的线速处理,但是单一共享缓存的交换容量受限于缓存的写入读取速率,同时也存在无法自由扩充的问题。crossbar交换结构可以很好的解决共享总线结构和共享缓存结构交换容量受限的问题。crossbar交换结构通过使用高速交叉开关矩阵电路实现多输入到多输出的通道通断,任何一个输入到输出的通道开关均不影响其他已连接的通道,可以实现了严格无阻塞。crossbar交换网络按照排队策略区分为输入排队(input queued,iq)、输出排队(out queued,oq)、输入输出联合排队(combined input and output queued,cioq)、交叉节点联合排队(combined input and crosspoint queued,cicq)。其中输入交叉节点联合排队可以有效的隔离输入端和输出端,而且便于扩展交换容量,因此输入交叉节点联合排队结构是目前被广泛采用的一种交换网络结构。在cicq交换结构中输入队列管理模块共享缓存和crossbar交叉节点缓存会消耗大量存储资源。当单片fgpa不足以支持当前交换容量所需求的存储资源时,使用多片fpga就能很好的解决存储资源不足的问题。如果需求中交换所要承载的物理端口数量大于一片fpga所能承载的数量的时候,使用两片fpga共同完成交换的功能是一个可行的解决方案。但是,使用两片fpga实现一个交换系统存在一个天然的问题,就是两片fpga之间的数据或信号交互存在很大的时延。以横向拆分的为例,横向拆分保留了从输入总线到同行交叉节点的逻辑,所以输入队列管理模块与同行交叉节点缓存的交互是在同一片fpga内部完成的,但是对同一列交叉节点缓存进行输出仲裁时,传输的数据和交互信号需要跨片传输。如何缓解跨片传输数据或者信号带来的调度效率的降低成为了一个待解决的问题。
技术实现思路
1、为了解决现有技术中存在的上述问题,本发明提供了一种基于共享交叉节点的横向拆分crossbar交换网络系统。本发明要解决的技术问题通过以下技术方案实现:
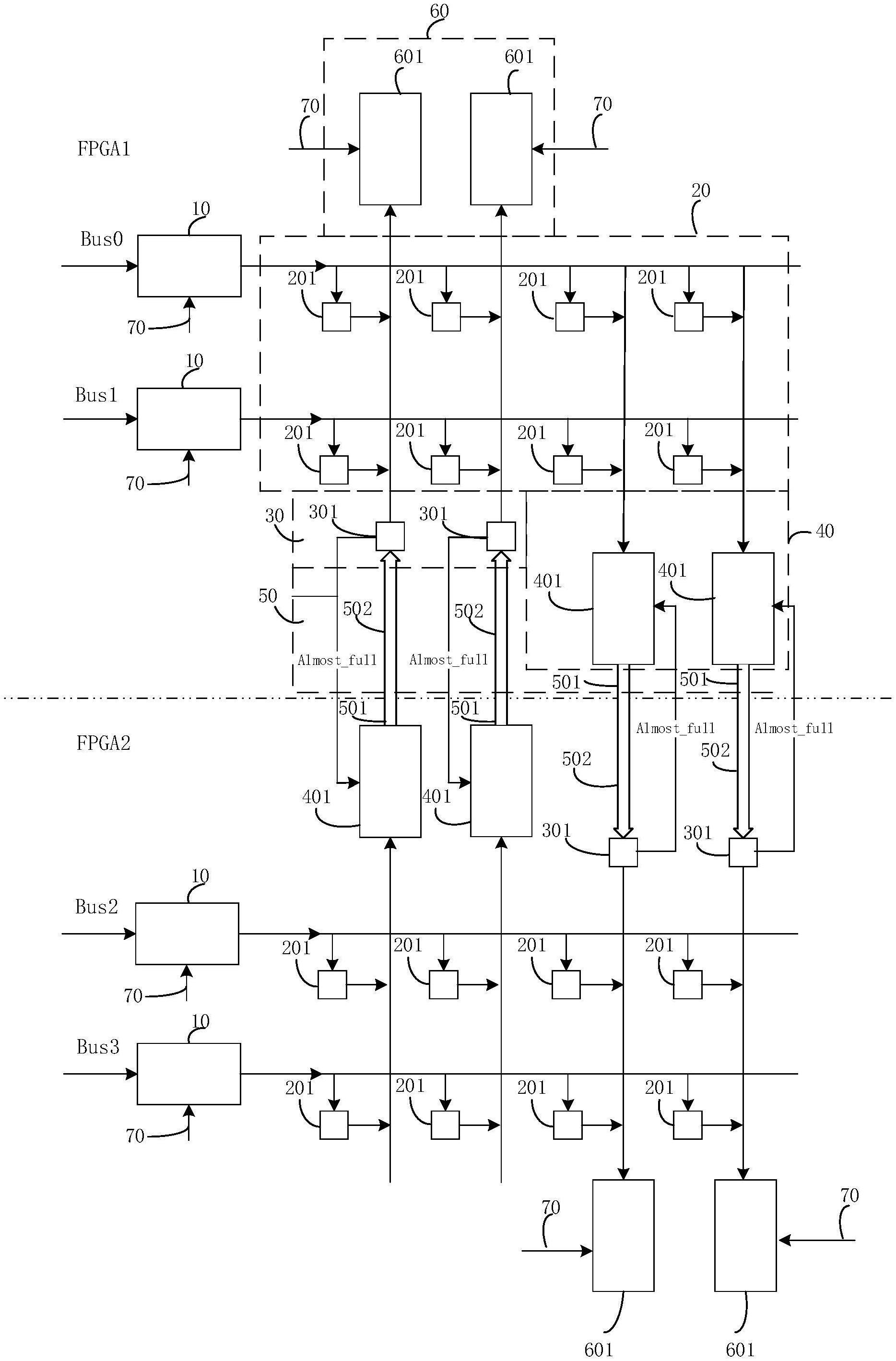
2、本发明实施例提供了一种基于共享交叉节点的横向拆分crossbar交换网络系统,包括:设置在每片fpga上的若干输入队列管理模块、普通交叉节点缓存模块、共享交叉节点缓存模块、rr列仲裁模块、高速aurora接口模块、wrr独立列仲裁模块和若干配置接口,其中,
3、所述若干输入队列管理模块用于接收来自物理端口的数据帧,依据数据帧的目的端口在数据帧头部添加tag头;
4、所述普通交叉节点缓存模块用于接收添加tag头的数据帧,并根据所述目的端口将添加tag头的数据帧暂存到不同的普通交叉节点缓存中;
5、所述共享交叉节点缓存模块用于接收并存储所述片间高速aurora接口模块中来自另一片fpga的数据帧,并与本片pfga上同一列的普通交叉节点缓存中的数据帧参与wrr独立列仲裁模块的仲裁;
6、所述rr列仲裁模块用于根据同一列上普通交叉节点缓存的发送请求给出仲裁结果,并且依据仲裁结果将本片fpga中添加tag头的数据帧从对应的普通交叉节点缓存搬移到所述片间高速aurora接口模块的发送部分,形成待发送数据帧;
7、所述片间高速aurora接口模块用于发送所述待发送数据帧到另一片fpga片间高速aurora接口模块的接收部分,并且接收另一片fpga中片间高速aurora接口模块发送部分输出的数据帧,传输至本片fpga的共享交叉节点缓存模块;
8、所述wrr独立列仲裁模块用于接收普通交叉节点缓存模块和共享交叉节点缓存模块中同一列的交叉节点缓存发送的请求信号并进行加权轮询调度,将轮询调度到的交叉节点缓存中的数据帧搬移到输出端口;
9、所述若干配置接口用于配置所述wrr独立列仲裁模块调度所需权值以及所述若干输入队列管理模块的队列最大最小门限。
10、在本发明的一个实施例中,所述普通交叉节点缓存模块包括若干普通交叉节点缓存,所述共享交叉节点缓存模块包括若干共享交叉节点缓存,所述rr列仲裁模块包括若干rr列仲裁子模块,所述片间高速aurora接口模块包括若干第一片间高速aurora接口和若干第二片间高速aurora接口,所述wrr独立列仲裁模块包括若干wrr独立列仲裁子模块,其中,
11、所述若干普通交叉节点缓存呈阵列分布,且每一行的普通交叉节点缓存均连接所述输入队列管理模块;
12、每个所述共享交叉节点缓存连接同一列的所述普通交叉节点缓存,每个所述rr列仲裁子模块连接同一列的所述普通交叉节点缓存,且所述共享交叉节点缓存和所述rr列仲裁子模块的数量之和与所述普通交叉节点缓存的列数相等;
13、所述第一片间高速aurora接口连接本片fpga的rr列仲裁子模块和另一片fpga片间高速aurora接口模块的接收部分,所述第二片间高速aurora接口连接本片fpga的共享交叉节点缓存和另一片fpga中片间高速aurora接口模块发送部分;
14、每个所述wrr独立列仲裁子模块连接同一列的所述普通交叉节点缓存且与所述共享交叉节点缓存位于同一列。
15、在本发明的一个实施例中,所述第一片间高速aurora接口包括第一aurora ip核、第一跨时钟模块和locallink转axi模块,所述第二片间高速aurora接口包括第二auroraip核、第二跨时钟模块和axi转locallink模块,其中,
16、所述locallink转axi模块用于将所述待发送数据帧格式转换成axi数据格式,得到格式转换的数据帧;所述第一跨时钟模块用于将所述格式转换的数据帧从系统主时钟域跨到aurora ip核的用户侧时钟域,得到第一跨时钟数据帧;所述第一aurora ip核用于将所述第一跨时钟数据帧发送到另一片fpga片间高速aurora接口模块的接收部分;
17、所述第二aurora ip核用于接收来自另一片fpga片间高速aurora接口模块的发送部分输出的数据帧,得到接收数据帧;所述第二跨时钟模块用于将所述接收数据帧从aurora ip核的用户侧时钟域跨到系统主时钟域,得到第二跨时钟数据帧;所述axi转locallink模块用于将所述第二跨时钟数据帧的格式转换成系统内部使用的locallink数据格式。
18、在本发明的一个实施例中,所述第一aurora ip核和所述第二aurora ip核均采用4路绑定形式,线速率可达40gbps。
19、在本发明的一个实施例中,每片fpga上,所述输入队列管理模块的数量为n/2个,n为总线数量;所述普通交叉节点缓存的数量为n2/2个;所述共享交叉节点缓存的数量为n/2个;所述rr列仲裁子模块的数量为n/2个;所述第一片间高速aurora接口的数量为n/2个,所述第二片间高速aurora接口的数量为n/2个,所述wrr独立列仲裁模块的数量为n/2个。
20、在本发明的一个实施例中,所述普通交叉节点缓存和所述共享交叉节点缓存均包括第一存储区域和第二存储区域,其中,
21、所述第一存储区域用于多播或广播数据,所述第二存储区域用于存储单播数据。
22、在本发明的一个实施例中,所述tag头包括单多播标识、队列号、帧长以及目的端口号。
23、在本发明的一个实施例中,根据所述目的端口将所述添加tag头的数据帧传输路径划分为本片传输路径和跨片传输路径,其中,
24、所述本片传输路径依次为:本片fpga的输入队列管理模块、本片fpga的普通交叉节点缓存模块、本片fpga的wrr独立列仲裁模块、与所述目的端口对应的输出端口;
25、所述跨片传输路径依次为:本片fpga的输入队列管理模块、本片fpga的普通交叉节点缓存模块、本片fpga的rr列仲裁模块、本片fpga的高速aurora接口模块、另一片fpga的高速aurora接口模块、另一片fpga的共享交叉节点缓存模块、另一片fpga的wrr独立列仲裁模块、与所述目的端口对应的输出端口。
26、在本发明的一个实施例中,所述本片传输路径的一个数据帧的调度周期包括调取间隔和数据传输时延,所述跨片传输路径的一个数据帧的调度周期包括调取间隔和数据传输时延。
27、与现有技术相比,本发明的有益效果:
28、1、本发明的基于共享交叉节点的横向拆分crossbar交换网络系统将crossbar交换网络横向拆分,采用包括共享交叉节点缓存模块、rr列仲裁模块、高速aurora接口模块的共享交叉节点的方式,只要共享交叉节点能够存储下一个最长帧即almost信号不拉高,就直接接收下来自另一片fpga的数据,再由共享交叉节点去进行仲裁请求的操作,这样仲裁请求和仲裁响应都是在片内完成,这样做的链路传输效率与同一片内数据调度的效率是相同的,唯一不同之处就是数据帧是从另一片过来的,所以交换时延会比单片fpag实现crossbar时更大;使用共享交叉节点缓存避免了片间仲裁带来的时延导致调度效率降低的问题,理论上只要共享交叉节点缓存足够大,横向拆分的wrr独立列仲裁调度与不拆分时的调度有一样的效率,提高了整个交换系统的调度效率,进而提高链路传输效率。
29、2、本发明依据数据帧的目的端口在数据帧头部添加tag头,可以很好的解决关键信息与数据帧到达另一片fpga不同步带来的调度效率降低的问题。
- 还没有人留言评论。精彩留言会获得点赞!