一种基于HTTP/3传输特性的加密视频识别方法
本发明涉及一种基于http/3传输特性的加密视频识别方法,属于计算机网络安全。
背景技术:
1、随着通信技术的进步和移动互联网的发展,网络交互场景越来越丰富,视频网络流量在互联网中的比重不断增加。互联网流量检测机构sandvine的2023年全球互联网现象报告显示,视频流量在2022年增长了24%,现已相当于所有互联网流量的65%。与此同时,为了保护用户安全和隐私,互联网各大视频平台对视频流量逐步进行了加密传输。基于此背景,一些含有不当内容的有害视频极易被快速传播并渗透社会生活各个方面,因此,对互联网上传输的有害视频进行快速识别是对网络安全空间有效管理的必要前提。
2、现有对视频内容进行识别的方法大多需要通过视频平台获取视频文件。视频平台在进行内容审核时,往往采用人工审核或人工智能(artificial intelligence,ai)识别两种方式。然而,人工审核工作量大、耗时长,ai识别受硬件和识别技术限制,成本高,这些原因导致小型视频平台无法负担视频审核的费用。此外,由于视频跨平台传播速度快,这类基于视频平台的管理方式需要多个平台高效协作,导致难以部署,实用性差。
3、近年也有根据视频传输的网络流量识别出有害视频的方法,这类方法不需要多方协作,只要在主干接入点部署流量采集点就可以应用,具有很强的实用性。这类方法需要事先建立公害视频特征库,对网络进行监测时,通过对流量的分析提取被传输的视频特征,与公害视频特征库中的视频特征进行匹配识别。当视频特征库被准确构建后,这类方法的核心技术是如何从传输流量中准确提取出与视频内容相关的特征用以匹配。
4、视频内容的特征最直接地由应用层数据的特征表达。目前从加密流量中识别视频的方法都利用了流媒体的http自适应流(http adaptive streaming,has)技术提取视频特征。has技术将视频内容切分成多个片段后使用可变比特率(variable bit rate,vbr)技术编码,并根据流媒体播放器的实际网络带宽传输不同比特率的视频内容片段,有效提高了用户的体验质量。youtube、facebook等主流互联网视频平台都采用了has中使用最广泛的基于http的动态自适应流媒体技术(dynamic adaptive streaming over http,dash)提供视频服务。dash技术将视频按照播放时间顺序切分成多个片段流式传输,每个视频片段的长度序列与视频内容有关,视频片段的长度序列构成了视频的特征,可以据此实现对特定视频的内容识别。基于dash技术的特点,已有一些通过流量分析对视频进行识别的方法。
5、随着视频平台普遍使用端到端加密传输视频,并且加密和传输技术不断演进更新,基于流量分析的视频识别方法的关键技术难点是视频的应用层内容被加密并分为很多ip报文传输,导致难以直接从密文数据中还原视频片段长度特征。
6、为了从加密流量中得到视频片段的长度特征,现有方法利用了http/1.1传输视频时的侧信道协议信息估计视频片段长度特征。http/1.1基于tcp传输,利用tcp头部的响应序列号可将属于同一个视频片段的加密报文的载荷长度相加,以此作为应用层音视频片段的长度特征,但是这些方法没有考虑到视频传输过程中加密协议和传输协议增加的信息对长度造成的干扰。近年一些方法提出基于数据加密传输的原理,将从加密流量中提取的视频片段载荷长度更加精准地还原为视频片段本来的长度,可以全面提高视频识别的准确性,减少误判率。
7、现有方法都利用了tcp报文头部的响应标志位,但是,最新的http/3协议不再基于tcp,而是基于udp传输。为了提高数据的传输效率,谷歌公司提出了基于udp的传输层协议quic,2022年ietf基于quic发布了运行在quic之上的http/3协议。根据w3techs的统计显示,全球前1000万个网站中,已有25.2%的网站采用http/3,可以预见http/3将在未来占有更大的网络流量比例。http/3基于udp协议重新定义了连接,在quic层实现了无序、并发字节流的传输,解决了队头阻塞问题。udp是无连接的传输协议,头部没有标志位,无法识别属于同一个音视频片段的报文。此外,quic协议加密了数据包头和载荷中的传输层元数据,使得传输过程几乎没有可用的明文信息,这导致现有依赖tcp头部信息的加密视频识别方法都无法应用于http/3协议。
8、目前,已有对经过tls或quic加密传输的youtube dash视频进行识别的发明专利。已有的发明专利“一种识别tls协议加密传输youtube dash视频的方法”主要针对使用基于tcp传输的http/1.1协议传输的方法,其利用了tcp头部信息和tls协议头部信息,将属于同一个视频片段的报文组合进行后续分析。但是这类方法在面对基于udp传输的http/3协议时将不再适用,因为udp头部没有类似tcp报文的头部信息帮助提取属于同一个视频片段的报文,且http/3协议基于的quic协议将tls1.3进行了封装,也无法提取tls头部信息。此外,http/3使用的多路复用技术导致多个视频片段混合传输,提取单个视频片段更加困难。除此之外,即使“一种识别quic协议加密传输的youtube dash视频的方法”可以解决类似问题,但是该发明专利于2019年申请,方法所针对的quic版本为gquic,该方法所依赖的视频传输方式及quic封装结构已经改变,因此使用该方法已经无法从现有的http/3视频流中还原出应用层特征,而本发明针对2021年被标准化的quic协议,提出了新的应用层长度特征还原方法。综上所述,本发明通过分析quic及http/3协议的特点,结合dash视频传输机制,提取使用http/3传输的加密视频的数据传输和控制信息特征,考虑各层传输协议对应用层长度的干扰,对从网络层和传输层信息中提取出的音视频长度进行修正,最终通过特征在视频库中的匹配来实现视频内容识别。
技术实现思路
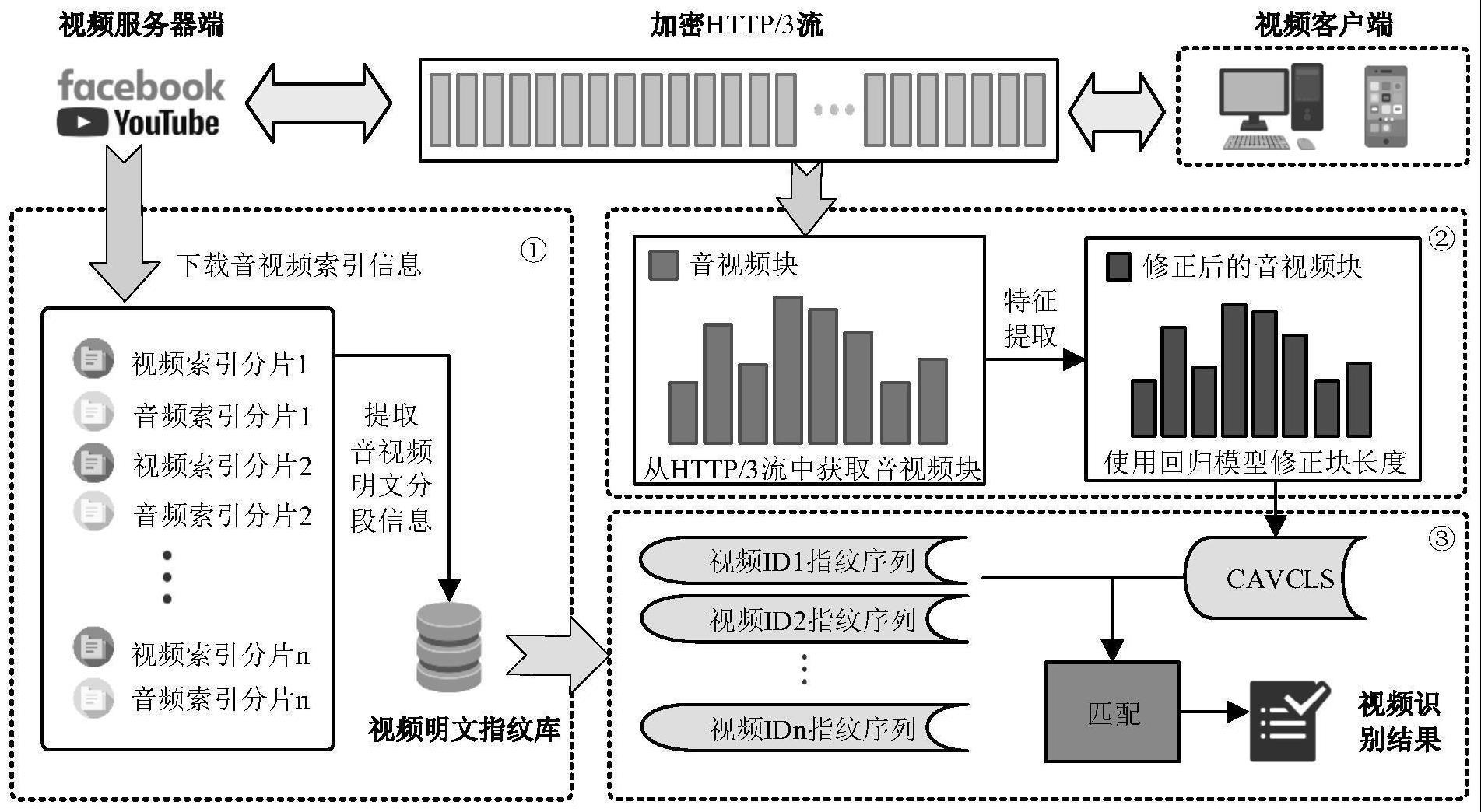
1、随着使用http/3传输视频的平台增多,如何从网络流量中识别使用http/3传输的加密视频成为网络空间安全管理中亟需解决的问题。为解决上述问题,本发明公开了一种基于http/3传输特性的加密视频识别方法。首先,该方法通过提取http/3协议中的控制信息特征和数据传输特征,提出了从加密http/3视频流中提取音视频块并对密文长度进行修正的方法,其次,将修正后的密文长度与视频指纹库中的视频指纹进行匹配产生备选视频集并计算概率,选取可能性最大的视频标题作为识别结果。本方法具有通用性,可用于识别使用dash分发机制、http/3协议传输的加密视频内容。
2、为了实现本发明的目的,本方案具体技术步骤如下:一种基于http/3传输特性的加密视频识别方法,所述方法包括以下步骤:
3、步骤(1)下载所需识别的视频的元信息并提取其中的音视频明文分段信息,打上内容标签,从而获取视频明文指纹,构建视频明文指纹库。
4、步骤(2)在采集设备上,抓取视频播放时的加密传输数据。
5、步骤(3)对步骤(2)采集的流量数据,根据五元组(源ip地址、目的ip地址、源端口,目的端口,传输层协议)筛选流量数据大于64kb的http/3加密视频数据流并进行分块处理,提取出音视频块及其长度特征。
6、步骤(4)对步骤(3)提取出的音视频块进行特征提取并记录特征数据,包括控制信息特征stream_idflag、minusflag和数据传输特征packetcount、streamlen。
7、步骤(5)根据步骤(4)提取出的特征,将音视频块传输前对应的音视频片段组合长度lfit作为音视频块密文长度的标签,使用回归模型对步骤(3)中提取的音视频块的长度进行修正得到修正密文长度cavcl(corrected audio/video combination length)。对http/3加密数据流中的所有音视频块进行修正处理,得到的cavcl序列称为cavcls(correctedaudio/video combination length serials)。
8、步骤(6)对(5)中得到的cavcls,将其与(1)中构建的明文指纹库进行匹配,得到视频内容标题。
9、进一步的,所述步骤(1)中,dash使用vbr技术将多媒体文件编码成不同质量级别的文件,vbr是一种视频流编码方式,可以根据文件内容的复杂程度决定使用不同的比特率编码。然后,dash将编码后的多媒体文件分割成一个或多个几秒长的片段,并创建一个索引文件用于储存音频和视频片段的信息,dash通过视频播放器向服务器请求索引文件来开始流媒体会话。同一个视频会被编码为多种比特率和分辨率的组合。因此,不同视频相同时长的片段长度,以及同一视频不同分辨率的片段长度之间的差异都可能较大,每个视频片段的数据量与视频内容的复杂性相关,也和播放的分辨率相关。虽然数据加密后无法破解数据内容,但是音视频片段的数据量能够通过流量分析获得,此外,这些视频片段正常情况下都是按顺序下载的,这使得这些片段的长度及其顺序序列可以作为视频识别的特征。所述步骤(1)具体包括以下子步骤:
10、(1.1)给定需要识别的视频标题和url列表。
11、(1.2)下载给定视频的响应json文件,提取索引片段在整个音视频中的所在范围,并根据该范围下载音视频索引片段。
12、(1.3)从音视频索引片段中提取索引信息,获取给定视频的音视频明文指纹信息并标记内容标签,如视频标题、分辨率信息以及明文标号等。
13、(1.4)对于步骤(1.1)中给定的视频,使用(1.2)和(1.3)相同的方法进行明文指纹提取,建立视频明文指纹数据库。
14、进一步的,所述步骤(2)具体包括以下子步骤:采集设备特定接口的加密传输数据,存为报文数据文件。
15、进一步的,所述步骤(3)中,根据http/3流传输特性,客户端请求之间的数据为一个音视频块,只要识别出请求报文就可以将音视频块作为一个单元分割出。但是在传输中,客户端除了请求,也会发送确认数据,而且数据内容都被加密,难以区分请求和确认报文。因为请求报文包含了请求的应用层音视频块的描述信息,数据内容远多于确认报文,本发明使用数据包的长度区分客户端发出的请求和确认报文。根据对http/3流的分析,因为要携带请求的目标参数,请求数据包的长度一般为1000字节左右,而确认数据包只有几十字节。根据以上特征,一个音视频块的开始标志可以被认定为客户端向服务器发送的长度为1000字节左右的数据包。持续接收一段时间后,如果客户端又发送了一个长度为1000字节左右的数据包,这个数据包之前的最后一个响应数据包是这个音视频块的结束。由此可以将http/3流中所有组合传输的音视频块分割出。所述步骤(3)具体包括以下子步骤:
16、(3.1)根据五元组(源ip地址,源端口,目的ip地址,目的端口,传输层协议)提取http/3双向流,并设置阈值64kb筛选出http/3加密视频流量。
17、(3.2)对于(3.1)提取出的http/3加密视频流,提取出客户端向服务器发送的长度为1000字节左右的数据包作为请求报文,将请求报文作为分割点,两次请求报文之间的一条stream的流量数据被认定为一个音视频块。
18、(3.3)对于步骤(3.1)中提取出的http/3加密视频流量,使用(3.2)相同的方法分割出多个音视频块。
19、(3.4)对于步骤(3.2)分割出的音视频块,将其中包含的所有响应数据包的udp载荷长度相加得到这个音视频块的密文长度。
20、(3.5)对于步骤(3.3)分割出的每个音视频块,使用(3.4)相同的方法得到(3.1)中http/3加密视频流的音视频块密文长度特征序列。
21、进一步的,所述步骤(4)中,随着视频长度的增加,传输的音视频片段组合超过15个后,stream id字段对音视频块密文长度的影响会增大。假设stream id为60的音视频块(即第15个音视频块)中包含9295个数据包,stream id为64的音视频块(即第16个音视频块)中包含10869个数据包,前者的stream id字段在其整个音视频块中共占用9295个字节,后者共占用21738字节,若不考虑stream id字段的影响,将其占用的字节都计为1,则对于后者来说,修正产生的偏差将会达到10869字节。除此之外,服务器发送响应数据时,根据一个音视频块响应开始的不同,有两种传输情况。第一种情况是先将响应信息与http/3header帧分为两个较小的包传输,然后再传输视频数据的第一个quic包;第二种情况是将响应信息单独以一个100字节左右的quic包传输,然后将http/3header帧与部分视频数据合并为一个quic包传输。由于本发明是从包含视频数据的第一个quic包开始累加载荷长度来获取音视频块的密文长度,因此对第一种情况,可以直接从该音视频块的第三个quic包开始减去增加的quic控制信息,而对第二种情况,第二个quic包中除了quic头部信息,还需要再减去header帧的长度。所述步骤(4)具体包括以下子步骤:
22、(4.1)对于每一个步骤(3)中提取出的音视频块,统计其中包含的所有响应数据包数量作为数据传输特征packetcount,统计所有响应数据包的udp载荷长度之和作为数据传输特征streamlen。
23、(4.2)对于每一个步骤(3)中提取出的音视频块,记录控制信息特征stream_idflag。stream id的取值从4开始以4为倍数递增,前15个音视频块中stream id为4至60,占用1字节,此时stream_idflag为0;后续音视频块中的stream id都大于64,占用2字节,此时stream_idflag为1。
24、(4.3)对于每一个步骤(3)中提取出的音视频块,记录控制信息特征minusflag。对于每个音视频块,若响应信息与http/3header帧分为两个较小的独立数据包传输,然后再传输视频数据的第一个数据包,则此时minusflag为0;若响应信息单独以一个100字节左右的数据包传输,然后再将http/3header帧与部分视频数据合并为一个数据包传输,则此时minusflag为1。
25、进一步的,所述步骤(5)中,统计音视频快密文长度与视频明文指纹库中对应的明文指纹组合的比值,发现呈线性关系,因此可以使用多元线性回归方法修正密文长度。步骤(4)中提取的packetcount、streamlen、stream_idflag、minusflag四个特征被用于产生多元线性回归模型,其中,数据传输特征packetcount、streamlen被作为自变量,对应的明文数据lfit作为因变量。所述步骤(5)具体包括以下子步骤:
26、(5.1)对于步骤(3)中提取的音视频块,根据步骤(4)提取出的特征,获取音视频块传输前对应的音视频片段组合长度,此时有:
27、
28、其中,lfit代表音视频块对应的明文数据;packetcount代表音视频块中的响应数据包数量;streamlen代表音视频块中的所有数据包udp载荷长度之和;stream_idflag代表stream id取值是否大于等于64,大于等于64取1,否则取0。minusflag代表http/3header帧与部分视频数据是否合并传输,合并传输取1,否则取0。对于不同的minusflag取值,使用不同的系数α、β、γ计算音视频块的修正密文长度。
29、(5.2)将音视频块对应的明文数据以及步骤(4)中得到的该音视频块的四个特征数据带入(5.1)中的公式,训练线性回归模型,获取系数α、β、γ的值。
30、(5.3)根据训练好的线性回归模型对音视频块进行密文长度修正,计算得到音视频块的应用层传输数据近似大小cavcl。
31、进一步的,所述步骤(6)具体包括以下子步骤:
32、(6.1)根据步骤(5)计算得到修正密文长度序列cavcls。
33、(6.2)对步骤(1)中得到的视频明文指纹库的每一个视频明文指纹序列,对序列中的1至n个相邻指纹进行组合,构建视频组合指纹库。
34、(6.3)设置误差上下限m1、m2,对视频组合指纹库中的每一个组合指纹,若其长度在[cavcl-m1,cavcl+m2]范围内,则认为该组合指纹与该cavcl匹配,并记录组合指纹的视频标题、分辨率信息以及包含的明文标号序列等信息。
35、(6.4)对(6.1)中得到的cavcls中的每一个cavcl使用(6.3)中相同的方法进行匹配,得到cavcls的匹配结果序列。
36、(6.5)对(6.4)中得到的匹配结果序列按照视频标题和时间顺序归类和排列后进行概率计算,选取其中概率最大的视频标题作为http/3加密视频流量的内容识别结果。
37、与现有技术相比,本发明的技术方案具有以下有益技术效果。
38、(1)本发明所提出的基于http/3传输特性的加密视频识别方法,解决了现有依赖tcp头部信息的加密视频识别方法无法应用于http/3协议的问题。已有方法利用tcp头部信息,将属于同一个视频片段的报文组合进行后续分析。但是由于http/3协议基于udp传输,没有类似tcp报文的头部信息帮助提取属于同一个视频片段的报文,且http/3使用的多路复用技术导致多个视频片段混合传输,无法提取单个视频片段。本发明给出了一种http/3协议中精准还原音视频块应用层长度特征的方法。
39、(2)本发明针对http/3的信息加密和多路复用的传输特点,通过提取针对性的数据传输特征和控制信息特征对音视频块传输层长度特征进行修正得到应用层长度的近似值cavcl,与视频明文指纹库生成的组合指纹库进行匹配以获取视频内容标题。
40、(3)本发明基于领域知识提取包括数据传输和控制信息两种特征,可以快速、简单地对视频进行识别,不过度依赖于训练集的规模,具有通用性,适用于youtube、facebook等使用dash分发机制和http/3协议传输视频的平台。
- 还没有人留言评论。精彩留言会获得点赞!